数据分析 参考python数据分析与挖掘实战-张良均著 数据探索 数据质量分析 缺失值分析 异常值分析 一致性分析 利用箱线图检验异常值,可以看出数据的分布范围大致情况,和
数据分析
参考python数据分析与挖掘实战-张良均著
数据探索
数据质量分析
- 缺失值分析
- 异常值分析
- 一致性分析
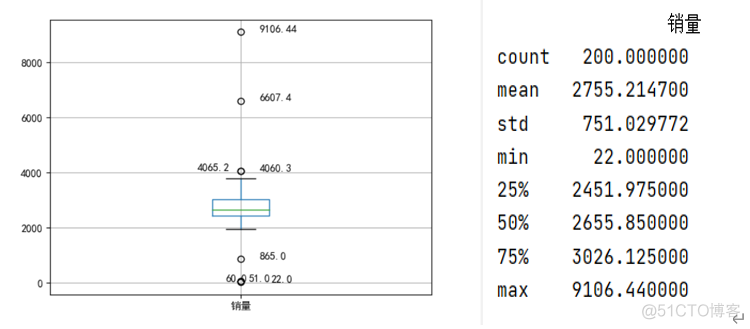
- 利用箱线图检验异常值,可以看出数据的分布范围大致情况,和1/4值、1/2值、3/4值得情况。
代码:
import pandas as pd
catering_sale = '../data/catering_sale.xls' # 餐饮数据
data = pd.read_excel(catering_sale, index_col = u'日期') # 读取数据,指定“日期”列为索引列
print(data.describe())
import matplotlib.pyplot as plt # 导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure() # 建立图像
p = data.boxplot(return_type='dict') # 画箱线图,直接使用DataFrame的方法
x = p['fliers'][0].get_xdata() # 'flies'即为异常值的标签
y = p['fliers'][0].get_ydata()
y.sort() # 从小到大排序,该方法直接改变原对象
'''
用annotate添加注释
其中有些相近的点,注解会出现重叠,难以看清,需要一些技巧来控制
以下参数都是经过调试的,需要具体问题具体调试。
'''
for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i]))
plt.show() # 展示箱线图
数据预处理阶段
数据清洗:
缺失值处理
- 3种方式:
1.删除该行数据,
2.数据插补(均值/中位数/众数插补、使用固定值、最近临插补、回归方法、插值法(拉格朗日插值法)参考地址,
3.不处理
- 3种方式:
异常值处理
- 常用方法
- 删除含有异常值的数据
- 视为缺失值
- 平均值修正
- 不处理
数据变换
- 简单函数板换(开方、平方、取对数、差分)
- 规范化
- 最大最小规范化
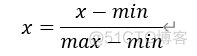
- 零-均值规范化
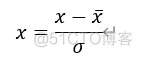 *σ原始数据标准差,
*σ原始数据标准差, - 小数定标规范化
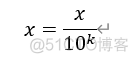
数据规范化代码
# -*- coding: utf-8 -*-import pandas as pd
import numpy as np
datafile = '../data/normalization_data.xls' # 参数初始化
data = pd.read_excel(datafile, header = None) # 读取数据
print(data)
(data - data.min()) / (data.max() - data.min()) # 最小-最大规范化
(data - data.mean()) / data.std() # 零-均值规范化
data / 10 ** np.ceil(np.log10(data.abs().max())) # 小数定标规范化
数据属性规约
- 常用方法:决策树归纳、主成分分析
主成分分析PCA代码主要作用降维
import pandas as pd
#参数初始化
inputfile = '../data/principal_component.xls'
outputfile = '../tmp/dimention_reducted.xls' #降维后的数据
data = pd.read_excel(inputfile, header = None) #读入数据
from sklearn.decomposition import PCA
a = 4
pca = PCA()#降低到的4维度
PCA(copy=True,n_components=None,whiten=False)#copy=Ture不改变原始数据
pca.fit(data)#训练
low_d = pca.transform(data)##降低他的维度
print(pca.components_) #返回模型的各个特征向量
print(low_d)
print(pca.explained_variance_ratio_) #返回各个成分各自的方差百分比
挖掘建模
分类与预测
-回归分析、决策树、人工神经网络、贝叶斯网络、支持向量机
逻辑回归代码logistic
# -*- coding: utf-8 -*-# 代码5-1
import pandas as pd
from sklearn.linear_model import LogisticRegression as LR
# 参数初始化
filename = '../data/bankloan.xls'
data = pd.read_excel(filename)
x = data.iloc[:,:8].values
y = data.iloc[:,8].values
lr = LR(max_iter=5000) # 建立逻辑回归模型
lr.fit(x, y) # 用筛选后的特征数据来训练模型
print('模型的平均准确度为:%s' % lr.score(x, y))
神经网络分类
# -*- coding: utf-8 -*-
import pandas as pd
# 参数初始化
inputfile = '../data/sales_data.xls'
data = pd.read_excel(inputfile, index_col = '序号') # 导入数据
# 数据是类别标签,要将它转换为数据
# 用1来表示“好”“是”“高”这三个属性,用0来表示“坏”“否”“低”
data[data == '好'] = 1
data[data == '是'] = 1
data[data == '高'] = 1
data[data != 1] = 0
x = data.iloc[:,:3].astype(int)
y = data.iloc[:,3].astype(int)
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers.core import Dense, Activation
model = Sequential() # 建立模型
model.add(Dense(input_dim = 3, units = 64))
model.add(Activation('relu')) # 用relu函数作为激活函数,能够大幅提供准确度
model.add(Dense(input_dim = 64, units = 1))
model.add(Activation('sigmoid')) # 由于是0-1输出,用sigmoid函数作为激活函数
model.compile(loss = 'binary_crossentropy', optimizer = 'adam')
# 编译模型。由于我们做的是二元分类,所以我们指定损失函数为binary_crossentropy,以及模式为binary
# 另外常见的损失函数还有mean_squared_error、categorical_crossentropy等,请阅读帮助文件。
# 求解方法我们指定用adam,还有sgd、rmsprop等可选
model.fit(x, y, epochs = 100, batch_size = 10) # 训练模型,学习一千次
yp = model.predict_classes(x).reshape(len(y)) # 分类预测
from cm_plot import * # 导入自行编写的混淆矩阵可视化函数
cm_plot(y,yp).show() # 显示混淆矩阵可视化结果
聚类分析
- 常用方法:划分方法(k-means聚类算法)、层次分析方法

import pandas as pd
# 参数初始化
inputfile = '../data/consumption_data.xls' # 销量及其他属性数据
outputfile = '../tmp/data_type.xls' # 保存结果的文件名
k = 3 # 聚类的类别
iteration = 500 # 聚类最大循环次数
data = pd.read_excel(inputfile, index_col = 'Id') # 读取数据
data_zs = 1.0*(data - data.mean())/data.std() # 数据标准化
from sklearn.cluster import KMeans
model = KMeans(n_clusters = k, max_iter = iteration,random_state=1234) # 分为k类,并发数4
model.fit(data_zs) # 开始聚类
# 简单打印结果
r1 = pd.Series(model.labels_).value_counts() # 统计各个类别的数目
print(r1)
r2 = pd.DataFrame(model.cluster_centers_) # 找出聚类中心
print(r2)
r = pd.concat([r2, r1], axis = 1) # 横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns = list(data.columns) + ['类别数目'] # 重命名表头
print(r)
# 详细输出原始数据及其类别
r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) # 详细输出每个样本对应的类别
r.columns = list(data.columns) + ['聚类类别'] # 重命名表头
r.to_excel(outputfile) # 保存结果
print(r)
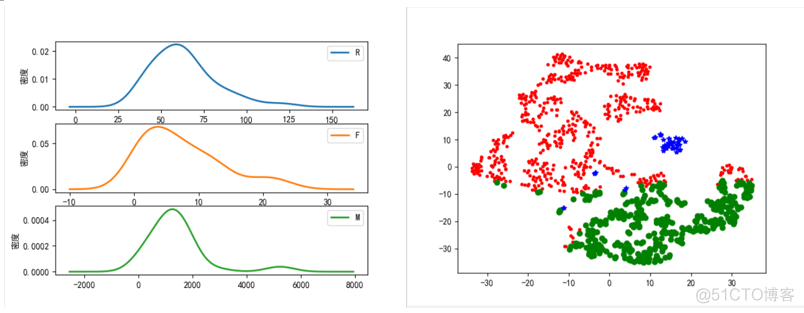
def density_plot(data): # 自定义作图函数
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
p = data.plot(kind='kde', linewidth = 2, subplots = True, sharex = False)
[p[i].set_ylabel('密度') for i in range(k)]
plt.legend()
return plt
pic_output = '../tmp/pd' # 概率密度图文件名前缀
for i in range(k):
density_plot(data[r['聚类类别']==i]).savefig('%s%s.png' %(pic_output, i))
density_plot(data[r['聚类类别'] == i]).show()
from sklearn.manifold import TSNE
tsne = TSNE(random_state=105)
tsne.fit_transform(data_zs) # 进行数据降维
tsne = pd.DataFrame(tsne.embedding_, index = data_zs.index) # 转换数据格式
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 不同类别用不同颜色和样式绘图
d = tsne[r['聚类类别'] == 0]
plt.plot(d[0], d[1], 'r.')
d = tsne[r['聚类类别'] == 1]
plt.plot(d[0], d[1], 'go')
d = tsne[r['聚类类别'] == 2]
plt.plot(d[0], d[1], 'b*')
plt.show()
在这里推荐两个好用的网站
scikit-learn中文社区:https://scikit-learn.org.cn/
包含七种启发式算法的代码库文档:https://scikit-opt.github.io/scikit-opt/#/zh/README
第一个
第二个