1、prometheus概述
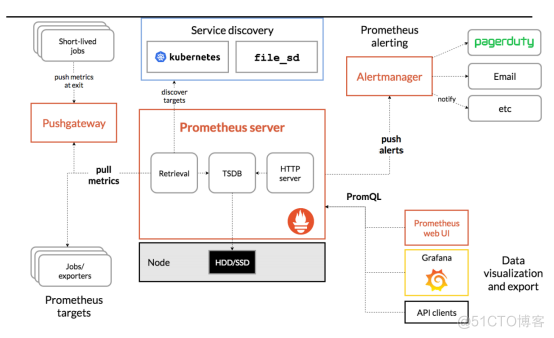
prometheus监控系统主要有pushgateway、prometheus server、alertmanager、prometheus web UI Grafana这些组件组成。
prometheus server主要有Retrieval,Storage,PromQL组成。
- Retrieval在活跃的target主机上抓取监控指标数据
- Storage把采集到的数据存储到磁盘中
- PromQL提供查询语言模块
工作流程:
- prometheus server定期从活跃的目标主机上拉取监控指标数据目标主机监控数据可配置静态job或服务发现方式被prometheus server采集到,默认方式是pull方式拉取指标,也可以通过pushgateway把采集的数据上报到prometheus server中,还可以通过一些组件自带的exporter采集相应组件的数据;
- promethues server把采集到的监控指标数据保存到本地磁盘或数据库;
- prometheus采集的监控指标数据按时间序列存储,通过配置报警规则,把触发的报警发送到alertmanager;
- alertmanager通过配置报警接收方,发送报警到邮件,微信或钉钉等;
- grafana可接入prometheus数据源,把监控数据以图形化形式展示出来。
2、kubernetes基础环境
master01
node01
192.168.2.73
192.168.2.74
centos76
centos76
8c8g
8c8g
2.1、docker基础环境(两个节点)
配置host
# vim /etc/hosts
192.168.2.73 master01
192.168.2.74 node01
配置免密相互免密
# ssh-keygen
# ssh-copy-id 192.168.2.73
# ssh-copy-id 192.168.2.74
关闭防火墙和selinux
# systemctl stop firewalld ; systemctl disable firewalld
# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
修改内核参数
#加载br_netfilter模块
# modprobe br_netfilter
#验证模块是否加载成功:
# lsmod |grep br_netfilter
#修改内核参数
# cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
#使刚才修改的内核参数生效
# sysctl -p /etc/sysctl.d/k8s.conf
配置yum源,配置至/etc/yum.repos.d/
安装iptables
# yum install iptables-services -y
# service iptables stop && systemctl disable iptables
# iptables -F
# chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs
# yum install -y yum-utils device-mapper-persistent-data lvm2 wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip sudo ntp libaio-devel wget vim ncurses-devel autoconf automake zlib-devel python-devel epel-release openssh-server socat ipvsadm conntrack ntpdate telnet rsync lrzsz
安装docker-ce和镜像加速源
# yum install docker-ce docker-ce-cli containerd.io -y
# systemctl start docker && systemctl enable docker.service && systemctl status docker
# tee /etc/docker/daemon.json << 'EOF'
{
"registry-mirrors":["https://rsbud4vc.mirror.aliyuncs.com","https://registry.docker-cn.com","https://docker.mirrors.ustc.edu.cn","https://dockerhub.azk8s.cn","http://hub-mirror.c.163.com","http://qtid6917.mirror.aliyuncs.com", "https://rncxm540.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
# systemctl daemon-reload
# systemctl restart docker
# systemctl status docker
时间同步
# yum install ntpdate -y
# crontab -e
*/5 * * * * /usr/sbin/ntpdate ntp1.aliyun.com
关闭交换分区swap,提升性能
# swapoff -a
# vim /etc/fstab
#/dev/mapper/centos-swap swap swap defaults 0 0
# mount
2.2、kubernetes基础环境
软件包:busybox-1-28.tar.gz k8simage-1-20-6.tar.gz k8s.repo calico.yaml
安装初始化k8s需要的软件包
将k8s.repo的YUM文件上传至/etc/yum.repos.d/目录下
# yum install -y kubelet-1.20.6 kubeadm-1.20.6 kubectl-1.20.6
# systemctl enable kubelet && systemctl start kubelet
# systemctl status kubelet
解压k8simage-1-20-6.tar.gz,同时两个节点都需要上传这个镜像包
# docker load -i k8simage-1-20-6.tar.gz
在master01节点操作如下(注意写自己主机IP)
# kubeadm init --kubernetes-version=1.20.6 --apiserver-advertise-address=172.16.90.73 --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=10.244.0.0/16 --ignore-preflight-errors=SystemVerification
# mkdir -p $HOME/.kube
# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
# chown $(id -u):$(id -g) $HOME/.kube/config
在node01节点操作如下(特别注意自己主机IP,以下命令是上面master01执行成功后会打印到屏幕上,可以直接使用)
# kubeadm join 192.168.2.73:6443 --token bligdo.0nrcvlwrdamdbkjd \
--discovery-token-ca-cert-hash sha256:285e0f44846819e66a13074a7263d18456c20c92feca35253d8ba9473dcf7e0e
修改node标签(在master01节点)
# kubectl label node node01 node-role.kubernetes.io/worker=worker
由于目前为止并无网络,因此需要安装网络插件(在master01节点执行即可)
# kubectl apply -f calico.yaml
为了方便监控,开启kube-proxy、scheduler、controller远程端口(在master01节点)
# vim /etc/kubernetes/manifests/kube-scheduler.yaml
- ;--bind-address=192.168.2.73
host: 192.168.2.73
host: 192.168.2.73
原来这三个地方是127.0.0.1修改成本机IP地址
并且去掉 - ;--port=0
# vim /etc/kubernetes/manifests/kube-controller-manager.yaml
- ;--bind-address=192.168.2.73
- ;--port=0 --去掉
host: 192.168.2.73
host: 192.168.2.73
原来这三个地方是127.0.0.1修改成本机IP地址
# systemctl restart kubelet
# kubectl edit cm kube-proxy -n kube-system
metricsBindAddress: "0.0.0.0:10249"
# kubectl get pods -n kube-system | grep kube-proxy |awk '{print $1}' | xargs kubectl delete pods -n kube-system
测试dns(在node01)解压镜像包
# docker load -i busybox-1-28.tar.gz
在master上登陆busyboxpod测试dns
# kubectl run busybox --image busybox:1.28 --restart=Never --rm -it busybox -- sh
If you don't see a command prompt, try pressing enter.
/ # nslookup kubernetes.default.svc.cluster.local
Server: 10.10.0.10
Address 1: 10.10.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes.default.svc.cluster.local
Address 1: 10.10.0.1 kubernetes.default.svc.cluster.local
/ # ping www.baidu.com
PING www.baidu.com (14.215.177.39): 56 data bytes
64 bytes from 14.215.177.39: ;seq=0 ;ttl=127 ;time=8.753 ms
64 bytes from 14.215.177.39: ;seq=1 ;ttl=127 ;time=10.323 ms
3、prometheus+alertmanager+grafana
3.1、prometheus存储卷
nfs存储卷:monitor-nfs-claim.yaml monitor-nfs-deploment.yaml monitor-nfs-storageclass.yaml
monitor-serviceaccount.yaml nfs-subdir-external-provisioner.tar.gz
pvc存储卷至nfs创建流程:
- 服务端和客户端安装nfs服务,在服务端创建共享目录
- 如有需要单独名称空间,则创建名称空间
- 创建sa账号并且账号授权
- 安装nfs-provisioner服务
- 通过storageclass创建pv
- 通过persistentvolumeclaim创建pvc
- 通过pvc的名称挂载使用
在master01和node01节点上安装nfs服务
# yum -y install nfs-utils
# service nfs start
# systemctl enable nfs
在master01节点作为服务端
# vim /etc/exports
/data/monitor 192.168.2.0/24(rw,no_root_squash)
# mkdir -pv /data/monitor
# chmod -R 777 /data/monitor
# exportfs -arv
# showmount -e 192.168.2.73
在node01节点安装nfs-subdir-external-provisioner.tar.gz
# docker load -i nfs-subdir-external-provisioner.tar.gz
在master01创建sa账号
# kubectl apply -f monitor-serviceaccount.yaml
sa账号授权
# kubectl create clusterrolebinding nfs-provisioner-clusterrolebinding --clusterrole=cluster-admin --serviceaccount=default:nfs-provisioner
设置共享目录和安装nfs-provisioner程序
monitor-nfs-deploment.yaml资源清单文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-provisioner
spec:
selector:
matchLabels:
app: nfs-provisioner
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: nfs-provisioner
spec:
nodeName: node01
serviceAccount: nfs-provisioner #上一步中的sa账号
containers:
- name: nfs-provvisioner
image: registry.cn-beijing.aliyuncs.com/mydlq/nfs-subdir-external-provisioner:v4.0.0 #特别注意是为上述中的镜像版本
imagePullPolicy: IfNotPresent
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: example.com/nfs #关联至pv的provisioner字段
- name: NFS_SERVER
value: 192.168.2.73 # nfs服务器地址,根据实际情况修改
- name: NFS_PATH
value: /data/monitor #nfs共享的目录,根据实际情况修改
volumes:
- name: nfs-client-root
nfs:
server: 192.168.2.73
path: /data/monitor# kubectl apply -f monitor-nfs-deploment.yaml
通过storageclass创建pv
monitor-nfs-storageclass.yaml资源清单文件如下:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-monitor #关联至pvc的storageclassname字段
provisioner: example.com/nfs #创建nfs-provisioner的env# kubectl apply -f monitor-nfs-storageclass.yaml
创建一个单独的名称空间
# kubectl create ns monitor-sa
通过persistentvolumeclaim创建pvc
注意如果pvc和pod不在同一个名称空间下,会出现如下图报错:

monitor-nfs-claim.yaml资源清单文件如下:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus
namespace: monitor-sa
spec:
accessModes: ["ReadWriteMany"]
resources:
requests:
storage: 10Gi
storageClassName: nfs-monitor #与pv进行关联# kubectl apply -f monitor-nfs-claim.yaml
以上操作完成nfs存储卷的创建。

3.2、alertmanager微信告警配置
创建微信地址:https://work.weixin.qq.com/nl/sem/registe?s=c&from=1011017349&bd_vid=8204533222119969491
企业微信告警配置文件alertmanager-wx.yaml:
kind: ConfigMap
apiVersion: v1
metadata:
name: alertmanager
namespace: monitor-sa
data:
alertmanager.yml: |
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '****' #163邮箱
smtp_auth_username: '******'
smtp_auth_password: '********' #163邮箱授权码
smtp_require_tls: false
templates:
- "/usr/local/prometheus/alertmanager/template/default.tmpl"
route:
group_by: [alertname]
group_wait: 10s
group_interval: 10s
repeat_interval: 10m
receiver: prometheus
receivers:
- name: 'prometheus'
wechat_configs:
- corp_id: 企业信息("我的企业"--->"CorpID"[在底部])
to_user: '@all'
agent_id: 企业微信("企业应用"-->"自定应用"[Prometheus]--> "AgentId")
api_secret: 企业微信("企业应用"-->"自定应用"[Prometheus]--> "Secret")# kubectl apply -f alertmanager-wx.yaml
设置微信告警模板
alertmanager-wx-template-configmap.yaml资源清单文件:
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: null
name: alertmanager-templates
namespace: monitor-sa
data:
default.tmpl: |
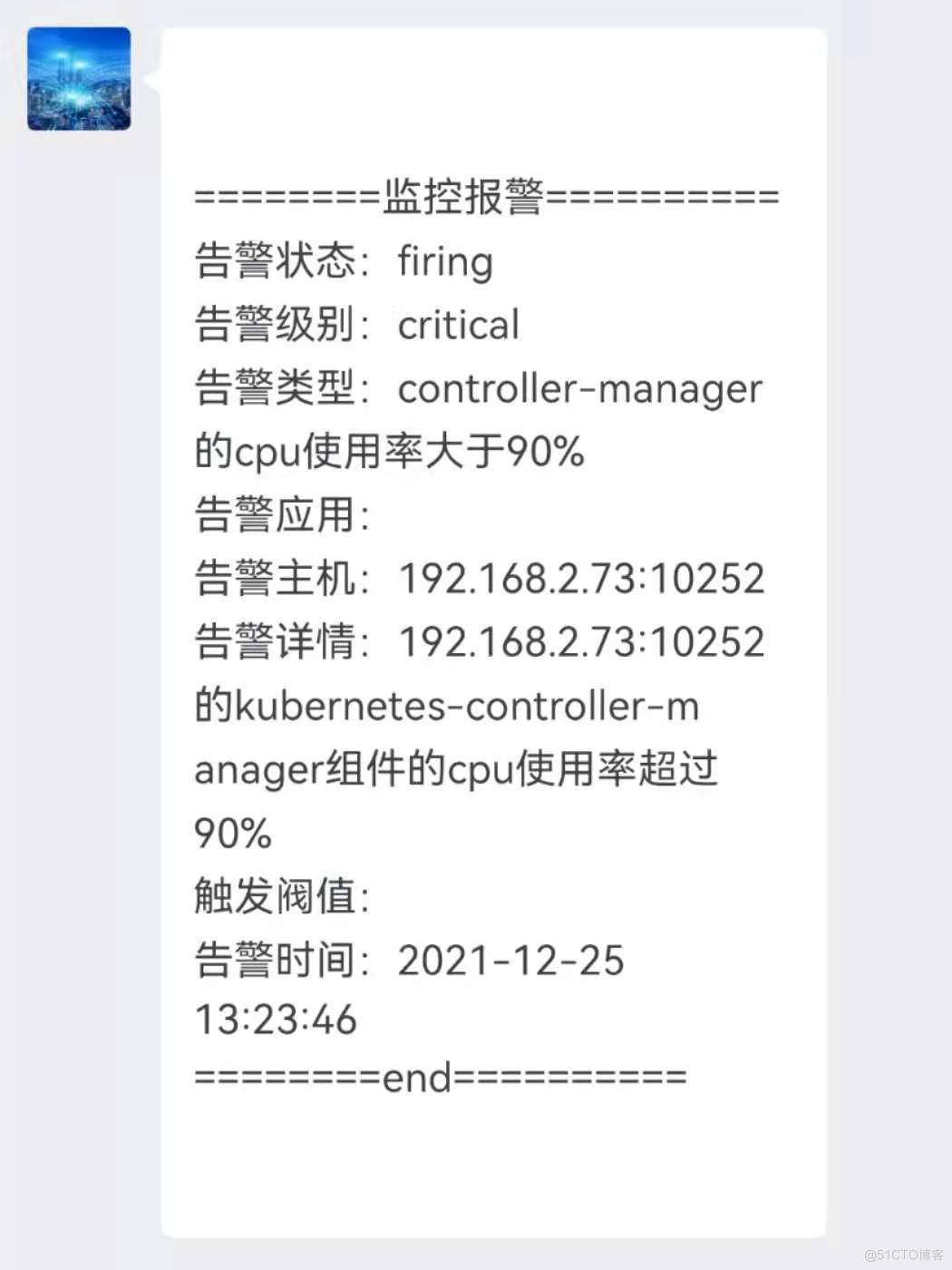
{{ define "wechat.default.message" }}
{{ range $i, $alert :=.Alerts }}
========监控报警==========
告警状态:{{ .Status }}
告警级别:{{ $alert.Labels.severity }}
告警类型:{{ $alert.Labels.alertname }}
告警应用:{{ $alert.Annotations.summary }}
告警主机:{{ $alert.Labels.instance }}
告警详情:{{ $alert.Annotations.description }}
触发阀值:{{ $alert.Annotations.value }}
告警时间:{{ $alert.StartsAt.Format "2006-01-02 15:04:05" }}
========end==========
{{ end }}
{{ end }}# kubectl apply -f alertmanager-wx-template-configmap.yaml
3.3、部署prometheus-alertmanager
#创建一个sa账号monitor
# kubectl create serviceaccount monitor -n monitor-sa
#把sa账号monitor通过clusterrolebing绑定到clusterrole 上
# kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
# kubectl -n monitor-sa create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt
创建prometheus和alertmanager配置文件
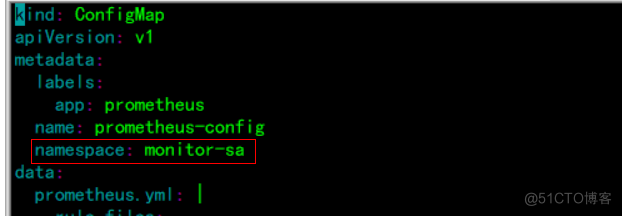
特别注意自己创建的命名空间是否这个一致
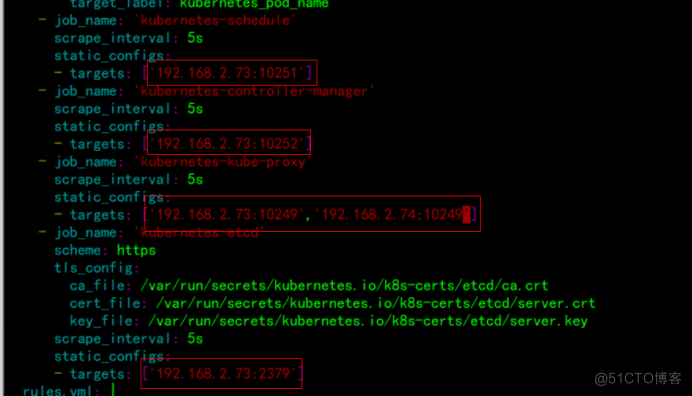
特别注意修改自己主机IP地址
# kubectl apply -f prometheus-alertmanager-cfg.yaml
prometheus+alertmanager服务资源清单文件prometheus-alertmanager-deploy.yaml
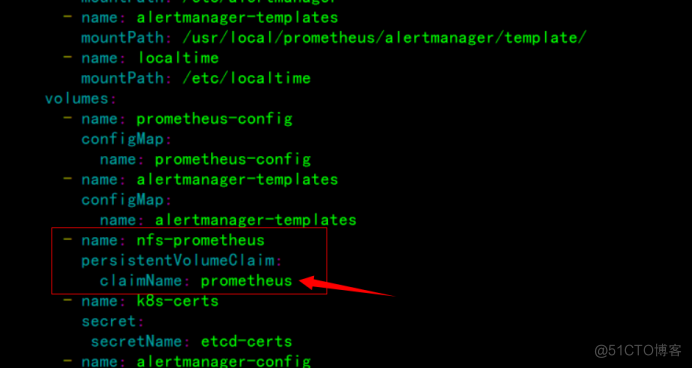
挂载之前通过nfs创建pvc存储卷
将prometheus和alertmanager镜像上传至node01节点
# docker load -i alertmanager.tar.gz
# docker load -i prometheus-2-2-1.tar.gz
# kubectl apply -f prometheus-alertmanager-deploy.yaml
prometheus+alertmanager添加service(alertmanager-svc.yaml、prometheus-svc.yaml)
# kubectl apply -f alertmanager-svc.yaml
# kubectl apply -f prometheus-svc.yaml
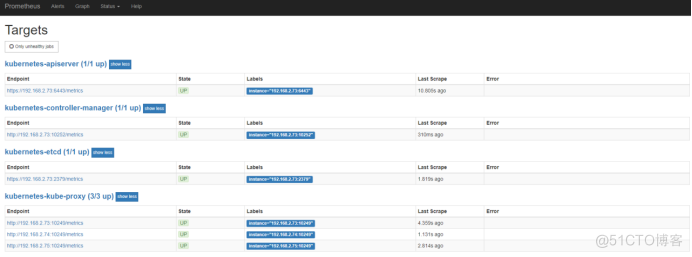
prometheus的targets界面
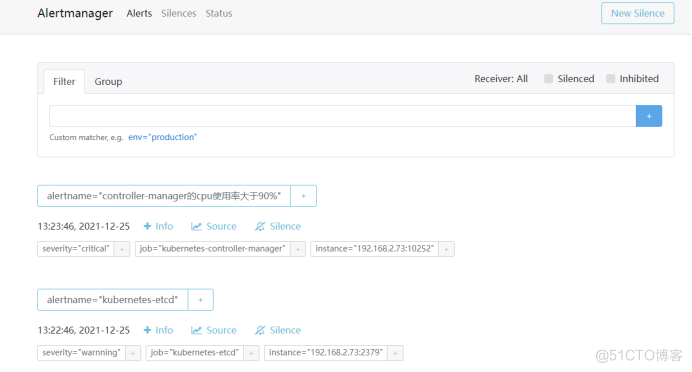
alertmanager告警界面
企业微信的告警信息
4、监控采集方式
4.1、node-exporter
node-exporter 可以采集机器(物理机、虚拟机、云主机等)的监控指标数据,能够采集到的指标包
括 CPU, 内存,磁盘,网络,文件数等信息。
在master01和node01节点上解压镜像
# docker load -i node-exporter.tar.gz
在master01执行资源清单文件
# kubectl apply -f node-export.yaml
在prometheus查看监控

4.2、pushgateway
在node01节点解压镜像并且启动镜像
# docker load -i pushgateway.tar.gz
# docker run -d --name=pushgateway -p 9091:9091 prom/pushgateway:latest
在master01节点增加一个关于job配置并且更新configmap(prometheus-alertmanager-cfg.yaml )
- job_name: 'pushgateway'
scrape_interval: 5s
static_configs:
- targets: ['192.168.2.74:9091']# kubectl apply -f prometheus-alertmanager-cfg.yaml
# kubectl delete -f prometheus-alertmanager-deploy.yaml
# kubectl apply -f prometheus-alertmanager-deploy.yaml
prometheus web页面查看连接情况

在node01节点通过pushgateway web管理页面看到,暂时为空,没有数据

在master01上模拟服务数据推送至pushgateway,然后pushgateway将数据转给prometheus
# vim push.sh
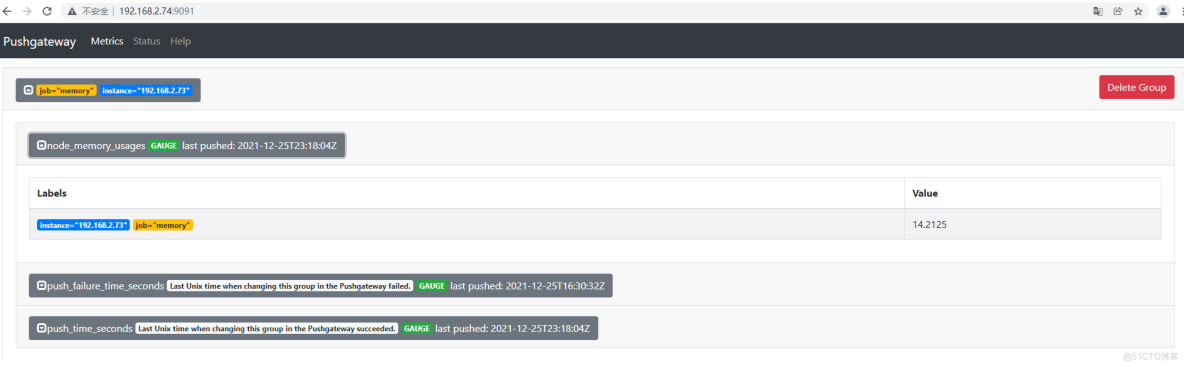
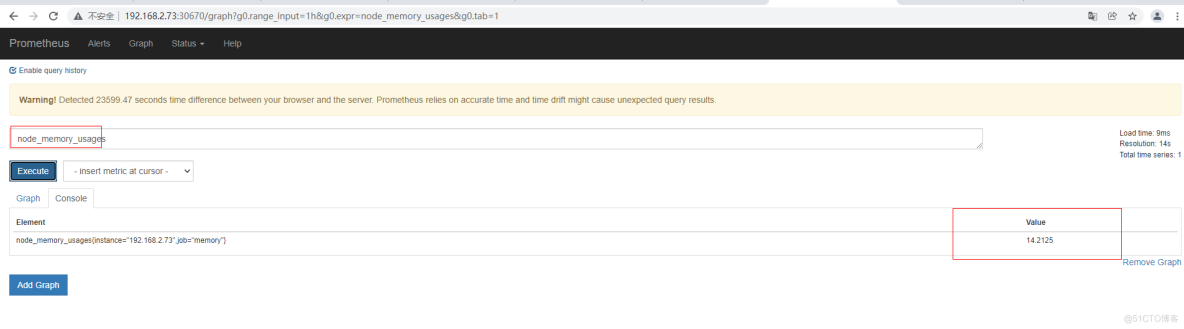
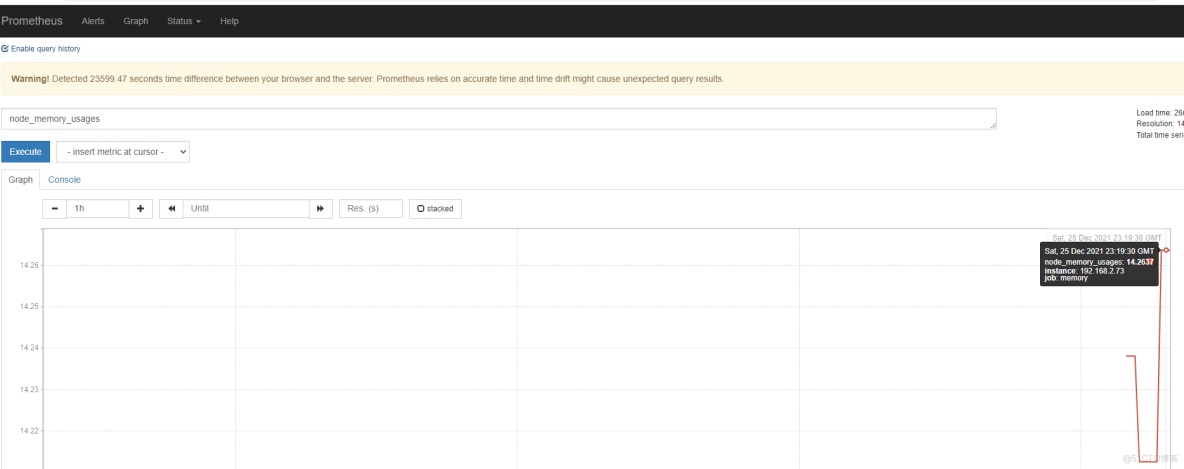
node_memory_usages=$(free -m | grep Mem | awk '{print $3/$2*100}')
job_name="memory"
instance_name="192.168.2.73"
cat <<EOF | curl --data-binary @- http://192.168.2.74:9091/metrics/job/$job_name/instance/$instance_name
#TYPE node_memory_usages gauge
node_memory_usages $node_memory_usages
EOF
# crontab -e
* * * * /bin/bash /root/push.sh
在pushgateway web管理页面查看数据
在prometheus查看数据
5、grafana数据可视化
5.1、grafana基础配置
在node01节点解压grafana镜像
# docker load -i heapster-grafana-amd64_v5_0_4.tar.gz
在master01节点更新grafana资源清单文件
# kubectl apply -f grafana.yaml
添加数据源
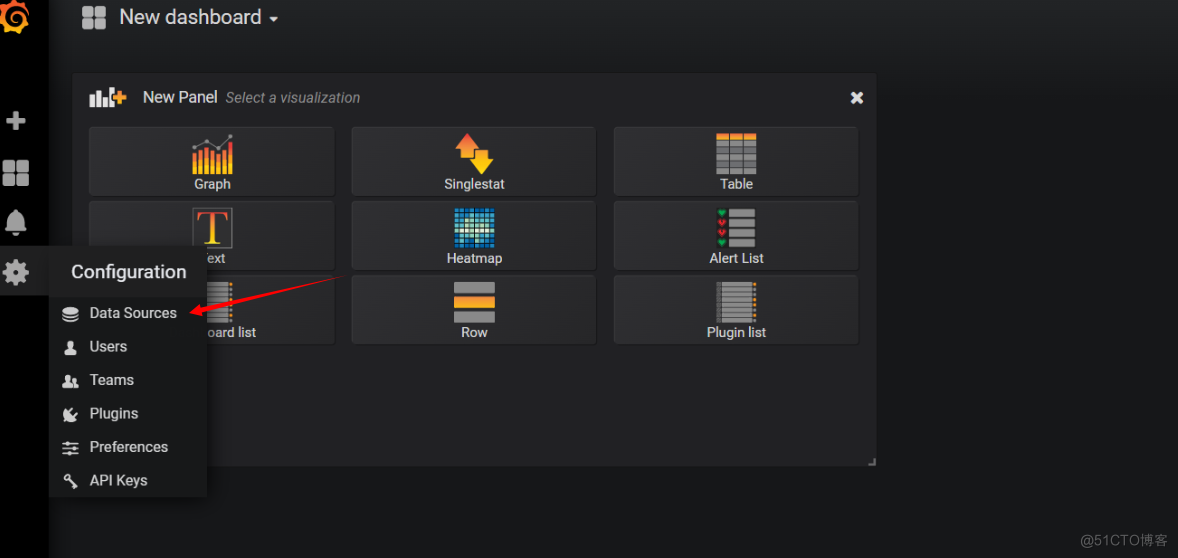
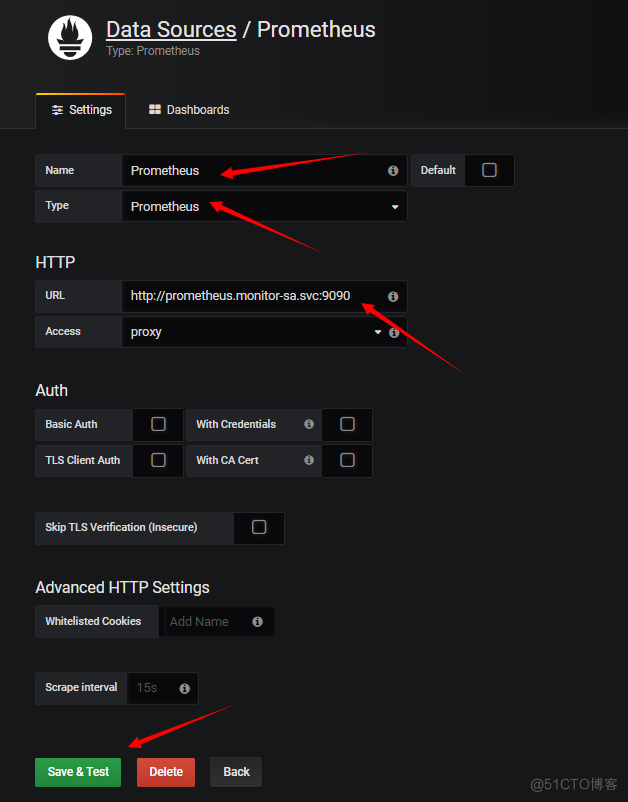
特别注意:name:Prometheus首字母大写
5.2、node模板导入(用于监控节点服务器资源)
导入模板
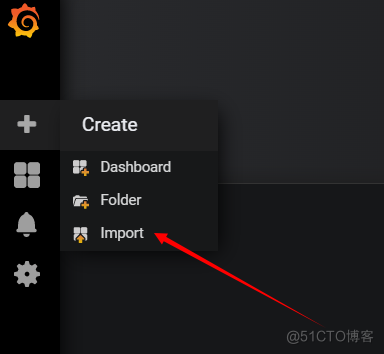
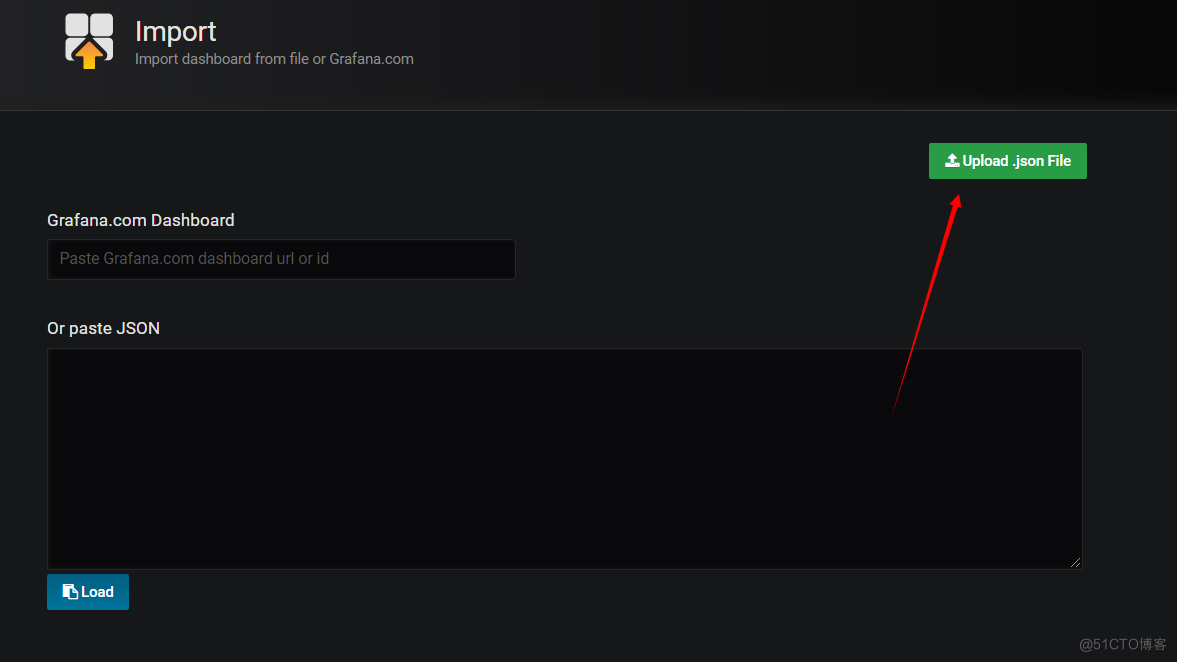
导入主机监控模板

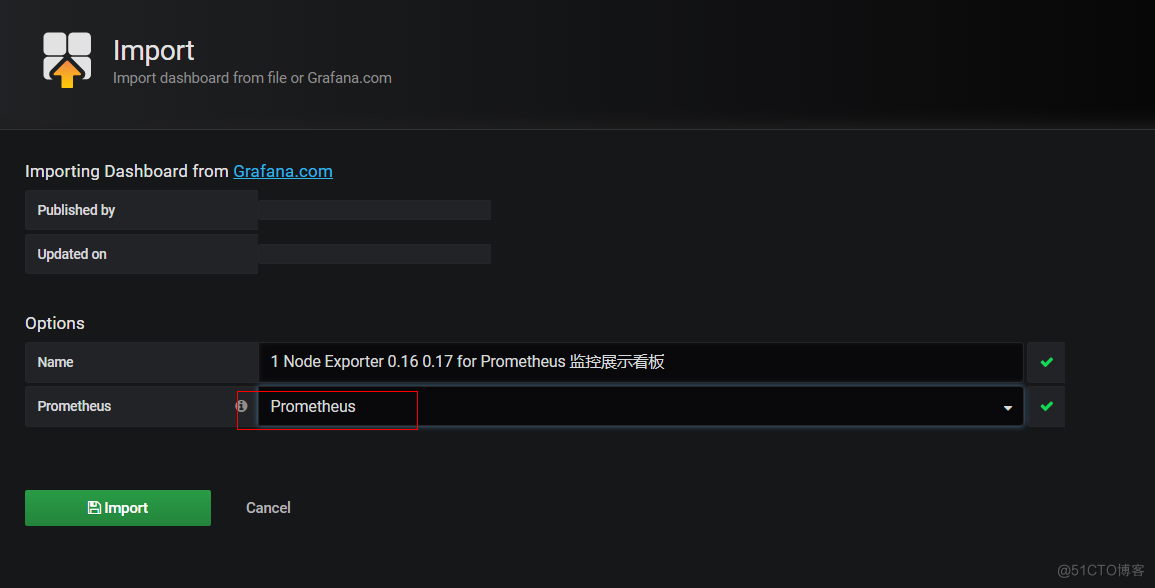
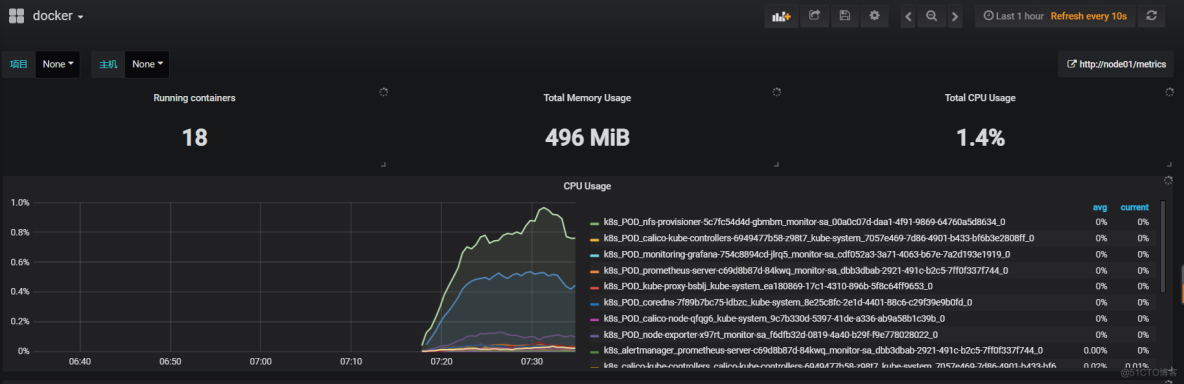
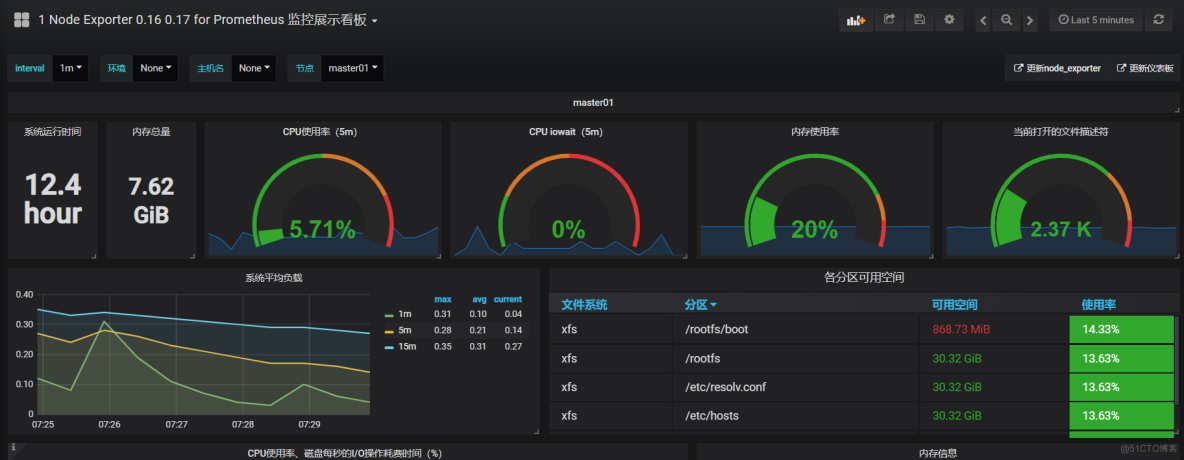
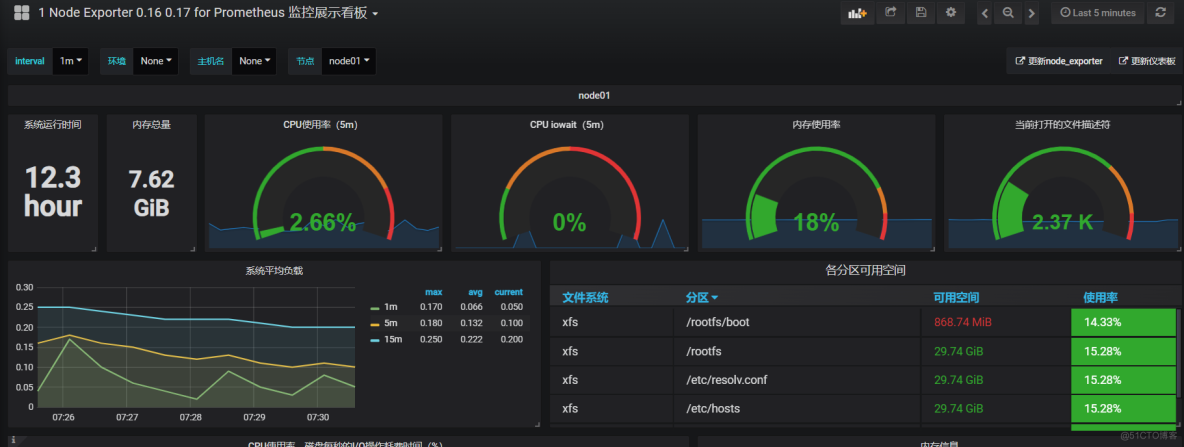
grafana数据展示
5.3、docker模板导入(用于监控pod资源)