 本文从众所周知的 setnx 命令开始实现一个简单的 Redis 锁,在实际应用中逐步揭示其面临的问题并给出解决方案,循序渐进地讲解分布式锁需要解决的诸多问题(被动释放、属主、锁等待、保活等),让人知其然且知其所以然。另外本文指出分布式锁并不是银弹,有些问题虽然能用分布式锁解决,但其实有其他更好的方案。
场景
本文从众所周知的 setnx 命令开始实现一个简单的 Redis 锁,在实际应用中逐步揭示其面临的问题并给出解决方案,循序渐进地讲解分布式锁需要解决的诸多问题(被动释放、属主、锁等待、保活等),让人知其然且知其所以然。另外本文指出分布式锁并不是银弹,有些问题虽然能用分布式锁解决,但其实有其他更好的方案。
场景
假设我们有个批处理服务,实现逻辑大致是这样的:
- 用户在管理后台向批处理服务投递任务;
- 批处理服务将该任务写入数据库,立即返回;
- 批处理服务有启动单独线程定时从数据库获取一批未处理(或处理失败)的任务,投递到消息队列中;
- 批处理服务启动多个消费线程监听队列,从队列中拿到任务并处理;
- 消费线程处理完成(成功或者失败)后修改数据库中相应任务的状态;
流程如图:
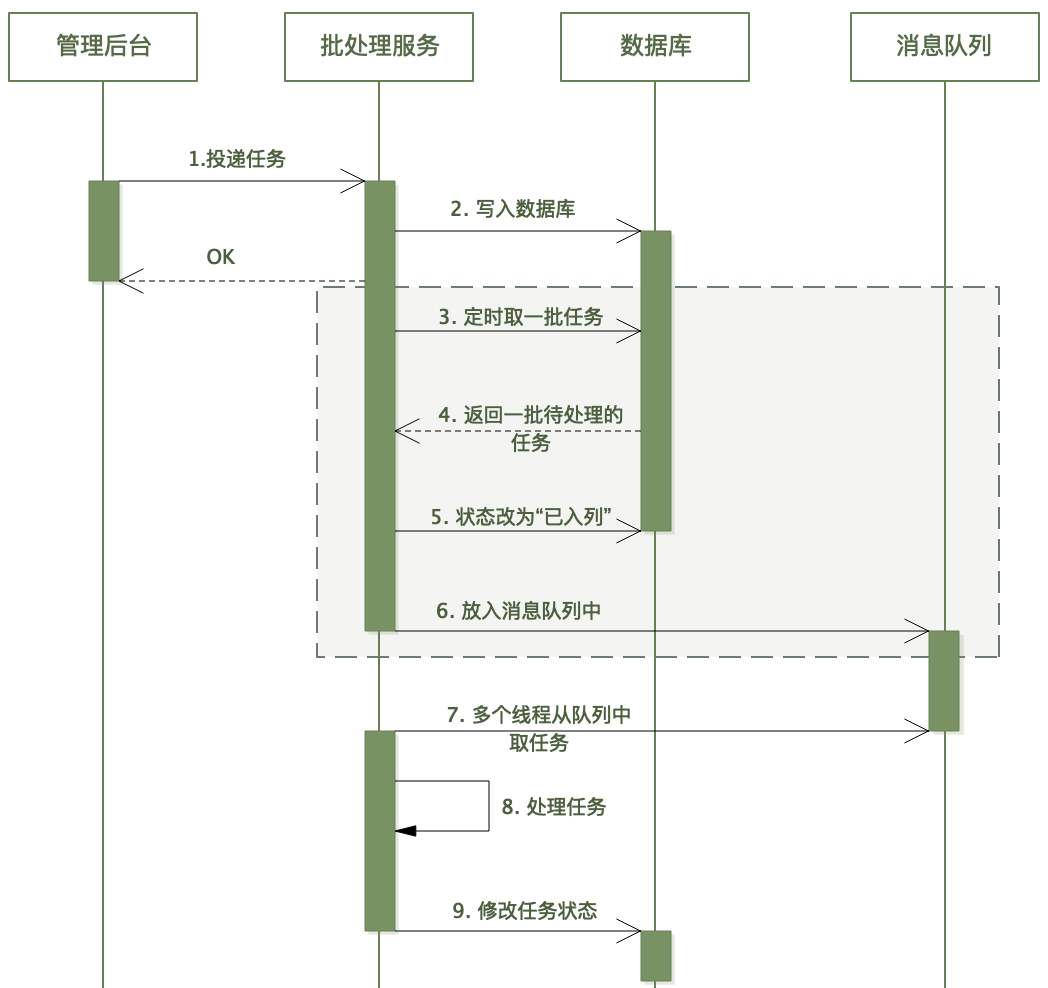
现在我们单独看看上图中虚线框中的内容(3~6):批处理服务从数据库拉取任务列表投递到消息队列。
生产环境中,为了高可用,都会部署至少两台批处理服务器,也就是说至少有两个进程在执行虚线框中的流程。
有什么问题呢?
假设这两个进程同时去查任务表(这是很有可能的),它俩很可能会得到同一批任务列表,于是这批任务都会入列两次。
当然,这不是说一个任务入列两次就一定会导致任务被重复执行——我们可以通过多引入一个状态值来解决此问题。
消费者线程从队列中获取到任务后,再次用如下 SQL 更新任务状态:
-- status:1-待处理;2-已入列;3-处理中;4-失败待重试;5-彻底失败(不可重试);
update tasks set status=3 where status=2 and id=$id;
由于 where 条件有 status=2,即只有原先状态是“已入列”的才能变成“处理中”,如果多个线程同时拿到同一个任务,一定只有一个线程能执行成功上面的语句,进而继续后续流程(其实这就是通过数据库实现的简单的分布式锁——乐观锁)。
不过,当定时进程多了后,大量的重复数据仍然会带来性能等其他问题,所以有必要解决重复入列的问题。
有个细节:请注意上图中步骤 5、6,是先改数据库状态为“已入列”,再将消息投递到消息队列中——这和常规逻辑是反过来的。
能否颠倒 5 和 6 的顺序,先入列,再改数据库状态呢?
不能。从逻辑上来说确实应该如此,但它会带来问题。消费线程从队列中拿到任务后,会执行如下 SQL 语句:
update tasks set status=3 where status=2 and id=$id;
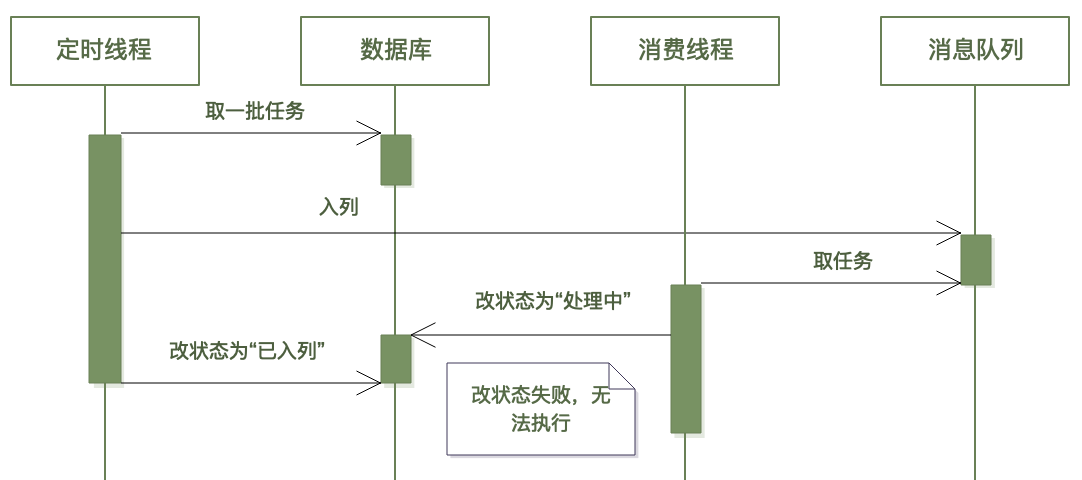
这条 SQL 依赖于前面(第 5 步)产生的状态值,所以它要求在执行该语句的时候,第 5 步的 SQL 语句(将状态改为“已入列”)一定已经执行完了。如果将 5 和 6 颠倒(先入列,再改状态值),就有可能出现下图的执行顺序,导致消费者线程修改状态失败,进而执行不下去:
上图中,任务入列后立即被消费线程获取到并去修改数据库,而此时定时线程的 SQL 可能还没执行(可能网络延迟),这就出问题了。
定时线程先将状态改为“已入列”带来的问题是,如果改状态后(入列前)进程挂了,会导致任务一直处于已入列状态(但实际上未入列),所以还需要搭配其它的超时重试机制。
上图虚线框中那段逻辑在并发原语中有个专门名称叫“临界区”——我们要做的就是让多个操作者(进程、线程、协程)必须一个一个地(而不能一窝蜂地)去执行临界区内部的逻辑,手段就是加锁:
var lock = newLock()
// 加锁
lock.lock()
// 执行临界区的逻辑
// 释放锁
lock.unlock()
所谓锁,就是多个参与者(进程、线程)争抢同一个共享资源(术语叫“信号量”),谁抢到了就有资格往下走,没抢到的只能乖乖地等(或者放弃)。锁的本质是两点:
- 它是一种共享资源,对于多方参与者来说,只有一个,就好比篮球场上只有一个篮球,所有人都抢这一个球;
- 对该资源的操作(加锁、解锁)是原子性的。虽然大家一窝蜂都去抢一个球,但最终这个球只会属于某一个人,不可能一半在张三手上,另一半在李四手上。只有抢到球的一方才可以执行后续流程(投篮),另一方只能继续抢;
在单个进程中,以上两点很容易实现:同一个进程中的线程之间天然是共享进程内存空间的;原子性也直接由 CPU 指令保证。所以单个进程中,我们直接用编程语言提供的锁即可。
进程之间呢?
进程之间的内存空间是独立的。两个进程(可能在两台不同的物理机上)创建的锁资源自然也是独立的——这就好比两个篮球场上的两个篮球之间毫不相干。
那怎样让两个篮球场上的两队人比赛呢?只能让他们去同一个地方抢同一个球——这在编程中叫“分布式锁”。
有很多实现分布式锁的方案(关系数据库、zookeeper、etcd、Redis 等),本篇单讲用 Redis 来实现分布式锁。
小试牛刀
之所以能用 Redis 实现分布式锁,依赖于其三个特性:
- Redis 作为独立的存储,其数据天然可以被多进程共享;
- Redis 的指令是单线程执行的,所以不会出现多个指令并发地读写同一块数据;
- Redis 指令是纯内存操作,速度是微妙级的(不考虑网络时延),性能足够高;
有些人一想到“单线程-高性能”就条件反射地回答 IO 多路复用,其实 Redis 高性能最主要就是纯内存操作。
Redis 分布式锁的大体调用框架是这样的:
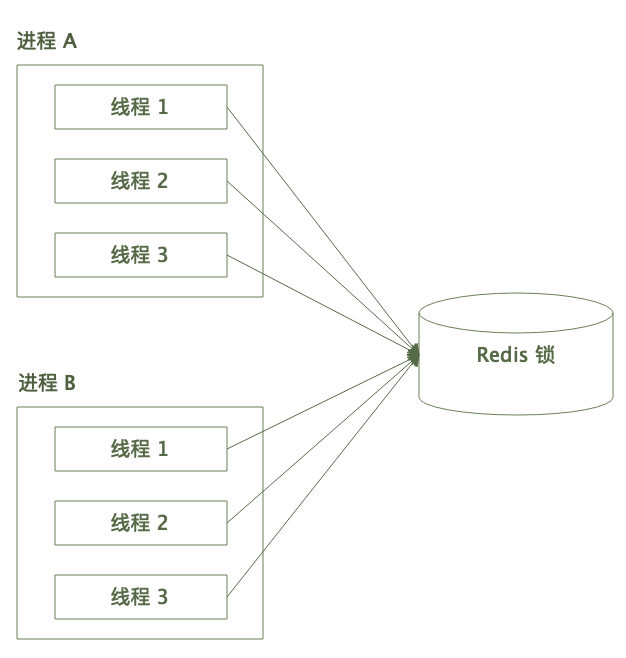
多个进程的多个线程争抢同一把 Redis 锁。
说到 Redis 分布式锁,大部分人都会想到 setnx 指令:
// setnx 使用方式
SETNX key value
意思是:如果 key 不存在(Not eXists),则将 key 设置为 value 并返回 1,否则啥也不做并返回 0——也就是说, key 只会被设置一次,利用这个特性就可以实现锁(如果返回 1 表示加锁成功,0 则说明别人已经加锁了,本次加锁失败)。
我们写下伪代码:
// 获取 redis client 单例
var redis = NewRedisClient(redisConf);
// 通过 SETNX 指令加锁
func lock(string lockKey) bool {
result = redis.setnx(lockKey, 1);
return bool(result);
}
// 通过 DEL 指令解锁
func unlock(string lockKey) {
redis.del(lockKey);
}
上面的定时任务进程中这样使用:
var lockKey = "batch:task:list"
// 上锁
if (!lock(lockKey)) {
// 获取锁失败,直接返回
return false;
}
try {
// 查询数据库获取待处理任务列表
// 更新任务状态
// 入列
} finally {
// 解锁
unlock(lockKey);
}
很简单!半小时搞定,上线!
第一次懵逼
上线没跑几天就出问题了:任务无缘无故地不执行了,消息队列中很长时间没接收到消息了。
分析了半天,我们发现 Redis 中一直存在 batch:task:list 这条记录,没人去删除它!
盯着代码我们突然发现问题所在:这个 key 压根没有过期时间!也就是说,如果程序不 DEL 它就永远存在。
估计某进程在执行 unlock 之前崩溃了(或者哪个愣头青执行了 kill -9 ?),或者 unlock 时发生了网络问题,或者 Redis 宕机了?总之 DEL 没执行,于是这个锁永远得不到释放!
好办,加上过期时间呗:
...
// 通过 SETNX 指令加锁
// 加上过期时间,单位毫秒
func lock(string lockKey, int ttl = 3000) bool {
// 加锁
result = redis.setnx(lockKey, 1);
// 设置过期时间(毫秒)
redis.pexpire(lockKey, ttl);
return bool(result);
}
...
这段代码有什么问题呢?
这里通过两次网络请求执行了两条 Redis 指令:setnx 设置 KV,expire 设置超时时间——我们前面说锁操作必须具备原子性,但这两条操作谁也不能保证要么都成功要么都失败啊。假如第一条指令(setnx)执行成功了,但 expire 由于网络原因或者进程崩溃导致执行失败了呢?此时同样会出现上面那个懵逼的问题啊。
我们可以用 Lua 脚本实现 setnx 和 expire 操作的原子性,不过 Redis 2.6.12 版本后可以用 SET 指令搞定:
// 2.6.12 后的 SET 指令格式
// 现在的 SET 指令相当强大也相当复杂,可以替代 SETNX, SETEX, PSETEX, GETSET, 此处只写出跟分布式锁有关的
// 其中两个可选参数:
// -- NX 表示 Not eXists,就是 SETNX 的意思;
// -- PX 是 PEXPIRE 的意思,表示设置 key 的过期时间(毫秒);
SET key value [NX] [PX milliseconds]
改下 Lock 代码:
// 加锁
func lock(string lockKey, int ttl = 3000) bool {
// Set 函数参数对应上面的命令格式
result = redis.set(lockKey, 1, "NX", "PX", ttl);
return bool(result);
}
如此,加了过期时间防止锁无法释放,还保证了加锁操作的原子性,妥了,上线!
第二次懵逼
第二次上线没多久又出现了灵异事件:偶尔会出现一批任务重复入列——敢情这锁加了个寂寞?
各种打日志,终于发现了端倪:有个进程加锁 3.5 秒后才解锁,而且解锁成功了——但我们设置的锁超时时间是 3 秒啊!
也就是说,这个线程解的是别的线程的锁!
// 通过 DEL 指令解锁
// 这里直接调 Redis 的 DEL 指令删除 lockKey,并没有判断该 lockKey 的值是不是本进程设置的
// 所以在有 TTL 的情况下,删的可能是别的线程加的锁
func unlock(string lockKey) {
redis.del(lockKey);
}
和进程内的本地锁不同的是,Redis 分布式锁加入超时机制后,锁的释放就存在两种情况:
- 加锁者主动释放;
- 超时被动释放;
所以解锁(DEL)之前需要判断锁是不是自己加的,方法是在加锁的时候生成一个唯一标识。之前我们 SET key value 时 value 给的是固定值 1,现在我们换成一个随机值:
// Redis 分布式锁
// 封装成类
// 该类实例不具备线程安全性,不应跨线程使用
class Lock {
private redis;
private name;
private token;
private ttl;
private status;
const ST_UNLOCK = 1;
const ST_LOCKED = 2;
const ST_RELEASED = 3;
public function Lock(Redis redis, string name, int ttl = 3000) {
this.redis = redis;
this.name = name;
this.token = randStr(16);// 生成 16 字节随机字符串
this.ttl = ttl;
this.status = self::ST_UNLOCK;
}
// 加锁
public function lock() bool {
if (this.status != self::ST_UNLOCK) {
return false;
}
// 使用 SET 命令加锁
// value 不再传 1,而是设置成构造函数中生成的随机串
try {
result = redis.set(this.name, this.token, "NX", "PX", this.ttl);
if (bool(result)) {
this.status = self::ST_LOCKED;
return true;
}
} catch (Exception e) {
return false;
}
return false;
}
// 解锁
public function unlock() {
if (this.status != self::ST_LOCKED) {
return;
}
// 执行 DEL 之前需要用 GET 命令判断 KEY 的值是不是当前的 token
// 由于需要执行 GET 和 DEL 两条指令,而锁操作必须保证原子性,需要用 Lua 脚本
// 脚本中通过 redis.call() 执行 Redis 命令
// 注意 Lua 脚本数组下标从 1 开始
// 这段脚本的意思是:
// 如果 key 的值是 token,则 DEL key,否则啥也不做
var lua = "
if (redis.call('get', KEYS[1]) == ARGV[1]) then
redis.call('del', KEYS[1]);
end
return 1;
";
// 调 Redis 的 EVEL 指令执行 Lua 脚本
// EVAL 指令格式:
// EVEL script numkeys key1,key2,arg1,arg2...
// -- script: Lua 脚本
// -- numkeys: 说明后面的参数中,有几个是 key,这些 key 后面的都是参数
// 比如:EVAL "redis.call('set', KEYS[1], ARGV[1])" 1 mykey hello
// 等价于命令 SET mykey hello
// 参见:https://redis.io/commands/eval/
redis.eval(lua, 1, this.name, this.token);
this.status = self::ST_RELEASED;
}
}
业务调用:
lock = new Lock(redis, "batch:task:list");
try {
if (!lock.lock()) {
return false;
}
// 加锁成功,执行业务
} finally {
lock.unlock();
}
上面这段代码实现了:
- 加锁的时候设置了过期时间,防止进程崩溃而导致锁无法释放;
- 解锁的时候判断了当前的锁是不是自己加的,防止释放别人的锁;
- 加锁和解锁操作都具备原子性;
这段代码已经是生产可用了,第三次上线。
不过,还是有些优化需要做的。
优化一:锁等待
上面的 lock() 方法中,如果获取锁失败则直接返回 false,结束执行流,这可能不能满足某些业务场景。
在本地锁场景中,如果获取锁失败,线程会进入阻塞等待状态——我们希望分布式锁也能提供该功能。
我们在加锁失败时增加重试功能:
class Lock {
// 重试间隔:1 秒
const RETRY_INTERVAL = 1000;
// ...
// 重试次数(包括首次)
private retryNum;
// retryNum: 默认只执行一次(不重试)
public function Lock(Redis redis, string name, int ttl = 3000, int retryNum = 1) {
...
// 做下防御
if (retryNum < 0 || retryNum > 20) {
retryNum = 1;
}
this.retryNum = retryNum;
}
// 加锁
public function lock() bool {
if (this.status != self::ST_UNLOCK) {
return false;
}
// 使用 SET 命令加锁
// 加入重试机制
for (i = 0; i < this.retryNum; i++) {
try {
result = redis.set(this.name, this.token, "NX", "PX", this.ttl);
if (bool(result)) {
// 加锁成功,返回
this.status = self::ST_LOCKED;
return true;
}
} catch (Exception e) {
}
// 加锁失败了,等待一定的时间后重试
// 当前线程/协程进入休眠
sleep(self::RETRY_INTERVAL);
}
return false;
}
}
优化二:锁超时
我们再回头看看上面的加锁逻辑,其核心代码如下:
public function lock() bool {
// ...
result = redis.set(this.name, this.token, "NX", "PX", this.ttl);
if (bool(result)) {
// 加锁成功,返回
this.status = self::ST_LOCKED;
return true;
}
//...
}
这段代码有没有什么问题呢?
想象如下的加锁场景:
// 锁超时时间是 2 秒
var lock = new Lock(redis, name, 2000);
if (lock.lock()) {
// 加锁成功,加锁用时 2.5 秒
try {
// 执行业务逻辑
} finally {
// 解锁
lock.unlock();
}
}
如上,我们创建一个有效期 2 秒的锁,然后调 Redis 命令加锁,该过程花了 2.5 秒(可能网络抖动)。
对于本线程来说,得到加锁成功的返回值,继续往下执行。
但此时该 lockKey 在 Redis 那边可能已经过期了,如果此时另一个线程去拿锁,也会成功拿到锁——如此锁的作用便失效了。
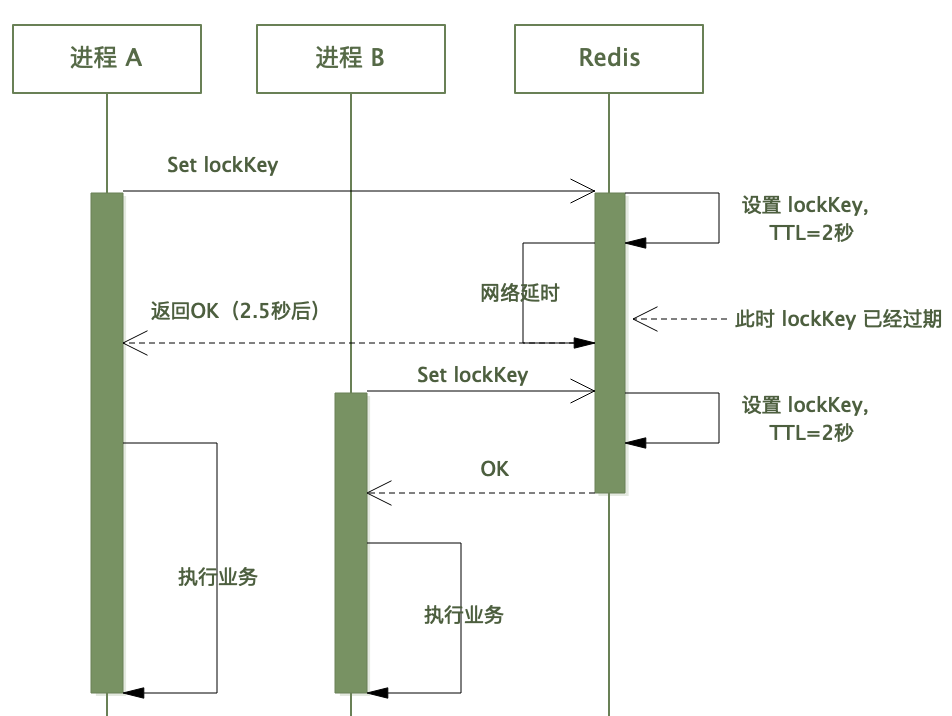
所以,在 lock() 方法中,调 Redis 上锁成功后,需要判断上锁用时,如果时间超过了锁的有效期,则应视为上锁无效,如果有重试机制,则重试:
class Lock {
// 加锁
public function lock() bool {
if (this.status != self::ST_UNLOCK) {
return false;
}
for (i = 0; i < this.retryNum; i++) {
try {
// 上锁之前,保存当前毫秒数
var startTime = getMillisecond();
// 上锁
result = redis.set(this.name, this.token, "NX", "PX", this.ttl);
// 上锁后,计算使用的时间
var useTime = getMillisecond() - startTime;
// 加锁成功条件:Redis 上锁成功,且所用的时间小于锁有效期
if (bool(result) && useTime < this.ttl) {
// 加锁成功,返回
this.status = self::ST_LOCKED;
return true;
}
} catch (Exception e) {}
// 加锁失败了,等待一定的时间后重试
// 当前线程/协程进入休眠
sleep(self::RETRY_INTERVAL);
}
return false;
}
}
如上,在判断条件中增加了加锁用时的判断。
这段代码还有问题吗?
有的。
我们用 Redis 的 SET NX 命令加锁,该命令如果发现 key 已经存在,则直接返回 0,加锁失败。
在上面的失败重试逻辑中,如果是因为加锁用时超限导致的失败(锁有效期是 2 秒,结果加锁操作用了 2.5 秒),此时我们并不能切确知道在 Redis 那边该 key 是否真的已经失效了,如果没有失效(比如来去网络用时各 1.24 秒,此时该 key 并没有失效),那么下一次的重试会因 SET NX 的机制而失败。
所以我们不能用 SET NX 加锁,只能用普通的 SET + Lua 脚本来实现:
class Lock {
// 加锁
public function lock() bool {
if (this.status != self::ST_UNLOCK) {
return false;
}
// 加锁的 Lua 脚本
// 注意 Lua 中的注释不是用 // 或者 /**/,而是用 --
// 参数说明:
// KEYS[1]: lockKey
// ARGV[1]: token
// ARGV[2]: ttl 毫秒
var lua = "
local val = redis.call('get', KEYS[1]);
if (not val) then
-- 没有设置,则直接设置
return redis.call('set', KEYS[1], ARGV[1], 'PX', ARGV[2]);
else
-- 存在,则比较 val 是否等于 token
if (val == ARGV[1] ) then
-- 该 key 就是当前线程设置的
-- 延长其 TTL
return redis.call('pexpire', KEYS[1], ARGV[2]);
else
-- 其他线程上的锁
return 0;
end
end
";
for (i = 0; i < this.retryNum; i++) {
// 加锁逻辑同上
}
return false;
}
}
如此,便解决了加锁超时导致的竞态问题——但只解决了一半。
设想这样的场景:
进程 A 加了一个有效期 5 秒的锁,加锁成功后执行业务逻辑,业务逻辑执行耗时 10 秒——就是说,在业务逻辑执行到差不多一半的时候锁就失效了,此时别的进程就可以抢到锁了,这就会导致竞态问题。
有两种解决方案:
- 设置个较长的过期时间。这是最简单的(而且也很有效)。比如我们预估 99% 的处理时间不超过 2 秒,则将锁有效期设置为 10 秒。该方案最大的缺点是一旦进程崩溃导致无法主动释放锁,就会导致其他进程在很长一段时间内(如 10 秒)无法获得锁,这在某些场景下可能是非常严重的。
- 搞个定时任务线程,定时延长锁的有效期。
方案二伪代码如下:
// 带 Refresh 版本的分布式锁
class Lock {
private redis;
private name;
private ttl;
private token;
private retryNum;
private status;
// 定时器
private timer;
// 锁状态:1 未加锁;2 已加锁;3 已释放
const ST_UNLOCK = 1;
const ST_LOCKED = 2;
const ST_RELEASED = 3;
// 刷新状态:
// 4 刷新成功;
// 5 非法(key 不存在或者不是本线程加的锁)
// 6 刷新失败(Redis 不可用)
const RF_SUC = 4;
const RF_INVALID = 5;
const RF_FAIL = 6;
// 构造函数
public function Lock(Redis redis, string name, int ttl = 2000, int retryNum = 1) {
...
}
// 加锁
// 加锁成功后启动定时器
public function lock() bool {
if (this.status != self::ST_UNLOCK) {
return false;
}
// 加锁的 Lua 脚本,同前面的
lua = "...";
for (i = 0; i < this.retryNum; i++) {
var startTime = getMillisecond();
try {
// 执行 Lua 脚本上锁
result = this.redis.eval(lua, 1, this.name, this.token, this.ttl);
var useTime = getMillisecond() - startTime;
if (bool(result) && useTime < this.ttl) {
// 加锁成功
this.status = self::ST_LOCKED;
// 启动定时器
this.tick();
return true;
}
} catch (Exception e) {
// Redis 不可用
}
// 失败重试
sleep(RETRY_INTERVAL);
}
return false;
}
// 启动定时器,定时刷新过期时间
private function tick() {
this.timer = startTimerInterval(
this.ttl / 3,
function () {
result = this.refresh();
if (result == self::RF_INVALID) {
// key 不存在,或者该锁被其他线程占用
// 停掉定时器
this.timer.stop();
}
}
);
}
// 释放锁
// 需要停掉定时器
public function unlock() {
if (this.status != self::ST_LOCKED) {
return;
}
// 释放锁的 Lua 脚本,同前
var lua = "...";
try {
this.redis.eval(lua, 1, this.name, this.token);
} catch (Exception e) {} finally {
this.status = self::ST_RELEASED;
// 停掉定时器
this.timer.stop();
}
}
// 刷新锁过期时间
private function refresh() int {
if (this.status != self::ST_LOCKED) {
return self::RF_INVALID;
}
var lua = "
-- key 存在而且其值等于 token 才刷新过期时间
if (redis.call("get", KEYS[1]) == ARGV[1]) then
return redis.call("pexpire", KEYS[1], ARGV[2])
else
return 0
end
";
try {
result = this.redis.eval(lua, 1, this.name, this.token, this.ttl);
if (result == 0) {
// key 不存在或者是别人加的锁
return self::RF_INVALID;
} else {
// 刷新成功
return self::RF_SUC;
}
} catch (Exception e) {
// Redis 不可用
return self::RF_FAIL;
}
}
}
如上,加锁成功后创建一个单独的定时器(独立的线程/协程)刷新锁的 TTL,只要锁没被主动释放(而且进程没有崩溃),就会不停地续命,保证不会过期。此时,我们就能在加锁时选择一个比较小的过期时间(比如 2 秒),一旦进程崩溃,其他进程也能较快获得锁。
上面定时器时间为何选择 ttl/3 呢?
假设锁过期时间(ttl)为 6 秒,由上面 lock() 函数逻辑可知,加锁耗时不可能超过 6 秒(超过就会判定为加锁失败)。我们假设某次加锁耗时比 6 秒小那么一丢丢(也就是近似 6 秒),接下来什么时候发起第一次刷新才能保证 Redis 那边的 key 不过期呢?极端情况下必须立即刷新(如果考虑刷新时的网络时延,就算立即刷新也不一定能保证)。
不过我们考虑的是一般情况。我们可以认为 6 秒耗时都花在网络上(Redis 本身执行时间可以忽略不计),然后再近似认为这 6 秒被来去均摊,各花 3 秒,因而当我们接收到 Redis 的响应时,该 key 在 Redis 那边的 TTL 已经用掉了一半,所以定时间隔必须小于 ttl/2,再将刷新时的网络时延考虑进去,取 ttl/3 或者 ttl/4 比较合适。
就算有了 refresh 机制,也不能说是万无一失了。
考虑 Redis 宕机或者网络不通的情况。
假设线程 A 加锁(ttl=2s)后不久 Redis 就宕机了(或者该业务服所在网络发生分区导致网络不通),宕机期间 refresh 会失败。2s 后 Redis 重启恢复正常,此时线程 A 设置的那个 key 已经过期了,其他线程就能够获取锁,如果线程 A 的执行时间超过 2s,就和其他线程产生竞态。
refresh 机制解决不了该问题,要用其他手段来保证 Redis 和锁的高可用性,如 Redis 集群、官方提供的 Redlock 方案等。
可重入性
一些语言(如 java)内置可重入锁,一些语言(如 go)则不支持。
我们通过代码说下可重入锁是什么:
var lock = newLock();
// 在同一个线程中, foo() 调 bar()
// 函数 foo() 和 bar() 都在竞争同一把锁
function foo() {
lock.lock();
...
bar();
...
lock.unlock();
}
function bar() {
lock.lock();
// do something
lock.unlock();
}
如上,同一个线程中 foo() 调 bar(),由于 foo() 调 bar() 之前加了锁,因而 bar() 中再竞争该锁时就会一直等待,导致 bar() 函数执行不下去,进而导致 foo() 函数无法解锁,于是造成死锁。
如果上面的 lock 是一把可重入锁,bar() 就会加锁成功。
实现原理是:加锁的 lock() 方法中会判断当前这把锁被哪个线程持有,如果持有锁的线程和现在抢锁的线程是同一个线程,则视为抢锁成功(这锁本来就是被它持有的嘛,抢啥呢)。
由于 foo() 和 bar() 是在同一个线程中调用的,所以他俩都会加锁成功。
锁是加成功了,解锁呢?bar() 中的 unlock() 要怎么处理呢?直接把锁释放掉?不行啊,foo() 中的 unlock() 还没执行呢,bar() 虽然用完锁了,但 foo() 还没用完啊,你 bar() 三下五除二把锁给释放了,其他线程拿到锁,不就和 foo() 中代码构成竞态了吗?
所以可重入锁采用信号量的思想,在内部维持了两个属性:threadid 表示哪个线程持有锁;lockNum 表示持有线程加了几次锁。同一个线程,每 lock() 一次 lockNum 加 1,每 unlock() 一次 lockNum 减 1,只有 lockNum 变成 0 了才表示这把锁真正释放了,其他线程才能用。
原理讲完了,但你不觉得上面的代码很怪吗?
既然 foo() 已经加锁了,bar() 为何还要加同一把锁呢?
在某些情况下这样做可能是有原因的,但大多数情况下,这个问题可以从设计上解决,而不是非要引入可重入锁。
比如我们可以将 bar() 声明为非线程安全的,将加锁工作交给调用者,同时限制 bar() 的可见域,防止其被滥用。
go 语言不支持可重入锁的理由就是:当你的代码需要用可重入锁了,你首先要做的是审视你的设计是否有问题。
可重入锁的便捷性可能会带来代码设计上的问题。
所以本篇并不打算去实现可重入能力——虽然实现起来并不难,无非是将上面讲的原理在 Redis 上用 Lua 脚本实现一遍而已。
不是银弹
有了锤子,全世界都是钉子。
分布式锁看似是颗银弹,但有些问题用其他方案会比分布式锁要好。
我们看看秒杀扣库存的例子。
网上很多讲分布式锁的文章都拿秒杀扣库存来举例。
秒杀场景为了应对高并发,一般会将秒杀商品库存提前写入到 Redis 中,我们假设就用字符串类型存商品库存:
// Redis 命令,设置商品 id=1234 的库存 100 件
set seckill.stock.1234 100
另外一个用户只能参加一次秒杀,所以扣库存前需要判断该用户是否已经参加了(防止羊毛党薅羊毛)。
扣库存逻辑是这样的:
var stockKey = "seckill.stock.1234";
var userKey = "seckill.ordered.users";
var lock = new Lock(redis, "seckill");
// 此处省略活动时间的判断
try {
// 加分布式锁
lock.lock();
// 判断库存
var stockNum = redis.get(stockKey);
if (stockNum <= 0) {
// 库存不足
return false;
}
// 判断用户是否已经参加过
if (redis.sismember(userKey, userId)) {
return false;
}
// 扣库存
if (redis.decr(stockKey) >= 0) {
// 下单
...
} else {
return false;
}
// 将用户加入到已参加集合中
redis.sadd(userKey, userId);
return true;
} catch (Exception e) {
// 异常
} finally {
// 解锁
lock.unlock();
}
以上逻辑为何要用分布式锁呢?
假设不用分布式锁,羊毛党同时发了十个请求(同一个用户),由于 redis.sismember(userKey, userId) 判断都会返回 0,于是都能扣库存下单,羊毛薅了一地。
但该场景有没有更优的解决方案呢?
我们使用分布式锁是为了保证临界区代码(lock 保护的区域)执行的原子性——不过 Redis 的原子性还可以通过 Lua 脚本来实现吧。
上面代码一共进行了 6 次 Redis 交互,假设每次用时 50ms,光 Redis 交互这块就用了 0.3s 的时间。
如果我们将这些逻辑封装成 Lua 脚本,只需要一次 Redis 交互就能保证原子性:
var lua = "
-- 参数说明:
-- KEYS[1]: actKey
-- KEYS[2]: userKey
-- KEYS[3]: stockKey
-- ARGV[1]: userId
-- 判断活动时间
-- (事先将活动的关键信息保存到 Redis hash 中)
-- 取活动的开始和结束时间
local act = redis.call('hmget', KEYS[1], 'start', 'end');
local now = redis.call('time')[1];
if (not act[1] or now < act[1] or now >= act[2])
then
return 0;
end
-- 判断库存
local stock = redis.call('get', KEYS[3]);
if (not stock or tonumber(stock) <= 0)
then
return 0;
end
-- 判断用户是否已经参与过
if (redis.call('sismember', KEYS[2], ARGV[1]) == 1)
then
return 0;
end
-- 扣库存
if (redis.call('decr', KEYS[3]) >= 0)
then
-- 加入用户
return redis.call('sadd', KEYS[2], ARGV[1]);
else
return 0;
end
";
var actKey = "seckill.act."+actId;
var userKey = actKey + ".users";
var stockKey = actKey + ".stock." + goodsId;
if (redis.eval(lua, 3, actKey, userKey, stockKey, userId)) {
// 扣库存成功,下单
...
}
上面的脚本还可以先缓存到 Redis 服务器中,然后用 evalsha 命令执行,这样客户端就不用每次都传这么一大坨代码,进一步提升传输性能。
总结
本篇我们从 setnx 命令开始实现了一个最简单的分布式锁,而后通过实际使用发现其存在各种缺陷并逐步增强其实现,主要涉及到以下几个方面:
- 被动释放。进程崩溃后,进程本地锁自然会销毁,但 Redis 锁不会。所以要加 TTL 机制,防止因加锁者崩溃而导致锁无法释放;
- 属主。线程不能释放别的线程的锁;
- 锁等待。加锁失败时可以等待一段时间并重试,而不是立即返回;
- 保活。通过定时刷新锁的 TTL 防止被动释放;
不难发现,分布式锁比进程内本地锁要复杂得多,也重得多(本地锁操作是纳秒级别,分布式锁操作是毫秒级别),现实中,在使用分布式锁之前我们要思考下有没有其它更优方案,比如乐观锁、Lua 脚本等。
另外需要注意的是,分布式锁只能解决多进程之间的并发问题,并不能实现数据操作的幂等性。一个例子是增减积分的操作。
增加积分的例子:
// 给用户增加积分
// sourceType、sourceId:积分来源标识,如消费赠送积分场景的 orderCode
// 幂等性:同样的 userId-sourceType-sourceId 不能重复加积分
function addBonus(userId, sourceType, sourceId, bonus) {
// 加分布式锁
var lock = new Lock(...);
try {
if (!lock.lock()) {
return false;
}
// 检查是否重复
if (isRepeat(userId, sourceType, sourceId)) {
return false;
}
// 加积分
add(userId, sourceType, sourceId, bonus);
} finally {
lock.unlock();
}
}
上面分布式锁的作用是防止并发请求(调用端 bug?薅羊毛?),而该操作的幂等性是由 isRepeat() 保证的(查数据库)。
保障幂等性一般有悲观锁和乐观锁两种模式。
上面这种属于悲观锁模式(把整个操作锁起来),另一种乐观锁实现方式是给 userId-sourceType-sourceId 加上组合唯一键约束,此时就不需要加分布式锁,也不需要 isRepeat() 检测,直接 add(userId, sourceType, sourceId, bonus) 就能搞定。
最后说下文中为啥使用伪代码(而不是用具体某一门编程语言实现)。
用伪代码的最主要目的是省去语言特定的实现细节,将关注点放在逻辑本身。
比如 redis 客户端,不同语言有不同的使用方式,就算同一门语言的不同类库用法也不同,有些语言的类库用起来又臭又长,影响心情。
伪代码不受特定语言约束,用起来自由自在,本文中 redis 客户端的使用方式和 Redis 官方的原始命令格式完全一致,没有额外的心智负担。
再比如生成 token 的随机字符串函数 randStr(),go 语言要这样写:
func randStr(size int) (string, error) {
sl := make([]byte, size)
if _, err := io.ReadFull(rand.Reader, sl); err != nil {
return "", err
}
return base64.RawURLEncoding.EncodeToString(sl), nil
}
代码虽然不多,但没玩过 go 的小伙伴看到这儿心里是不是要起伏那么两三下?但这玩意怎么实现跟本文的主题没半毛钱关系。
相反,本文的 lua 脚本都是货真价实的,测试通过的——因为这是本文的核心啊。
伪代码的缺点是它不能“拎包入住”,但本文的重点并不是要写个源码库——我们没必要真的自己写一个,直接用 redission 或者其他什么库不香吗?
本文的重点在于分析 Redis 分布式锁的原理,分布式锁面临哪些问题?解决思路是什么?使用时要注意什么?知其然知其所以然。
当你不知其所以然时,很多东西显得特高大上,什么“看门狗”,搞得神乎其神,当搞明白其原理和目的时,也就那么回事。
