引言:UNIX/LINUX下大多数都是用gzip格式来做文件的压缩方案的,而gzip文件损坏的情况也屡见不鲜,常见的有遇到坏扇区、压缩进程io阻塞,或恢复后的压缩文件被破坏等。因近期有做关于gzip文件的修复研究,特分为三个篇章对此成果进行表述,分别为原理篇,方法篇,案例篇。此为第一部分原理篇。
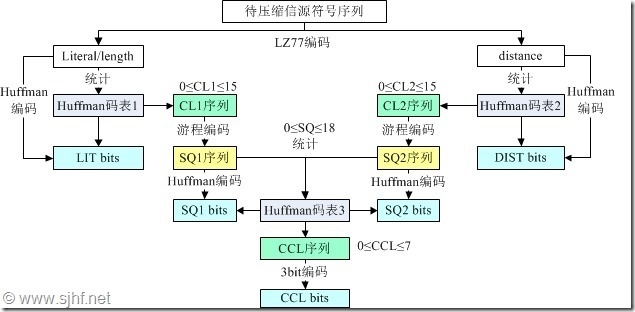
gzip的压缩算法本质上是deflate(zip也几乎都用),这个算法其实是由LZ77算法加上一个变形的哈夫曼编码组成的。大概算法流程是:”原始数据--->LZ77--->哈夫曼 “这三个步骤。因啥夫曼树仍有可能进行压缩,所以,实质上的算法流程是:”原始数据--->LZ77--->(哈夫曼树->CL压缩) “
先来聊聊“原始数据--->LZ77”这一层的思想。LZ77的详细算法见相关文档,本文不做赘述,仅描述涉及本文主题的一些思想。本质上看,LZ77是基于对连续重复的字节片断用指向的方式表示来实现压缩。比如:有句英文叫business is business,为了简化这个句子(注意有空格),我们用business is (12,8)来表示,意思是括号内的数字并非原始数据,而是代表从当前位置向前12个字节,并且连续了8个字节的那段文字。这样一来,文字部分就变得简短了。当然,我们一定会注意到,对于每个句子,要额外有信息表示到底是原始数据,还是指针类的数据。所以,整个压缩后的数据,由三类不同的信息元素组成:本来就是这样的文字、指向的位置,指向的长度,这三个元素即是lz77算法中的literal、distance和length。
给定任何一段字节流,如果使用LZ77算法进行了压缩,就一定会得到一段由literal、distance和length组成的字节流,那要如何区分这三类元素呢?distance和length总是成对出现的,所以,其实是如何区分这2类:1、literal 2、distance与length。通过适当方法区分开这2类成员,就完成了LZ77算法的整个方法。
LZ77完成后,会形成一段较短的字节流。但这还不够,还要经过哈夫曼编码进行二次压缩才能使压缩比更为理想。
同样的原因,对哈夫曼编码原理不做过多解释,仅对涉及本文主题的一些原理进行概要性表述。关于哈夫曼编码,举个例子说明一下:如果有一段字节流(由字节为最小单位组成),这些字节流中每种字节值的出现概率是不相同的,但每个字节都使用了8位进行记录,从概率角度可以知道,这一定是可以再做优化的。哈夫曼就是针对这个思想的优化,简单地说,就如同生成了一个一一对应的映射字典,用一些短的位代替经常频繁出现的字节,用一些长的位代替不常出现的字节,这样,总体上就又进行了一次压缩。(本文转载时请保留完整版权信息: 北亚数据恢复中心 张宇 )
当然,如何区分某个位置开始的是短的位还是些长的位呢?其实很简单,只要约定:短位用了的,比他长的就不再用这个短位做前缀即可。比如,如果英文中不想用空格间隔开单词了,只需要这样设计:I如果表示我的意思,那其他所有单词就不可能以I开头。AM如果表示”是”的含义,那既没有以A开头的单词,也没有以AM开头的更长的单词了。以此类推,或许Iamchinese就不用加空格也能间隔开了。
因为LZ77压缩后的数据元素中有literal、distance和length,为了有效区分,deflate算法把把literal和length合起来,使用一颗哈夫曼树。树中编码表述的数值如果小于255,即表示literal;如果等于256,表示本压缩块结束;如果大于256,表示length(需要减254得到);如果是length,再在其后紧跟distance的编码,distance使用单一的哈夫曼树,实现方法见相关文档。
literal、distance和length采用的哈夫曼树本身也是个大的负担,为了进一步压缩空间,deflate又对这两颗哈夫曼树进行了一次压缩,同样的,主体上,也是采用哈夫曼算法,这样,就是第三颗哈夫曼树了。
简单的结构如下图:
按照图中结构可知,一个gzip结构大致如下图所示:
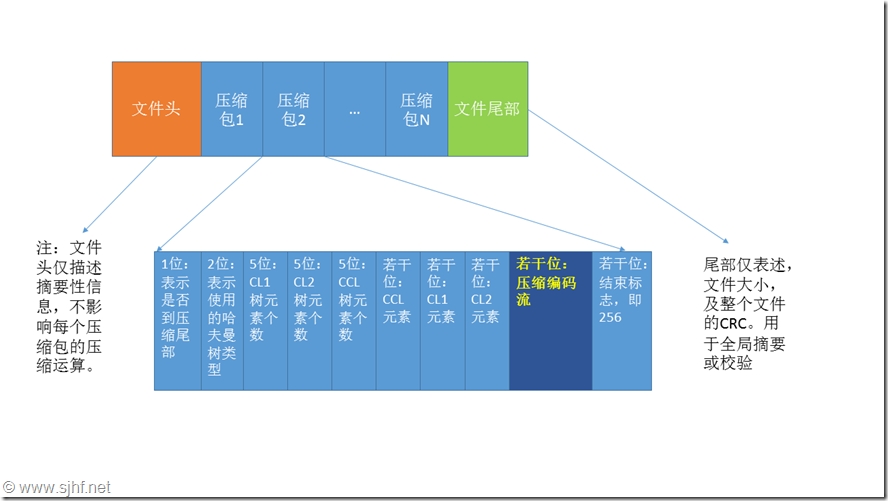
可以看到,每个的压缩包均是独立存在的,包括其本身使用的动态哈夫曼树,也仅存在于其作用域的压缩包内。故而,只要找到每个压缩包的起始位置,如果这个包没被破坏,就可解出其对应内容。
通常而言,因gzip的压缩作业窗口仅32K,所以每个包的大小都不会很大,如果部分包损坏,只要找到下一个包的起始,即可正确解压后续的数据。
如果gzip压缩的是多个文件(并非tar之后再做gzip),此种情况则相对容易。对于gzip而言,文件内包含多个原始文件的,不可以多个文件共用一个压缩包,也就是说如果有一个文件损坏,并不影响其他文件。这种思路容易实现,也可以使用linux下的gzip recover来完成修复。
我们重点要讨论的如果单一文件(如TAR包)gzip后,若其中间损坏,如何正确解压出后面的数据。这个思路如果理解了,gzip recover的算法就非常容易理解了,其算法也似乎有些弱了。
详见下一篇章。