以Python 3.x版本为主 清除列表元素的特殊字符,综合运用前面学到的基础知识点 1、效果如下 2、知识点 编号 知识点 说明 1 import re 引入模块 2 list列表 保存多个值 3 for for循环,遍历列表
以Python 3.x版本为主
清除列表元素的特殊字符,综合运用前面学到的基础知识点
1、效果如下
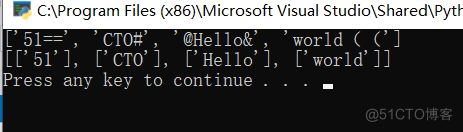
2、知识点
编号
知识点
说明
1
import re
引入模块
2
list列表
保存多个值
3
for
for循环,遍历列表
4
split
以默认空格进行分组
5
def
自定义函数方法
6
findall
正则表达式匹配,过滤返回值,参数有re.S,不会对\n进行中断
2.1、re模块
python独有的匹配字符串的模块,提供的很多功能是基于正则表达式实现的,而正则表达式是对字符串进行模糊匹配,提取自己需要的字符串部分,正则表达式对所有语言都是通用的
import re,表示引入这个模块函数库,即可调用模块下面定义好的方法
2.2、list列表
列表,和数组一样,在这里的概念就是列表、序列的意思,在实际项目中,序列会经常用到,列表数据的动态添加、删除、获取等等
2.3、for循环
同样for循环在实际场景中,也会经常用到,遍历各种数据,对数据进行筛选过滤等等处理操作,同时集合List列表一起使用
2.4、split分隔
由于内置分隔方法split,本身只针对字符或字符串而言,没有模糊匹配的概念,所以这里就引入一个re模块,可通过正则表达式的方式进行模糊匹配进行分隔,动态空格分隔
2.5、def
自定义函数方法
2.6、findall
查找匹配符合的值,并返回值
3、整体代码
#!/usr/bin/python3# -*- coding: utf-8 -*-
# Apr 14, 2022 22:50 AM
import re
def special_endings(strings):
list1=[]
for i in strings:
x=i.split()
for c in x:
new_c = re.findall('[\u4e00-\u9fa5a-zA-Z0-9]+',c,re.S) #只要字符串中的中文,字母,数字
list1.append(new_c)
return list1
list=["51==","CTO#", "@Hello&","world(("]
print(list)
result=special_endings(list)
print(result)