一、个性化推荐算法简介
项目
demo1图书管理系统demo2电影推荐系统demo
1、基于⽤户的协同过滤算法(UserCF)
该算法利⽤⽤户之间的相似性来推荐⽤户感兴趣的信息,个⼈通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的⽬的进⽽帮助别⼈筛选信息,回应不⼀定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
但两个问题,⼀个是稀疏性,即在系统使⽤初期由于系统资源还未获得⾜够多的评价,很难利⽤这些评价来发现相似的⽤户。
另⼀个是可扩展性,随着系统⽤户和资源的增多,系统的性能会越来越差。
用户协同算法讲解传送门
2.基于物品的协同过滤算法(ItemCF)
内容过滤根据信息资源与⽤户兴趣的相似性来推荐商品,通过计算⽤户兴趣模型和商品特征向量之间的向量相似性,主动将相似度⾼的商品发送给该模型的客户。
由于每个客户都独⽴操作,拥有独⽴的特征向量,不需要考虑别的⽤户的兴趣,不存在评价级别多少的问题,能推荐新的项⽬或者是冷门的项⽬。
这些优点使得基于内容过滤的推荐系统不受冷启动和稀疏问题的影响。
二、基于物品的协同过滤算法以及流程
1、算法核心
通过分析用户行为记录(评分、购买、点击、浏览等行为)来计算两个物品的相似度,同时喜欢物品A和物品B的用户数越多,就认为物品A和物品B越相似。
2、流程
1.构建⽤户–>物品的对应表 2.构建物品与物品的关系矩阵(同现矩阵) 3.通过求余弦向量夹角计算物品之间的相似度,即计算相似矩阵 4.根据⽤户的历史记录,给⽤户推荐物品3、构建用户与物品的对应关系表
如下表,⾏表⽰⽤户,列表⽰物品(电影),数字表⽰⽤户喜欢该物品的程度(评分)
用户\电影 唐伯虎点秋香 逃学威龙1 追龙 他人笑我太疯癫 喜欢你 暗战 A 5 1 2 B 4 2 3.5 C 2 4 D 4 3 E 4 34、构建物品与物品的关系矩阵(共现矩阵)
共现矩阵C表⽰同时喜欢两个物品的⽤户数,是根据⽤户物品对应关系表计算出来的。
如根据上⾯的⽤户物品关系表可以计算出如下的共现矩阵C:
电影\电影 唐伯虎点秋香 逃学威龙1 追龙 他人笑我太疯癫 喜欢你 暗战 唐伯虎点秋香 1 1 1 1 逃学威龙1 1 1 2 追龙 1 1 他人笑我太疯癫 2 喜欢你 1 2 暗战 1 25、计算相似矩阵
两个物品之间的相似度如何计算?
设|N(i)|表⽰喜欢物品i的⽤户数,|N(i)⋂N(j)|表⽰同时喜欢物品i,j的⽤户数,则物品i与物品j的相似度为:
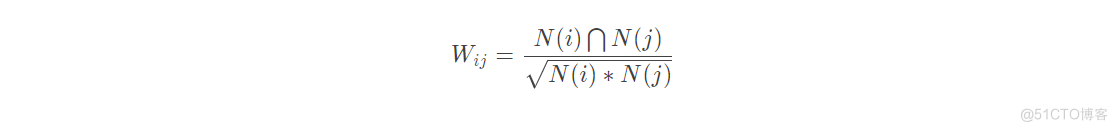
利用公式计算物品之间的余弦相似矩阵如下:
电影\电影 唐伯虎点秋香 逃学威龙1 追龙 他人笑我太疯癫 喜欢你 暗战 唐伯虎点秋香 0.41 0.7 0.5 0.5 逃学威龙1 0.41 0.58 0.82 追龙 0.71 0.58 他人笑我太疯癫 0.82 喜欢你 0.5 1.0 暗战 0.5 1.06、给用户推荐物品
根据⽤户的历史记录,给⽤户推荐物品。
最终推荐的是什么物品,是由预测兴趣度决定的。
物品j预测兴趣度=⽤户喜欢的物品i的兴趣度×物品i和物品j的相似度
例如:A⽤户喜欢唐伯虎点秋香,逃学威龙1,追龙 ,兴趣度分别为5,1,2
在用户A的评分电影列表中只有唐伯虎点秋香与喜欢你有相似度,推荐喜欢你的预测兴趣度=5 x 0.5 = 2.5
在用户A的评分电影列表中只有唐伯虎点秋香与暗战有相似度,推荐暗战的预测兴趣度=5 x 0.5 = 2.5
在用户A的评分电影列表中只有逃学威龙1与他人笑我太疯癫有相似度,推荐他人笑我太疯癫的预测兴趣度=1 x 0.82 =0.82
三、python实现代码
from math import sqrt import operator def similarity(data): # 1 构造物品:物品的共现矩阵 N = {} # 喜欢物品i的总⼈数 C = {} # 喜欢物品i也喜欢物品j的⼈数 for user, item in data.items(): for i, score in item.items(): N.setdefault(i, 0) N[i] += 1 C.setdefault(i, {}) for j, scores in item.items(): if j != i: C[i].setdefault(j, 0) C[i][j] += 1 print("---1.构造的共现矩阵---") print('N:', N) print('C', C) # 2 计算物品与物品的相似矩阵 W = {} for i, item in C.items(): W.setdefault(i, {}) for j, item2 in item.items(): W[i].setdefault(j, 0) W[i][j] = C[i][j] / sqrt(N[i] * N[j]) print("---2.构造的相似矩阵---") print(W) return W def recommandList(data, W, user, k=3, N=10): ''' # 3.根据⽤户的历史记录,给⽤户推荐物品 :param data: 用户数据 :param W: 相似矩阵 :param user: 推荐的用户 :param k: 相似的k个物品 :param N: 推荐物品数量 :return: ''' rank = {} for i, score in data[user].items(): # 获得⽤户user历史记录,如A⽤户的历史记录为{'唐伯虎点秋香': 5, '逃学威龙1': 1, '追龙': 2} for j, w in sorted(W[i].items(), key=operator.itemgetter(1), reverse=True)[0:k]: # 获得与物品i相似的k个物品 if j not in data[user].keys(): # 该相似的物品不在⽤户user的记录⾥ rank.setdefault(j, 0) rank[j] += float(score) * w # 预测兴趣度=评分*相似度 print("---3.推荐----") print(sorted(rank.items(), key=operator.itemgetter(1), reverse=True)[0:N]) return sorted(rank.items(), key=operator.itemgetter(1), reverse=True)[0:N] if __name__ == '__main__': # ⽤户,电影,评分 data = { '用户A': {'唐伯虎点秋香': 5, '逃学威龙1': 1, '追龙': 2}, '用户B': {'唐伯虎点秋香': 4, '喜欢你': 2, '暗战': 3.5}, '用户C': {'逃学威龙1': 2, '他人笑我太疯癫': 4}, '用户D': {'喜欢你': 4, '暗战': 3}, '用户E': {'逃学威龙1': 4, '他人笑我太疯癫': 3} } W = similarity(data) # 计算物品相似矩阵 recommandList(data, W, '用户A', 3, 10) # 推荐输出:
---1.构造的共现矩阵--- N: {'唐伯虎点秋香': 2, '逃学威龙1': 3, '追龙': 1, '喜欢你': 2, '暗战': 2, '他人笑我太疯癫': 2} C {'唐伯虎点秋香': {'逃学威龙1': 1, '追龙': 1, '喜欢你': 1, '暗战': 1}, '逃学威龙1': {'唐伯虎点秋香': 1, '追龙': 1, '他人笑我太疯癫': 2}, '追龙': {'唐伯虎点秋香': 1, '逃学威龙1': 1}, '喜欢你': {'唐伯虎点秋香': 1, '暗战': 2}, '暗战': {'唐伯虎点秋香': 1, '喜欢你': 2}, '他人笑我太疯癫': {'逃学威龙1': 2}} ---2.构造的相似矩阵--- {'唐伯虎点秋香': {'逃学威龙1': 0.4082482904638631, '追龙': 0.7071067811865475, '喜欢你': 0.5, '暗战': 0.5}, '逃学威龙1': {'唐伯虎点秋香': 0.4082482904638631, '追龙': 0.5773502691896258, '他人笑我太疯癫': 0.8164965809277261}, '追龙': {'唐伯虎点秋香': 0.7071067811865475, '逃学威龙1': 0.5773502691896258}, '喜欢你': {'唐伯虎点秋香': 0.5, '暗战': 1.0}, '暗战': {'唐伯虎点秋香': 0.5, '喜欢你': 1.0}, '他人笑我太疯癫': {'逃学威龙1': 0.8164965809277261}} ---3.推荐---- [('喜欢你', 2.5), ('暗战', 2.5), ('他人笑我太疯癫', 0.8164965809277261)]