这里的高性能指的就是网卡有多快请求发送就能有多快,基本上一般的服务器在一台客户端的压力下就会出现明显延时。该篇实际是介绍pipe管线的原理,下面主要通过其高性能的测试实
这里的高性能指的就是网卡有多快请求发送就能有多快,基本上一般的服务器在一台客户端的压力下就会出现明显延时。
该篇实际是介绍pipe管线的原理,下面主要通过其高性能的测试实践,解析背后数据流量及原理。最后附带一个简单的实现
实践
先直接看对比测试方法
测试内容单一客户的使用尽可能快的方式向服务器发送一定量(10000条)请求,并接收返回数据
对于单一客户端对服务器进行http请求,一般我们的方式
1:单进程或线程轮询请求(这个效能自然很低,原因会讲到,也不用测试)
2:多条线程提前准备数据等待信号(对客户端性能要求较高)
3:提前准备一组线程同时轮询操作
4:使用系统/平台自带异步发送机制(实际就是平台线程池的方式,发送与接收使用从线程池中的不同线程)
对于测试方案1,及方案2测试中性能较低没有可比性,后面测试不会展示其结果
以下展示后面2种测试方法及当前要说的管线式的方式
- 先讲管线式(pipe)测试方案(原理在后面会讲到),测试中使用100条管线(管道),实际上更少甚至一条管线也是能达到近似的性能,不过多数服务器nginx限制一条管可以持续发送request的数量(大部分是100也有部分会是200或是更高),每条管线发送100个请求。
- 然后是线程组的方式准备100条线程(100条线程并不是很多不会对系统本身有明显影响),每条线程轮询发送100个request。
- 异步方式的方式,10000全部提交发送线程,由线程池控制接收。
测试环境:普通家用PC,i5 4核,12G ,100Mb电信带宽
测试数据:
GET http://www.baidu.com HTTP/1.1
Content-Type: application/x-www-form-urlencoded
Host: www.baidu.com
Connection: Keep-Alive
这里就是测试最常用的baidu,如果测试接口性能不佳,大部分请求会在应用服务器排队,难以直观提现pipe的优势(其实就是还没有用到pipe的能力,服务器就先阻塞了)
下文中所有关于pipe的测试都是使用PipeHttpRuner (http://www.cnblogs.com/lulianqi/p/8167843.html 为该测试工具的下载地址,使用方法及介绍)
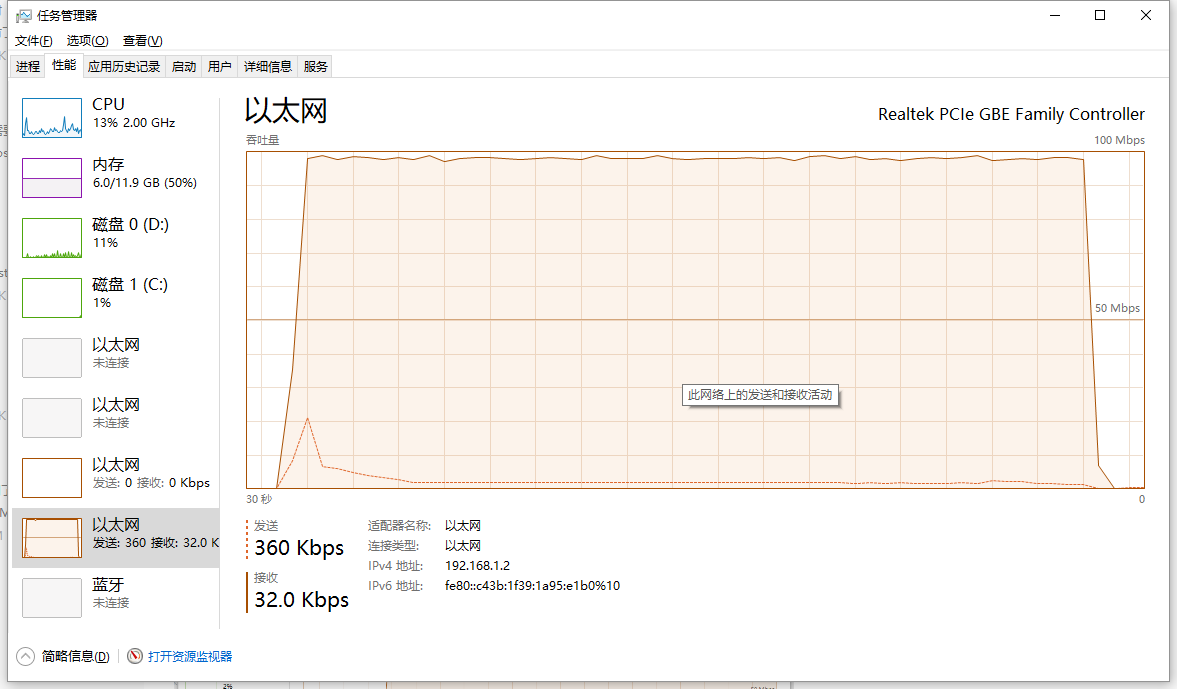
先直接看管道式的表现:(截图全部为windows自带任务管理器及资源管理器)
![]()
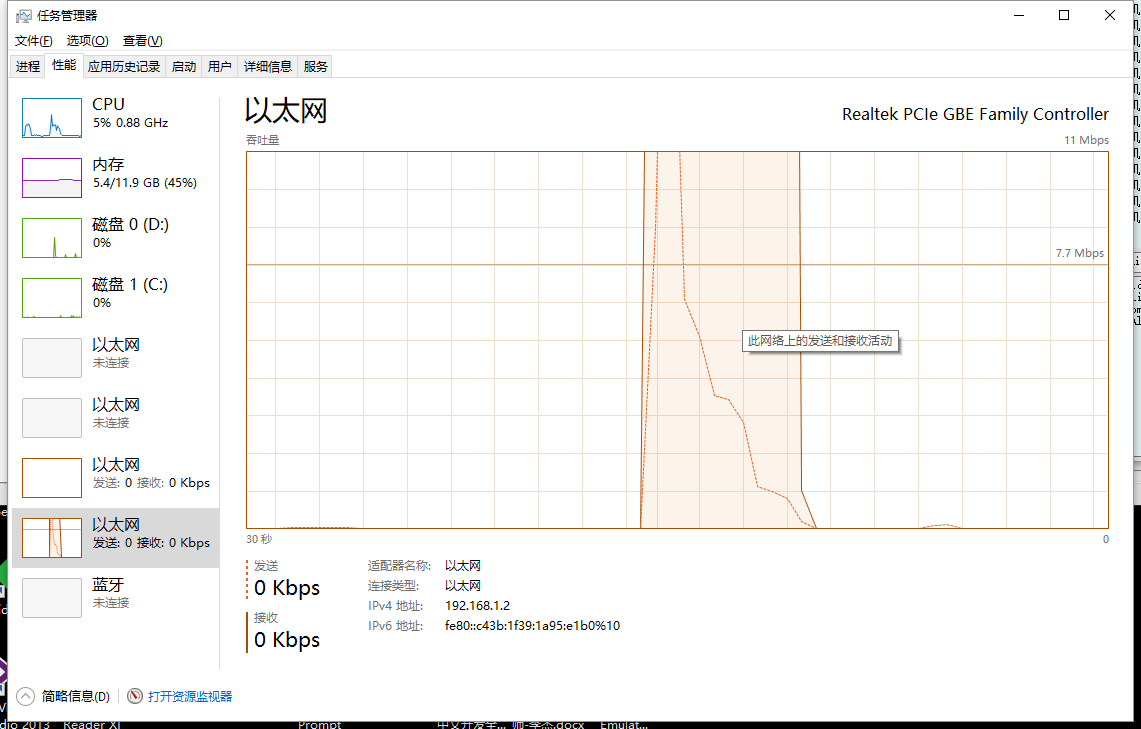
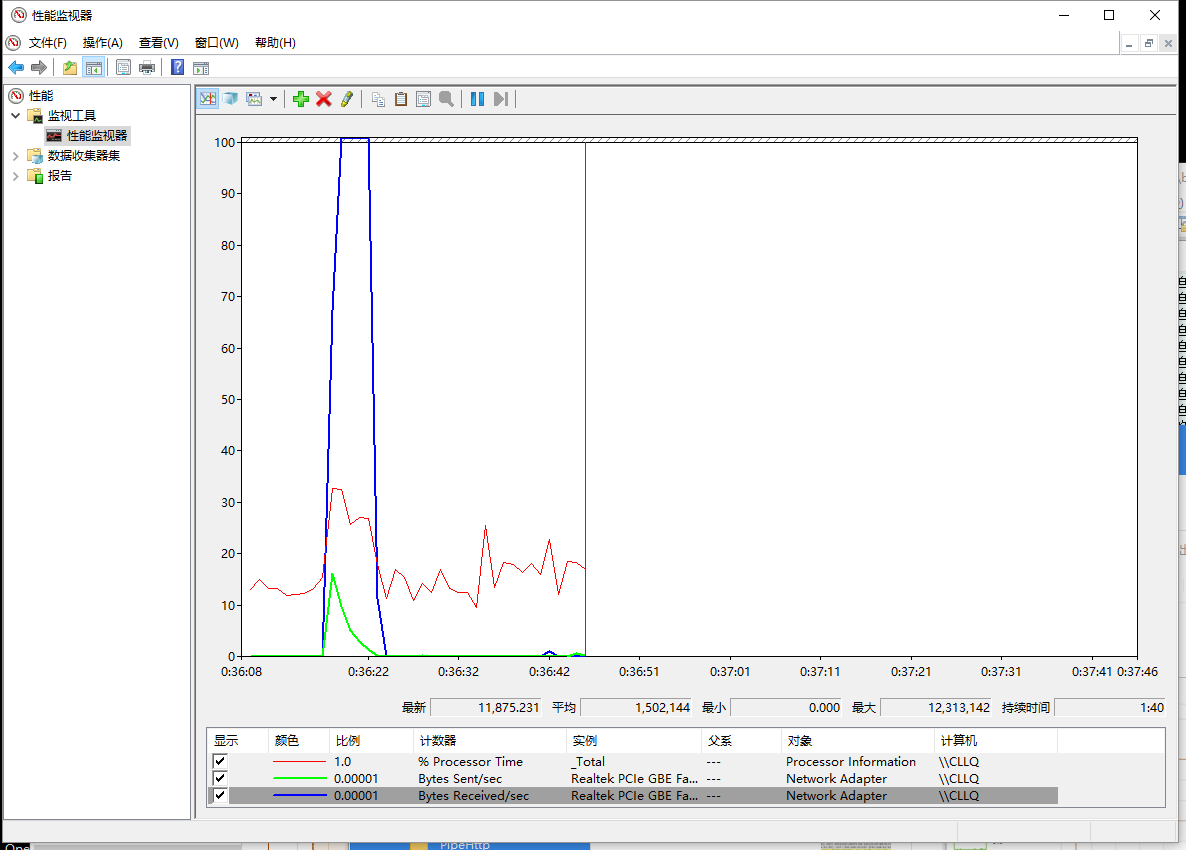
先解释下截图含义,后面的截图也都是同样的含义
第一副为任务管理器的截图实线为接收数据,虚线为发送数据,取样0.5s,每一个正方形的刻度为1.5s(因为任务管理器绘图策略速率上升太快过高的没有办法显示,不过还是可以看到时间线)
第二副为资源管理器,添加了3个采样器,红色为CPU占用率,蓝色为网络接收速率,绿色为网络发送速率。
测试中 一次原始请求大概130字节,加上tcp,ip包头,10000条大概也只有1.5Mb(包头不会太多因为管道式请求里会有多个请求放到一个包里的情况,不过大部分服务器无法有这么快的响应速度会有大量重传的情况,实际上传流量可能远大于理论值)
一次的回包大概在60Mb左右(因为会有部分连接中途中断所以不一定每次测试都会有10000个完整回复)
可以看到使用pipe形式性能表现非常突出,总体完成测试仅仅使用了5s左右
发送本身压力比较小,可以看到0.5秒即到达峰值,其实这个时候基本10000条request已经发送出去了,后面的流量主要来自于服务器端缓存等待(TCP window Full)来不及处理而照成是重传,后面会讲到。
再来看看response的接收,基本上也仅仅使用了0.5s即达到了接收峰值,使用大概5s 即完成了全部接收,因为测试中cpu占用上升并不明显,而对于response的接收基本上是从tcp缓存区读出后直接就存在了内容里,也没有涉及磁盘操作(所以基本上可以说对于pipe这个测试并没有发挥出其全部性能,瓶颈主要在网络带宽上)。
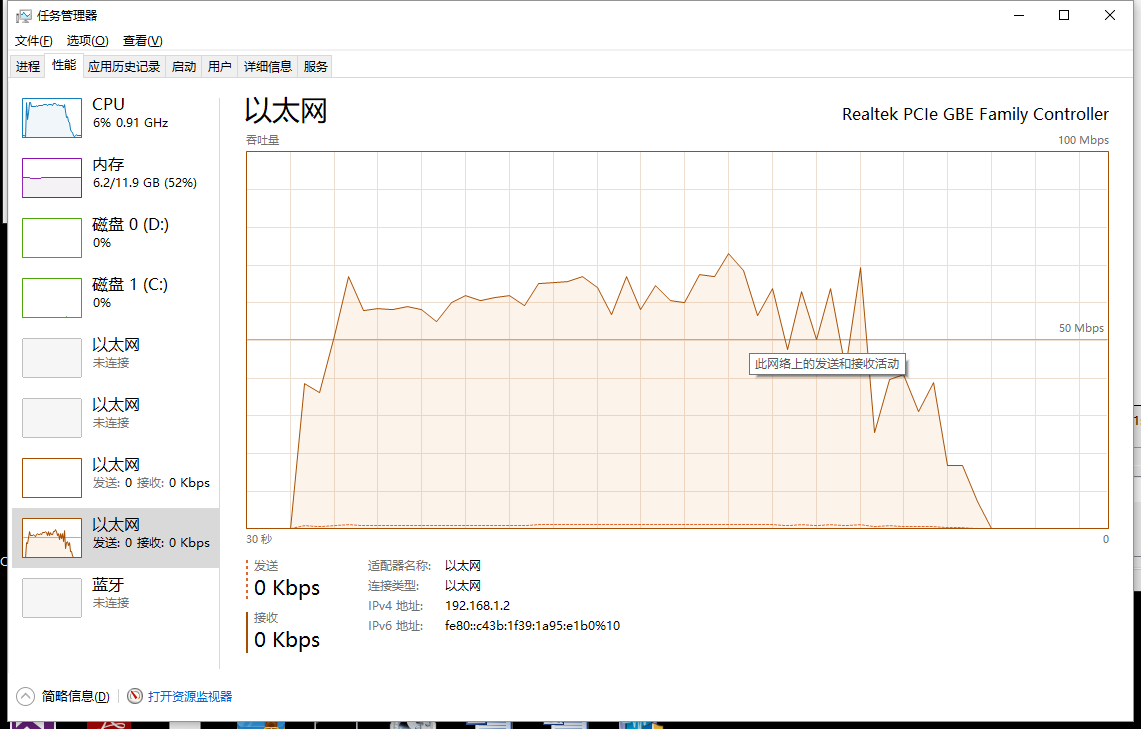
再来看下线程组的方式(100条线程每条100次)
![]()
![]()
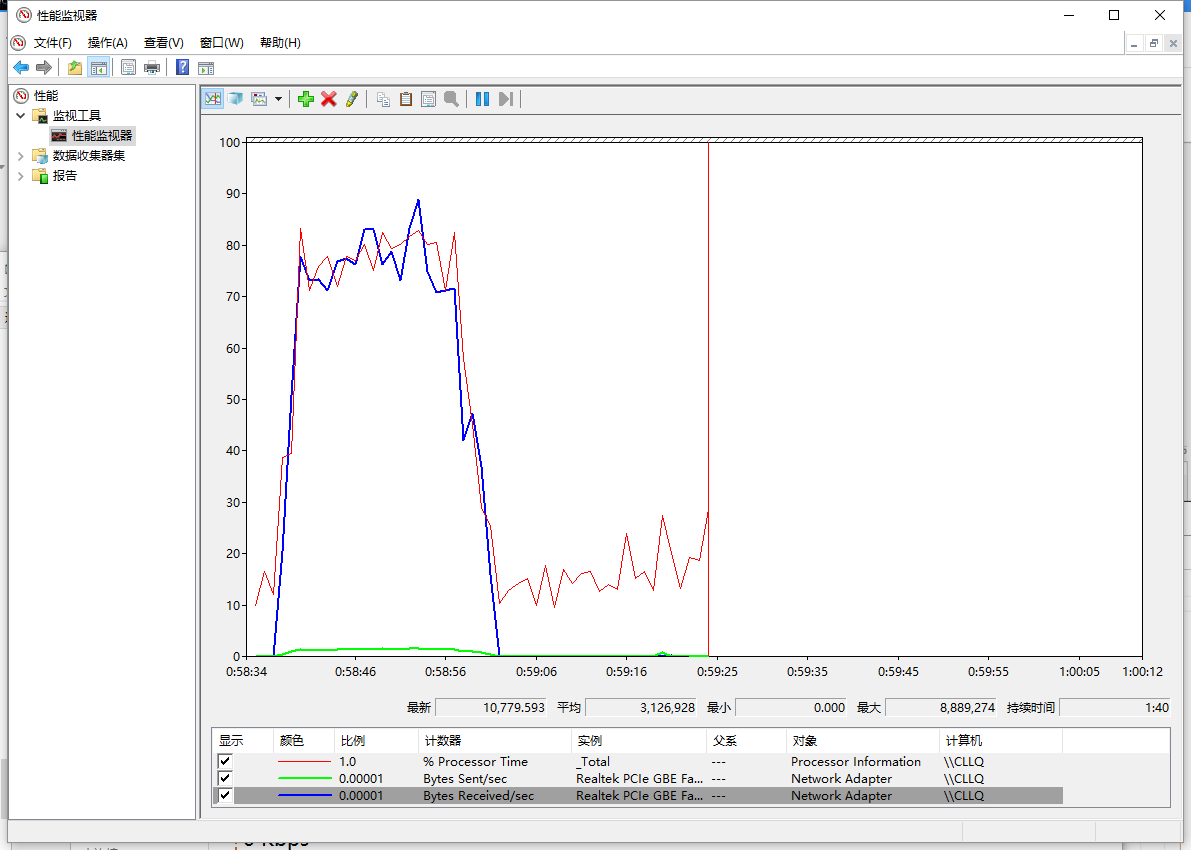
下面是异步接收的方式
![]()
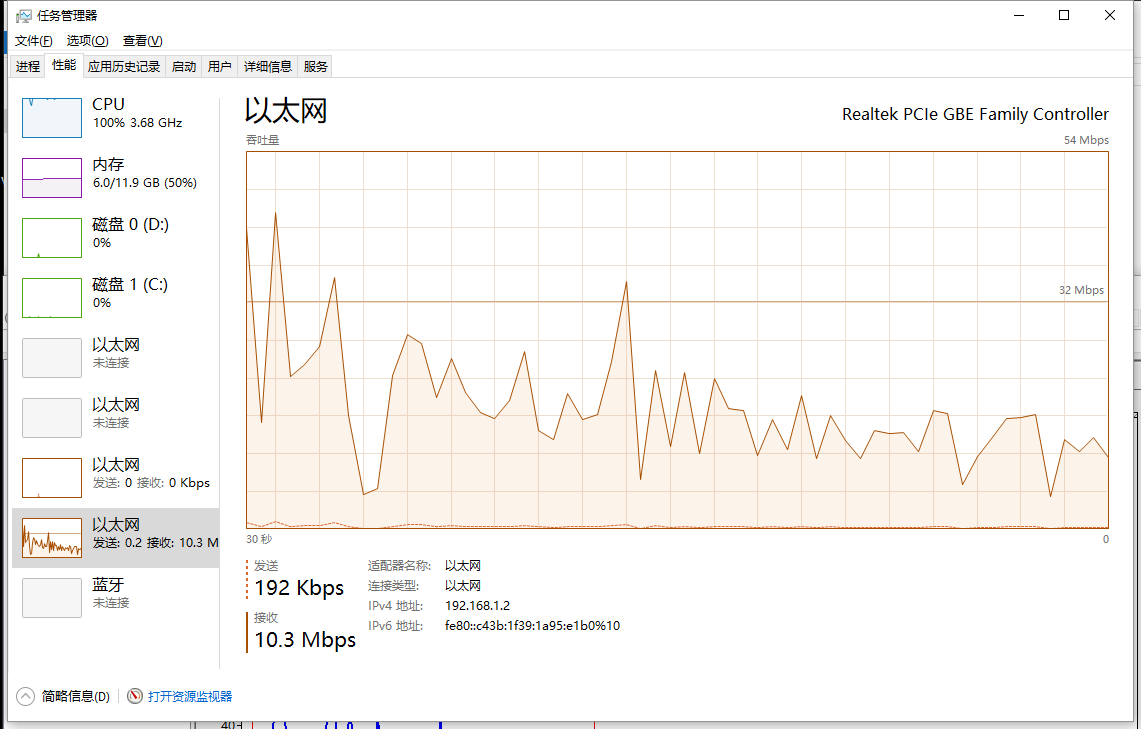
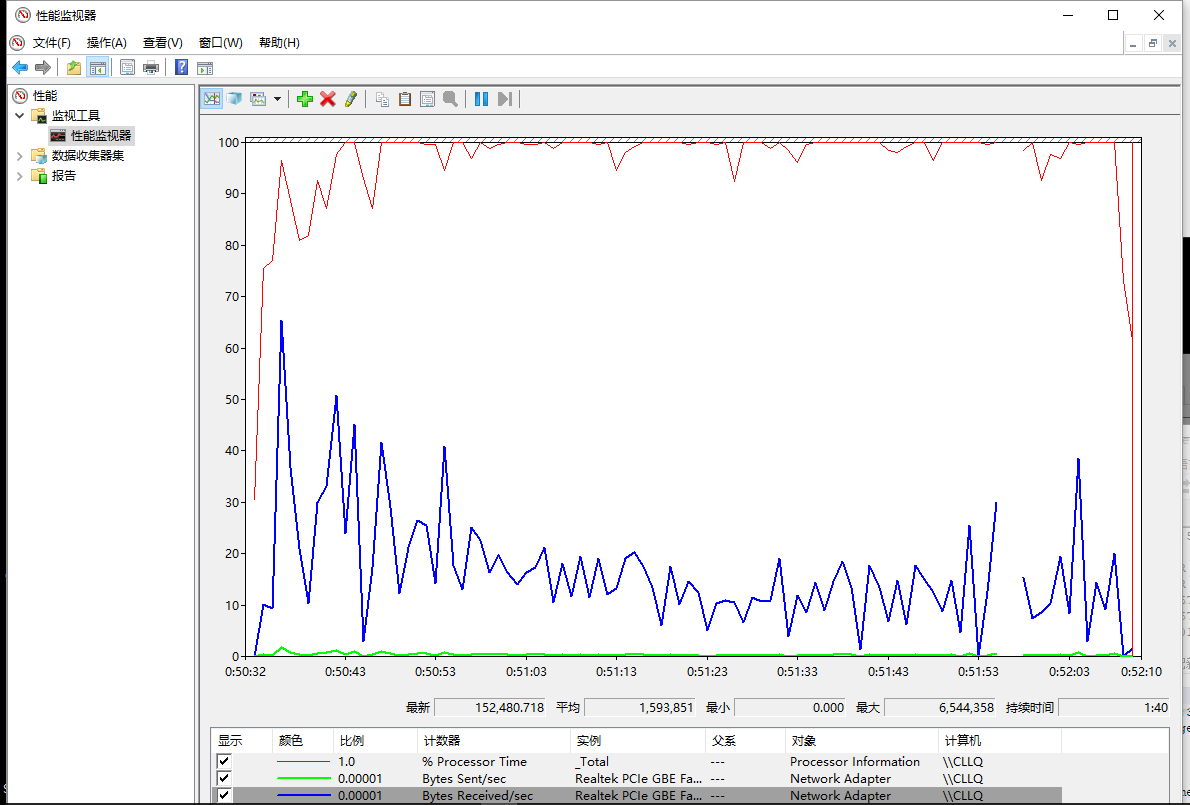
很明显的差距,对于线程组的形式大概使用了25秒,而异步接收使用了超过1分钟的时间(异步接收的模式是平台推荐的发送模式,正常应用情况下性能是十分优越的,而对于过高的压力不如自定义的线程组,主要还是因为其使用了默认的线程池,而默认线程池不可能在短时间开100条线程出来用来接收数据,所以大量的回复对线程池里的线程就会有大量的切换,通过设置默认线程池数量可以提高测试中的性能)。更为重要的是这2者中的无论哪一种方式在测试中,cpu的占用都几乎是满的(即是说为了完成测试计算机已经满负荷工作了,很难再有提高)
后面其实还针对jd,toabao,youku,包括公司自己的服务器进行过测试,测试结果都是类似的,只要服务器不出问题基本上都有超过10倍的差距(如果客户端带宽足够这个差距会更大)。
下面我们再对接口形式的HTTP进行简单一次测试
这里选用网易电商的接口(电商的接口一般可承受的压力比较大,这里前面已经确认测试不会对其正常使用造成实质的影响)
http://you.163.com/xhr/globalinfo/queryTop.json?__timestamp=1514784144074 (这里是一个获取商品列表的接口)
测试数据设置如下
![]()
![]()
![]()
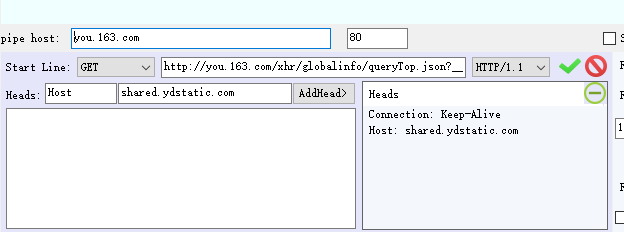
![]()
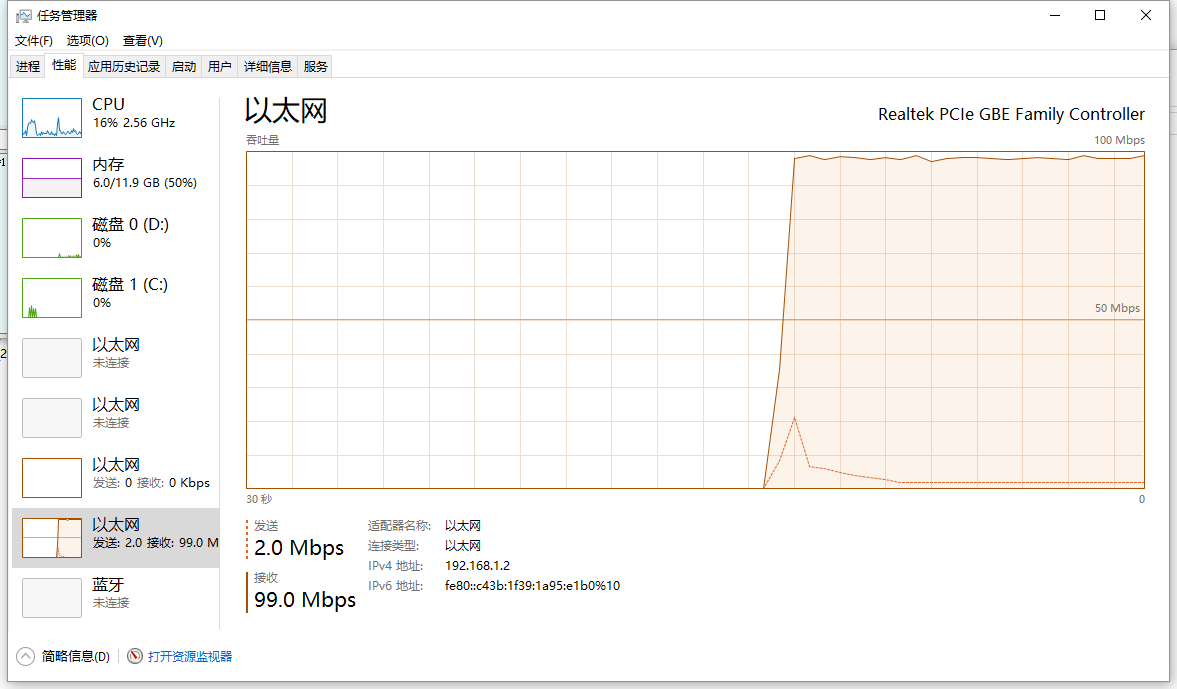

![]()
请求量还是10000条接收的response数据大概有326Mb 30s之内完成。基本上是网络的极限,此时cpu也基本无然后压力(100条管线,每条100个请求)
这里其实请求是带时间戳的,因为测试时使用的是同一个时间戳,所以实际对应用服务器的影响不大,真实测试时可以为每条请求设置不同时间戳(这里是因为要演示使用了线上公开服务,测试时请使用测试服务)
注意,这里的测试如果选择了性能较低的测试对象,大部分流量会在服务器端排队等候,导致吞吐量不大,这实际是服务器端处理过慢,与客户端关系不大。
一般情况下一台普通的pc在使用pipe进行测试时就可以让服务器出现明显延时
原理
正常的http一般实现都是连接完成后(tcp握手)发生request流向服务器,然后及进入等待,收到response后才算结束(如下图)
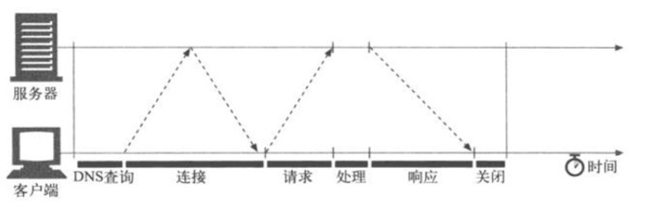
![]()
当然http1.1 即支持keep alive,完成一次收发后完全可以不关闭连接使用同一个链接发生下一个请求(如下图)
![]()

这种方式对性能的提升还是比较明显的,特别早些年服务器性能有限,网络资源匮乏,RTT大(网络时延大)。不过对如今的情况,其实这些都已经不是最主要的问题了
可以明显看到上面的模式,是一定要等到response到达后,客户端才能发起下一个request的,如果应用服务器需要时间处理,所有后面的请求都需要等待,即使不需要任何处理直接回复给客户端,请求,回复在网络上的时间也是必须完整的等下去,而且由于tcp传输本身的特性,速率是逐步上升的,这样断断续续的发送接收十分影响tcp迅速达到线路性能最大值。
pipe (管线式)正是回避了上面的问题,他不需要等回复达到即可直接发送(事实上http1.1协议也从来没有讲过必须要等response到达后客户端才能发送下一个请求,只是为了方便应用层业务实现,一般的http库都是这样实现的,而现在看到的绝大多少http服务器都是默认支持pipe的),这样发送与接收即可以分离开来(如下图)
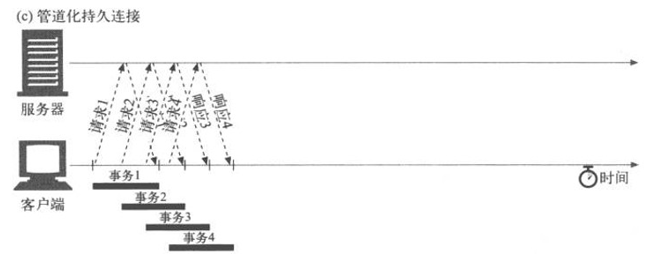
![]()
在事实情况下,发生可能会比这个图表现的更快,请求1,2,3,4很可能被放到一个tcp包里被一次性全部发出去(这种模式也给部分应用带来了麻烦,后面会讲到)
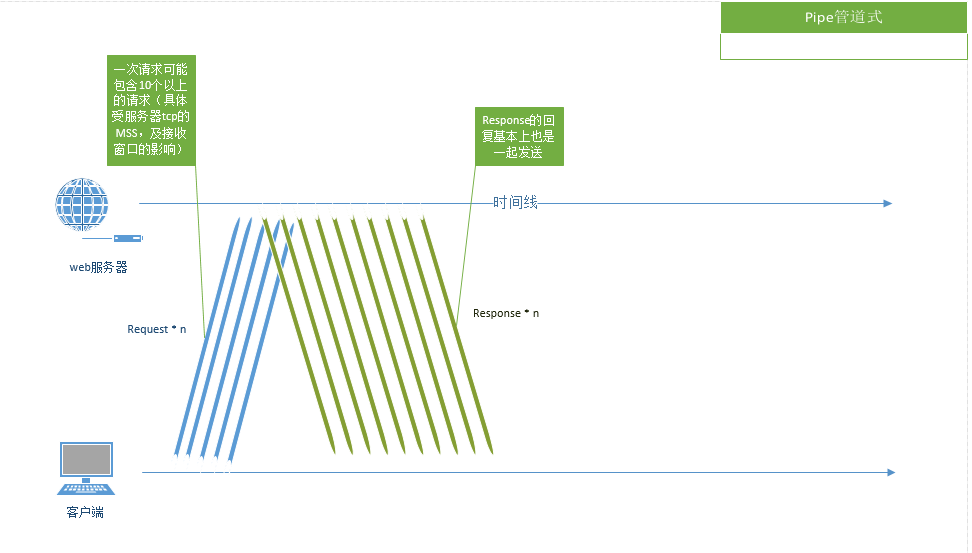
![]()
对于pipe相对真实的情况如上图,多个请求会被打包在一起被发送,甚至有时是所有request发送完成后,服务器才开始回复第一个response。
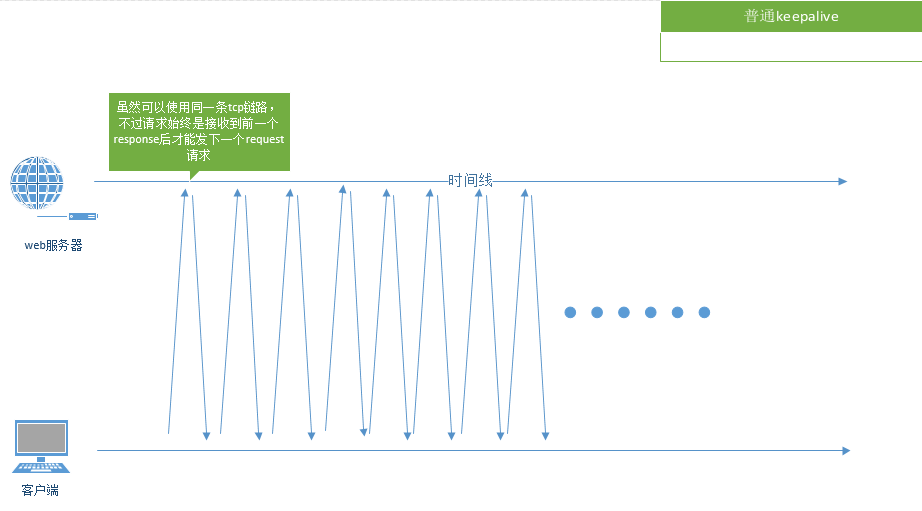
![]()
而普通的keepalive的模式如上图,一条线代表一个请求,不仅一次只能发送一个,而且必须等待回复后才能发下一个。
下面看下实际测试中pipe的模式具体是什么模样的
![]()
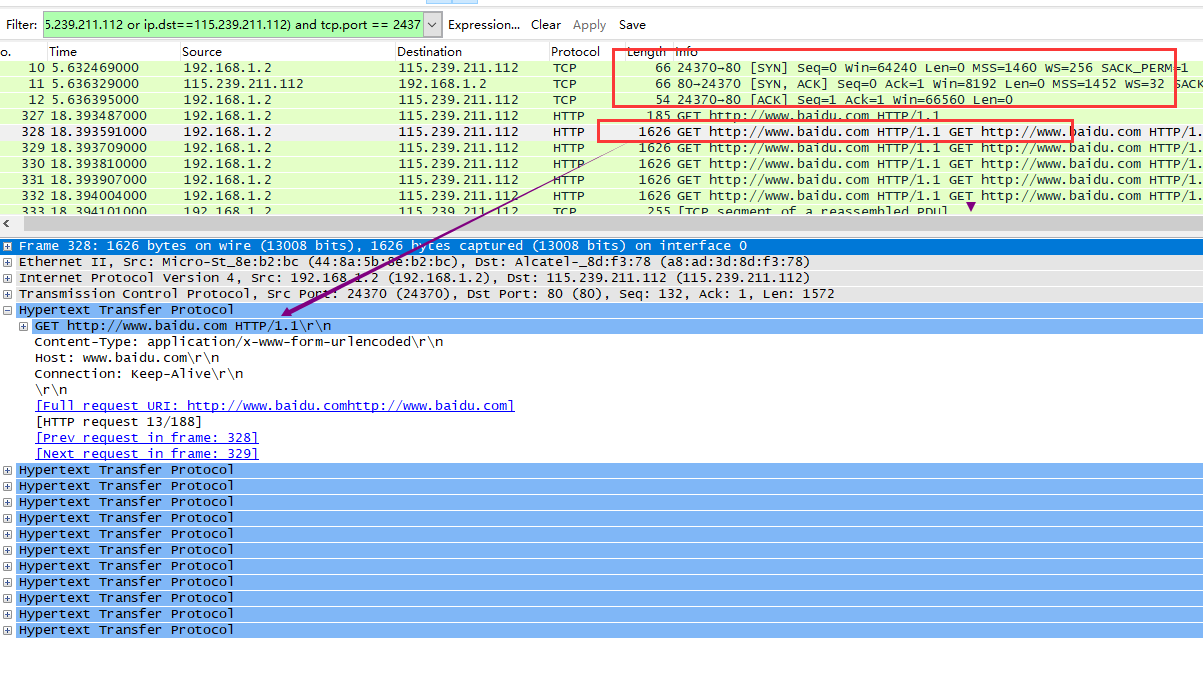
可以看到握手完成后(实际上握手时间也不长只用了4ms),随后即直接开始了request的发送,可以看到后面的一个tcp包里直接包含了完整的12个请求。在没有收到任何一个回复的情况下,就可以把所有要发送的请求提前全部发出(服务器已经关闭了Nagle算法)。
![]()
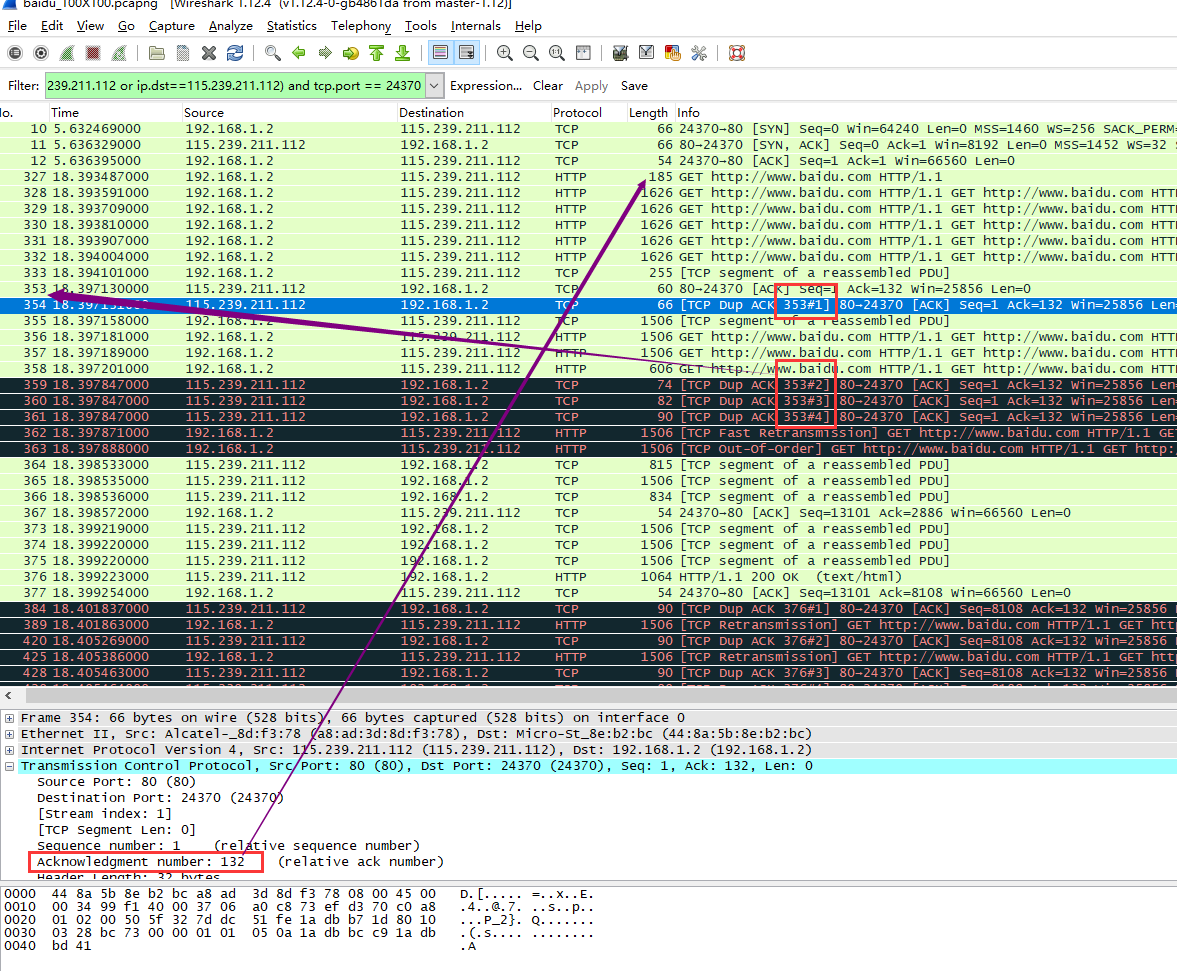
由于发送速度过快直到发出一大半近70个request的时候第一个tcp确认包序号为353的包(只是确认包不是response)才发出(327的ack),而且服务器很快就发现下一个包出问题了并引发了TCP DUP ACK (https://ask.wireshark.org/questions/29216/why-are-duplicate-tcp-acks-being-seen-in-wireshark-capture 产生原因可以参考这里)
【TCP DUP ACK 出现在接收方发现数据包缺口时(数据包失序),这种情况就会发送重复的ACK,这不仅用于快重传,会触发比快重传更快的恢复机制(Fast Retransmission)如果发现重复的ACK,但是报文中未发现缺口,这表示你捕获的是数据来源(而不是接收方),这是十分正常的如果数据在发往接收方的时候发生了丢失。你应该会看到一个重传包】
其实就是说服务器没有发现下一个包后面又发了3次(一共4次·)TCP DUP ACK 都是针对353的,所以后面客户端很快就重传了TCP DUP ACK 所指定的丢失的包(即下面看到的362)
后面还可以看到由于过快的速度,还造成了部分的失序列(out of order)。不过需要说明的是,这些错误在tcp的传输中是很常见的,tcp有自己的一套高效的机制对这些错误进行恢复,即便有这些错误的存在也不会对pipe的实际性能造成影响。
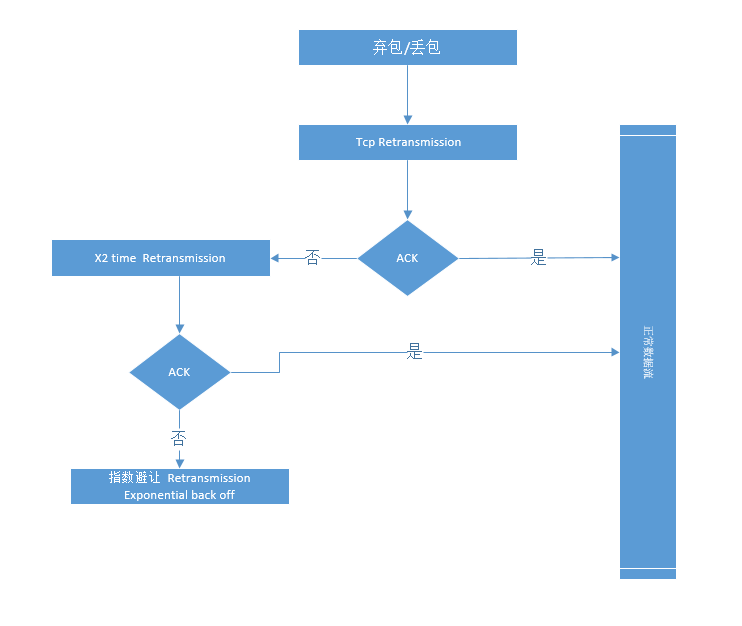
如果服务器异常误包不能马上被恢复可能会造成指数退避的情况如下图
![]()
高速收发带来的问题,不仅有丢包,失序,重传,无论是客户端还是服务器都会有接收窗口耗尽的情况,如果接收端窗口耗尽会出现TCP ZeroWIndow / Window full。 所以无论是客户端还是服务器都需要快速读取tcp缓冲区数据
![]()
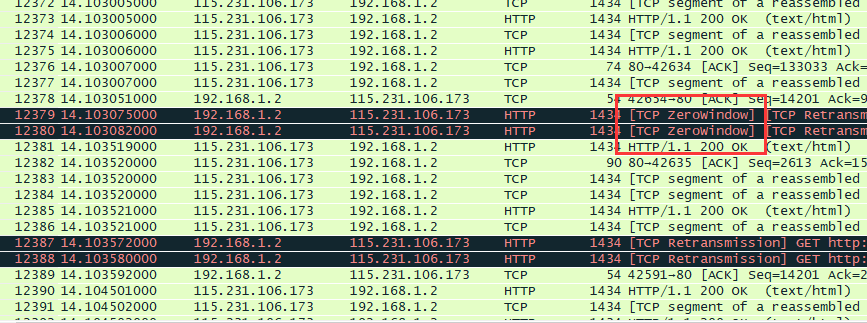
通过对TCP流的检查可以确定在本次测试中的部分管道的100条request是全部发出后,response才逐步被服务器发出
现在看一下response的回复情况
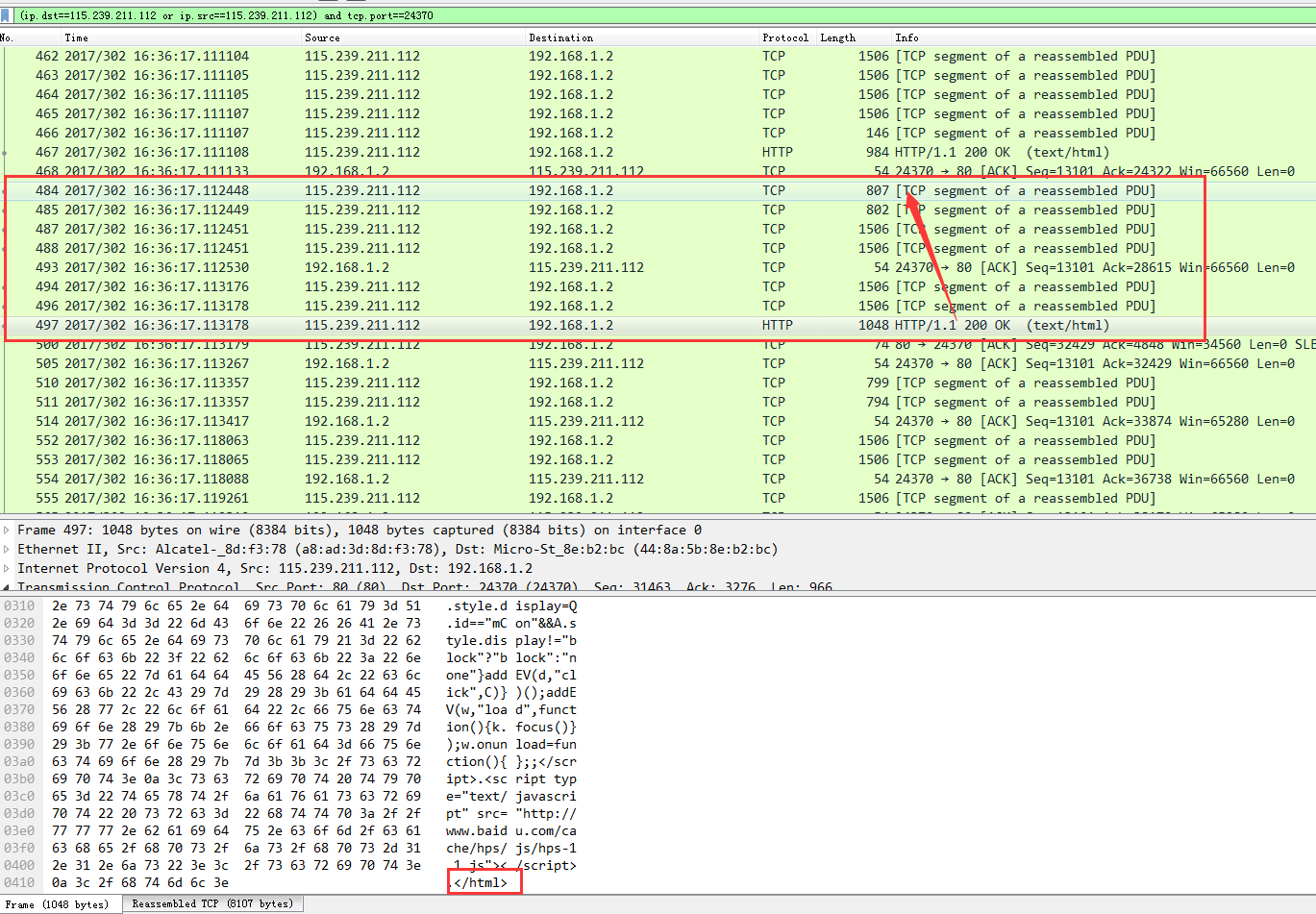
![]()
因为response本身很大,而客户端的MSS只有1460 (上面看到的1506不是超过了MSS的意思,实际该数据包只有1424,加上48个字节的TCP包头,20字节的ip包头,14字节的以太网包头一共是1506,正常tcp包头为20字节因为这个tcp包被拆包了,所以包头里多了28个字节的options)所以一个response被拆成了多个包。
通过报文不难看出这个response在网络中传输大概花了1ms不到的时间(大概730微秒),因为看到是过滤掉过端口(指定管道)的流量,实际上在这不到1ms的时间里另外的管道也是可能同时在接收数据的。
pipe之所以能比常规请求方式性能高出这么多,主要有以下几点
1:管线式发送,每条request不要等response回复即可直接发送下一个(重点不在于使用的是同一条线路,而且不约等待回复)
2:多条请求打包发送,在网络条件合适的情况下一个包可以包含多条request
3:只要服务器允许只需要创建极少tcp链接 (因为非局域网的TCP线路一般都遵循慢启动,网络正常情况下需要一定时间后效率才能达到最高)
现在我们可以来说下pipe弊端
实际pipe早就被http1.1所支持,并且大部分nginx服务器也支持并开启了这一功能。
相比普通的http keepalive传输 pipe http 解决了HOL blocking (Head-of-Line Blocking),而正是不再遵循一发一收的模式,使得应用层不能直接将每个请求与回复一一对应起来,对部分需要提交并区分返回结果的POST一类的请求,这种方式显的不是很友好。
解决方法其实也很简单,在应用服务上为request于response加上唯一标签即可以区分,或者直接使用HTTP2.0(https://tools.ietf.org/pdf/rfc7540.pdf)(这也是2.0的一个重要改进,http2.0也是通过类似的方式为其每个帧添加标识当前stream的id来实现区分的)
下面是pipe与常规http的简单对比
pipe 管线式HTTP
普通HTTP 1.1
使用同一条tcp线路
使用不同链接(支持keepalive 可以保持链接)
不用等待回复即可以直接发送下一个请求
同一个链接必须收到回复后才能发起下一个请求
一次/一包可以同时发送多个请求
一次只能发送一个请求
实现
如下为pipe的.NET简单实现类库,及应用该类库的deom 测试工具
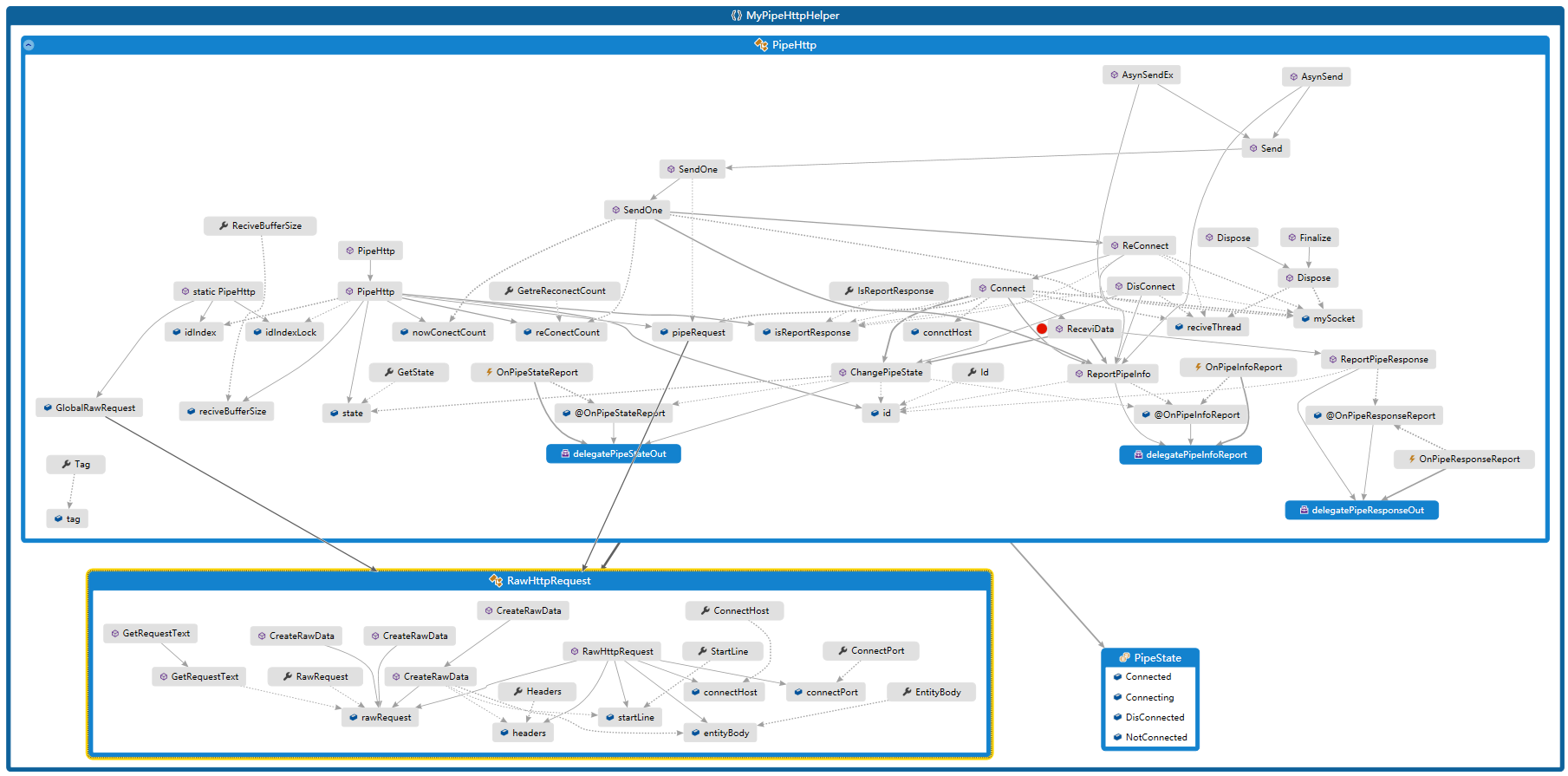
实现过程还是比较简单的可直接参看GitHub工程,
MyPipeHttpHelper为实现pipe的工具类(代码中有较详细的注释),PipeHttpRuner为使用该工具类编写的测试工具
![]()
https://github.com/lulianqi/PipeHttp/ (工程地址)
https://github.com/lulianqi/PipeHttp/tree/master/MyPipeHttpHelper (类库地址)
https://github.com/lulianqi/PipeHttp/tree/master/PipeHttpRuner (测试demo地址)