前言:
笔者看来, 监控不应该只是监控,除了及时有效的报警,更应该”好看”,因为视觉上的感受更能给我们直观的感受,更能从绚丽的走势中发现异常, 如果你觉得监控就应该像老牌监控nagios,cacti一样,我想也没什么不对的,因为也许那是你们最适合的,但,你还是可以瞧瞧这个监控能给你带来什么。
文章目录:
效果图
Prometheus架构
安装
配置
可视化
可视化自定义
报警
其他exporter
自定义exporter
效果图
为了你能有更多的动力看下去,这里放一部分通过Prometheus + grafana打造出来的监控平台,效果图如下。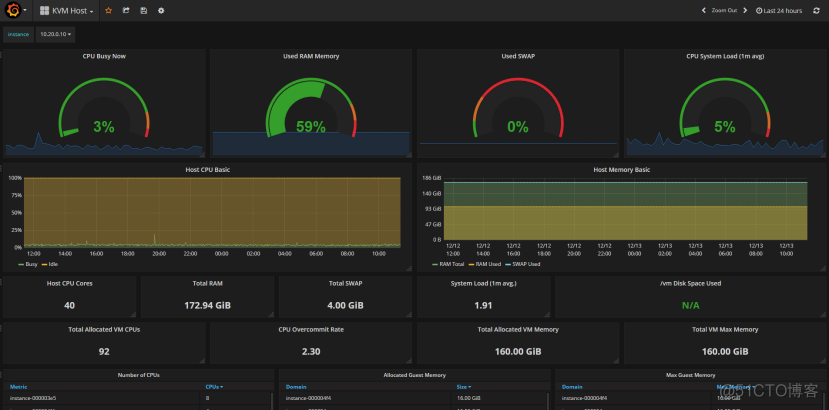
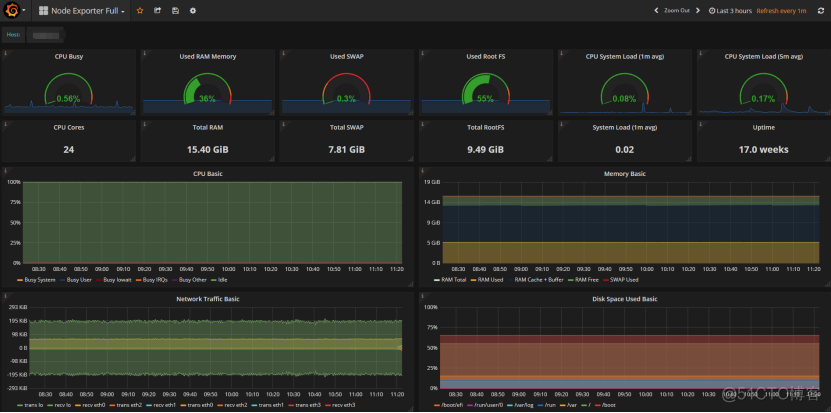
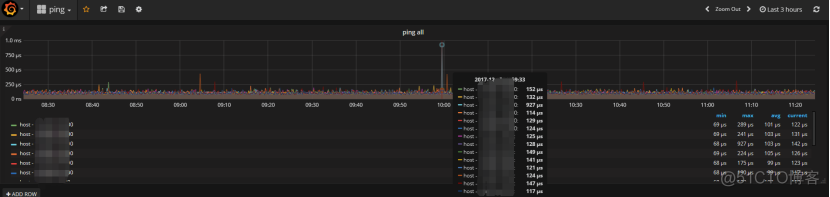

如果你觉得不错可以继续看下去,上面主要是kvm宿主机, ceph集群, 物理机监控,以及ping, 最后一张的监控图没有展开是为了让你可以瞥一眼所能监控的指标条目。
Prometheus架构图
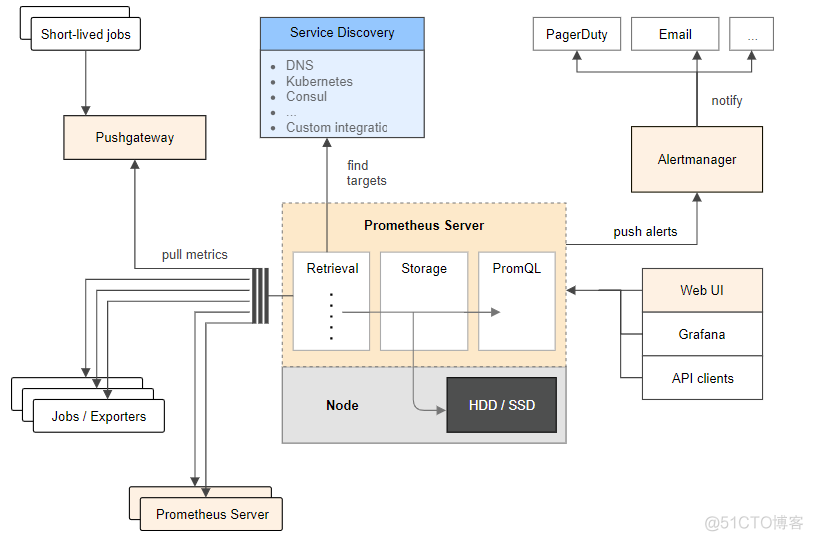
参考:https://prometheus.io/docs/introduction/overview/
如果你对Prometheus没有接触过,也许会看不懂上面说什么,但是没关系,如果你看完之后,在回过头来瞧瞧,也许就了解这个架构了,也会对Prometheus有一个更深的认识。这里简单说一下Prometheus的各个部分。Prometheus Server: Prometheus服务端,由于存储及收集数据,提供相关api对外查询用。Exporter: 类似传统意义上的被监控端的agent,有区别的是,它不会主动推送监控数据到server端,而是等待server端定时来手机数据,即所谓的主动监控。Pushagateway: 用于网络不可直达而居于exporter与server端的中转站。Alertmanager: 报警组件,将报警的功能单独剥离出来放在alertmanager。Web UI: Prometheus的web接口,可用于简单可视化,及语句执行或者服务状态监控。
安装
由于Prometheus是go语言写的,所以不需要编译,安装的过程非常简单,仅需要解压然后运行。Prometheus官方下载地址:https://prometheus.io/download/
注:为了演示方便,这里node_exporter, Prometheus server, grafana都安装再同一台机器,系统环境Ubuntu14.04
安装Prometheus server
解压
tar xf prometheus-2.0.0-rc.2.linux-amd64.tar.gz运行
cd prometheus-2.0.0-rc.2.linux-amd64 ./prometheus --config.file=prometheus.yml
然后我们可以访问 http://<服务器IP地址>:9090,验证Prometheus是否已安装成功,web显示应该如下
通过点击下拉栏选取指标,点击”Excute” 我们能够看到Prometheus的性能指标。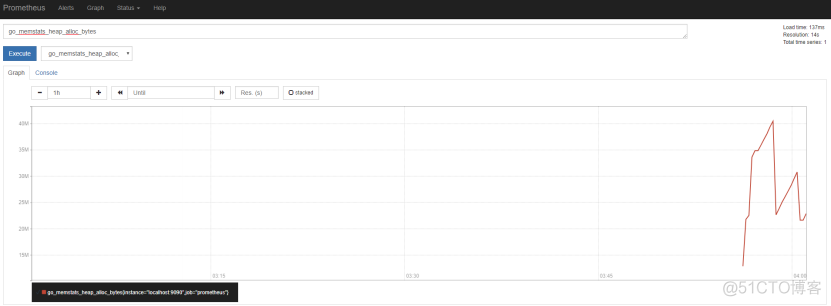
点击”status”可以查看相关状态。
但是光安装Prometheus server意义不大,下面我们再安装node_exporter以及grafana
node_exporter安装
解压
tar xf node_exporter-0.15.0.linux-amd64.tar.gz运行
cd node_exporter-0.15.0.linux-amd64 ./node_exporter
验证node_exporter是否安装成功
curl 127.0.0.1:9100
返回一大堆性能指标。
grafana安装
下载deb安装
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana_4.5.2_amd64.deb dpkg -i grafana_4.5.2_amd64.deb安装依赖
sudo apt-get install -y adduser libfontconfig启动grafana
sudo service grafana-server start加入自启动
sudo update-rc.d grafana-server defaults注:其他系统安装参考:http://docs.grafana.org/installation/
启动grafana并查看状态
systemctl daemon-reload systemctl start grafana-serversystemctl status grafana-server
访问grafana, http://<服务器IP>:3000默认用户名密码:admin/admin
为grafana添加Prometheus数据源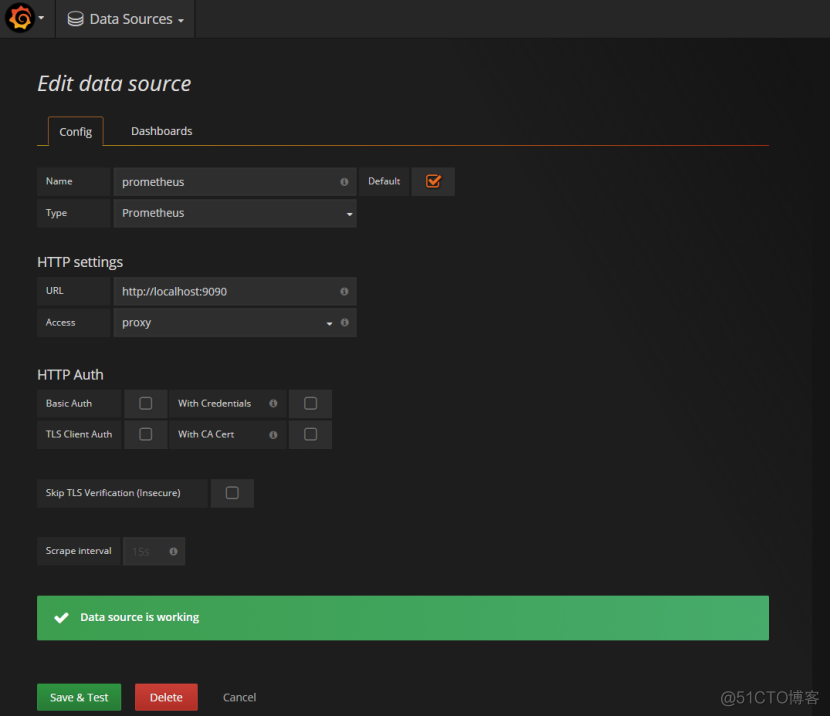
至此所有安装已完成但是还存在以下问题一:Prometheus server并没有配置被监控端的IP地址,即没有取指定的机器取数据二:启动的方式太不人性化了,没有启动脚本。三:grafana没有可用的dashboard用于展示这些问题我们放在下面的配置,可视化段落处理。
配置
关闭之前之间运行的node_exporter及prometheus
增加一个被监控端配置项
创建目录/etc/prometheus/
mkdir /etc/prometheus/创建配置文件
vi /etc/prometheus/prometheus.yml修改如下(在有配置文件基础上增加红色区域)
# my global configglobal: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Attach these labels to any time series or alerts when communicating with # external systems (federation, remote storage, Alertmanager). external_labels: monitor: 'codelab-monitor'# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.rule_files: # - "first.rules" # - "second.rules"# A scrape configuration containing exactly one endpoint to scrape:# Here it's Prometheus itself.scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090']注意:缩进是必须的
添加启动脚本下载地址:https://github.com/youerning/blog/tree/master/prometheus
cp node-exporter.service /etc/init.d/node-exporter cp prometheus.service /etc/init.d/prometheuschmod +x /etc/init.d/node-exporterchmod +x /etc/init.d/prometheus将上面的可执行二进制文件移到/usr/local/bin
cp prometheus-2.0.0-rc.2.linux-amd64/prometheus /usr/local/bin/prometheus mv node_exporter-0.15.0.linux-amd64/node_exporter /usr/local/bin/node_exporter然后启动Prometheus,node-exporter创建工作目录(Prometheus的数据会存在这,启动脚本里面我写的是/data)
mkdir /data service prometheus startservice node-exporter start在Prometheus的web页面能看到被监控端

然后grafana导入dashboard下载地址:https://grafana.com/dashboards/1860
注:https://grafana.com/dashboards还有很多的dashboard可以下载
按照以下步骤导入

点击import以后grafana就会多一个dashboard
至此一个系统层面性能指标监控已经全部完成。
可视化自定义由于grafana的界面配置都是页面点击,需要截图标注,如果截太多图就文章太冗长了,这里就不进一步说明了,相关配置参考http://docs.grafana.org/features/panels/通过上面的安装配置发现,其实整个监控的流程还缺少了报警的环节,如果不能及时通报异常情况再好看也白搭。
报警
解压
tar xf alertmanager-0.11.0.linux-amd64.tar.gz规则配置
cat /etc/prometheus/alert.rulesgroups:
name: uptimerules:
Alert for any instance that is unreachable for >1 minutes.- alert: InstanceDownexpr: up == 0for: 1mlabels:severity: pageannotations:summary: "Instance {{ $labels.instance }} down"description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
prometheus.yml增加以下内容
详细配置参考: https://github.com/youerning/blog/blob/master/prometheus/prometheus-alertmanager.yml
启动alertmanager
./alertmanager --config.file=/etc/prometheus/alertmanager.yml查看监控状态


不过Prometheus的报警操作真的很扯淡。支持的接受操作如下
<email_config>
<hipchat_config>
<pagerduty_config>
<pushover_config>
<slack_config>
<opsgenie_config>
<victorops_config>
<webhook_config>
而email报警有个扯淡的地方就是如果邮件服务器必须tls认证且ssl是自签名的话就会starttls failed: x509: certificate signed by unknown authority而且没有一个in_secure:true的选项。
所以需要邮件报警的话有两种方法,一:再报警服务器里面植入自己的证书,参考:http://blog.amigapallo.org/2016/04/14/alertmanager-docker-container-self-signed-smtp-server-certificate/二:允许smtp不使用tls
其实上面两种方法都不太优雅,观法推荐的是使用web_hook但是又得保证web_hook的服务是运行的,这就很扯淡了,不过,如果是全部跑在docker管理平台,如k8s,倒是不错的。
下面是一个简单的实现。
from __future__ import print_function import falcon from wsgiref import simple_server from email.mime.text import MIMEText import smtplib import json smtpServer = "mx.example.com" smtpUser = "sender@example.com" smtpPass = "password" sender = "sender@example.com" reciver = "reciver@example.com" tpl = """ status: {status} alerts: {alerts} """ def sendMail(reciver, subject, message): server = smtplib.SMTP(smtpServer, 587) server.ehlo() server.starttls() server.ehlo() server.login(smtpUser, smtpPass) server.set_debuglevel(1) msg = MIMEText(message, "plain", "utf8") msg["Subject"] = subject server.sendmail(sender, [reciver], msg.as_string()) server.quit() class WebHook(object): def on_post(self, req, resp): """Handles GET requests""" body = req.stream.read() postData = json.loads(body.decode('utf-8')) msg = tpl.format(**postData) print(msg) sendMail(reciver, "alert", msg) resp.status = falcon.HTTP_200 # This is the default status resp.body = "OK" app = falcon.API() app.add_route('/', WebHook()) if __name__ == '__main__': httpd = simple_server.make_server('0.0.0.0', 80, app) httpd.serve_forever()源码:https://github.com/youerning/blog/blob/master/prometheus/webhookmail.py
注意:有falcon的依赖,需要pip install falcon
效果如下

注:由于我没有进一步处理post过来的json数据,所以显得不是很直观,大家可以根据自己的需要编排数据
其他exporter除了基本的node_exporter,Prometheus官方还提供其他的exporter,如mysql, memcache,haproxy等除了官方提供的,也还有很多第三方的expoter,参考:https://prometheus.io/docs/instrumenting/exporters/
自定义exporter本文太长了, 直接看官方example吧。参考:https://github.com/prometheus/client_golang/blob/master/examples/random/main.go
后记:个人认为,其实你不一定知道你要监控什么的,但是足够多的监控数据,能够支撑你对异常的全面审查及追溯。其实Prometheus的很多细节没有说,比如监控规则编写,Prometheus的查询语法,不过本文太长了,如果有机会在详细说明吧。