前言
犹豫了几天,看了很多大牛写的关于c语言链表,感触很多,终于下定决心,把自己对于链表的理解随之附上,可用与否,自行裁夺。由于作者水平有限也是第一次写,不足之处,竭诚希望得到各位大神的批评指正。制作不易,不喜勿喷,谢谢!!!
在正文开始之前,我先对数组和链表进行简单的对比分析。
链表也是一种很常见的数据结构,不同于数组的是它是动态进行存储分配的一种结构。数组存放数据时,必须要事先知道元素的个数。举个例子,比如一个班有40个人,另一个班有100个人,如果要用同一个数组先后来存放这两个班的学生数据,那么必须得定义长度为100的数组。如果事先不确定一个班的人数,只能把数组定义的足够大,以能存放任何班级的学生数据。这样就很浪费内存,而且数组对于内存的要求必须是是连续的,数据小的话还好说,数据大的话内存分配就会失败,数组定义当然也就失败。还有数组对于插入以及删除元素的效率也很低这就不一一介绍了。然而链表就相对于比较完美,它很好的解决了数组存在的那些问题。它储存数据时就不需要分配连续的空间,对于元素的插入以及删除效率就很高。可以说链表对于内存就是随用随拿,不像数组要事先申请。当然,有优点就必然有缺点,就比如说链表里每一个元素里面都多包含一个地址,或者说多包含一个存放地址的指针变量,所以内存开销就很大。还有因为链表的内存空间不是连续的,所以想找到其中的某一个数据就没有数组那么方便,必须先得到该元素的上一个元素,根据上一个元素提供的下一元素地址去找到该元素。所以不提供“头指针”(下文中“头指针”为“PHead”),那么整个链表将无法访问。链表就相当于一条铁链一环扣一环(这个稍后会详细的说)。
链表
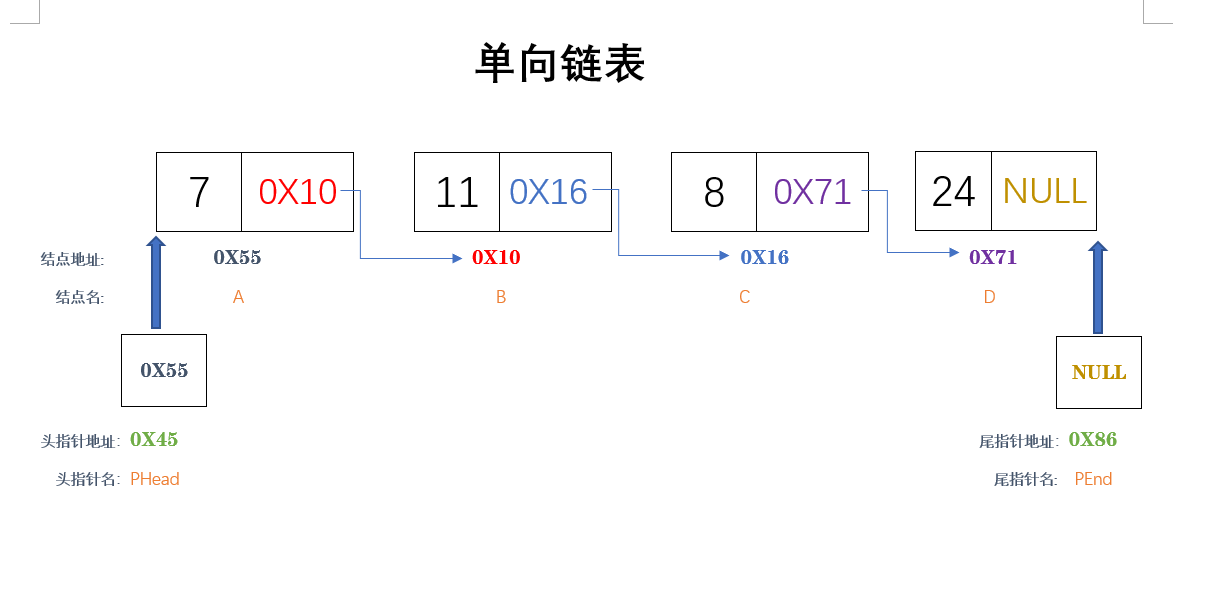
上面我提到过链表是动态进行存储分配的一种结构。链表中的每一个元素称为“结点”,每个结点都包括两部分:一部分为用户需要的实际数据,另一部分为下一结点的地址。链表有一个“头指针(PHead)”变量,存放着一个地址,该地址指向第一个结点,第一个结点里面存放着第二个结点的地址,第二个结点又存放着第三个结点地址。就这样头指针指向第一个结点,第一个结点又指向第二个......直到最后一个结点。最后一个结点不再指向其他结点,地址部分存放一个“NULL”。 见下图:(表中有一个尾指针(PEnd)其作用后面会解释)
c语言单项链表尾添加整体代码如下:(详解附后)
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
//函数声明
//尾添加
void wei_tian_jia(struct NODE** PHEAD, struct NODE** PEND, int shu_ju);
//尾添加(没有尾指针)
void wei_tian_jia_(struct NODE** PHEAD, int shu_ju);
//释放链表
void shi_fang_lian_biao(struct NODE* PHEAD);
//释放链表(并是头指针(PHead)尾指针(PEnd)指向空)
void shi_fang_lian_biao_free(struct NODE** PHEAD, struct NODE** PEnd);
//输出链表
void shu_chu(struct NODE* PHEAD);
//定义一个链表结构体
struct NODE
{
int shu_ju; //用户需要的实际数据
struct NODE* PNext; //下一结点的地址
};
int main(void)
{
//创建头尾指针
struct NODE* PHead = NULL;
struct NODE* PEnd = NULL;
//尾添加
wei_tian_jia(&PHead, &PEnd, 17);
wei_tian_jia(&PHead, &PEnd, 21);
wei_tian_jia(&PHead, &PEnd, 34);
wei_tian_jia(&PHead, &PEnd, 8);
wei_tian_jia(&PHead, &PEnd, 24);
//尾添加(没有尾指针)
//wei_tian_jia_(&PHead, 23);
//wei_tian_jia_(&PHead, 17);
//wei_tian_jia_(&PHead, 11);
//输出链表
shu_chu(PHead);
//释放链表
//shi_fang_lian_biao(PHead);
//释放链表(并是头指针(PHead)尾指针(PEnd)指向空)
shi_fang_lian_biao_free(&PHead, &PEnd);
system("pause");
return 0;
}
//尾添加
void wei_tian_jia(struct NODE** PHEAD, struct NODE** PEND, int SHU_JU)
{
//创建结点
struct NODE* PTEMP = (struct NODE*)malloc(sizeof(struct NODE));
if (PTEMP != NULL)
{
//节点赋值
PTEMP->shu_ju = SHU_JU;
PTEMP->PNext = NULL;
//把结点连起来
if (NULL == *PHEAD) // 因为PHEAD如果是NULL的话 PEND也就是NULL 所以条件里面不必要写
{
*PHEAD = PTEMP;
*PEND = PTEMP;
}
else
{
(*PEND)->PNext = PTEMP;
*PEND = PTEMP;
}
}
}
//尾添加(没有尾指针)
void wei_tian_jia_(struct NODE** PHEAD1, int SHU_JU)
{
//创建结点
struct NODE* PTEMP = (struct NODE*)malloc(sizeof(struct NODE));
if (PTEMP != NULL)
{
//结点成员赋值
PTEMP->shu_ju = SHU_JU;
PTEMP->PNext = NULL;
//把结点连一起
if (NULL == *PHEAD1)
{
*PHEAD1 = PTEMP;
}
else
{
struct NODE* PTEMP2 = *PHEAD1;
while (PTEMP2->PNext != NULL)
{
PTEMP2 = PTEMP2->PNext;
}
PTEMP2->PNext = PTEMP;
}
}
}
//输出链表
void shu_chu(struct NODE* PHEAD)
{
while (PHEAD != NULL)
{
printf("%d\n", PHEAD->shu_ju);
PHEAD = PHEAD->PNext;
}
}
//释放链表
void shi_fang_lian_biao(struct NODE* PHEAD)
{
struct NODE* P = PHEAD;
while (PHEAD != NULL)
{
struct NODE* PTEMP = P;
P = P->PNext;
free(PTEMP);
}
free(PHEAD);
}
//释放链表(并是头指针(PHead)尾指针(PEnd)指向空)
void shi_fang_lian_biao_free(struct NODE** PHEAD, struct NODE** PEnd)
{
while (*PHEAD != NULL)
{
struct NODE* PTEMP = *PHEAD;
*PHEAD = (*PHEAD)->PNext;
free(PTEMP);
}
*PHEAD = NULL;
*PHEAD = NULL;
}
部分代码详解:(再次申明:由于作者水平有限,所以有的变量名用的拼音。见笑,莫怪!!!为了简单明了,方便起见,我定义了一个实际数据。)

“头指针”(PHead)以及“尾指针”(PEnd):

头指针很好理解指向首结点用于遍历整个数组,而尾指针呢?我们先看下面两段代码一段是有尾指针的一段是没有尾指针的:
//尾添加
void wei_tian_jia(struct NODE** PHEAD, struct NODE** PEND, int SHU_JU)
{
//创建一个结点
struct NODE* PTEMP = (struct NODE*)malloc(sizeof(struct NODE));
if (PTEMP != NULL)
{
//节点成员赋值(一定要每个成员都要赋值)
PTEMP->shu_ju = SHU_JU;
PTEMP->PNext = NULL;
//把结点连起来
if (NULL == *PHEAD) // 因为PHEAD如果是NULL的话 PEND也就是NULL 所以条件里面不必要写
{
*PHEAD = PTEMP;
*PEND = PTEMP;
}
else
{
//把尾指针向后移
(*PEND)->PNext = PTEMP;
*PEND = PTEMP;
}
}
}
那么下面这段代码是没有尾指针的。它的思想就是头指针一直指向第一个结点,然后通过遍历来找到最后一个结点,从而使最后一个结点里面的指针指向所要插入的元素。
//尾添加(没有尾指针)
void wei_tian_jia_(struct NODE** PHEAD1, int SHU_JU)
{
//创建结点
struct NODE* PTEMP = (struct NODE*)malloc(sizeof(struct NODE));
if (PTEMP != NULL)
{
//结点成员赋值
PTEMP->shu_ju = SHU_JU;
PTEMP->PNext = NULL;
//把结点连一起
if (NULL == *PHEAD1)
{
*PHEAD1 = PTEMP;
}
else
{
struct NODE* PTEMP2 = *PHEAD1;
while (PTEMP2->PNext != NULL)
{
PTEMP2 = PTEMP2->PNext;
}
PTEMP2->PNext = PTEMP;
}
}
}
我把上面代码里面的一段摘出来说明一下。
这段代码里面可以看到我又定义了一个PTEMP2指针变量,为什么呢?前面我提到过没有尾指针的时候添加结点的思想就是要遍历数组,从而找到最后一个结点然后让它指向我们要插入的结点,如果没有这个PHEAD2,我们遍历完链表以后我们的头指针PHEAD1就已经指向了最后一个结点了,单项链表如果头指针移动了,数据就会找不到了。所以我定义了一个中间变量装着头指针然后去遍历链表,让头指针永远指向链表的头。
else
{
struct NODE* PTEMP2 = *PHEAD1;
while (PTEMP2->PNext != NULL)
{
PTEMP2 = PTEMP2->PNext;
}
PTEMP2->PNext = PTEMP;
}
可以看到有尾指针的代码和没有尾指针的代码里面,有尾指针的链表里面我每次添加完数据都让尾指针指向最后一个结点,然后通过尾指针来添加数据。而没有尾指针的链表里面每次添加数据都要通过循环来遍历链表找到最后一个结点然后指向所添加的结点。如果一个链表里面有几万个结点,每次都通过循环遍历链表来添加数据,那么速度就相对于有尾指针的链表慢很多。总而言之,还是看个人爱好吧。不管黑猫还是白猫能抓到耗子都是好猫。
总结
到此这篇关于c语言单链表尾添加的文章就介绍到这了,更多相关c语言单链表尾添加内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!