上周夜里,一个奢侈品电商网站的程序员手抖,把阿里云rds的某个库给删了,当时都11点多了,心中一万个羊驼在奔腾,还好,没让我出手,小弟就把它给恢复了。昨天上午,又一个网站的程序员手抖,给一个还要用的库给删了。这也不能全怪他,本来计划迁移数据的,因为数据库太大,进行分拆,把大库变小。迁移走了一些,就要删掉迁走的,这样以利于后边迁移加快速度。
也许有人说,这是管理上的问题,的确如此。应该加强权限管理,并制度相应的技术保障措施及流程规范。有相应的保障或者措施,虽然不能完全杜绝误操作,但起码会大大降低概率。我为啥经常遇到这种事情,来回折腾呢?主要是这些年,我做的是外围支援,以技术层面为主,不参与更多的事务。当然,对于大多数规模有限的公司来说,完善流程制度也难于落实。因此,虽然遇到不少麻烦,总结一下写出来,应该对其他人有所帮助。
恢复的第一要务,是找备份。还好,有一个2018年6月9日的备份存在。本来一直都在自动备份的,后来由于要迁移,而且据说近期夜间备份时,非常占用资源,负载老高,到上午上班时,备份压缩那一步还没有结束,就把备份给停了。
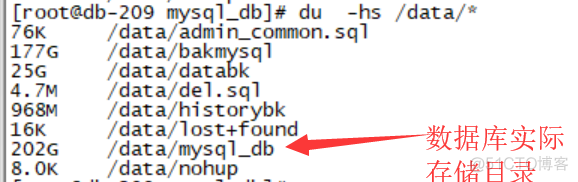
这是迁移部分数据后,还删掉迁走库以后的容量,确实有点大。像这种情况,要么分拆,要么做增量备份,把自动备份停了的做法,风险实在是大。
为了降低风险,在恢复前最好做一次全库备份,万一搞出问题,还能回得去。基于这个想法,开始执行备份。执行了两个小时,还没见动静,也无法评估大概要多长时间,其它人等不及了,同时备份也影响其它业务的正常运行,因此只好直接停止备份。
开干前先算一卦,测一下吉凶。得诟之坎卦,三爻、四爻、上爻动,好在用神旺相,有修复的希望。导入数据步骤如下:◆备份文件解包,并打开文件看一眼内容
[root@db-209 mysql_bk_dir]# pwd /data/databk/mysql_bk_dir [root@db-209 mysql_bk_dir]# tar zxvf mobile7_quanzhen20180609.tgz mobile7_quanzhen20180609.sql [root@db-209 mysql_bk_dir]# more mobile7_quanzhen20180609.sql -- MySQL dump 10.13 Distrib 5.5.29, for Linux (x86_64) -- -- Host: localhost Database: mobile7_quanzhen -- ------------------------------------------------------ -- Server version 5.5.29-log /*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */; /*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */; /*!40101 SET NAMES utf8 */; /*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */; /*!40103 SET TIME_ZONE='+00:00' */; /*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */; /*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */; /*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */; /*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */; -- -- Table structure for table `quanzhen_aboutegg` -- DROP TABLE IF EXISTS `quanzhen_aboutegg`; /*!40101 SET @saved_cs_client = @@character_set_client */; /*!40101 SET character_set_client = utf8 */; CREATE TABLE `quanzhen_aboutegg` ( `id` int(8) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID', `uid` mediumint(8) unsigned NOT NULL COMMENT '会员ID', `content` text NOT NULL COMMENT '内容', `title` varchar(100) NOT NULL COMMENT '标题', `sort` int(5) unsigned NOT NULL COMMENT '排序', `status` tinyint(1) unsigned NOT NULL COMMENT '0不显示,1显示', `updated` int(8) NOT NULL COMMENT '修改时间', `created` int(8) NOT NULL COMMENT '增加时间', PRIMARY KEY (`id`) ) ENGINE=MyISAM AUTO_INCREMENT=8 DEFAULT CHARSET=utf8 COMMENT='关于金蛋系统说明表'; /*!40101 SET character_set_client = @saved_cs_client */; ……………………………省略若干……………………………………….◆创建数据库并导入数据
mysql> create database mobile7_quanzhen; mysql> use mobile7_quanzhen; mysql> source /data/databk/mysql_bk_dir/mobile7_quanzhen20180609.sql;上述操作很顺利,基本没啥障碍。
重点部分来了,需要确定恢复到什么位置。这些信息从哪里得到呢?数据库存储目录里边的二进制日志。
[root@db-209 mysql_db]# pwd /data/mysql_db [root@db-209 mysql_db]# ls -al |grep mysql-bin -rw-rw---- 1 mysql mysql 1073744253 Jun 17 01:20 mysql-bin.000856 -rw-rw---- 1 mysql mysql 106606897 Jun 17 04:02 mysql-bin.000857 -rw-rw---- 1 mysql mysql 1073742155 Jun 18 02:22 mysql-bin.000858 -rw-rw---- 1 mysql mysql 58702046 Jun 18 04:02 mysql-bin.000859 -rw-rw---- 1 mysql mysql 1073745791 Jun 19 03:20 mysql-bin.000860 -rw-rw---- 1 mysql mysql 24180628 Jun 19 04:02 mysql-bin.000861 -rw-rw---- 1 mysql mysql 1073741973 Jun 20 00:31 mysql-bin.000862 -rw-rw---- 1 mysql mysql 172478749 Jun 20 04:02 mysql-bin.000863 -rw-rw---- 1 mysql mysql 1073741972 Jun 20 23:11 mysql-bin.000864 -rw-rw---- 1 mysql mysql 172554351 Jun 21 04:02 mysql-bin.000865 -rw-rw---- 1 mysql mysql 150489 Jun 21 04:02 mysql-bin.000866 -rw-rw---- 1 mysql mysql 747165143 Jun 21 16:11 mysql-bin.000867 -rw-rw---- 1 mysql mysql 228 Jun 21 04:02 mysql-bin.index从输出可知,二进制文件并不多,最旧的一个的时间戳是6月17号,10号到16号的丢失了。只保留最近5天的日志,这个是由mysql选项文件/etc/my.cnf设定的,其内容为:
[root@db-209 mysql_db]# more /etc/my.cnf ……………………………………….省略若干………………………… [mysqld] port = 3306 socket = /tmp/mysql.sock datadir = /data/mysql_db #log_bin_trust_function_creators = 1 skip-external-locking skip-name-resolve wait_timeout=10 interactive_timeout=300 connect_timeout=300 max_connections = 2000 max_connect_errors = 50 tmp_table_size = 128M …………重要………… expire_logs_days = 5 …………重要………… slave-skip-errors = 1690,1062 # Try number of CPU's*2 for thread_concurrency thread_concurrency = 8 slow_query_log = 1 slow_query_log_file=/data/mysql_db/slow.log ………………………………省略若干……………………………………………….虽然是五天的数据,但文件却是好几个。为啥不设置保留天数多一些呢?还不是因为这个机器太老,资源有限。把风险告知其他让你,申明可能有几天的的数据会丢失。大家一致认同,能恢复多少算多少,总比没有强。
询问了执行误操作的程序员,大概是哪个时间执行的drop操作?回答说是6月20号上午10点过几分。有了这个参照点,再查看二进制日志文件的时间戳,就可定位到文件“mysql-bin.000864”,确定这个文件的原因是文件“mysql-bin.000863”的最后写入时间是“6月20日4:02”,这样一来范围就缩小很多。当然,也可以不管这些,用通配符,搜索所有二进制日志文件,确定恢复点。我决定以时间点来进行恢复,具体的操作如下:◆确定恢复的时间点
[root@db-209 mysql_db]# pwd /data/mysql_db [root@db-209 mysql_db]# /usr/local/mysql/bin/mysqlbinlog -v --base64-output=DECODE-ROWS mysql-bin.000864|grep -C 10 -i drop INSERT INTO `quanzhen_everydaycpdcontrol` (todaytime,uid,todaynum) VALUES (1529424000,661526,3) /*!*/; # at 393124773 #180620 10:08:44 server id 21 end_log_pos 393124800 Xid = 629128212 COMMIT/*!*/; # at 393124800 …………重要………… #180620 10:08:44 server id 21 end_log_pos 393124901 Query thread_id=85127174 exec_time=0 error_code=0 SET TIMESTAMP=1529460524/*!*/; /*!\C latin1 *//*!*/; SET @@session.character_set_client=8,@@session.collation_connection=8,@@session.collation_server=33/*!*/; drop database mobile7_quanzhen /*!*/; …………重要………… # at 393124901 #180620 10:08:44 server id 21 end_log_pos 393124989 Query thread_id=85160078 exec_time=0 error_code=0 SET TIMESTAMP=1529460524/*!*/; /*!\C utf8 *//*!*/; SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=33/*!*/; BEGIN /*!*/; # at 393124989 #180620 10:08:44 server id 21 end_log_pos 393125017 Intvar -- INSERT INTO `quanzhen_everydaycpdcontrol` (todaytime,uid,todaynum) VALUES (1529424000,399677,4) /*!*/; # at 399014378 #180620 10:13:27 server id 21 end_log_pos 399014405 Xid = 629434799 COMMIT/*!*/; ………………………………………………………..省略若干…………………………………………现在得到确切删库的时间是2018年6月20日上午10:08:44,恢复时间就以此为准,稍微往前移一点也是合理的。这里有一个小插曲,最开始不加选项,简化执行“mysqlbinlog mysql-bin.000864”只有寥寥几行输出,输出结尾还有一行报错信息,如下所示:
ERROR: Error in Log_event::read_log_event(): 'Found invalid event in binary log', data_len: 96, event_type: 19 Could not read entry at offset 820:Error in log format or read error DELIMITER ;又试着打开其它几个二进制日志,结果差不多。加选项执行“mysqlbinlog -v --base64-output=DECODE-ROWS mysql-bin.000864|grep -C 10 -i drop”,提示不支持。

这样看来,恢复的机会不太大了,吓得赶紧喝泡菜水压压惊。用某度搜一下,知道是版本不一致造成的,find 一下,果然有两个mysql安装。这mysql是我几年前亲自部署的,一般都是定制安装在/usr/local/mysql目录,数据文件分开。但不知道后边那个程序员,yum惯了,又给安装了一个低版本的。后边我执行带全路径,就没问题,不过我暂时不想告诉他们,以免大家商和气。 ◆数据恢复还是使用mysqlbinlog指令,加管道“|”把输出给mysql,具体的操作如下所示:
[root@db-209 ~]#/usr/local/mysql/bin/mysqlbinlog --database=mobile7_quanzhen --stop-datetime='2018-06-20 10:08:40' mysql-bin.000* |mysql mobile7_quanzhen -p开始操作的时候,mysqlbinlog 没带选项“--database=mobile7_quanzhen”,执行后,抛主键冲突错误信息。后在管道右侧mysql这一边强制强制加选项“-f”,虽然能继续往下进行,但还是不断报主键冲突的错误信息。

后来想,是不是在管道又边把数据库名字也指定上?反正这样搞也没风险。嘿嘿,加上以后,输入mysql密码,还真正常导入了。我猜想,不指定数据库选项,mysqlbinlog会尝试对所有的库进行恢复,而其它库却并没有丢失数据,因此造成主键冲突。
有一个有意思的问题,本来在恢复前导入了旧库,其所关联的目录和文件都已经生成,但在执行mysqlbinlog恢复时,该库所对应的目录里的文件和子目录会消失一阵,过一会又会自己回来。恢复继续进行,可看到数据目录里的文件时间戳在发生变化,而不需要恢复的数据,其时间戳是固定的。
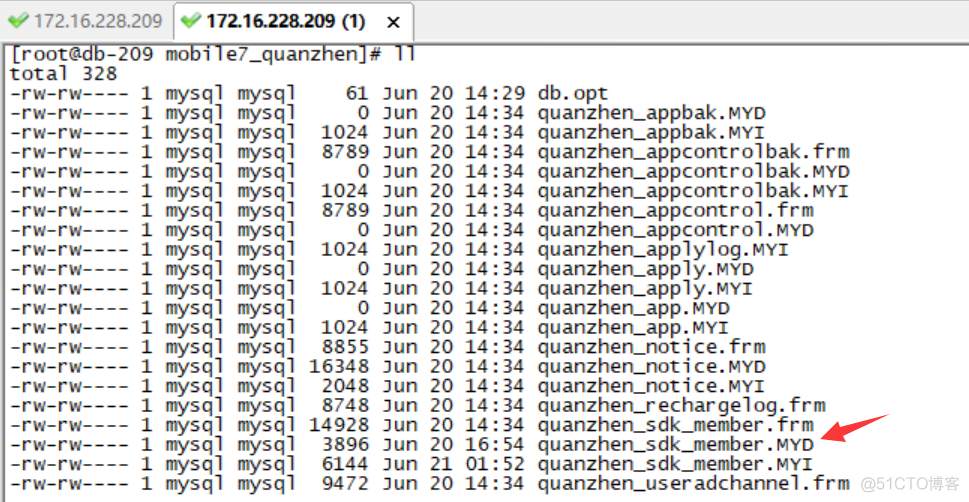
恢复过的数据,跟最初旧库导入数据的时间有明显的差异。恢复完以后,请程序员帮忙核对一下,看表的数量,表的记录数是否与删除前一样活着差不多。经确认,恢复成功,大家不用跑路。
老田有话说最近受邀在51CTO博客专栏出版《负载均衡高手炼成记》,依托自己十余年的IT运维经验,以实际工作经验为基础,介绍不同场景下,负载均衡的实现方式,以及负载均衡的日常维护。本专栏适合于一直徘徊在运维初级未找到入佳境之门的运维工程师,也适合对负载均衡有兴趣了解和学习的技术爱好者。跟着老田学完这个系列课程,不仅学知识,更是涨薪、升职、进心仪公司的一大捷径!负载均衡高手炼成记