5.1 什么是数据结构?
现实世界中,我们经常需要一些“容器”来存储生活中使用的小物件。比如使用存钱罐存硬币、抽屉存媳妇用的护肤品、首饰等。通常我们如果将硬币、护肤品当成前文讲到的基本数据类型的实例,那么存钱罐、抽屉就可以类比成存储多个基本数据类型实例的容器,即Python的数据结构。
在互联网世界中也是一样,如下图豆瓣网展示,同类型的数据可以存储在一个容器中。
Python有四种基本数据结构,分别是:列表(list)、字典(dict)、元组(tuple)、集合(set)。我们先从整体上来认识一下这四种数据结构:

5.2 列表(list)
列表是最常用的Python数据类型,创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。
list = ['physics', 'chemistry', 1997, 2000]理解list,可以类比下图的手机袋;每个手机袋可以装一个物品,记着储物袋编号就能找到你物品所在位置。
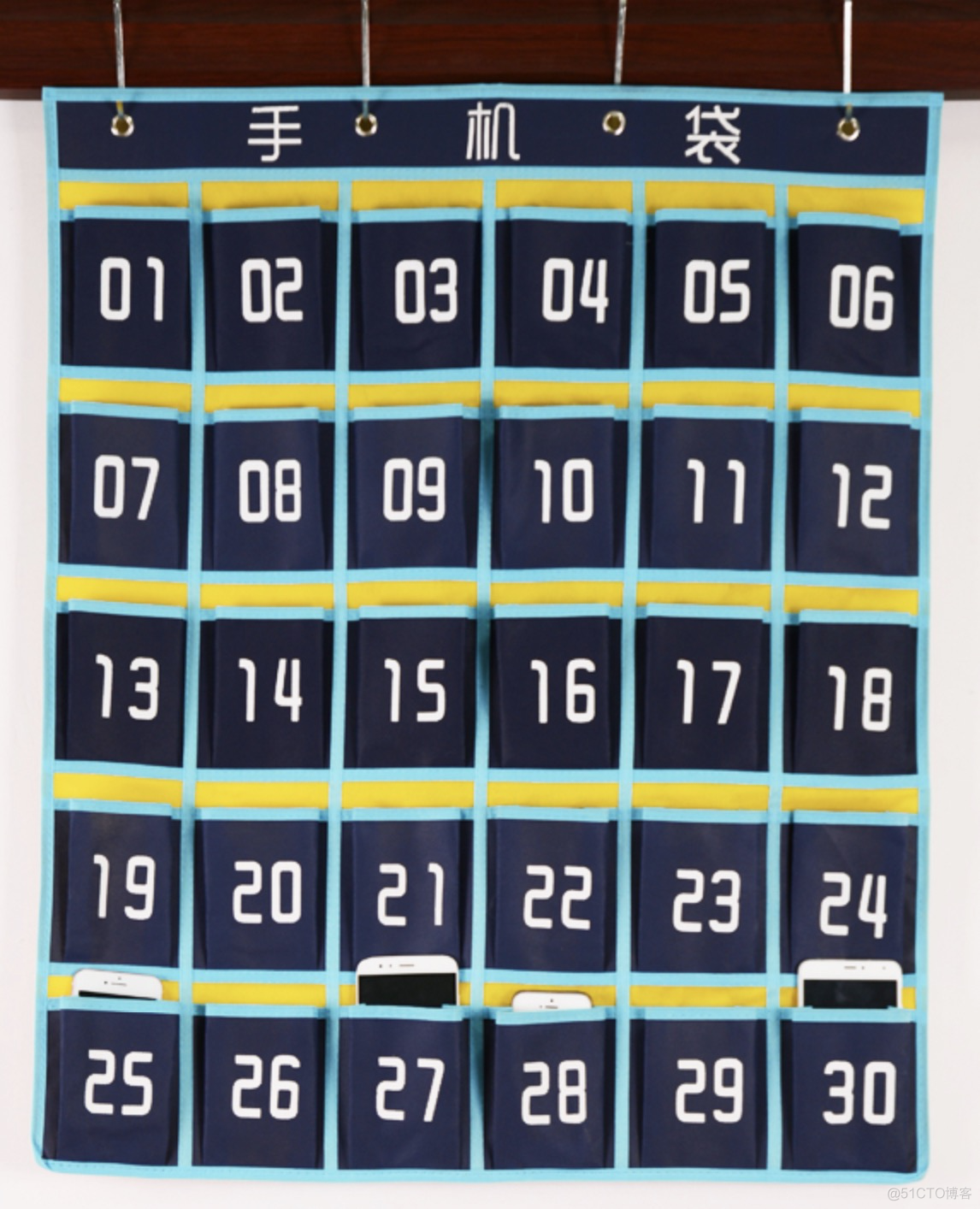
而这个编号,在Python列表中被称作索引,而且列表的索引是从 0 开始,即列表的第一个值的索引为0,最后一个值的索引为-1。如下图所示:

5.2.1 增
list.append()函数
# list创建list = ['hello', 'world']
# list追加元素
list.append('qa.yw')
print(list)
>> ['hello', 'world', 'qa.yw']
5.2.2 删
del list[index]
# list创建list = ['hello', 'world']
# list追加元素
list.append('qa.yw')
del list[1]
print(list)
>> ['hello', 'qa.yw']
5.2.3 改
# list创建list = ['hello', 'world']
# list追加元素
list.append('qa.yw')
print(list)
>> ['hello', 'world', 'qa.yw']
list[2] = 'qa'
print(list)
>> ['hello', 'world', 'qa']
5.2.4 查
list[index]
# list创建list = ['hello', 'world']
# list追加元素
list.append('qa.yw')
print(list[1])
>> world
5.2.5 切片
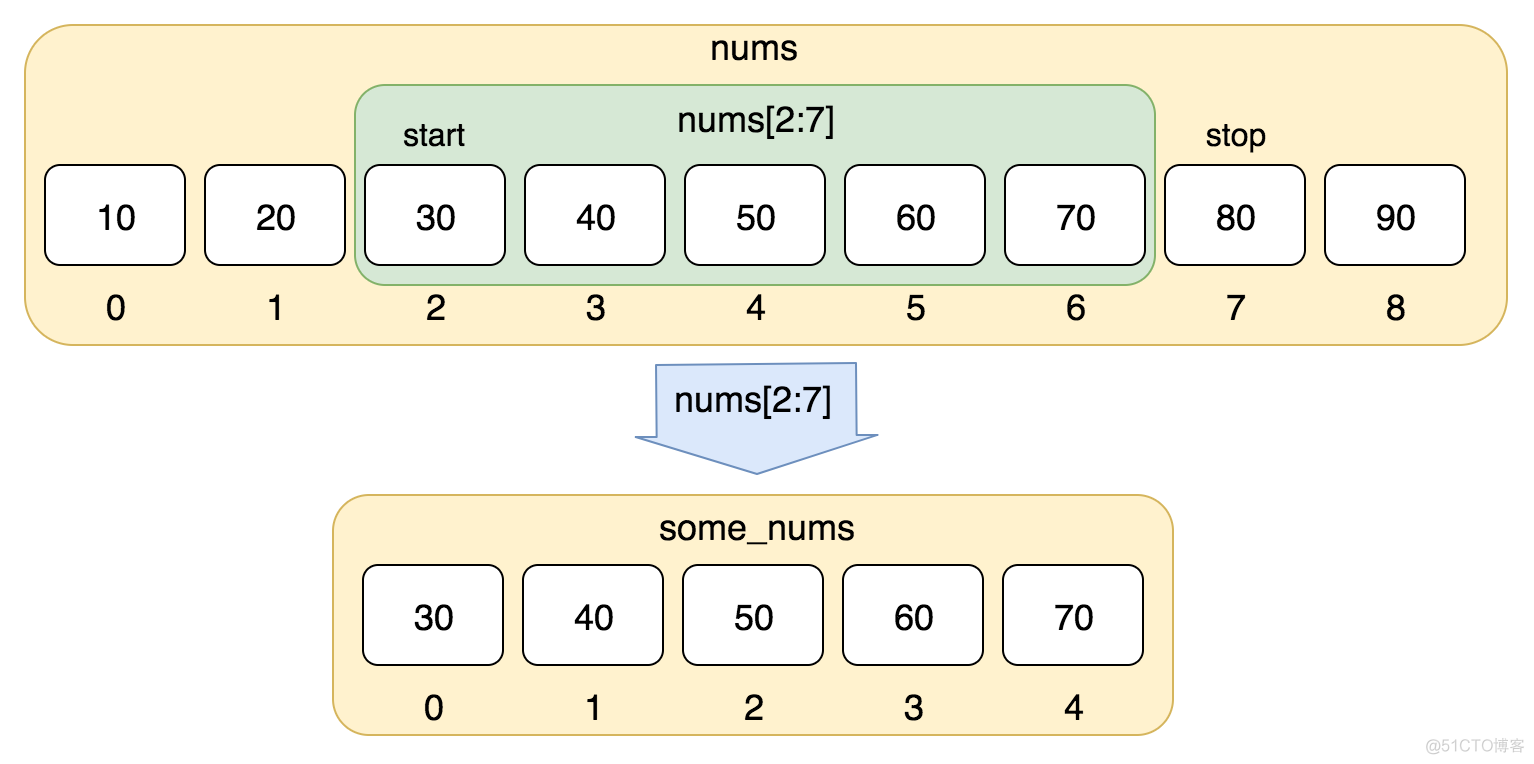
print(nums[2:7])
>> [30, 40, 50, 60, 70]
print(nums[2:])
>> [30, 40, 50, 60, 70, 80, 90]
print(nums[::-1])
>> [90, 80, 70, 60, 50, 40, 30, 20, 10]
print(nums)
>> [10, 20, 30, 40, 50, 60, 70, 80, 90]
注意:此时列表反转并未对真正对nums进行元素反转。
5.2.6 排序
print(sorted(nums, reverse=True))
>> [90, 80, 70, 60, 50, 40, 30, 20, 10]
print(sorted(nums, reverse=False))
>> [10, 20, 30, 40, 50, 60, 70, 80, 90]
5.2.7 列表方法总结
序号
函数
1
len(list)
列表元素个数
2
max(list)
返回列表元素最大值
3
min(list)
返回列表元素最小值
4
list(seq)
将元组转换为列表
5
list.append(obj)
在列表末尾添加新的对象
2
list.count(obj)
统计某个元素在列表中出现的次数
7
list.extend(seq)
在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
8
list.index(obj)
从列表中找出某个值第一个匹配项的索引位置
9
list.insert(index, obj)
将对象插入列表
5.3 字典(dict)
字典数据结构,可以借助真正的字典来理解。如下图:每个字都对应其释义。那么每个字就是对应右图的key,释义对应的value。

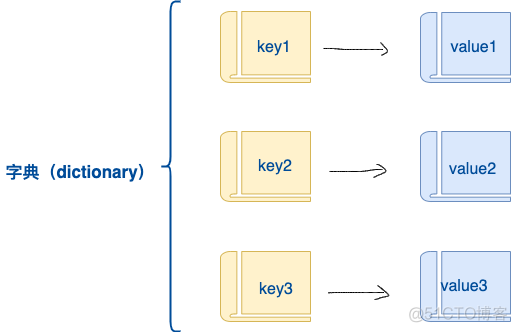
字典的每个键值 key=>value 对用冒号 : 分割,每个对之间用逗号(,)分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2, key3 : value3 }字典的特点:
1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例:
dict = {'Name': 'qa.yw', 'Age': 7}print("dict['Name']: ", dict['Name'])
>> dict['Name']: qa.yw
2)键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行,如下实例:
dict = {['Name']: 'qa.yw', 'Age': 7}print ("dict['Name']: ", dict['Name'])
>> TypeError: unhashable type: 'list'
5.3.1 增
增加字典很简单,在字典中增加key-value即可。
dict1 = { 'abc': 456 }dict1['bcd'] = 567
print(dict1)
>> {'abc': 456, 'bcd': 567}
5.3.2 删
能删单一的元素也能清空字典,清空只需一项操作。显示删除一个字典用del命令,如下实例:
dict = {'Name': 'qa.yw', 'Age': 7, 'Class': 'First'}del dict['Name'] # 删除键 'Name'
dict.clear() # 清空字典
del dict # 删除字典
print("dict['Age']: ", dict['Age'])
print("dict['School']: ", dict['School'])
>>
Traceback (most recent call last):
File "/Users/younger/PycharmProjects/TeachWifeLearnPython/chapter_five/数据结构.py", line 47, in <module>
print("dict['Age']: ", dict['Age'])
TypeError: 'type' object is not subscriptable
上述引发一个异常,是因为用执行 del 操作后字典不再存在:
5.3.3 改
dict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}dict['Age'] = 8 # 更新 Age
print ("dict['Age']: ", dict['Age'])
>> dict['Age']: 8
5.3.4 查
dict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}print ("dict['Name']: ", dict['Name'])
print ("dict['Age']: ", dict['Age'])
>> dict['Name']: Runoob
dict['Age']: 7
5.3.5 内置函数
序号
函数及描述
实例
1
len(dict)
计算字典元素个数,即键的总数。
>>> dict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
>>> len(dict)
3
2
str(dict)
输出字典,以可打印的字符串表示。
>>> dict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
>>> str(dict)
"{'Name': 'Runoob', 'Class': 'First', 'Age': 7}"
3
type(variable)
返回输入的变量类型,如果变量是字典就返回字典类型。
>>> dict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
>>> type(dict)
<class 'dict'>
1
radiansdict.clear()
删除字典内所有元素
2
radiansdict.copy()
返回一个字典的浅复制
3
radiansdict.fromkeys()
创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值
4
radiansdict.get(key, default=None)
返回指定键的值,如果键不在字典中返回 default 设置的默认值
5
key in dict
如果键在字典dict里返回true,否则返回false
5.4 元组(tuple)
元素其实可以理解成一个稳固版的列表,由于元祖的元素是不可修改的,因为在列表中存在的方法均不可使用在元祖上,但是元组是可以被查询索引的,方式和列表一致。
nums = [80, 20, 30, 40, 50, 60, 70, 10, 90]# list转为tuple
nums = tuple(nums)
print(nums)
>> (80, 20, 30, 40, 50, 60, 70, 10, 90)
print(nums[1])
>> 20
5.5 集合(set)
集合概念更接近数学上集合的概念,每一个集合的元素是无序的,而且是不能重复的。当我们需要存储并过滤重复元素的时候,可以考虑使用集合数据结构。
由于集合有无序特点,故不能通过索引的方式取集合元素。
set.add(4)
print(set)
set.add(4)
print(set)
set.discard(3)
print(set)
>> {1,2,4}
set_B = {1,2,4}
print(set_A.difference(set_B))
>> {3}