案例来源与分析
今天这篇博客非常有趣,是来源自78技术人的一个需求,有好友反馈在上传资源的时候,发现了CSDN下载频道的如下界面。

此时该好友的需求是:期望得到这些优质资源的真实下载地址,去看一下下载数,瞻仰一下大佬,学习一下如何日赚700米。
接到这个需求之后,橡皮擦进行了简单的调查,最终结论是,该案例可以通过 Python 实现,并且还存在一定的反爬难度。
分析之后得到的逻辑如下:
按照上述思路的第一条,通过开发者工具获取了接口数据,在得到接口数据之后,发现此路不通,原因如下所示:
获取到的接口数据如下所示:
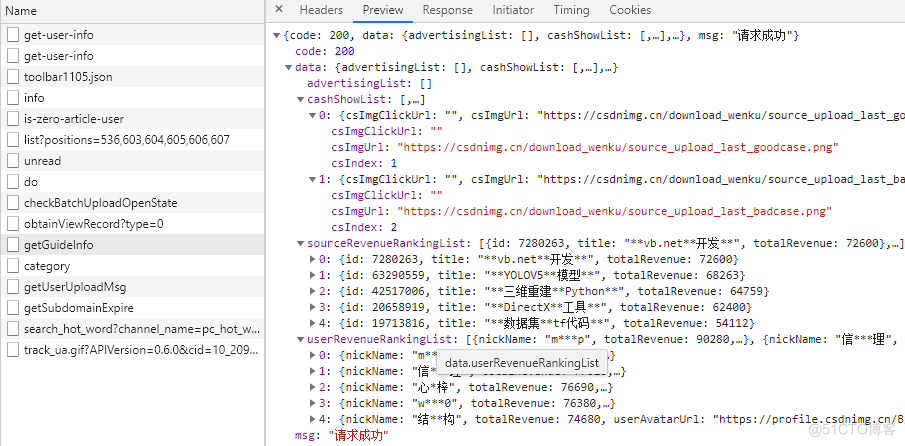
上述接口返回的下载资源数据,仅包括如下值
id: 7280263 title: "**vb.net**开发**" totalRevenue: 72600- id:文件资源ID,属于资源唯一键,但由于无法获取上传者的ID,还是没办法直接调用资源下载地址;
- title:文件名,但是缺少关键信息;
- totalRevenue:收益数字,精确到分。
截止到这里,你会得到了一些残缺的信息,包含一个加 * 的资源名,一个资源ID。
再次查阅一下资源的下载地址,拿橡皮擦自己的资源举例如下:
https://download.csdn.net/download/hihell/84991631地址参数模板说明如下:
https://download.csdn.net/download/用户ID/资源ID
从上文的开发者工具中我们得到了资源ID,那只是完整路径中的一部分,由于没有用户ID,还是无法拼凑出完整的连接,那只能凭借搜索引擎部分检索,去提取完整地址。
操作步骤如下所示,这里截图使用的是百度搜索,在搜索框输入下图内容,其中ID使用的是上述接口获取的资源ID。
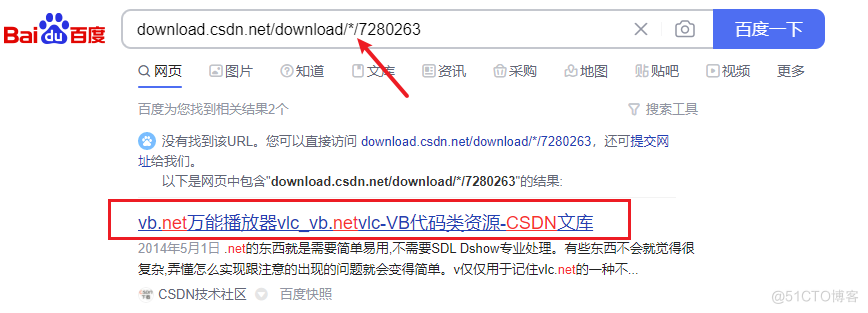
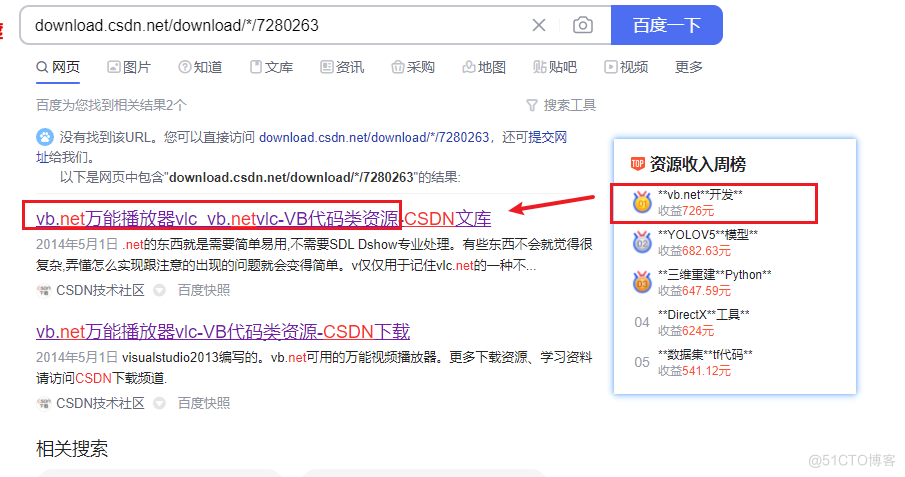
但是又发现一个问题,这个相同资源ID,名称类似的文件,竟然文件名没有对应上,难道CSDN隐藏了部分重要信息?
一系列的逻辑落地解析完毕,下面就可以将逻辑转换为代码了,具体编码参见下文呈现。
编码时间
首先通过 Python 调用接口,获取文件ID,但这里由于CSDN该接口增加了反爬限制,而本篇博客也不想因为5条数据,就去研究C站的反爬原力,所以建议大家直接复制接口返回的数据集即可。
如果你希望研究一下C站的反爬手段,可以参考下图,其中重要的参数如下所示。
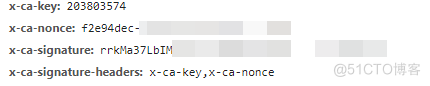
既然不需要反爬提取数据了,那直接复制 getGuidInfo 接口响应的数据即可,结果如下所示:
[ { "id": 7280263, "title": "**vb.net**开发**", "totalRevenue": 72600 }, { "id": 63290559, "title": "**YOLOV5**模型**", "totalRevenue": 68263 }, ... ... ]接下来使用 cn.bing 来获取请求结果集,其中请求数据的地址如下所示,里面的 wd 参数,即搜索地址,其余参数尽量携带,否则容易返回空数据。
https://cn.bing.com/search?q={wd}&form=QBLH&sp=-1&pq={wd}&sc=0-36&qs=n&sk=&cvid=850DEE65A66648489A8E615C4443FC1C import requests from lxml import etree import time datas = [ { "id": 7280263, "title": "**vb.net**开发**", "totalRevenue": 72600 }, { "id": 63290559, "title": "**YOLOV5**模型**", "totalRevenue": 68263 }, { "id": 42517006, "title": "**三维重建**Python**", "totalRevenue": 64759 }, { "id": 20658919, "title": "**DirectX**工具**", "totalRevenue": 62400 }, { "id": 19713816, "title": "**数据集**tf代码**", "totalRevenue": 54112 } ] headers = { "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9", "Host": "cn.bing.com", "User-Agent": "复制自己的 UA 即可", } for item in datas: id = item["id"] wd = f"download.csdn.net/download/*/{id}" print(f"正在检索 {wd}") res = requests.get( f'https://cn.bing.com/search?q={wd}&form=QBLH&sp=-1&pq={wd}&sc=0-36&qs=n&sk=&cvid=850DEE65A66648489A8E615C4443FC1C', headers=headers, timeout=3) if res.text.strip() != "": eles = etree.HTML(res.text) li = eles.xpath('.//li[@class="b_algo"]') print(li)
接下来只需要获取到第一个 li 内部的超链接地址即可。
if res.text.strip() != "": eles = etree.HTML(res.text) lis = eles.xpath('.//li[@class="b_algo"]') real_href = lis[0].xpath('./div/h2/a/@href')此时的输出结果如下所示,已经得到优质(赚钱)资源的真实下载地址了
正在检索 download.csdn.net/download/*/7280263 ['https://download.csdn.net/download/u010484563/7280263'] 正在检索 download.csdn.net/download/*/63290559 ['https://download.csdn.net/download/ECHOSON/63290559'] 正在检索 download.csdn.net/download/*/42517006 ['https://download.csdn.net/download/guyuealian/42517006'] 正在检索 download.csdn.net/download/*/20658919 ['https://download.csdn.net/download/VBcom/20658919'] 正在检索 download.csdn.net/download/*/19713816 ['https://download.csdn.net/download/ECHOSON/19713816']记录时间
2022年度 Flag,写作的 <font color=red>588</font> / 1024 篇。 可以<font color=#04a9f4>关注</font>我,<font color=#04a9f4>点赞</font>我、<font color=#04a9f4>评论</font>我、<font color=#04a9f4>收藏</font>我啦。