1、我们的需求: 抓取超话下粉丝们的评论内容,这里我们选择樊振东被保送上海交大的一则超话粉丝 获取用户ID 使用用户ID抓取用户基本的公开信息 使用CSV将抓取的内容存入CSV文件中
1、我们的需求:
2、代码如下:
import collectionsimport time
import os, numpy
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
from pyecharts import options
from pyecharts.charts import Map, Pie
import requests, random, json
import re, csv, jieba
import jieba.analyse
from wordcloud import WordCloud as wordclouds
from PIL import Image
from matplotlib import pyplot
# 初始化会话
session = requests.Session()
min_since_id = ''
comment_path = "D:/comment.txt"
csv_path = "D:/comment_csv.csv"
STOP_WORD_FILE_PATH = "d:/stop_word.txt"
def capture_sina():
"""
抓取樊振东超话信息
:return:
"""
global min_since_id
weibo_url = "https://m.weibo.cn/api/container/getIndex?jumpfrom=weibocom&containerid=1008080391332928de4da0860b025d281356e1_-_feed&since_id=4757578200385829"
if min_since_id:
weibo_url = weibo_url + '&since_id=' + min_since_id # 构造抓取URL
head = {
"User-Agent": "Mozilla/5.0",
"Referer": "https://m.weibo.cn/p/1008080391332928de4da0860b025d281356e1/super_index?jumpfrom=weibocom"
}
# try:
result = session.post(url=weibo_url, headers=head)
result.raise_for_status()
r_json = json.loads(result.text)
# except:
# print("fail")
data = r_json['data']['cards']
card_group = data[2]['card_group'] if len(data) > 1 else data[0]['card_group']
# print(card_group)
for comment in card_group:
mblog = comment['mblog']
user = mblog['user']
user_id = user['id'] # 获取用户ID
since_id = mblog['id'] # 微博分页机制是利用这个since_id实现的
sina_text = re.compile(r'<[^>]+>', re.S).sub(' ', mblog['text'])
# 去除评论内容中无效的内容
sina_text = sina_text.replace('樊振东', '').strip().replace(r'#连续24个月世界排名第一#', '')
# print(sina_text)
if min_since_id:
min_since_id = since_id if min_since_id > since_id else min_since_id
else:
min_since_id = since_id
# try:
capture_user_info(user_id)
# except:
# print("爬取用户信息失败")
with open(comment_path, 'a+', encoding='utf-8') as files:
files.write(sina_text+'\n')
def capture_user_info(uid):
"""
抓取用户信息,这儿需要先使用自己账号登录,我们先在浏览器登录在把cookie等请求头复制过来
:return:
"""
user_info_url = "https://weibo.com/ajax/profile/detail?uid=%s" % uid
headers = {
"user-agent": "Mozilla/5.0",
"referer": "https://weibo.com/u/6026794900",
"cookie": "将浏览器中cookie完整复制过来"}
try:
get = session.get(url=user_info_url, headers=headers)
get.raise_for_status()
except:
print("抓取失败")
userinfo = get.text
userinfo_json = json.loads(userinfo)
# print(userinfo_json)
# 解析用户数据
area = userinfo_json['data']['ip_location'].strip() # 获取地区,这个地区是IP所属地区
sex = userinfo_json['data']['gender'].strip() # 获取性别,m代表男生,f代表女生
age = userinfo_json['data']['birthday'].strip() # 获取年龄,但是根据抓取分析看,很多用户都开启只显示星座,价值不大
# school = userinfo_json['education']['school'] # 获取用户教育信息,很多用户没有写,价值也不大
area_location = userinfo_json['data']['location'].strip() # 这个是用户自己填的地区,无法确保数据,在分析时使用IP归属地
sina_data = []
# 数据清洗
if '其他' in area or '海外' in area:
area = ''
elif '其他' in area_location or '海外' in area_location:
area_location = ''
elif str(sex) == 'm':
sex = '男'
elif str(sex) == 'f':
sex = '女'
elif age.startwith('19') or age.startwith('20'):
age = age[:3]
# 数据顺序:用户ID,所在地,性别,年龄
sina_data.append(uid)
sina_data.append(area[5:])
sina_data.append(sex.replace(r'f', '女'))
sina_data.append(age)
sina_data.append(area_location)
# 保存数据
save_data_to_csv(column=sina_data)
def save_data_to_csv(column, encodeing='utf-8'):
"""
保存数据到CSV文件,方便后续读取分析
:param column:
:param encodeing:
:return:
"""
with open(csv_path, 'a', newline='', encoding=encodeing) as csvfile:
csv_write = csv.writer(csvfile)
csv_write.writerow(column)
def cut_data():
with open(comment_path, encoding='utf-8', errors='ignore') as file:
comment_content = file.read()
word_list = jieba.cut(comment_content, cut_all=True)
wl = " ".join(word_list)
# print(wl)
return wl
def create_word_cloud():
# 生成词云
color = numpy.array(Image.open("D:/Python/repository-toolbox/test.jpg"))
# 设置词云的配置,如字体,背景色,大小等
word_cloud = wordclouds(background_color="white", max_words=2000, mask=color,
scale=4, max_font_size=50, random_state=42,
font_path="C:/Windows/Fonts/simhei.ttf")
# 生成词云
word_cloud.generate(cut_data())
pyplot.imshow(word_cloud, interpolation="bilinear")
pyplot.axis("off")
pyplot.figure()
pyplot.show()
def analyse_sina_content():
"""
分析微博内容,使用pycharts
:return:
"""
# 读取微博内容列
with open(comment_path, encoding='utf-8', errors='ignore') as file:
comment_content = file.read()
# 数据清洗,去掉无效词
jieba.analyse.set_stop_words(STOP_WORD_FILE_PATH)
# 词数统计
words_count_list = jieba.analyse.textrank(comment_content, topK=100, withWeight=True)
# print(words_count_list)
# 生成词云
word_cloud = (
WordCloud()
.add("", words_count_list, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=options.TitleOpts(title="樊振东微博超话内容分析"))
)
word_cloud.render('D:/word_cloud.html')
def read_csv_data(index) -> dict:
"""
读取CSV文件内容,将其封装为一个方法,方便以后读取
:param index:
:return:
"""
with open(csv_path, 'r', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
column = [columns[index] for columns in reader]
# print(column)
dic = collections.Counter(column)
if '' in dic:
dic.pop('')
return dic
def analyse_city():
"""
根据IP地址所在地分析微博粉丝所处的城市
:return:
"""
dic = read_csv_data(index=1)
city_count = [list(z) for z in zip(dic.keys(), dic.values())]
maps = (
Map()
.add("樊振东粉丝分布图", city_count, "china")
.set_global_opts(title_opts=options.TitleOpts(title="樊振东粉丝分布图"),
visualmap_opts=options.VisualMapOpts(max_=300)
)
)
maps.render("D:/map.html")
def analyse_gender():
"""
根据抓取的用户性别数据对粉丝数据进行性别分析
:return:
"""
gender = read_csv_data(index=2)
gender_count = [list(z) for z in zip(gender.keys(), gender.values())]
pie = (
Pie()
.add("Gender Analyse", gender_count)
.set_colors(["red", "blue", "green", "orange"])
.set_global_opts(title_opts=options.TitleOpts("樊振东粉丝性别分析"))
.set_series_opts(label_opts=options.LabelOpts(formatter="{b}:{c}"))
)
pie.render("d:/gender_analyse.html")
def fetch_sina(page):
"""
调用相关批量抓取
:return:
"""
if os.path.exists(comment_path) or os.path.exists(csv_path):
os.remove(comment_path) or os.remove(csv_path)
for i in range(page):
print("正在抓取第{}页".format(i))
try:
capture_sina()
time.sleep(random.random()*6)
except KeyError as key_error:
print("无法匹配到key:{}".format(key_error))
continue
except:
print("有错误,但是我们还是要继续爬,let go!")
continue
if __name__ == "__main__":
# cut_data()
# create_word_cloud()
fetch_sina(page=400) # 看了下评论大概4000多条,一页大概10条,所以我们爬取400页
analyse_sina_content()
analyse_city()
analyse_gender()
3、分析的结果
微博评论分析结果,可以看到东哥出现的频率很高啊

粉丝地区分析结果
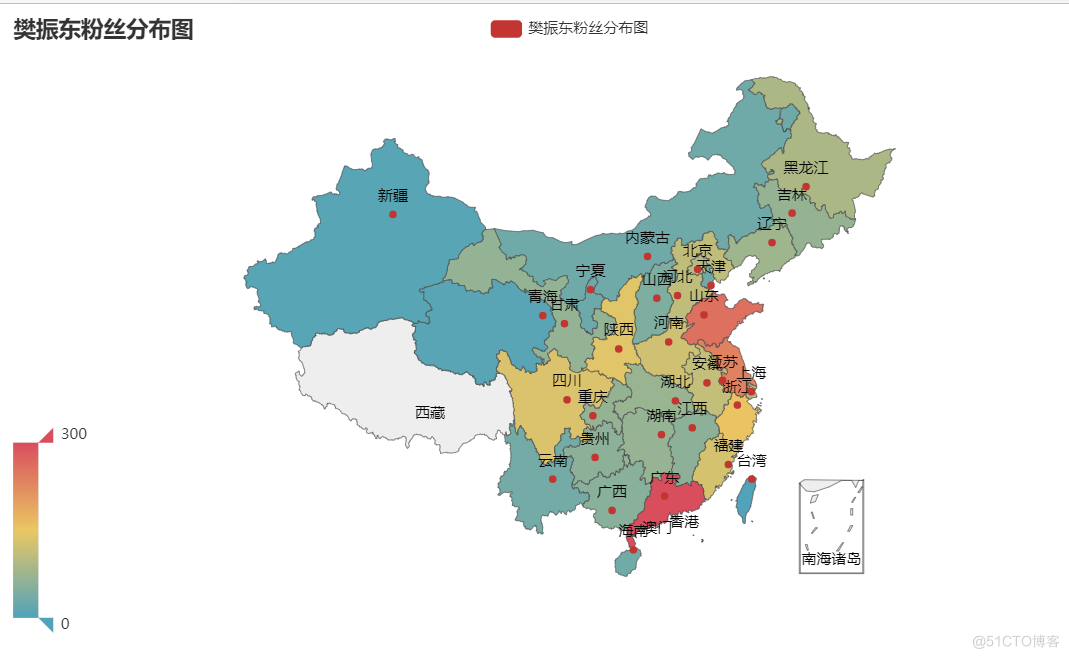
可以看到广东的樊振东粉丝很多啊
粉丝性别分析
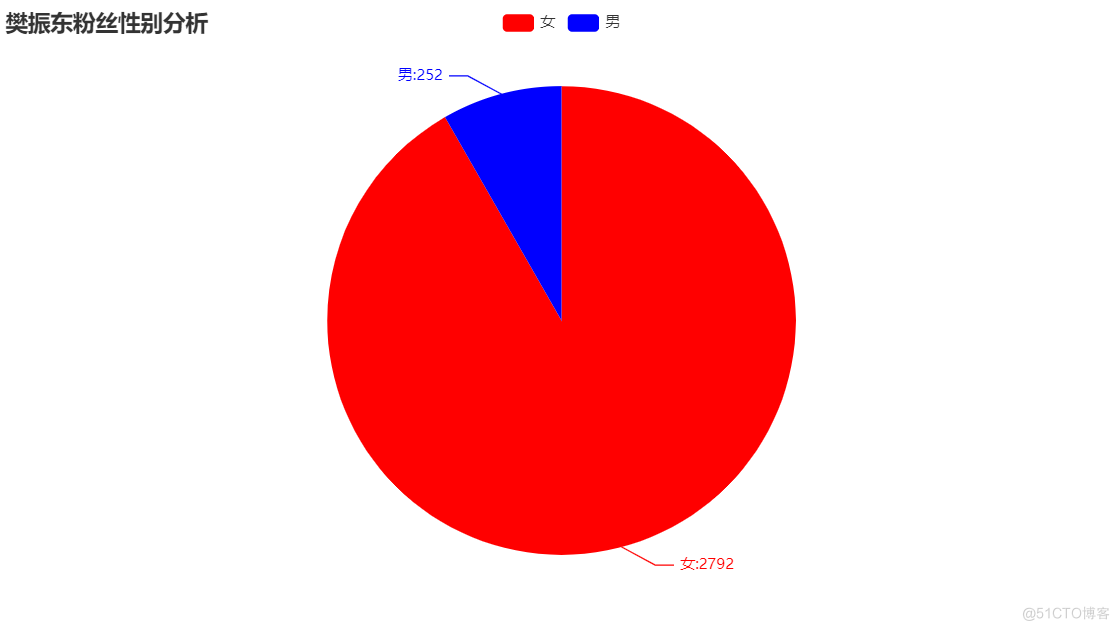
从上图可以看到,在超话下评论的樊振东粉丝大部分是女生