1.C++数据类型简介
C++是一种强类型语言,任何变量或函数必须遵循“先申明后使用”的原则。定义数据类型有两个方面的作用:一是决定该类型的数据在内存中如何存储,二是决定可对该类型的数据进行哪些合法的运算。
C++的数据类型分为基本数据类型和非基本数据类型。其中非基本数据类型称为复合数据类型或构造数据类型。为了能够体现C++语言和传统C语言在非基本数据类型上的区别,在这里把能够体现面向对象特性的非基本数据类型成为构造函数类型,而将其他非基本数据类型称为复合数据类型。C++的数据类型数据如下图所示:
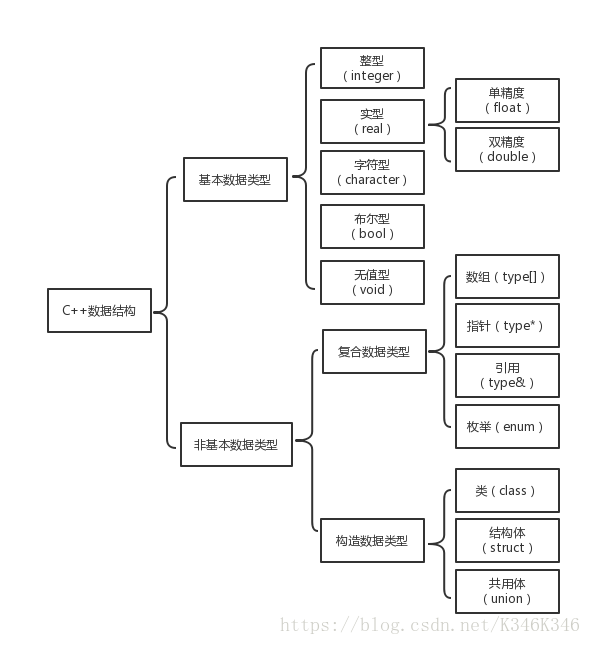
基本数据类型是C++内部预定义的,又叫内置(built-in)数据类型。非基本数据类型则是用户根据需要按照C++语法规则创建的数据类型。在这里,构造数据类型和复合数据类型的区别在于:构造数据类型的实例叫做对象,它是属性和方法的集合。复合数据类型的实例叫变量,变量本身并无成员函数。构造数据类型的一个显著特征是在生成该数据类型的一个实例时,会自动调用该类型定义的构造函数。也就是说,构造数据类型实例的初始化工作是由构造函数完成的。
**注意:**用基本数据类型定义变量时,类型出现在前面,变量直接跟在类型之后。但是用复合数据类型定义变量时,变量却不一定完全位于类型之后。例如,定义一个数组int a[8],标识符a的数据类型是int[8],但是它出现在数据类型的中间部位。另外,定义或申明变量时,类型外一定不能加括号,例如用这种方式定义一个指针是不对的:(int*)p;,它的真实含义是将p转换为int*类型,是强制类型转换的语法形式。
2.宽字符型与单字符型
传统的字符型char是单字节字符型,存储的是该字符的ASCII码,占用一个字节。也可以把char理解成单字节整型,取值范围是-128~127。单字节无符号整数可以用unsigned char表示,取值范围是0-255。
VC++中,如果在一个字符串中包含汉字,每个汉字占用2个字节,每个字节的最高位都是1,宽字符占用多少字节与编译器的具体实现有关,以保证能够存储Unicode字符。VC++将wchar_t实现为2个字节,2个字节很显然不能表示所有的Unicode字符,但是通过当前系统的语言环境进行编码转换,两个字节最大能够表示65536个字符,足以表示某个国家的文字。
单字节字符是无法容纳一个汉字字符的,如定义char c='好';将得到一条编译警告信息,并且只有低字节编码会存放在字符变量c中。
C++语言同时支持宽字符类型(wchar_t),用于表示Unicode字符。为了支持Unicode字符的处理,C++在库函数中定义了相应的Unicode字符的处理函数,并将这些函数的申明放在了头文件<cstring>中。
Visual C++中whar_t和char是两种不同的数据类型,它们的存储结构和使用方法都不一样。见如下例子。
#include <iostream>
using namespace std;
int main(int argc,char* argv[])
{
char* p;
wchar_t s[]=L"ABC";
char name[]="张三";
wchar_t wname[]=L"张三";
cout<<sizeof(wchar_t)<<" "; //输出2
cout<<sizeof(s)<<endl; //输出8
p=(char*)s;
for(int i=0;i<sizeof(s);++i)
cout<<(int)p[i]<<" ";
cout<<endl;
cout<<s<<" ";
wcout<<s<<endl;
for(int i=0;i<sizeof(name);++i)
cout<<(int)name[i]<<" ";
cout<<endl;
p=(char*)wname;
for(int i=0;i<sizeof(wname);++i)
cout<<(int)p[i]<<" ";
cout<<endl;
cout<<name<<endl;
//setlocale(LC_ALL, "chs"); //加上此句下面的wname才会输出
wcout<<wname<<endl;
}
程序输出结果:
2 8
65 0 66 0 67 0 0 0
0048FC0C ABC
-43 -59 -56 -3 0
32 95 9 78 0 0
张三
阅读以上程序,得出如下结论:
(1)wchar_t和char是不同的数据类型,数据宽度也不一样,sizeof(char)==1,wchar_t的数据宽度与编译器的实现有关,再根据当前系统语言环境进行编码转换,足以保证存储Unicode字符,在Visual C++中 wchar_t占用两个字节。
(2)定义一个wchar_t类型的字符串时,要以L开头,否则出现编译错误。定义一个wchar_t类型的字符常量,也需要以L开头,例如wchar_t wc=L'A',如果去掉L,编译器会自动执行由char到wchar_t的转换。
(3)对于西文字符(如'A'、‘B'、'C'等)来说,在wchar_t类型的变量中,高字节存放的是0x00,低字节存放的是西文字符的ASCII码值。
(4)char类型的字符串以单字节'\0'结束,wchar_t类型的字符串以双字节'\0\0'结束。
(5)Windows7中文简体环境中一个汉字占用两个字节,采用的是GBK 编码,所以char类型的字符串中一个汉字占用两个字节表示,这两个字节的最高位都是1,只有这样,才能将它们与西文字符区别开来,所以将它们的ASCII码输出时得到两个负数。在wchar_t类型的字符串中,每个汉字都用双字节表示,采用的是UTF-16编码方式,因此相同的中文字符,存储的码值是不同的。UTF-16编码与ASCII编码不兼容,所以上面的代码中用cout输出L"ABC"无法正常输出。还有就是UTF-16编码将常用的字符采用两个字节进行存储,不常用的汉字采用四个字节存储,因此用wchar_t存储UTF-16编码中四个字节的汉字会产生数据丢失,无法正确存储。
(6)在上面的程序中,语句cout<<name<<endl;的输出结果是"张三",而语句wcout< <wname< <endl;却无法正常看到输出。如果字符串wname中全是西文字符,则仍然可以看到输出,这是在控制台程序中的一个现象,与控制台的缺省语言环境的设置有关,即设置采用什么编码方式输出。通过setlocale来设置语言环境后,进行编码转换,见程序中的代码。
以上就是浅析C++ 数据类型的详细内容,更多关于C++ 数据类型的资料请关注自由互联其它相关文章!