正则表达式语法 位置 正向预查 比如说我们有一个文本叫做abcd,现在我们希望匹配"a后面的bcd",但是“又不希望匹配到a”,那么可以用正向预查这么写: (?=a)bcd 这里的(?=a)即为正向预
正则表达式语法

位置

正向预查
比如说我们有一个文本叫做abcd,现在我们希望匹配"a后面的bcd",但是“又不希望匹配到a”,那么可以用正向预查这么写:
(?<=a)bcd这里的(?<=a)即为正向预查的写法,它代表的含义就是匹配a后面的内容,但是又不包含a本身
负向预查
接下来再来看负向预查的写法,还是拿abcd来举例子,假设这里我们要匹配"d前面的abc",但是“又不希望匹配到d”,那么使用负向预查可以这么写
abc(?=d)这里的(?=d)即为负向预查的写法,它代表的含义就是匹配d前面的内容,但是又不包含d本身
正则表达式关卡
关卡1-固定字符串
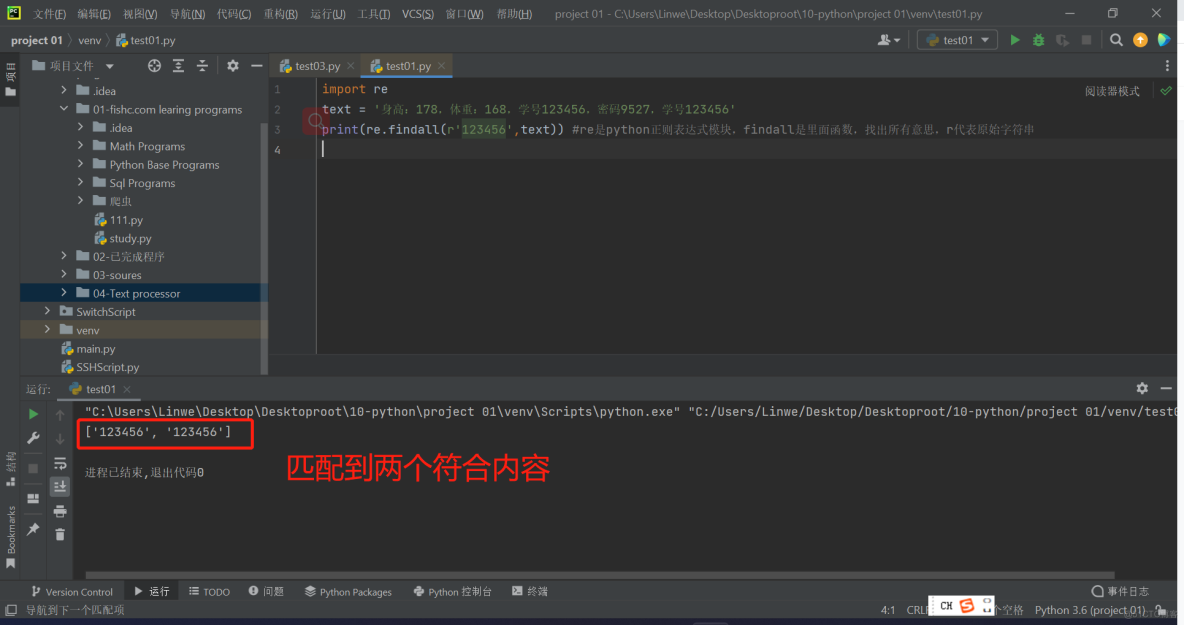
要求:找出字符串中是否含有123456
import retext = '身高:178,体重:168,学号123456,密码9527,学号123456'
print(re.findall(r'123456',text)) #re是python正则表达式模块,findall是里面函数,找出所有意思,r代表原始字符串
关卡2-预定义字符集
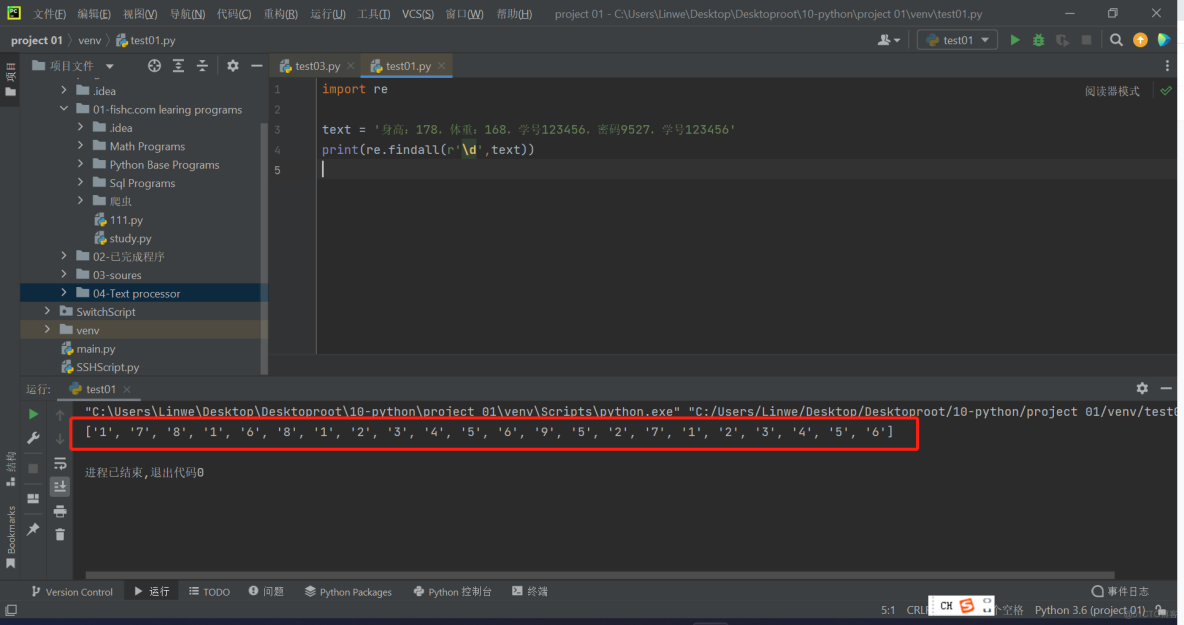
要求:找出所有单个的数字
import retext = '身高:178,体重:168,学号123456,密码9527,学号123456'
print(re.findall(r'\d',text))
关卡3-重复某一类字符
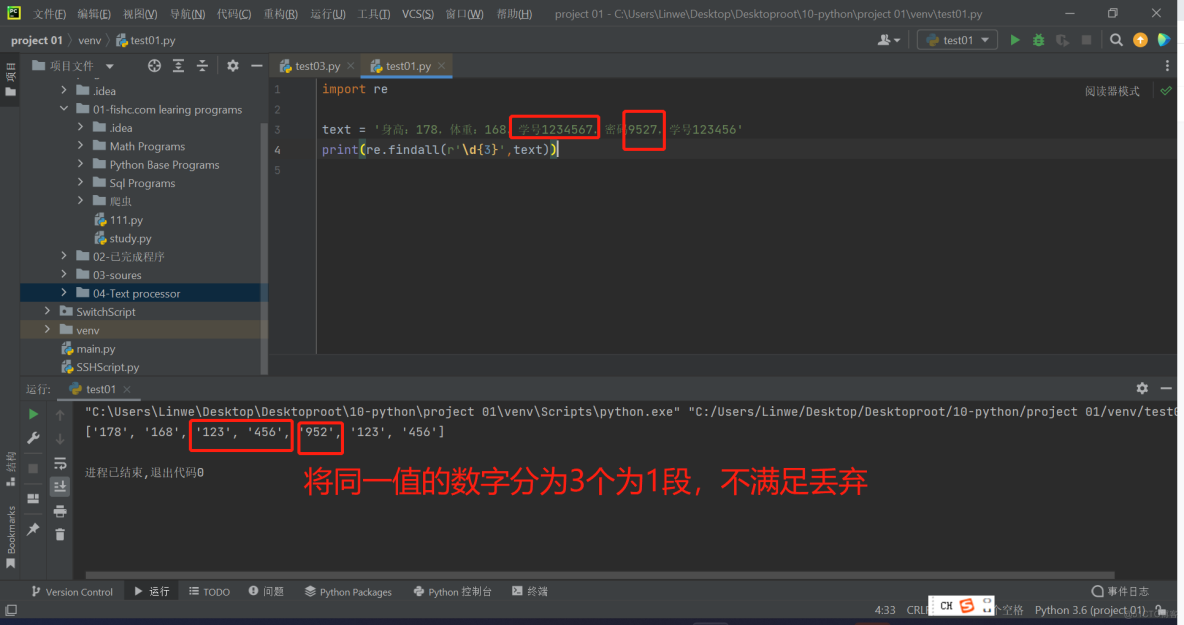
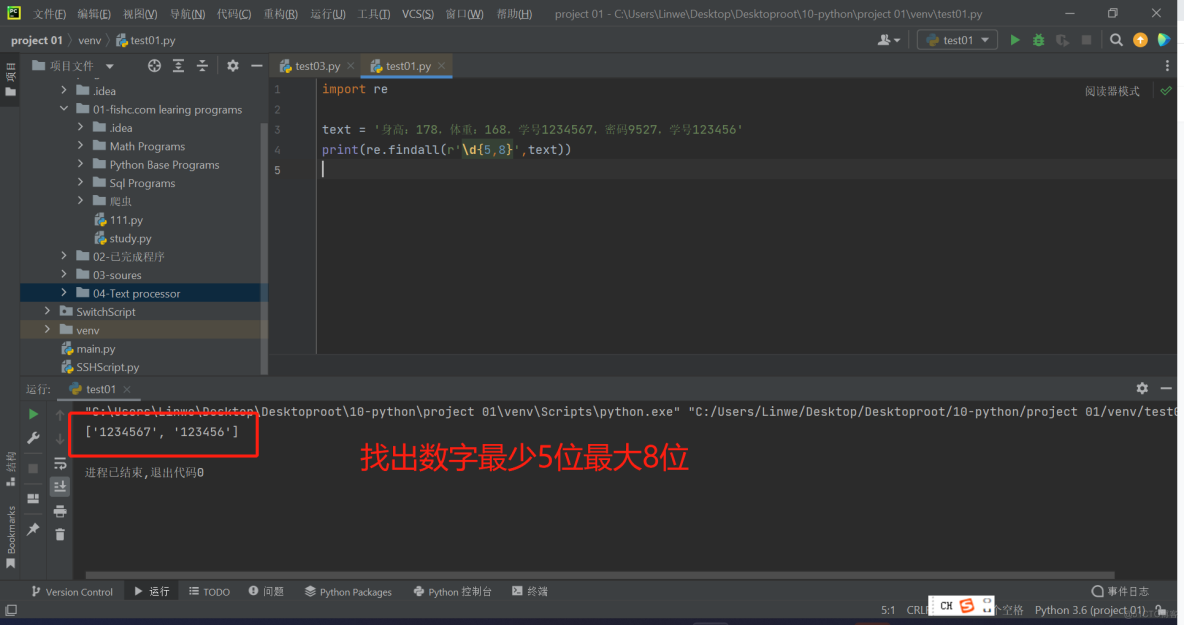
要求:找出所有数字或者长度
import retext = '身高:178,体重:168,学号123456,密码9527,学号123456'

关卡4-组合{}()[]
要求:找出座机号码
- 数量词{}中间代入数值代表前面应该是几位长,可以用逗号分隔代表区间
- ()代表一个整体
- []代表里面多个参数,只要有一个匹配上即可

将最终前后匹配一致的数据分组,最终得到后面那组数据


关卡5-逻辑或|
要求:找出手机号码和座机号码

关卡6-边界匹配^&
要求:找出手机号
text = '18512345678是我的电话号码,另外一个号码是18612345678,座机号码是021-12345678,另外一个座机是0211-12345678'
关卡7-内部约束
要求,找出barbar前后三个字母重复的字符串
text = 'barbar, barpar, parparp'
关卡8-正反向结合

写正则表达式步骤
例如:021-12345678-120
Python的re模块

查找
- search 部分匹配,只要在字符串中找到字符存在即可
- match 从头开始匹配
- findall 返回字符串
- finditer 返回match迭代器
替换
匹配替换返回数量
import re# 去掉电话号码中的-
num = re.subn(r'\D', '', '188-1926-8053')
print(num)
# (18819268053, 2)
分割字符串
按照正则表达式的规则来分割字符串,并返回列表
可以规定分割的次数
import reprint(re.split('a*', 'hello world'))
# ['', 'h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '']
print(re.split('a*', 'hello world', 1))
# ['', 'hello world']
修饰符
re.I:忽略大小写
re.L:本地化识别匹配
re.M:多行匹配
re.S:使.匹配包括换行在内的所有字符
re.U:根据unicode字符解析字符
re.X:给予灵活的格式以便理解
import recontent = "Cats are smarter than dogs"
print(re.search(r'DOGS', content, re.M | re.I))