前言 ①python第三方库ddddocr(带带弟弟ocr)通用验证码识别。 ②环境要求:python版本=3.9。 调用方法 import ddddocr # 导入 ddddocr ocr = ddddocr.DdddOcr(use_gpu=False, device_id=0) # 实例化 file_name = 't
前言
①python第三方库ddddocr(带带弟弟ocr)通用验证码识别。
②环境要求:python版本<=3.9。
调用方法
import ddddocr # 导入 ddddocrocr = ddddocr.DdddOcr(use_gpu=False, device_id=0) # 实例化
file_name = 'test.png'
with open(file_name, 'rb') as f: # 打开图片
img_bytes = f.read() # 读取图片
content = ocr.classification(img_bytes=img_bytes) # 识别
print("识别到的内容 {}".format(content))
参数说明
Ddddocr 类接受两个实例参数
参数名
默认值
说明
use_gpu
False
Bool 是否使用gpu进行推理,如果该值为False则device_id不生效
device_id
0
int cuda设备号,目前仅支持单张显卡
classification() 方法需要一个参数
参数名
默认值
说明
img
0
bytes 图片的bytes格式
下载安装
pip install ddddocr运行如下:
实例1
图片示例:
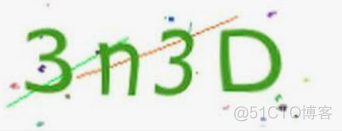
代码如下:
import ddddocrocr = ddddocr.DdddOcr()
file_name = 'test.png'
with open(file_name, 'rb') as f:
img_bytes = f.read()
content = ocr.classification(img_bytes)
print("识别到的内容 {}".format(content))
运行结果:

实例2
环境:win10 + python3.7 + selenium + ddddocr + PIL 实现自动化测试过程中识别验证码
from selenium import webdriverfrom selenium.webdriver.support.ui import WebDriverWait
import time
import ddddocr
from PIL import Image
import os
def getToken():
url = "http://localhost/#/login"
from selenium.webdriver.firefox.options import Options
firefox_options = Options()
firefox_options.headless = False
driver = webdriver.Firefox(options=firefox_options)
# 设置等待时间
waite = WebDriverWait(driver, 5)
driver.get(url)
driver.implicitly_wait(6)
# 1.先保存当前页面为一个png图
driver.get_screenshot_as_file("page.png")
inputname = driver.find_elements_by_class_name("el-input__inner")[0]
inputname.click()
inputname.send_keys("10000")
inputpassword = driver.find_elements_by_class_name("el-input__inner")[1]
inputpassword.send_keys("123456")
# choice = driver.find_element_by_class_name("person")
choice = driver.find_element_by_xpath('/html/body/div/div/div/div[1]/div/div[2]/div/div[2]/div[2]')
choice.click()
# 2.然后将页面截图中的验证码截取出来
image = Image.open("page.png")
captchaurl = driver.find_element_by_class_name("login-code-img")
left = captchaurl.location.get("x")
top = captchaurl.location.get("y")
right = left + captchaurl.size.get("width")
bottom = top + captchaurl.size.get("height")
cropImg = image.crop((left, top, right, bottom))
cropImg.save("code.png")
# 3.读取验证码图
with open('code.png','rb') as f:
content_captcha = f.read()
# print(content_captcha)
# 4.此处是重点,解析验证码,得到4位数字,只需要2行代码
ocr = ddddocr.DdddOcr()
code = ocr.classification(content_captcha)
print(code)
inputcaptcha = driver.find_elements_by_class_name("el-input__inner")[2]
inputcaptcha.send_keys(code)
button = driver.find_element_by_tag_name("button")
button.click()
# logs = driver.get_log('performance')
cookie = driver.get_cookies()
print(cookie)
if cookie != []:
token = cookie[0]['value']
else:
token = ""
driver.quit()
return token
token = ""
result = False
while result == False:
token = getToken()
if token != "":
result = True
print(token)
未完成:
python3安装OCR识别库tesserocr过程图解
去期待陌生,去拥抱惊喜。