首先 bert ber_wwm rabert 等模型没有解决对比学习的一些问题 在这里不提了
SimCSE等对比学习方法到底在解决什么问题?
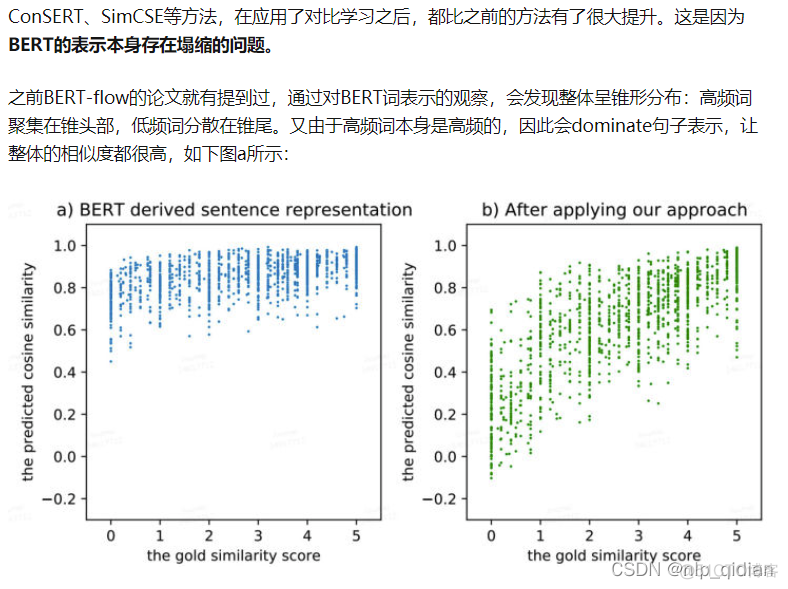
它是通过拉近相同样本的距离、拉远不同样本的距离,来刻画样本本身的表示,正好可以解决BERT表示的塌缩问题。
ESimCSE
在语义文本相似性(STS)任务上效果竟然还真的优于BERT base版的SimCSE有2个点(Spearman相关系数),并且提出了两大优化方法,解决了SimCSE遗留的两个问题:
1、SimCSE通过dropout构建的正例对包含相同长度的信息(原因:Transformer的Position Embedding),会使模型倾向于认为相同或相似长度的句子在语义上更相似(insight很合理);
2、更大的batch size会导致SimCSE性能下降(这点确实很困扰);
所以从以上可以看出,ESimCSE并没有使用最小的数据增强方法dropout构建正例对(毕竟有利也有弊哈),并且还扩展了负例对的构建,鼓励模型进行更精细的学习。这点SimCSE并没有考虑,而是直接将一个batch内与自己不同的样本都作为负样本了。
SimCSE的缺点1
在讲解ESimCSE之前,我们一定要搞清楚SimCSE的缺点以及作者的intuition是如何产生的。
使用 dropout 作为最小数据增强方法简单有效,但是预训练语言模型如BERT是建立在Transformer上,它将通过position embedding对句子的长度信息进行编码。因此,同一个句子通过BERT产生的正例对具有相同的长度,而来自两个不同句子的负例对通常包含不同长度的信息。因此,正例对和负例对所包含的长度信息是不同的,可以作为特征来区分它们。具体来说,由于这样的差异,会导致模型训练时出现偏差,让模型自动认为相同或相似长度的两个句子在语义上更相似
为了缓解这个问题,ESimCSE提出一种简单但有效的样本增强方法。对于每个正例对,我们期望在不改变其语义的情况下改变句子的长度。现有的改变句子长度的方法一般采用随机插入和随机删除。但是,在句子中插入随机选择的词可能会引入额外的噪音,这可能会扭曲句子的含义;从句子中删除关键字也会大大改变其语义。因此,我们提出了一种更安全的方法,称为“Word Repetition”,它随机复制句子中的一些单词,例子:
原句翻译为“我喜欢这个苹果,因为它看起来很新鲜,我认为它应该很好吃”。
随机插入可能会产生“我不喜欢这个苹果,因为它看起来很不新鲜,我认为它应该是狗的美味”;随机删除可能会产生“我这个苹果,因为它看起来如此,我认为它应该如此”。两者都偏离了原句的意思。
相反,“Word Repetition”的方法可能会得到“我喜欢这个苹果,因为它看起来很新鲜,我认为它应该很好吃。”或“我喜欢这个苹果,因为它看起来很新鲜”我认为它应该很好吃。”两者都很好地保持了原句的意思。
SimCSE的缺点2
由于对比学习是在正例对和负例对之间进行的,理论上更多的负例对可以导致更好的比较。因此一个潜在的优化方向是利用更多的负例对,鼓励模型进行更精细的学习。然而在SimCSE中,更大的batch size并不总是更好的选择。例如,如下图所示, 对于无监督的SimCSE-BERTbase模型,最佳batch size大小为 64,batch size大小的其他设置会降低性能。
为了缓解这个问题,ESimCSE 提出Momentun Contrast(动量对比)允许我们通过维护固定大小的队列来重用来自紧邻的前面mini-batch中编码的句子Embedding。具体来说,队列中的Embedding会被逐步替换。若当前mini-batch中输出句子的Embedding入队时,如果队列已满,则删除队列中“最旧”的句子Embedding。
ESimCSE代码:
import nlp_basictasksimport os,json
import numpy as np
import torch
import torch.nn as nn
import random
from tqdm.autonotebook import tqdm, trange
from torch.utils.data import DataLoader
from nlp_basictasks.modules import SBERT
from nlp_basictasks.modules.transformers import BertTokenizer,BertModel,BertConfig
from nlp_basictasks.readers.sts import InputExample,convert_examples_to_features,getExamples,convert_sentences_to_features
from nlp_basictasks.modules.utils import get_optimizer,get_scheduler
from nlp_basictasks.Trainer import Trainer
from nlp_basictasks.evaluation import stsEvaluator
from sentence_transformers import SentenceTransformer,models
model_path='chinese-roberta-wwm/'
tokenizer=BertTokenizer.from_pretrained(model_path)
max_seq_len=64
batch_size=128
#数据集来源:https://github.com/pluto-junzeng/CNSD
train_file='cnsd-sts-train.txt'
dev_file='cnsd-sts-dev.txt'
test_file='cnsd-sts-test.txt'
def read_data(file_path):
sentences=[]
labels=[]
with open(file_path) as f:
lines=f.readlines()
for line in lines:
line_split=line.strip().split('||')
sentences.append([line_split[1],line_split[2]])
labels.append(line_split[3])
return sentences,labels
train_sentences,train_labels=read_data(train_file)
dev_sentences,dev_labels=read_data(dev_file)
test_sentences,test_labels=read_data(test_file)
print(train_sentences[:2],train_labels[:2])
print(dev_sentences[:2],dev_labels[:2])
print(test_sentences[:2],test_labels[:2])
train_sentences=[sentence[0] for sentence in train_sentences]#无监督形式
print(len(train_sentences))
print(train_sentences[:3])
train_examples=[InputExample(text_list=[sentence,sentence],label=1) for sentence in train_sentences]
train_dataloader=DataLoader(train_examples,shuffle=True,batch_size=batch_size)
def smart_batching_collate(batch):
features_of_a,features_of_b,labels=convert_examples_to_features(examples=batch,tokenizer=tokenizer,max_seq_len=max_seq_len)
return features_of_a,features_of_b,labels
train_dataloader.collate_fn=smart_batching_collate
print(train_examples[0])
#dev_sentences=[example.text_list for example in dev_examples]
#dev_labels=[example.label for example in dev_examples]
print(dev_sentences[0],dev_labels[0])
sentences1_list=[sen[0] for sen in dev_sentences]
sentences2_list=[sen[1] for sen in dev_sentences]
dev_labels=[int(score) for score in dev_labels]
evaluator=stsEvaluator(sentences1=sentences1_list,sentences2=sentences2_list,batch_size=64,write_csv=True,scores=dev_labels)
from queue import Queue
class ESimCSE(nn.Module):
def __init__(self,
bert_model_path,
q_size=256,
dup_rate=0.32,
is_sbert_model=True,
temperature=0.05,
is_distilbert=False,
gamma=0.99,
device='cpu'):
super(ESimCSE,self).__init__()
if is_sbert_model:
self.encoder=SentenceTransformer(model_name_or_path=bert_model_path,device=device)
self.moco_encoder=SentenceTransformer(model_name_or_path=bert_model_path,device=device)
else:
word_embedding_model = models.Transformer(bert_model_path, max_seq_length=max_seq_len)
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
self.encoder=SentenceTransformer(modules=[word_embedding_model, pooling_model],device=device)
self.moco_encoder=SentenceTransformer(modules=[word_embedding_model, pooling_model],device=device)
self.gamma=gamma
self.q=[]
self.q_size=q_size
self.dup_rate=dup_rate
self.temperature=temperature
self.is_distilbert=is_distilbert#蒸馏版本的BERT不支持token_type_ids
def cal_cos_sim(self,embeddings1,embeddings2):
embeddings1_norm=torch.nn.functional.normalize(embeddings1,p=2,dim=1)
embeddings2_norm=torch.nn.functional.normalize(embeddings2,p=2,dim=1)
return torch.mm(embeddings1_norm,embeddings2_norm.transpose(0,1))#(batch_size,batch_size)
def word_repetition(self,sentence_feature):
input_ids, attention_mask, token_type_ids=sentence_feature['input_ids'].cpu().tolist(),sentence_feature['attention_mask'].cpu().tolist(),sentence_feature['token_type_ids'].cpu().tolist()
bsz, seq_len = len(input_ids),len(input_ids[0])
#print(bsz,seq_len)
repetitied_input_ids=[]
repetitied_attention_mask=[]
repetitied_token_type_ids=[]
rep_seq_len=seq_len
for bsz_id in range(bsz):
sample_mask = attention_mask[bsz_id]
actual_len = sum(sample_mask)
cur_input_id=input_ids[bsz_id]
dup_len=random.randint(a=0,b=max(2,int(self.dup_rate*actual_len)))
dup_word_index=random.sample(list(range(1,actual_len)),k=dup_len)
r_input_id=[]
r_attention_mask=[]
r_token_type_ids=[]
for index,word_id in enumerate(cur_input_id):
if index in dup_word_index:
r_input_id.append(word_id)
r_attention_mask.append(sample_mask[index])
r_token_type_ids.append(token_type_ids[bsz_id][index])
r_input_id.append(word_id)
r_attention_mask.append(sample_mask[index])
r_token_type_ids.append(token_type_ids[bsz_id][index])
after_dup_len=len(r_input_id)
#assert after_dup_len==actual_len+dup_len
repetitied_input_ids.append(r_input_id)#+rest_input_ids)
repetitied_attention_mask.append(r_attention_mask)#+rest_attention_mask)
repetitied_token_type_ids.append(r_token_type_ids)#+rest_token_type_ids)
assert after_dup_len==dup_len+seq_len
if after_dup_len>rep_seq_len:
rep_seq_len=after_dup_len
for i in range(bsz):
after_dup_len=len(repetitied_input_ids[i])
pad_len=rep_seq_len-after_dup_len
repetitied_input_ids[i]+=[0]*pad_len
repetitied_attention_mask[i]+=[0]*pad_len
repetitied_token_type_ids[i]+=[0]*pad_len
repetitied_input_ids=torch.LongTensor(repetitied_input_ids)
repetitied_attention_mask=torch.LongTensor(repetitied_attention_mask)
repetitied_token_type_ids=torch.LongTensor(repetitied_token_type_ids)
return {"input_ids":repetitied_input_ids,'attention_mask':repetitied_attention_mask,'token_type_ids':repetitied_token_type_ids}
def forward(self,batch_inputs):
'''
为了实现兼容,所有model的batch_inputs最后一个位置必须是labels,即使为None
get token_embeddings,cls_token_embeddings,sentence_embeddings
sentence_embeddings是经过Pooling层后concat的embedding。维度=768*k,其中k取决于pooling的策略
一般来讲,只会取一种pooling策略,要么直接cls要么mean last or mean last2 or mean first and last layer,所以sentence_embeddings的维度也是768
'''
batch1_features,batch2_features,_=batch_inputs
if self.is_distilbert:
del batch1_features['token_type_ids']
del batch2_features['token_type_ids']
batch1_embeddings=self.encoder(batch1_features)['sentence_embedding']
batch2_features=self.word_repetition(sentence_feature=batch2_features)
batch2_embeddings=self.encoder(batch2_features)['sentence_embedding']
cos_sim=self.cal_cos_sim(batch1_embeddings,batch2_embeddings)/self.temperature#(batch_size,batch_size)
batch_size=cos_sim.size(0)
assert cos_sim.size()==(batch_size,batch_size)
labels=torch.arange(batch_size).to(cos_sim.device)
negative_samples=None
if len(self.q)>0:
negative_samples=torch.vstack(self.q[:self.q_size])#(q_size,768)
if len(self.q)+batch_size>=self.q_size:
del self.q[:batch_size]
with torch.no_grad():
self.moco_encoder[0].auto_model.encoder.config.attention_probs_dropout_prob=0.0
self.moco_encoder[0].auto_model.encoder.config.hidden_dropout_prob=0.0
self.q.extend(self.moco_encoder(batch1_features)['sentence_embedding'])
if negative_samples is not None:
batch_size+=negative_samples.size(0)#(N+M)
cos_sim_with_neg=self.cal_cos_sim(batch1_embeddings,negative_samples)/self.temperature#(N,M) not (N,N) N is bsz
cos_sim=torch.cat([cos_sim,cos_sim_with_neg],dim=1)#(N,N+M)
#labels=
for encoder_param,moco_encoder_param in zip(self.encoder.parameters(),self.moco_encoder.parameters()):
moco_encoder_param.data=self.gamma*moco_encoder_param.data+(1.-self.gamma)*encoder_param.data
return nn.CrossEntropyLoss()(cos_sim,labels)
def encode(self, sentences,
batch_size: int = 32,
show_progress_bar: bool = None,
output_value: str = 'sentence_embedding',
convert_to_numpy: bool = True,
convert_to_tensor: bool = False,
device: str = None,
normalize_embeddings: bool = False):
'''
传进来的sentences只能是single_batch
'''
return self.encoder.encode(sentences=sentences,
batch_size=batch_size,
show_progress_bar=show_progress_bar,
output_value=output_value,
convert_to_numpy=convert_to_numpy,
convert_to_tensor=convert_to_tensor,
device=device,
normalize_embeddings=normalize_embeddings)
def save(self,output_path):
os.makedirs(output_path,exist_ok=True)
with open(os.path.join(output_path, 'model_param_config.json'), 'w') as fOut:
json.dump(self.get_config_dict(output_path), fOut)
self.encoder.save(output_path)
def get_config_dict(self,output_path):
'''
一定要有dict,这样才能初始化Model
'''
return {'bert_model_path':output_path,'temperature': self.temperature, 'is_distilbert': self.is_distilbert,
'q_size':self.q_size,'dup_rate':self.dup_rate,'gamma':self.gamma}
@staticmethod
def load(input_path):
with open(os.path.join(input_path, 'model_param_config.json')) as fIn:
config = json.load(fIn)
return ESimCSE(**config)
device='cpu'
esimcse=ESimCSE(bert_model_path=model_path,
is_distilbert=False,
is_sbert_model=False,
dup_rate=0.32,gamma=0.99,
device=device)
evaluator(esimcse)
epochs=5
output_path='定义想要模型保存的路径'
tensorboard_logdir=os.path.join(output_path,'log')
optimizer_type='AdamW'
scheduler='WarmupLinear'
warmup_proportion=0.1
optimizer_params={'lr': 2e-5}
weight_decay=0.01
num_train_steps = int(len(train_dataloader) * epochs)
warmup_steps = num_train_steps*warmup_proportion
optimizer = get_optimizer(model=esimcse,optimizer_type=optimizer_type,weight_decay=weight_decay,optimizer_params=optimizer_params)
scheduler = get_scheduler(optimizer, scheduler=scheduler, warmup_steps=warmup_steps, t_total=num_train_steps)
trainer=Trainer(epochs=epochs,output_path=output_path,tensorboard_logdir=tensorboard_logdir,early_stop_patience=20)
trainer.train(train_dataloader=train_dataloader,
model=esimcse,
optimizer=optimizer,
scheduler=scheduler,
evaluator=evaluator,
)