训练Tesseract
大多数其他的验证码都是比较简单的。例如,流行的 PHP 内容管理系统 Drupal 有一个著 名的验证码模块(https://www.drupal.org/project/captcha),可以生成不同难度的验证码。
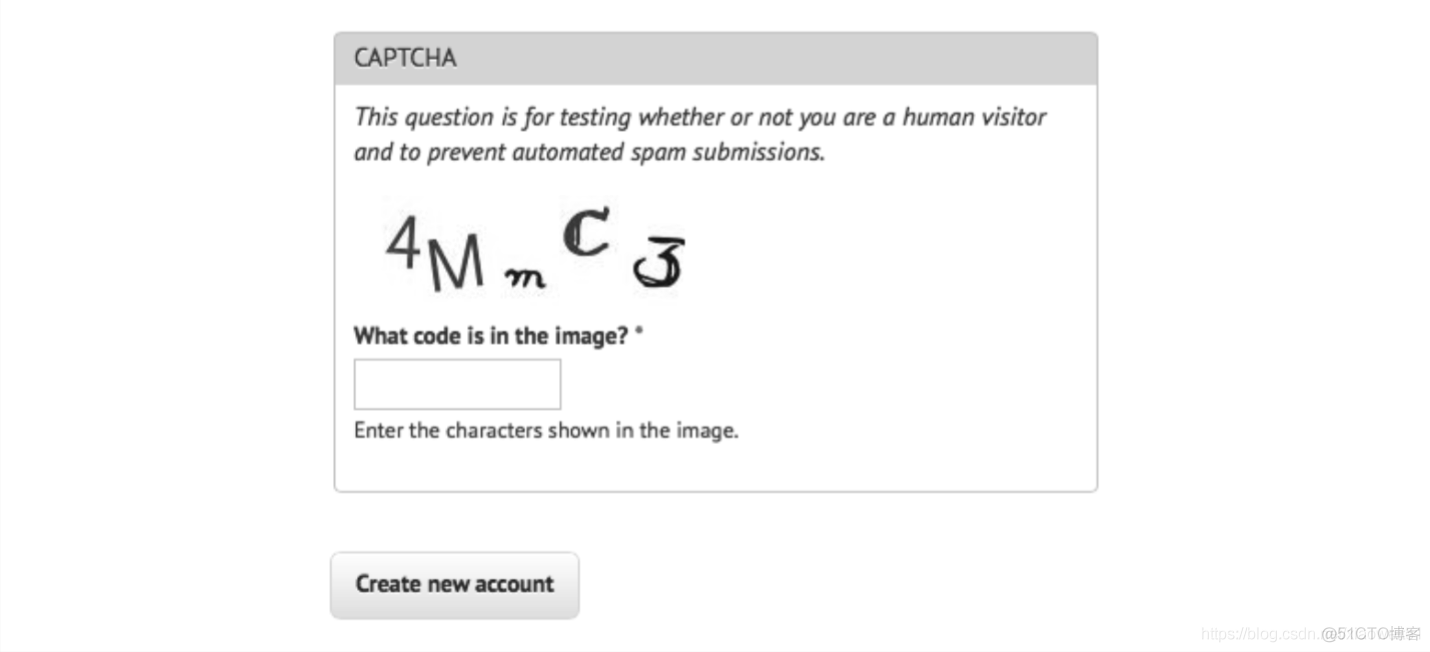
那么与其他验证码相比,究竟是什么让这个验证码更容易被人类和机器读懂呢?
- 字母没有相互叠加在一起,在水平方向上也没有彼此交叉。也就是说,可以在每一个字 母外面画一个方框,而不会重叠在一起。
- 图片没有背景色、线条或其他对 OCR 程序产生干扰的噪点。
- 虽然不能因一个图片下定论,但是这个验证码用的字体种类很少,而且用的是 sans-serif 字体(像“4”和“M”)和一种手写形式的字体(像“m”“C”和“3”)。
- 白色背景色与深色字母之间的对比度很高。
这个验证码只做了一点点改变,就让 OCR 程序很难识别。
- 字母和数据都使用了,这会增加待搜索字符的数量。
- 字母随机的倾斜程度会迷惑 OCR 软件,但是人类还是很容易识别的。
- 那个比较陌生的手写字体很有挑战性,在“C”和“3”里面还有额外的线条。另外这 个非常小的小写“m”,计算机需要进行额外的训练才能识别。 用下面的代码运行 Tesseract 识别图片:
tesseract captchaExample.png output
我们得到的结果 output.txt 是: 4N\,,,C<3
训练Tesseract
要训练 Tesseract 识别一种文字,无论是晦涩难懂的字体还是验证码,你都需要向 Tesseract 提供每个字符不同形式的样本。
做这个枯燥的工作可能要花好几个小时的时间,你可能更想用这点儿时间找个好看的视频 或电影看看。首先要把大量的验证码样本下载到一个文件夹里。
下载的样本数量由验证码 的复杂程度决定;我在训练集里一共放了 100 个样本(一共 500 个字符,平均每个字符 8 个样本;a~z 大小写字母加 0~9 数字,一共 62 个字符),应该足够训练的了。
提示:建议使用验证码的真实结果给每个样本文件命名(即4MmC3.jpg)。 这样可以帮你 一次性对大量的文件进行快速检查——你可以先把图片调成缩略图模式,然后通过文件名 对比不同的图片。这样在后面的步骤中进行训练效果的检查也会很方便。
第二步是准确地告诉 Tesseract 一张图片中的每个字符是什么,以及每个字符的具体位置。 这里需要创建一些矩形定位文件(box file),一个验证码图片生成一个矩形定位文件。一 个图片的矩形定位文件如下所示:
4 15 26 33 55 0M 38 13 67 45 0
m 79 15 101 26 0
C 111 33 136 60 0
3 147 17 176 45 0
第一列符号是图片中的每个字符,后面的 4 个数字分别是包围这个字符的最小矩形的坐标 (图片左下角是原点 (0,0),4 个数字分别对应每个字符的左下角 x 坐标、左下角 y 坐标、右上角 x 坐标和右上角 y 坐标),最后一个数字“0”表示图片样本的编号。
显然,手工创建这些图片矩形定位文件很无聊,不过有一些工具可以帮你完成。我很喜欢 在线工具 Tesseract OCR Chopper(http://pp19dd.com/tesseract-ocr-chopper/),因为它不需要 安装,也没有其他依赖,只要有浏览器就可以运行,而且用法很简单:上传图片,如果要 增加新矩形就单击“add”按钮,还可以根据需要调整矩形的尺寸,最后把新生成的矩形 定位文件复制到一个新文件里就可以了。
矩形定位文件必须保存在一个 .box 后缀的文本文件中。和图片文件一样,文本文件也是用 验证码的实际结果命名(例如,4MmC3.box)。另外,这样便于检查 .box 文件的内容和文件的名称,而且按文件名对目录中的文件排序之后,就可以让 .box 文件与对应的图片文件 的实际结果进行对比。
你还需要创建大约 100 个 .box 文件来保证你有足够的训练数据。因为 Tesseract 会忽略那 些不能读取的文件,所以建议你尽量多做一些矩形定位文件,以保证训练足够充分。如果 你觉得训练的 OCR 结果没有达到你的目标,或者 Tesseract 识别某些字符时总是出错,多 创建一些训练数据然后重新训练将是一个不错的改进方法。
创建完满载 .box 文件和图片文件的数据文件夹之后,在做进一步分析之前最好备份一下这 个文件夹。虽然在数据上运行训练程序不太可能删除任何数据,但是创建 .box 文件用了你 好几个小时的时间,来之不易,稳妥一点儿总没错。此外,能够抓取一个满是编译数据的 混乱目录,然后再尝试一次,总是好的。
前面的内容只是对 Tesseract 库强大的字体训练和识别能力的一个简略概述。如果你对 Tesseract 的其他训练方法感兴趣,甚至打算建立自己的验证码训练文件库,或者想和全世 界的 Tesseract 爱好者分享自己对一种新字体的识别成果,推荐阅读 Tesseract 的文档:https://github.com/tesseract-ocr/tesseract/wiki,加油!