教程翻译自Seastar官方文档:https://www.scylladb.com/2018/06/12/scylla-leverages-control-theory/
转载请注明出处:https://www.cnblogs.com/morningli/p/16170046.html
从鸟瞰的角度来看,数据库的任务很简单:用户插入一些数据,然后再获取它。但是当我们仔细观察时,事情变得更加复杂。例如,为了持久性,数据需要进入提交日志,需要被索引,并且被多次重写以便可以轻松获取。
所有这些任务都是数据库的内部进程,它们将争夺有限的资源,如 CPU、磁盘和网络带宽。然而,授予其中一个或另一个特权的回报并不总是很清楚。这种内部过程的一个例子是 compactions,这是任何具有基于日志结构化合并 (LSM) 树的存储层的数据库中的一个事实,比如 ScyllaDB。
LSM 树由源自数据库写入的append-only的不可变文件组成。随着写入的不断发生,系统可能会变成相同的key的数据会出现在许多不同的文件中,这使得读取非常昂贵。然后,这些文件根据用户选择的压缩策略在后台由 compaction process 进行压缩。如果我们花费更少的资源来压缩现有文件,我们可能能够实现更快的写入速率。但是,读取将受到影响,因为它们现在需要访问更多文件。
设置用于压缩的资源量的最佳方法是什么?一个不太理想的选择是以可调参数的形式将决定推给用户。然后,用户可以在配置文件中选择专用于压缩的带宽。然后,用户负责trial-and-error 调试周期来尝试为匹配的工作负载找到正确的数字。
在 ScyllaDB,我们认为这种方法是脆弱的。手动调优对工作负载的变化没有弹性,其中许多变化是无法预料的。资源稀缺时峰值负载的最佳速率可能不是集群非工作时间(资源充足时)的最佳速率。但是,即使调优周期确实能以某种方式找到一个好的速率,该过程也会显著增加操作数据库的成本。
在本文中,我们将讨论 ScyllaDB 规定的解决此问题的方法。我们借鉴了工业控制器的数学框架,以确保压缩带宽自动设置为合适的值,同时保持可预测的系统响应。
控制系统入门虽然我们无法通过查看系统神奇地确定最佳压缩带宽,但我们可以设置希望数据库遵守的用户可见行为。一旦我们这样做了,我们就可以使用控制理论来确保所有部分以指定的速率协同工作,从而实现所需的行为。这种系统的一个例子是汽车的巡航控制。虽然不可能猜测每个部分的单独设置会结合起来使汽车以所需的速度行驶,但我们可以简单地设置汽车的巡航速度,然后期望各个部分进行调整以实现这一目标。
特别是,我们将在本文中关注闭环控制系统——尽管我们也在 ScyllaDB 中使用开环控制系统。对于闭环控制系统,我们有一个被控制的过程和一个执行器,它负责将输出移动到特定状态。期望状态和当前状态之间的差异称为误差,它会反馈给输入。因此,闭环控制系统也称为反馈控制系统。
让我们看另一个真实世界闭环控制系统的例子:我们希望水箱中的水处于或接近某个水位,我们将有一个阀门作为执行器,当前水位之间的差异所需的水平是错误。控制器将打开或关闭阀门,以便更多或更少的水从水箱中流出。阀门应该打开多少取决于控制器的传递函数。图 1 显示了这个一般概念的简单图表。

图 1:工业控制器,控制水箱中的水位。测量电流电平并将其馈送到反馈回路控制器。基于此,执行器将调整水箱中的水流量。像这样的系统通常用于工业厂房。我们也可以利用这些知识来控制数据库进程。
拼图:调度器和积压控制器在 ScyllaDB 中,我们控制流程的基础是嵌入在数据库中的调度程序。我们在一篇由三部分组成的文章(第 1部分、第 2部分和第 3 部分)中广泛讨论了其中最早的 I/O 调度程序。调度程序作为控制系统中的执行器工作。通过增加某个组件的份额,我们提高了该过程的执行速度——类似于图 1 中允许更多(或更少)流体通过的阀门。ScyllaDB 还嵌入了一个 CPU Scheduler,它对每个数据库内部进程使用的 CPU 量起着类似的作用。
要设计我们的控制器,首先要提醒自己压缩的目标是很重要的。拥有大量未压缩的数据会导致读取到读取放大和空间放大。我们有读取放大,因为每次读取操作都必须从许多 SSTable 中读取,以及空间放大,因为重叠数据将被复制很多次。我们的目标是摆脱这种放大。
然后,我们可以定义一个衡量标准,即要使系统达到零放大状态还需要做多少工作。我们称之为backlog。每当x新字节写入系统时,我们都会在未来生成ƒ(x)字节的backlog。请注意, x和ƒ(x)之间没有一对一的关系,因为我们可能必须多次重写数据才能达到零放大状态。当 backlog为零时,一切都被完全压缩,没有读取或空间放大。
不同的工作负载具有不同的稳态带宽。我们的控制法将为他们解决不同的 backlog 措施;高带宽工作负载将比低带宽工作负载拥有更高的 backlog 。这是一个理想的属性:较高的 backlog 为覆盖留下了更多的机会(这减少了写入放大的总量),而低带宽写入工作负载将具有较低的 backlog,因此更少的 SSTables 和更小的读取放大。
考虑到这一点,我们可以编写一个与积压成正比的传递函数。
确定压缩积压现有 SSTable 的压缩是根据特定的压缩策略进行的,该策略选择哪些 SSTable 必须被压缩在一起,以及应该生成哪些以及应该生成多少。每种策略都会为相同的数据做不同的工作量。这意味着没有一个单一的积压控制器——每个压缩策略都必须定义自己的。ScyllaDB 支持大小分层压缩策略 (STCS)、分级压缩策略 (LCS)、时间窗口压缩策略 (TWCS) 和日期分层压缩策略 (DTCS)。
在本文中,我们将研究用于控制默认压缩策略的积压控制器,即 Size Tiered Compaction Strategy。STCS 在上一篇文章中有详细描述。快速回顾一下,STCS 将尝试将大小相似的 SSTable 压缩在一起。如果可能的话,我们会尝试等到创建 4 个大小相似的 SSTable 并对其进行压缩。当我们压缩相似大小的 SSTables 时,我们可能会创建更大的 SSTables,这些 SSTables 将属于下一层。
为了设计 STCS 的 backlog 控制器,我们从一些观察开始。第一个是当所有的 SSTable 被压缩成一个 SSTable 时,积压为零,因为没有更多的工作要做。由于积压是对该过程仍有待完成的工作的衡量,因此这是从积压的定义中得出的。 第二个观察是 SSTables 越大,积压越大。这也很容易直观地看到。在系统上压缩 2 个 1MB 的 SSTable 应该比压缩 2 个 1TB 的 SSTable 容易得多。 第三个也是更有趣的观察是,积压必须与特定 SSTable 在完全压缩之前仍必须通过的层数成正比。如果只有一个层,我们将不得不使用该层中的所有 SSTable 压缩当前正在写入的传入数据。如果有两层,我们将压缩第一层,但随后必须压缩该层中存在的每个字节——即使是那些已经在以前的 SSTables 中密封到另一层的字节。图 2 显示在实践中。当我们编写一个新的 SSTable 时,我们正在创建一个未来的 backlog,因为新的 SSTable 必须与其层中的那些压缩。但是如果有第二层,那么最终会有第二次压缩,backlog 必须考虑到这一点。
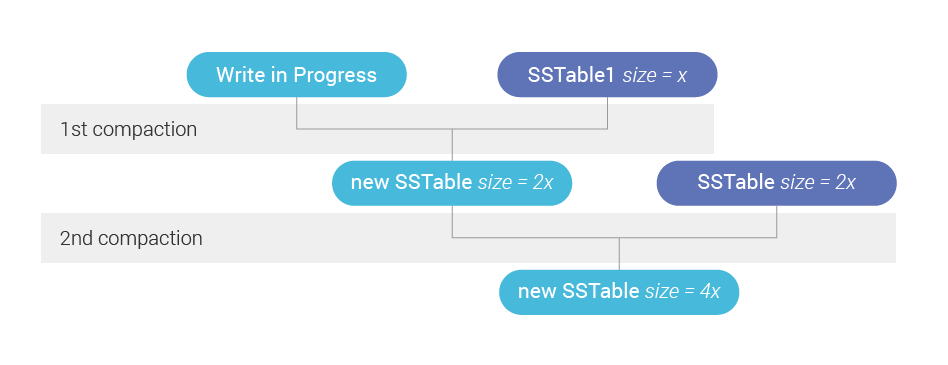 图 2:在写入新的 SSTable 时,系统中已经存在蓝色的 SSTable。因为那些现有的 SSTable 存在于两个不同的 Size Tier 中,所以新的 SSTable 创建的未来积压工作大约是我们只有一个层的两倍——因为我们将不得不进行两次压缩而不是一次。
请注意,这不仅对由于数据从内存中刷新而正在写入的 SSTable 有效,对于由于其他压缩从更早的 tiers 移动数据而被写入的 SSTable 也有效。由先前压缩产生的表的backlog将与它仍然必须爬到最后一层的级别数成正比。
图 2:在写入新的 SSTable 时,系统中已经存在蓝色的 SSTable。因为那些现有的 SSTable 存在于两个不同的 Size Tier 中,所以新的 SSTable 创建的未来积压工作大约是我们只有一个层的两倍——因为我们将不得不进行两次压缩而不是一次。
请注意,这不仅对由于数据从内存中刷新而正在写入的 SSTable 有效,对于由于其他压缩从更早的 tiers 移动数据而被写入的 SSTable 也有效。由先前压缩产生的表的backlog将与它仍然必须爬到最后一层的级别数成正比。很难知道我们有多少层。这取决于很多因素,包括数据的形状。但是因为 STCS 中的层数是由 SSTable大小决定的,所以我们可以根据计算backlog的表中的总大小与特定的 SSTable的大小之间的对数关系来估计特定 SSTable 之前的层数的上限——因为这些层的大小呈指数级增长。
例如,考虑一个没有更新的恒定插入工作负载,它不断生成每个大小为 1GB 的 SSTable。它们被压缩成 4GB 大小的 SSTables,然后再被压缩成 16GB 大小的 SSTables,等等。
当前两层已满时,我们将有四个大小为 1GB 的 SSTable 和另外四个大小为 4GB 的 SSTable。总表大小为 4 * 1 + 4 * 4 = 20GB,表与 SSTable 的比率分别为 20/1 和 20/4。我们将使用以 4 为底的对数,因为有 4 个 SSTables 被压缩在一起,以产生 4 个小的 SSTables:
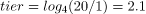
对于大的
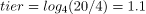
所以我们知道第一个大小为 1GB 的 SSTable 属于第一层,而大小为 4GB 的 SSTable 属于第二层。
一旦理解了这一点,我们就可以将属于特定表的任何现有 SSTable 的积压工作编写为:

其中  是 SSTable 的积压
是 SSTable 的积压 ,
, 是 SSTable 的大小
是 SSTable 的大小 。那么一个表的总积压是
。那么一个表的总积压是

为了推导出上面的公式,我们使用了系统中已经存在的 SSTables。但很容易看出它对正在写入的 SSTable 也是有效的。我们需要做的就是注意, 事实上,SSTable 的部分大小——到目前为止写入的字节数。
事实上,SSTable 的部分大小——到目前为止写入的字节数。
随着新数据的写入,积压会增加。但它是如何减少的?当压缩过程从现有的 SSTables 中读取字节时,它会减少。然后我们将上面的公式调整为:
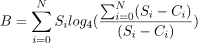
其中 是从 sstable 压缩已读取的字节数。在未进行压缩的 SSTables 中它将为 0。
是从 sstable 压缩已读取的字节数。在未进行压缩的 SSTables 中它将为 0。
请注意,当只有一个 SSTable 时 ,因为
,因为 没有积压,这与我们最初的观察结果一致。
没有积压,这与我们最初的观察结果一致。
为了在实践中看到这一点,让我们看看系统如何响应仅摄取的工作负载,我们将 1kB 的值写入固定数量的随机键,以便系统最终达到稳定状态。
我们将以最大吞吐量摄取数据,确保即使在任何压缩开始之前,系统已经使用了 100% 的资源(在这种情况下,它受到 CPU 的瓶颈),如图 3 所示。随着压缩开始,内部压缩过程使用的 CPU 时间与其份额成正比。随着时间的推移,压缩使用的 CPU 时间会增加,直到达到 15% 左右的稳定状态。压缩所花费的时间比例是固定的,系统不会出现波动。
图 4 显示了同一时期股票随时间的变化。份额与积压成正比。随着新数据的刷新和压缩,总磁盘空间围绕特定点波动。在稳定状态下,积压工作位于一个恒定的位置,我们正在以与传入写入生成新工作相同的速度压缩数据。
一个非常好的副作用如图 5 所示。ScyllaDB CPU 和 I/O 调度程序强制分配给其内部进程的份额数量,确保每个内部进程消耗与其份额的确切比例的资源。由于份额在稳定状态下是恒定的,因此服务器所看到的延迟在每个百分位都是可预测且稳定的。
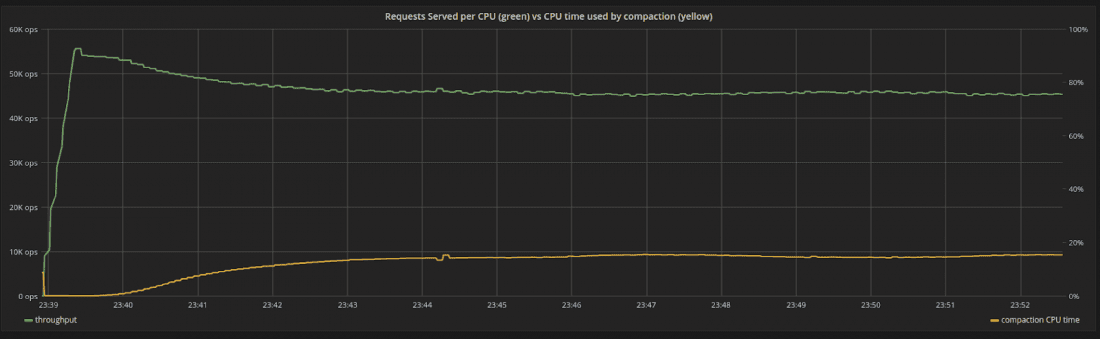
图 3:系统中 CPU 的吞吐量(绿色)与压缩使用的 CPU 时间百分比(黄色)。一开始,没有压缩。随着时间的推移,系统达到稳定状态,吞吐量稳步下降。
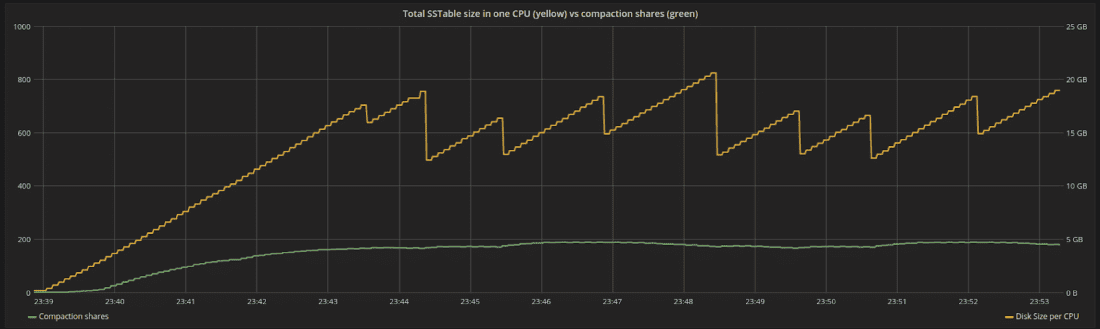
图 4:分配给系统中特定 CPU 的磁盘空间(黄色)与分配给压缩的份额(绿色)。份额与积压成正比,在某些时候将达到稳定状态

图 5:第 95、第 99 和第 99.9 个百分位延迟。即使在 100% 的资源利用率下,延迟仍然很低且有限。
一旦系统处于稳定状态一段时间,我们会突然增加每个请求的负载,从而导致系统更快地摄取数据。随着数据摄取率的增加,积压也应该增加。压缩现在必须移动更多数据。
我们可以在图 6 中看到它的影响。在新的摄取率下,系统受到干扰,因为 backlog 比以前增长得更快。但是,压实控制器会自动增加内部压实过程的份额,系统将达到新的平衡。
在图 7 中,我们重新审视了分配给压缩的 CPU 时间百分比发生了什么变化,因为工作负载发生了变化。随着请求变得更加昂贵,请求/秒的吞吐量自然会下降。但是,除此之外,更大的有效载荷将导致压缩积压更快地积累。压缩使用的 CPU 百分比会增加,直到达到新的平衡。吞吐量的总下降是这两种影响的结合。
有了更多的份额,压缩现在使用更多的系统资源、磁盘带宽和 CPU。但是股票的数量是稳定的,没有大范围的波动导致可预测的结果。这可以通过图 8 中的延迟行为观察到。工作负载仍然受 CPU 限制。现在可用于处理请求的 CPU 较少,因为有更多的 CPU 用于压缩。但是由于份额的变化是平滑的,所以延迟的变化也是如此。
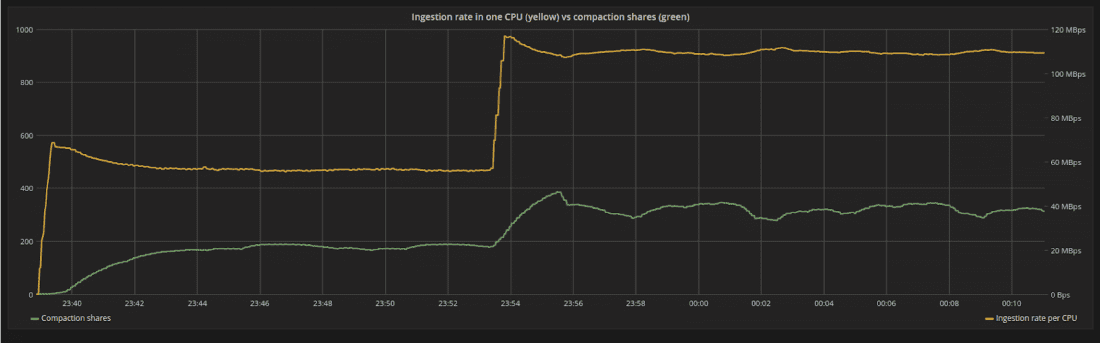
图 6:随着每个请求的负载大小增加,摄取速率(黄线)突然从 55MB/s 增加到 110MB/s。系统从其稳态位置受到干扰,但会为积压找到新的平衡(绿线)。
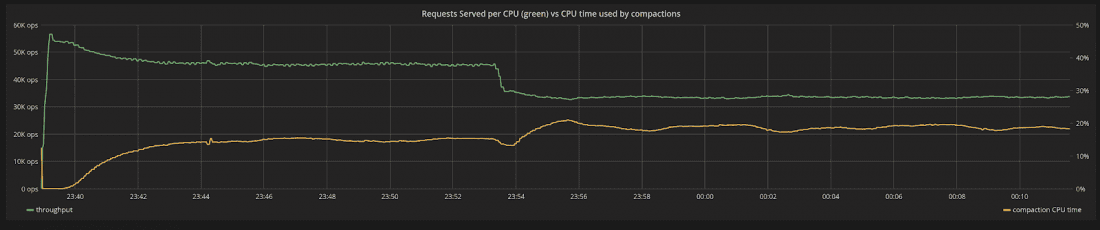
图 7:随着工作负载的变化,系统中 CPU 的吞吐量(绿色)与压缩使用的 CPU 时间百分比(黄色)。随着请求变得更加昂贵,请求/秒的吞吐量自然会下降。除此之外,更大的有效载荷将导致压缩积压更快地积累。压缩使用的 CPU 百分比增加。
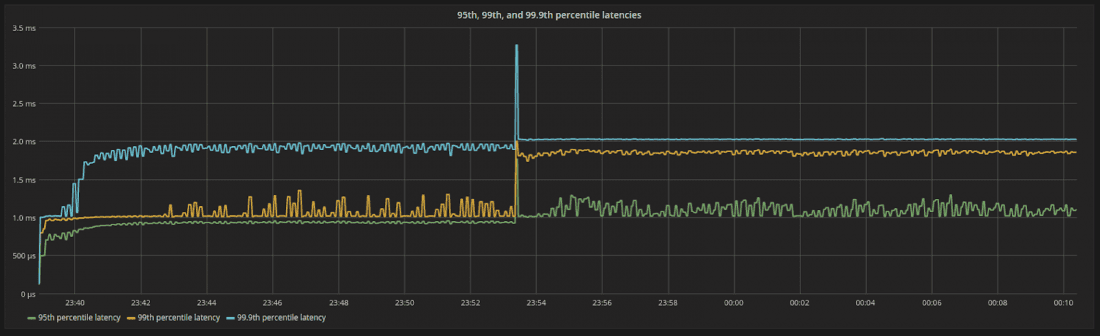
图 8:负载增加后的第 95、99 和 99.9 个百分位延迟。延迟仍然是有限的并且以可预测的方式移动。这是系统中所有内部进程以稳定速率运行的一个很好的副作用。
结论在任何给定时刻,像 ScyllaDB 这样的数据库都必须兼顾前台请求的准入和压缩等后台进程,确保传入的工作负载不会受到压缩的严重干扰,也不会因为压缩积压太大而导致以后的读取受到惩罚。
在本文中,我们展示了调度程序可以实现传入写入和压缩之间的隔离,但数据库仍然需要确定传入写入和压缩将使用的资源份额数量。
ScyllaDB 在此任务中避开了用户定义的可调参数,因为它们将操作的负担转移给了用户,使操作复杂化并且对于不断变化的工作负载很脆弱。通过借鉴工业控制器强大的理论背景,我们可以提供一个自治数据库,无需操作员干预即可适应不断变化的工作负载。
提醒一下,ScyllaDB 2.2 指日可待,它将随大小分层压缩策略的 Memtable Flush 控制器和压缩控制器一起提供。所有压缩策略的控制器很快就会出现。