kubernetes通过vertica pod autoscaler实现动态垂直缩放
今天给大家分享一下k8s的垂直缩放这块,生产中你可能对request的值配置不知道如何进行配置,设置的大小也不太清楚,大多数配置request都是自己去估量的去配置request,可能就是以自己项目可能的预期大小去配置,甚至直接和limit配置成一样,但对于request决定了你节点可以跑多少个pod,如果设置的过大,那么有可能你的pod就用不了那么多,也会造成资源的一些浪费,如果不设置,默认就共享宿主机的资源,你又不能评估出你节点还剩多少可利用的资源来使用,设置的太小,服务有可能还会起不来,那么如何更好的合理去利用自己的资源,这就是我们需要重要考虑的事情
pod垂直扩容会涉及到request的概念,所以这里我会多啰嗦一下request到底是怎么回事和docker的cpu shares又有什么关系?
垂直容器自动缩放器(VPA)简单说就是使用户无需设置最新的资源限制和对容器中容器的要求。 配置后,它将根据使用情况自动设置请求,从而允许在节点上进行适当的调度,以便为每个Pod提供适当的资源量。 它还将保持限制和初始容器配置中指定的请求之间的比率。
它既可以根据资源的使用情况来缩减对资源过度使用的Pod的规模,也可以对资源需求不足的向上扩展的Pod的规模进行扩展。自动缩放是使用称为VerticalPodAutoscaler的自定义资源定义对象配置的。 它允许指定哪些吊舱应垂直自动缩放,以及是否/如何应用资源建议。
简单来说是 Kubernetes VPA 可以根据实际负载动态设置 pod resource requests。
说到资源限制前面说一下request这块到底是怎么回事?
在我们使用kubernetes的过程中,我们知道Pod 是最小的原子调度单位。这也就意味着,所有跟调度和资源管理相关的属性都应该是属于 Pod 对象的字段。而这其中最重要的部分,就是 Pod 的 CPU 和内存配置,如下所示:
apiVersion: apps/v1 kind: Deployment metadata: creationTimestamp: null labels: app: nginx name: nginx spec: replicas: 1 selector: matchLabels: app: nginx strategy: {} template: metadata: creationTimestamp: null labels: app: nginx spec: containers: - image: nginx name: nginx resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m"在 Kubernetes 中,像 CPU 这样的资源被称作“可压缩资源”(compressible resources)。它的典型特点是,当可压缩资源不足时,Pod 只会“饥饿”,但不会退出。而像内存这样的资源,则被称作“不可压缩资源(incompressible resources)。当不可压缩资源不足时,Pod 就会因为 OOM(Out-Of-Memory)被内核杀掉。
而由于 Pod 可以由多个 Container 组成,所以 CPU 和内存资源的限额,是要配置在每个 Container 的定义上的。这样,Pod 整体的资源配置,就由这些 Container 的配置值累加得到。
其中,Kubernetes 里为 CPU 设置的单位是“CPU 的个数”。比如,cpu=1 指的就是,这个 Pod 的 CPU 限额是 1 个 CPU。当然,具体“1 个 CPU”在宿主机上如何解释,是 1 个 CPU 核心,还是 1 个 vCPU,还是 1 个 CPU 的超线程(Hyperthread),完全取决于宿主机的 CPU 实现方式。Kubernetes 只负责保证 Pod 能够使用到“1 个 CPU”的计算能力。
此外,Kubernetes 允许你将 CPU 限额设置为分数,比如在我们的例子里,CPU limits 的值就是 500m。所谓 500m,指的就是 500 millicpu,也就是 0.5 个 CPU 的意思。这样,这个 Pod 就会被分配到 1 个 CPU 一半的计算能力。
当然,你也可以直接把这个配置写成 cpu=0.5。但在实际使用时,我还是推荐你使用 500m 的写法,毕竟这才是 Kubernetes 内部通用的 CPU 表示方式。
而对于内存资源来说,它的单位自然就是 bytes。Kubernetes 支持你使用 Ei、Pi、Ti、Gi、Mi、Ki(或者 E、P、T、G、M、K)的方式来作为 bytes 的值。比如,在我们的例子里,Memory requests 的值就是 64MiB (2 的 26 次方 bytes) 。这里要注意区分 MiB(mebibyte)和 MB(megabyte)的区别。备注:1Mi=10241024;1M=10001000此外,不难看到,Kubernetes 里 Pod 的 CPU 和内存资源,实际上还要分为 limits 和 requests 两种情况,如下所示:
备注:1Mi=1024*1024;1M=1000*1000 spec.containers[].resources.limits.cpu spec.containers[].resources.limits.memory spec.containers[].resources.requests.cpu spec.containers[].resources.requests.memory这两者的区别其实非常简单:在调度的时候,kube-scheduler 只会按照 requests 的值进行计算。而在真正设置 Cgroups 限制的时候,kubelet 则会按照 limits 的值来进行设置。更确切地说,当你指定了 requests.cpu=250m 之后,相当于将 Cgroups 的 cpu.shares 的值设置为 (250/1000)*1024。那么我们来验证一下这个cpu-shares具体的值测试运行一个pod,这里我给的资源cpu限制是250m
#kubectl describe po nginx-846bc8d9d4-lcrzk |grep -A 2 Requests: Requests: cpu: 250m memory: 64Mi现在已经交给了cgroups的cpu.shares的值进行配置,如何计算(250/1000)*1024=256这个256份额值我们可以通过下面的命令docker inspect 格式化直接获取到,我们现在在docker所看到的256这个值则是pod我们进行request设置的值
#docker ps |grep nginx |awk '{print $1}'|head -1 |xargs docker inspect --format '{{.Id}}:CpuShare={{.HostConfig.CpuShares}}' b164dc1c62f7eb16a28dc0a14a26e0ef764a7517487d97e9d87883034380302a:CpuShare=256而当你没有设置 requests.cpu 的时候,cpu.shares go模版的显示默认则是 2,但是我们要知道实际上使用这里默认为1024,每一个启动的容器份额为1024只是显示的是这样表示可以通过定位到pod的启动容器的具体目录查看
#cd /sys/fs/cgroup/cpu/docker #cat 709e4aeaea9331d09980d6f041e4fc0c8ff78c5d7477825852c076ffcc4fb3d5/cpu.shares 1024这样,Kubernetes 就通过 cpu.shares 完成了对 CPU 时间的按比例分配。这里所说的时间分配又说到了cpu分配的优先级,也就是cpu-shares其实是对cpu使用的一个优先分配的份额,我们知道cpu是可压缩资源,当分配的时候也决定cpu谁有更快分配CPU的能力,我们可以通过下面的测试来验证这个cpu-shares
计划我这里运行3个容器,为它们提供100、500和1000个cpu共享。
在后面,我们将使用实际的Linux基准测试工具使用自己的工作台容器进行这些测试。我们将特别关注在非常短的运行时运行这些占用CPU的系统,并且仍然可以得到准确的结果。
注意,dd、urandom和md5sum也不是工具,只是用来压测我们的cpu-shares的分配的时间,谁更有优先去分配到cpu的能力
我们的CPU压力应用程序:时间dd if=/dev/urandom bs=1M count=2 | md5sum
指标解释:
时间度量运行时间:显示这3个计时器行dd if=/dev/urandom bs=1M count=2…复制bs=块大小1 MB 进行100次md5sum……计算md5安全哈希值(给cpu一个负载)让我们运行它并调查结果:
docker container run -d --cpu-shares=1024 --name mycpu1024 alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=100 | md5sum' docker container run -d --cpu-shares=500 --name mycpu500 alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=100 | md5sum' docker container run -d --cpu-shares=100 --name mycpu100 alpine:3.8 /bin/sh -c 'time dd if=/dev/urandom bs=1M count=100 | md5sum'查看并获取我们的容器返回的数据日志
#docker logs mycpu1024 100+0 records in 100+0 records out real 0m 0.96s user 0m 0.00s sys 0m 0.60s #docker logs mycpu500 100+0 records in 100+0 records out real 0m 0.99s user 0m 0.00s sys 0m 0.60s b06118f07ce61d0e5a1201ad31659137 - #docker logs mycpu100 100+0 records in 100+0 records out real 0m 1.00s user 0m 0.00s sys 0m 0.60s 0046b35a22a48237cac7a75648e4e056 -注意,所有容器都使用了相同的sys cpu时间这是可以理解的,因为它们都做了完全相同的工作。--cpu-share =100显然需要更长的时间,但是--cpu-share =500只比--cpu-share =1024稍微慢一点,这里我测试显示的和1024几乎一样,这跟测试也存在略微差别问题是cpu-shares=1024运行非常快,然后退出。那么我们可以得到以下结论:那么--CPU -shares=500和--CPU -shares=100具有对CPU的完全访问权。
然后--CPU -shares=500个完成,因为它拥有最多的CPU共享。
然后--CPU -shares=1024快速完成,因为它拥有大多数CPU共享
经过这个测试我希望你明白一个道理,pod进行配置的request资源的限制,其实和docker的cgroup做了同样的操作,只不过docker将对应的pod的值进行计算得到另外一个值的形式显示出来,而计算的值则是(250/1000)*1024来计算的,request 的值不是指直接给容器实际分配的资源大小,它仅仅是给调度器看的,调度器会 "观察" 每个节点可以用于分配的资源有多少,也知道每个节点已经被分配了多少资源。被分配资源的大小就是节点上所有 Pod 中定义的容器 request 之和,它可以计算出节点剩余多少资源可以被分配(可分配资源减去已分配的 request 之和)。
分配的request的值如果没有限制则具有大多数cpu的共享,可以优先共享cpu资源。
另外我再说一下生产中的一个设置request的最佳实践
在你生产中你配置的资源限制,如果节点剩余可分配资源大小比当前要被调度的 Pod 的 reuqest 还小,那么就不会考虑调度到这个节点,反之,才可能调度。所以,如果不配置 request,那么调度器就不能知道节点大概被分配了多少资源出去,调度器得不到准确信息,也就无法做出合理的调度决策,很容易造成调度不合理,有些节点可能很闲,而有些节点可能很忙,甚至 NotReady。所以,建议是给所有容器都设置 request,让调度器感知节点有多少资源被分配了,以便做出合理的调度决策,让集群节点的资源能够被合理的分配使用,避免陷入资源分配不均导致一些意外发生。
下面limit这里我也多啰嗦几句,后面回到主题~~而如果你指定了 limits.cpu=500m 之后,则相当于将 Cgroups 的 cpu.cfs_quota_us 的值设置为 (500/1000)*100ms,而 cpu.cfs_period_us 的值始终是 100ms。这样,Kubernetes 就为你设置了这个容器只能用到 CPU 的 50%。
而对于内存来说,当你指定了 limits.memory=128Mi 之后,相当于将 Cgroups 的 memory.limit_in_bytes 设置为 128 1024 1024。我们可以通过docker 模版查看
#docker ps |grep nginx 45676528fbea nginx我们限制了128Mi则在docker的cgroup这么计算,12810241024得到cgroup的limit限制则是134217728字节
#docker ps --quiet --all |xargs docker inspect --format '{{.Id }}:Memory={{.HostConfig.Memory}}' 45676528fbea55a94b80553a8f1c57396c31aecc674b91eddb61024931ac11c9:Memory=134217728而需要注意的是,在调度的时候,调度器只会使用 requests.memory=64Mi 来进行判断。Kubernetes 这种对 CPU 和内存资源限额的设计,实际上参考了 Borg 论文中对“动态资源边界”的定义,既:容器化作业在提交时所设置的资源边界,并不一定是调度系统所必须严格遵守的,这是因为在实际场景中,大多数作业使用到的资源其实远小于它所请求的资源限额。
基于这种假设,Borg 在作业被提交后,会主动减小它的资源限额配置,以便容纳更多的作业、提升资源利用率。而当作业资源使用量增加到一定阈值时,Borg 会通过“快速恢复”过程,还原作业原始的资源限额,防止出现异常情况。而 Kubernetes 的 requests+limits 的做法,其实就是上述思路的一个简化版:用户在提交 Pod 时,可以声明一个相对较小的 requests 值供调度器使用,而 Kubernetes 真正设置给容器 Cgroups 的,则是相对较大的 limits 值。不难看到,这跟 Borg 的思路相通的。
下面回到正题~~~ 当首先考虑垂直自动扩展可能意味着什么时,我们会认为垂直pod自动扩展器将成为主机或VM垂直扩展的寓言,换句话说,就是增加该计算机上的资源量。如果VM正在使用4GB内存,并且正在使用3.8GB,则为该计算机提供额外的2GB可用空间。
当首先考虑垂直自动扩展可能意味着什么时,我们会认为垂直pod自动扩展器将成为主机或VM垂直扩展的寓言,换句话说,就是增加该计算机上的资源量。如果VM正在使用4GB内存,并且正在使用3.8GB,则为该计算机提供额外的2GB可用空间。
例如,在vSphere世界中,我们可以为虚拟机设置资源池,这可能是有道理的;但是在Kubernetes世界中,这没有任何意义。毕竟,Kubernetes只是位于主机顶部的调度程序。Kubelet确定并报告主机已安装的资源量,并使用这些值和运行的工作负载所需的报告资源,调度程序确定工作负载是否可以容纳在节点上。
那么垂直pod自动缩放在理论上可以采取什么形式?好吧,由于调度程序只有在报告了工作负载的请求和限制的情况下才可以有效地工作,因此设置真实的应用程序使用请求将使调度程序能够确保将可使用的资源池中的该资源量确保可以在特定节点上用于该应用程序。如果任何一个群集节点上没有足够大的洞可以容纳该应用程序,这可能会阻止工作负载进行调度,但是同样,这保证了我们可以在群集上运行现有的工作负载而不会压倒可用资源并使节点停机。
尽管VPA和HPA可能会针对相同的工作负载,但是由于VPA仅与CPU和内存资源配合使用,因此我们不应对水平扩展使用相同的指标。由于VPA和HPA控制器目前尚不相互了解,因此这两个控制器可能会尝试对工作负载应用不兼容的更改。VPA可以作为水平自动缩放的补充,但是我们必须对HPA使用分配非计算指标。有了这些,我们就可以深入了解VPA的工作原理。
Kubernetes VPA 组成部分:与HPA控制器不同,默认情况下,实现垂直容器自动缩放的组件默认情况下未安装在Kube中,因此我们将需要安装构成VPA架构的组件。有三个控制器可实现垂直吊舱自动缩放:
Recommender:用于根据监控指标结合内置机制给出资源建议值,自动扩展所需的初始任务是获取指标并确定工作负载的当前使用情况。根据资源的当前和过去指标,推荐器将为每个容器确定一组“推荐”的CPU和内存值。
默认情况下,这将是metrics-server。由于metrics-server旨在将度量标准存储在内存中,因此它仅提供最近10分钟的度量标准。为了向推荐者提供其正在监视的服务的运行历史的更广泛的历史记录,你还可以从Prometheus等时间序列数据库中插入历史记录指标。
Updater:用于实时更新 pod resource requests,当检测到应将哪些“正确”请求委托给推荐程序时,更新程序控制器会将每个部署的当前请求和建议请求与委托的垂直容器自动缩放器对象进行比较。如果部署的相应VPA对象的更新模式设置为“自动”或“重新创建”,则更新程序控制器将有助于创建包含新建议请求的新Pod。它不会使用新的推荐值直接更新Pod,而是指示Kube API应该从集群中退出特定Pod。它将依赖Kube主平面中的其他控制器来完成新容器的创建,并确保容器具有新的所需请求值。
History Storage:用于采集和存储监控数据
Admission Controller: 用于在 pod 创建时修改 resource requests,如果您已经弄清了什么是准入控制器及其用途,则VPA还包括一个变异的准入钩子。如果VPA对象的模式设置为“自动”,“重新创建”或“初始”,则该Webhook将在将Pod接纳到群集时注入由Recommender生成的当前请求值。
先看一下VPA这个对象
apiVersion: autoscaling.k8s.io/v1beta2 kind: VerticalPodAutoscaler metadata: annotations: name: test-vpa namespace: dev spec: resourcePolicy: containerPolicies: - containerName: '*' maxAllowed: memory: 1Gi minAllowed: memory: 500Mi targetRef: apiVersion: extensions/v1beta1 kind: Deployment name: test updatePolicy: updateMode: Recreate看到这里我们会发现有一些有趣的事情
通过使用分配器,resourcePolicy,我们可以分配推荐器允许的最小和最大值,从而为推荐器如何改变Pod的CPU和内存资源提供一些界限。如何限制这些资源的使用情况取决于单个Pod中有多少个容器正在运行。
如果pod只有一个容器,则containerName: ‘*‘可以使用设置通配符值。如果要将其应用于带有sidecar的pod,则当然需要基于每个容器对值进行边界划分。应用通配符值没有意义,因为这将对每个单个容器应用相同的内存值,而且我敢肯定,你的容器中的每个容器都不需要500-1000MB!如果推荐者控制器能够提取指标,则它将在大约五分钟的内部时间内生成指标,然后将推荐内容写入VPA对象的状态块。
另外VPA会生成四个不同的界限:这个值获取到这里并分为4个指标建议1、 Lower Bound: 也就是最低的下限,容器的最小CPU和内存请求。不建议将其用作请求的基准2、Target: 目标我理解为也就是平均值,也就是基线建议该容器的基线建议的CPU和内存请求3、Uncapped Target,建议的CPU和内存请求,但不考虑ContainerResourcePolicy中定义的限制4、Upper Bound 上限,建议的最大CPU和内存请求。
它的架构是这样的来自官方图片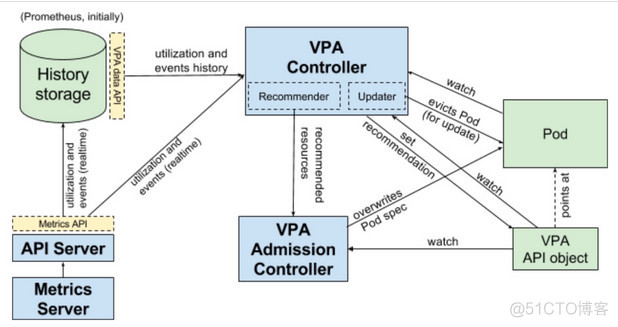 vpa的工作流程它是这样的:Recommender在启动时从History Storage获取历史数据,根据内置机制修改VPA API object资源建议值。Updater监听VPA API object,依据建议值动态修改 pod resource requests。VPA Admission Controller则是用于 pod 创建时修改 pod resource requests。History Storage则是通过Kubernetes Metrics API采集和存储监控数据
vpa的工作流程它是这样的:Recommender在启动时从History Storage获取历史数据,根据内置机制修改VPA API object资源建议值。Updater监听VPA API object,依据建议值动态修改 pod resource requests。VPA Admission Controller则是用于 pod 创建时修改 pod resource requests。History Storage则是通过Kubernetes Metrics API采集和存储监控数据
现在开始部署vpa,部署可参考我的githubhttps://github.com/zhaocheng173/vpa
1、现在开始部署vpa,前提保证metics server正常工作 , 部署metrics server 、vpa我已经都上传到github上,部署沟通遇到问题,可以联系我部署metrics server为了使推荐程序能够接收Pod指标,metrics-server也需要在集群上运行。由于metrics-server旨在将度量标准存储在内存中,因此它仅提供最近10分钟的度量标准。为了向VPA推荐器提供其正在监视的服务的运行历史的更广泛的历史记录,另外你还可以从Prometheus等时间序列数据库中插入历史记录指标。
#kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% ma 2245m 28% 2801Mi 36% mb 2453m 30% 2947Mi 18% mc 2356m 58% 2374Mi 30% md 308m 15% 709Mi 40%2、需要依赖openssl-1.1.1 最佳实践需要安装openssl-1.1.1 查看默认版本的openssl version是 1.0.2k-fips,如果直接安装的话是失败的,它会报一个错误,vpa-admission-controller这个pod会始终处于创建之中,会找不到证书,原因低版本的openssl没有生成证书的命令,有一个称为vpa-tls-certs,它安装在包含证书捆绑包的准入控制器中
所以我们需要升级openssl 第一步卸载yum安装的opensslrpm -e --nodeps openssl
安装组件依赖yum install libtool perl-core zlib-devel -y
下载1.1.1的openssl,默认我的环境为centos-7.6,centos的部署基本大致相同,下面放了一个下载openssl的地址,可供选择https://www.openssl.org/docs/man1.1.1/man1/req.html
#cd /usr/local/src #tar -zxf openssl-1.1.1g-latest.tar.gz #cd openssl-1.1.1g #./config #make #make test #make install #ln -s /usr/local/bin/openssl /usr/bin/openssl加载共享库libssl.so.1.1时如何解决openssl错误 如果安装成功查看版本如有以下报错 查看openssl version openssl: error while loading shared libraries: libssl.so.1.1: cannot open shared object file: No such file or directory调试 我们尝试找到名为libssl.so.1.1的文件,如下所示: 我们可以发现'libcrypto.so.1.1'位于/ usr / local / lib64中,但是openssl尝试在LD_LIBRARY_PATH中找到.so库。
[root@master ~]# ll /usr/local/lib64 总用量 10480 drwxr-xr-x 2 root root 39 8月 7 14:23 engines-1.1 -rw-r--r-- 1 root root 5630906 8月 7 14:23 libcrypto.a lrwxrwxrwx 1 root root 16 8月 7 14:23 libcrypto.so -> libcrypto.so.1.1 -rwxr-xr-x 1 root root 3380224 8月 7 14:23 libcrypto.so.1.1 -rw-r--r-- 1 root root 1024200 8月 7 14:23 libssl.a lrwxrwxrwx 1 root root 13 8月 7 14:23 libssl.so -> libssl.so.1.1 -rwxr-xr-x 1 root root 685528 8月 7 14:23 libssl.so.1.1 drwxr-xr-x 2 root root 61 8月 7 14:23 pkgconfig [root@master ~]# ll /usr/local/lib64/libssl* -rw-r--r-- 1 root root 1024200 8月 7 14:23 /usr/local/lib64/libssl.a lrwxrwxrwx 1 root root 13 8月 7 14:23 /usr/local/lib64/libssl.so -> libssl.so.1.1 -rwxr-xr-x 1 root root 685528 8月 7 14:23 /usr/local/lib64/libssl.so.1.1因此,解决方案是尝试告诉openssl库在那里。 解决方法 创建到文件的链接
[root@localhost openssl-1.1.g]# ln -s /usr/local/lib64/libssl.so.1.1 /usr/lib64/libssl.so.1.1 [root@localhost openssl-1.1.g]# ln -s /usr/local/lib64/libcrypto.so.1.1 /usr/lib64/libcrypto.so.1.1看到openssl的版本为以下,就可以部署了
#openssl version OpenSSL 1.1.1g 21 Apr 20203、开始部署
[root@master hack]# ./vpa-up.sh 此次省略 ........ Generating certs for the VPA Admission Controller in /tmp/vpa-certs. Generating RSA private key, 2048 bit long modulus (2 primes) ................................+++++ .+++++ e is 65537 (0x010001) Generating RSA private key, 2048 bit long modulus (2 primes) .............................................+++++ .............................+++++ e is 65537 (0x010001) Signature ok subject=CN = vpa-webhook.kube-system.svc Getting CA Private Key Uploading certs to the cluster. secret/vpa-tls-certs created Deleting /tmp/vpa-certs. deployment.apps/vpa-admission-controller created service/vpa-webhook created最后效果为成功部署
[root@master hack]# kubectl get po -A kube-system vpa-admission-controller-69c96bd8bd-4st7v 1/1 Running 0 39s kube-system vpa-recommender-765b6c5f59-rdxk4 1/1 Running 0 45s kube-system vpa-updater-86865896cf-z8bxn 1/1 Running 0 50s现在去检查Vertical Pod Autoscaler是否在您的集群中完全正常运行的一种简单方法是创建示例部署和相应的VPA配置:
--- apiVersion: "autoscaling.k8s.io/v1beta2" kind: VerticalPodAutoscaler metadata: name: hamster-vpa namespace: kube-system spec: targetRef: apiVersion: "apps/v1" kind: Deployment name: hamster resourcePolicy: containerPolicies: - containerName: '*' minAllowed: cpu: 100m memory: 50Mi maxAllowed: cpu: 1 memory: 500Mi controlledResources: ["cpu", "memory"] --- apiVersion: apps/v1 kind: Deployment metadata: name: hamster namespace: kube-system spec: selector: matchLabels: app: hamster replicas: 2 template: metadata: labels: app: hamster spec: securityContext: runAsNonRoot: true runAsUser: 65534 # nobody containers: - name: hamster image: nginx resources: requests: cpu: 100m memory: 50Mi command: ["/bin/sh"] args: - "-c" - "while true; do timeout 0.5s yes >/dev/null; sleep 0.5s; done" kubectl create -f examples/hamster.yaml Start deploying the Ceph cluster上面的命令创建了一个包含2个Pod的部署,每个Pod运行一个请求100m的容器,并尝试使用最高不超于500m的容器。该命令还会创建一个指向部署的VPA配置。VPA将观察Pod的行为,大约5分钟后,它们应使用更高的CPU请求进行更新(请注意,VPA不会在部署中修改模板,但Pod的实际请求会被更新)。
要查看VPA配置和当前推荐的资源请求,可以运行以下命令:
#kubectl get vpa -A NAMESPACE NAME AGE kube-system hamster-vpa 15m现在我们的在yaml中配置的默认值是以下配置
requests: cpu: 100m memory: 50Mi大概等待60s之后pod会重建,vpa会通知pod更新request这里可以看到再次pod的请求的request的值已经被更新为627m
#kubectl get pod -o=custom-columns=NAME:.metadata.name,PHASE:.status.phase,CPU-REQUEST:.spec.containers\[0\].resources.requests.cpu NAME PHASE CPU-REQUEST hamster-7df5c45bbc-jzpg2 Running 627m hamster-7df5c45bbc-knqfv Running 627m #kubectl describe vpa nginx-deployment-basic -n kube-system另外这个值获取到这里并分为4个指标建议上咱们说到过,这个值是实时推荐的,默认重启后推荐的值也是target的值
Recommendation: Container Recommendations: Container Name: hamster Lower Bound: Cpu: 578m Memory: 262144k Target: Cpu: 627m Memory: 262144k Uncapped Target: Cpu: 627m Memory: 262144k Upper Bound: Cpu: 1 Memory: 262144k那么这种情况下我们操作会导致我们的pod会重启,也会将pod调度到其他的节点,对于不设置任何调度规则的话,这样对于我们的业务肯定会受到影响,即使设置了调度规则,request会重启也会正常影响我们的业务所有使用VPA需要注意以下在环境中的事项
VPA不会驱逐没有在副本控制器管理下的Pod。目前对于这类Pod,Auto模式等同于Initial模式。目前VPA不能和监控CPU和内存度量的Horizontal Pod Autoscaler (HPA)同时运行,除非HPA只监控其他定制化的或者外部的资源度量。VPA使用admission webhook作为其准入控制器。如果集群中有其他的admission webhook,需要确保它们不会与VPA发生冲突。准入控制器的执行顺序定义在API Server的配置参数中。VPA会处理绝大多数OOM(Out Of Memory)的事件,但不保证所有的场景下都有效。VPA的性能还没有在大型集群中测试过。VPA对Pod资源requests的修改值可能超过实际的资源上限,例如节点资源上限、空闲资源或资源配额,从而造成Pod处于Pending状态无法被调度。同时使用集群自动伸缩(ClusterAutoscaler)可以一定程度上解决这个问题。多个VPA同时匹配同一个Pod会造成未定义的行为。
VPA在四种模式下运行:"Auto":将使用指定的更新机制在pod启动时和pod处于活动状态时分配请求值。目前,这等效于“重新创建”,因为当前没有用于更新实时Pod上的请求值的“就地”机制
"Recreate":将在容器启动时分配请求值,并且,如果当前推荐值与当前请求值相差很大,则将驱逐该容器并创建一个新的容器。
"Initial":VPA仅在pod创建时分配资源请求,以后再也不会更改它们。
"Off":VPA不会自动更改容器的资源要求。将计算建议,并可以在VPA对象中对其进行检查。
我们其实要做的就是不采用Auto的形式,只通过推荐参考的形式,将历史给出的target作为我们项目参考的request值
现在运行一个redis的示例,并获取vpa推荐的值
--- apiVersion: autoscaling.k8s.io/v1beta2 kind: VerticalPodAutoscaler metadata: name: redis-vpa spec: targetRef: apiVersion: "apps/v1" kind: Deployment name: redis-master updatePolicy: updateMode: "Off" --- apiVersion: apps/v1 kind: Deployment metadata: name: redis-master labels: app: redis spec: selector: matchLabels: app: redis replicas: 3 template: metadata: labels: app: redis spec: containers: - name: master image: redis # or just image: redis ports: - containerPort: 6379因为我们没有设置request所以没有资源的请求进行配置
#kubectl get pod -o=custom-columns=NAME:.metadata.name,PHASE:.status.phase,CPU-REQUEST:.spec.containers\[0\].resources.requests.cpu |grep -w redis redis-master-59fcd7f58f-5q88d Running <none> redis-master-59fcd7f58f-htmzj Running <none> redis-master-59fcd7f58f-x8bp6 Running <none>所以只会将值发送到vpa,可以describe vpa可以看到target的值
#kubectl describe vpa redis-vpa |awk '/Container Recommendations:/,/Events/{if(i>1)print x;x=$0;i++}' Container Name: master Lower Bound: Cpu: 25m Memory: 262144k Target: Cpu: 25m Memory: 262144k Uncapped Target: Cpu: 25m Memory: 262144k Upper Bound: Cpu: 329m Memory: 262144k最后我们就可以根据推荐值来实际配置Deployment中资源的requests。VPA会持续的监控应用资源的使用情况,并提供优化建议。通过将target的值可以根据换算进行使用到我们的生产环境当中