文章目录 scrapy框架图示 完成第一个示例 scrapy框架图示 完成第一个示例 创建项目 scrapy startproject 项目名字 scrapy startproject labSpider 创建爬虫 scrapy genspider 爬虫名字 域名
文章目录
- scrapy框架图示
- 完成第一个示例
scrapy框架图示
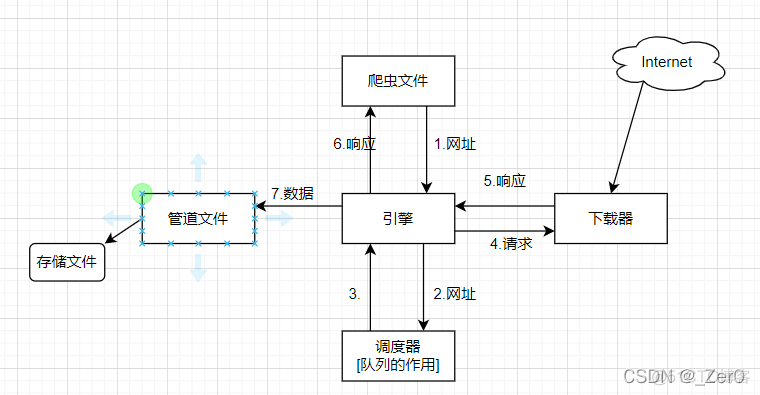

完成第一个示例
创建项目
scrapy startproject 项目名字
创建爬虫
scrapy genspider 爬虫名字 域名
编写spiders目录下的爬虫文件
编辑piplines.py文件,修改settings.py的ITEM_PIPELINES,取消注释。用于配置管道文件处理每一个数据项。
配置请求头编辑settings.py
给DEFAULT_REQUEST_HEADERS添加一个User-Agent头。
编辑爬虫文件lab.py
import scrapyfrom labSpider.items import LabspiderItem
class LabSpider(scrapy.Spider):
name = 'lab'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
selectors = response.xpath('//div') # 获取所有div标签
# 获取页面中的数据
for selector in selectors:
text = selector.xpath('./span[1]/text()').get() # 获取内容
author = selector.xpath('./span[2]/small/text()').get() # 获取相应作者
if text and author:
# print(text, author)
item = LabspiderItem()
item['text'] = text
item['author'] = author
yield item
# 翻页操作
next_page = response.xpath('//li[@class="next"]/a/@href').get()
# 没到最末页
if next_page:
# 拼接网址
next_url = response.urljoin(next_page)
# yield生成器,回调到自己parse函数
yield scrapy.Request(next_url, callback=self.parse)
编辑items.py
# Define here the models for your scraped items#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class LabspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
text = scrapy.Field()
author = scrapy.Field()
编辑pipelines.py文件
# Define your item pipelines here#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class LabspiderPipeline(object):
def open_spider(self, spider):
self.f = open("./res.txt", "w")
def close_spider(self, spider):
self.f.close()
def process_item(self, item, spider):
try:
data = str(dict(item)) + '\n'
self.f.write(data)
except Exception as e:
print(e)
return item
运行爬虫
scrapy crawl 爬虫名字
最终效果是将网站中的标题和作者存储到文本文件。