电商类网站爬虫,永远是爬虫圈必爬项目。今天我们就拿《孔夫子旧书网》练练手。
爬取目标源数据分析
本次要爬取的目标网址为 https://book.kongfz.com/Cxiaoshuo/v6/,打开页面寻找分页数据,在下图所示位置可以进行页码切换。
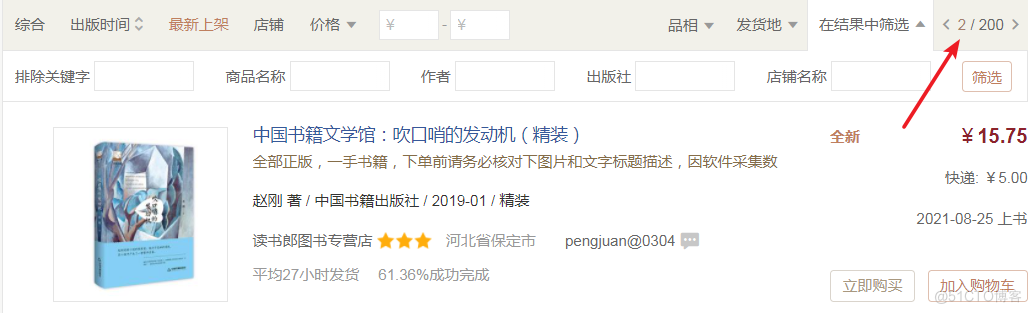 在切换页码的同时,捕获到分页链接,并寻找分页规则。
在切换页码的同时,捕获到分页链接,并寻找分页规则。
提炼列表页地址模板为 https://book.kongfz.com/C{类别}/v6w{页码}/。
上述内容梳理完毕,就可以对列表页进行采集爬取了,本次爬取分为三个步骤进行。
接下来按照步骤实现即可。
提取所有图书分类
通过开发者工具,捕获图书分类区域 HTML 代码,如下所示:
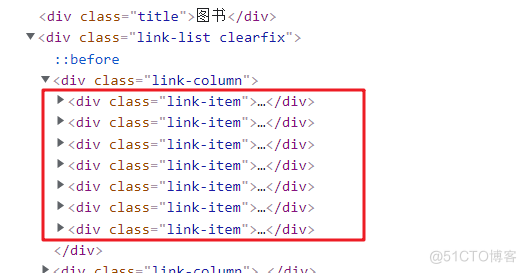 上述数据,可访问任意分类页即可获取,核心代码如下所示,其中 self.get_headers() 函数,可参考之前的博客,或者下载代码查阅。
上述数据,可访问任意分类页即可获取,核心代码如下所示,其中 self.get_headers() 函数,可参考之前的博客,或者下载代码查阅。
此时简单运行之后,就会得到如下清单,即孔夫子旧书网所有图书分类。
xiaoshuo wenxue yuyan lishi dili yishu ……此时遍历该列表,即可获取所有图书列表页数据,学习阶段,可取其中一条进行分析,例如我选择的文学与小说分类,self.types = ["wenxue", "xiaoshuo"]。
采集分类页静态页面数据
对于静态页面数据,采用之前的方法保存到本地即可,在 SSS 类中增加 get_detail 与 run 函数,页码由于数据量的原因,最大为 200,可以先设置为 5,便于爬取,下述代码在运行时,注意提前建立好 孔夫子 文件夹。
代码继续使用 session.get 方法,进行数据请求。
def get_detail(self, type, page): with self.session.get(url=self.url_format.format(type, page), headers=self.headers, timeout=5) as res: if res.text: with open(f"./孔夫子/{type}_{page}.html", "w+", encoding="utf-8") as f: f.write(res.text) else: # 如果无数据,重新请求 print(f"页码{page}请求异常,重新请求") self.get_detail(page) def run(self): pagesize = 5 for type in self.types: for page in range(1, pagesize): self.get_detail(type, page) time.sleep(2) print(f"分类:{type},页码:{page}页面储存完毕!")运行代码,得到如下数据,实测过程中,并未发现反爬措施,为了便于测试,可针对性控制请求速度。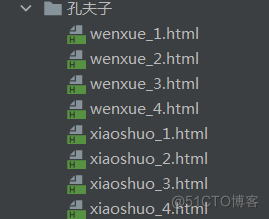
提取数据
最后对本地 HTML 进行操作,获取最终的目标数据。
在进行提取的时候,依旧是 CSS 选择器 的使用熟练程度起决定性作用,当然对于异常数据的处理,也需要注意一下。
# 数据提取类 class Analysis: def __init__(self): # 待抓取的分类,可以扩展 self.types = ["wenxue", "xiaoshuo"] # 去除特殊字符 def remove_character(self, origin_str): if origin_str is None: return origin_str = origin_str.replace('\n', '') origin_str = origin_str.replace(',', ',') return origin_str def format(self, text): html = etree.HTML(text) # 获取所有项目区域 div div_books = html.cssselect('div#listBox>div.item') for book in div_books: # 获取标题属性值 title = book.cssselect('div.item-info>div.title')[0].get('title') # 作者默认给空值 author = None author_div = book.cssselect('div.item-info>div.zl-isbn-info>span:nth-child(1)') if len(author_div)>0: author = author_div[0].text # 出版社相同操作 publisher = None publisher_div = book.cssselect('div.item-info>div.zl-isbn-info>span:nth-child(2)') if len(publisher_div)>0: # 进行数据提取与截取 publisher = publisher_div[0].text.split(' ')[1] print(publisher) def run(self): pagesize = 5 for type in self.types: for page in range(1, pagesize): with open(f"./孔夫子/{type}_{page}.html", "r", encoding="utf-8") as f: text = f.read() # print(text) self.format(text)提取过程中出现了部分异常数据,针对异常数据进行特殊化处理即可,例如下述截图数据。 学习阶段,就不再继续提取更多的数据,仅提取书名,作者和出版社。
学习阶段,就不再继续提取更多的数据,仅提取书名,作者和出版社。
收藏时间
==来都来了,不发个评论,点个赞,收个藏吗?==
【本文来自:日本服务器 http://www.558idc.com/jap.html 复制请保留原URL】