1.环境安装 python处理Excel的方式 openpyxl 环境安装: 模块官网:openpyxl · PyPI 最新版本: pip install - U openpyxl == 3.0.7 / pip install openpyxl == 3.0.7 三方支持: pip install lxml pip install pi
1.环境安装
- python处理Excel的方式
- openpyxl
- 环境安装:
- 模块官网:openpyxl · PyPI
- 最新版本:
- 三方支持:
pip install pillow
- 首先,让我们来看一些基本定义:
- 工作簿:一个 Excel 电子表格文档称为一个工作簿,一个 工作簿保存在扩展名为.xlsx 的文件中
- sheet表:每个工作簿可以包含多个表(也称为工作表)
- 活动表:用户当前查看的表(或关闭 Excel 前最后查看的表),称为活动表
- 单元格:每个表都有一些列(地址是从 A 开始的字母)和一些行(地址是从 1 开始的数 字)。在特定行和列的方格称为单元格。每个单元格都包含一个数字或文本值。
2.读取Excel表格
实例表格如下:

用 openpyxl 模块打开 Excel 文档
#创建了一个指定的工作簿对象wb = openpyxl.load_workbook(filename='./data/test.xlsx')
获取工作簿的sheet表的名称
wb.get_sheet_names()获取指定的sheet对象
sheet = wb.get_sheet_by_name('基本信息') #sheet = wb.get_sheet_by_name('也就是某个sheet')
获取活动表
wb.get_active_sheet()- 从表中取得单元格
- 有了 Worksheet 对象后,就可以按名字访问 Cell 对象
- 属性:
- value:cell中存储的值
- row:行索引
- column:列索引
- coordinate:坐标
cell.value
cell.row
cell.column
cell.coordinate
print上述得到:
bobo2;4;1;A4
用字母来指定列,这在程序中可能有点奇怪,特别是在 Z 列之后,列开时使用 两个字母:AA、AB、AC 等。作为替代,在调用表的 cell()方法时,可以传入整数 作为 row 和 column 关键字参数,也可以得到一个单元格。第一行或第一列的整数 是 1,不是 0。
sheet.cell(row=1,column=2).value'age'
- 从工作表中取得行和列
- 可以将 Worksheet 对象进行切片操作,从而取得电子表格中一行、一列或一个矩形区域中的所有 Cell 对象。
for cell in cell_row:
print(cell.coordinate,cell.value)
- 要访问特定行或列的单元格的值,也可以利用 Worksheet 对象的 rows 和 columns属性。
#第一列
(<Cell 基本信息.A1>,
<Cell 基本信息.A2>,
<Cell 基本信息.A3>,
<Cell 基本信息.A4>,
<Cell 基本信息.A5>,
<Cell 基本信息.A6>,
<Cell 基本信息.A7>)
for cell in list(sheet.columns)[0]:
print(cell.value)
name
bobo
bobo1
bobo2
bobo3
bobo4
bobo5
获取工作表中的最大行和最大列的数量
print(sheet.max_ row,sheet.max column)7 6
3.项目实战
项目:2010 年美国人口普查数据自动化处理
- 在这个项目中,你要编写一个脚本,从人口普查电子表格文件中读取数据,并在几秒钟内计算出每个县的统计值(可以根据县的名称快速计算出县的总人口和普查区的数量)。
- 下面是程序要做的事:
- 从 Excel 电子表格中读取数据。
- 计算每个县中普查区的数目。
- 计算每个县的总人口。 打印结果。
- 这意味着代码需要完成下列任务:
- 用 openpyxl 模块打开 Excel 文档并读取单元格。
- 计算所有普查区和人口数据,将它保存到一个数据结构中。
- 利用 pprint 模块,将该数据结构写入一个扩展名为.py 的文本文件。
- 数据说明:
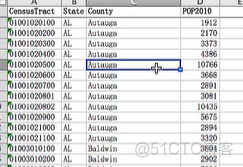
- censuspopdata.xlsx 电子表格中只有一张表,名为'Population by Census Tract'。
- 每一行都保存了一个普查区的数据。
- 列分别是普查区的编号(A),州的简称(B),县的名称(C),普查区的人口(D)。
- 注意:一个县会设定多个普查区,D列表示县中所有普查区对应每一个普查区的人口数量
- print()和pprint()都是python的打印模块,功能基本一样,唯一的区别就是pprint()模块打印出来的数据结构更加完整,每行为一个数据结构,更加方便阅读打印输出结果。特别是对于特别长的数据打印,print()输出结果都在一行,不方便查看,而pprint()采用分行打印输出,所以对于数据结构比较复杂、数据长度较长的数据,适合采用pprint()打印方式。当然,一般情况多数采用print()。
countyData结构:【构建要求形式】

如果前面的字典保存在 countyData 中,下面的表达式求值结果如下:

代码:openpyxl 2.x版本
import openpyxl, pprintprint('Opening workbook...')
wb = openpyxl.load_workbook('data/censuspopdata.xlsx')
sheet = wb.get_sheet_by_name('Population by Census Tract') #sheet[0]
#countyData将包含你计算的每个县的总人口和普查区数目。但在它里面存储任何东西之前,你应该确定它内部的数据结构。
countyData = {}
print('Reading rows...')
for row in range(2, sheet.get_highest_row() + 1): #sheet.get_highest_row() 获取最大行数
state = sheet['B' + str(row)].value #获取值
county = sheet['C' + str(row)].value
pop = sheet['D' + str(row)].value
countyData.setdefault(state, {}) #{state:{}} #setdefault给字典添加键值
#在给后续添加键值
countyData[state].setdefault(county, {'tracts': 0, 'pop': 0}) #{state:{county:{'tracts': 0, 'pop': 0}}}
countyData[state][county]['tracts'] += 1
countyData[state][county]['pop'] += int(pop)
print('Writing results...')
#写入py文件
resultFile = open('census2010.py', 'w')
#使用 pprint.pformat()函数,将变量字典的值作为一个巨大的字符串, 写入文件 census2010.py
resultFile.write('allData = ' + pprint.pformat(countyData))
resultFile.close()
print('Done.')Opening workbook...
Reading rows...
Writing results...
Done.
将countyData输出到文本文件 census2010.py,你就通过 Python 程序生成了一个 Python 程序!这样做的好处是现在可以导入 census2010.py,就像任何其他 Python 模块一样。
import osimport census2010
#查看AK州Anchorage县的人口普查数据
census2010.allData['AK']['Anchorage']
{'pop': 291826, 'tracts': 55}
#增加可读性:
anchoragePop = census2010.allData['AK']['Anchorage']['pop']
print('The 2010 population of Anchorage was ' + str(anchoragePop))
The 2010 population of Anchorage was 291826
openpyxl 3.0版本以上版本升级书写简介点:
import openpyxl, pprintprint('Opening workbook...')
wb = openpyxl.load_workbook('data/censuspopdata.xlsx')
#sheet = wb.get_sheet_by_name('Population by Census Tract') #sheet[0]
sheet = wb['Population by Census Tract']
#countyData将包含你计算的每个县的总人口和普查区数目。但在它里面存储任何东西之前,你应该确定它内部的数据结构。
countyData = {}
print('Reading rows...')
#for row in range(2, sheet.get_highest_row() + 1): #sheet.get_highest_row() 获取最大行数
for row in range(2, sheet.max_row + 1): #新版本只能sheet.max_row获取最大化
state = sheet['B' + str(row)].value #获取值
county = sheet['C' + str(row)].value
pop = sheet['D' + str(row)].value
countyData.setdefault(state, {}) #{state:{}} #setdefault给字典添加键值
#在给后续添加键值
countyData[state].setdefault(county, {'tracts': 0, 'pop': 0}) #{state:{county:{'tracts': 0, 'pop': 0}}}
countyData[state][county]['tracts'] += 1
countyData[state][county]['pop'] += int(pop)
print('Writing results...')
#写入py文件
resultFile = open('census2010.py', 'w')
#使用 pprint.pformat()函数,将变量字典的值作为一个巨大的字符串, 写入文件 census2010.py
resultFile.write('allData = ' + pprint.pformat(countyData))
resultFile.close()
print('Done.')