一、概述vivo 互联网服务器团队 - Ma Jian
SPI(Service Provider Interface),是Java内置的一种服务提供发现机制,可以用来提高框架的扩展性,主要用于框架的开发中,比如Dubbo,不同框架中实现略有差异,但核心机制相同,而Java的SPI机制可以为接口寻找服务实现。SPI机制将服务的具体实现转移到了程序外,为框架的扩展和解耦提供了极大的便利。
得益于SPI优秀的能力,为模块功能的动态扩展提供了很好的支撑。
本文会先简单介绍Java内置的SPI和Dubbo中的SPI应用,重点介绍分析Spring中的SPI机制,对比Spring SPI和Java内置的SPI以及与 Dubbo SPI的异同。
二、Java SPIJava内置的SPI通过java.util.ServiceLoader类解析classPath和jar包的META-INF/services/目录 下的以接口全限定名命名的文件,并加载该文件中指定的接口实现类,以此完成调用。
2.1 Java SPI先通过代码来了解下Java SPI的实现
① 创建服务提供接口
package jdk.spi;
// 接口
public interface DataBaseSPI {
public void dataBaseOperation();
}
② 创建服务提供接口的实现类
- MysqlDataBaseSPIImpl
实现类1
package jdk.spi.impl;
import jdk.spi.DataBaseSPI;
public class MysqlDataBaseSPIImpl implements DataBaseSPI {
@Override
public void dataBaseOperation() {
System.out.println("Operate Mysql database!!!");
}
}
- OracleDataBaseSPIImpl
实现类2
package jdk.spi.impl;
import jdk.spi.DataBaseSPI;
public class OracleDataBaseSPIImpl implements DataBaseSPI {
@Override
public void dataBaseOperation() {
System.out.println("Operate Oracle database!!!");
}
}
③ 在项目META-INF/services/目录下创建jdk.spi.DataBaseSPI文件

jdk.spi.DataBaseSPI
jdk.spi.impl.MysqlDataBaseSPIImpl
jdk.spi.impl.OracleDataBaseSPIImpl
④ 运行代码:
JdkSpiTest#main()
package jdk.spi;
import java.util.ServiceLoader;
public class JdkSpiTest {
public static void main(String args[]){
// 加载jdk.spi.DataBaseSPI文件中DataBaseSPI的实现类(懒加载)
ServiceLoader<DataBaseSPI> dataBaseSpis = ServiceLoader.load(DataBaseSPI.class);
// ServiceLoader实现了Iterable,故此处可以使用for循环遍历加载到的实现类
for(DataBaseSPI spi : dataBaseSpis){
spi.dataBaseOperation();
}
}
}
⑤ 运行结果:
Operate Mysql database!!!
Operate Oracle database!!!
上述实现即为使用Java内置SPI实现的简单示例,ServiceLoader是Java内置的用于查找服务提供接口的工具类,通过调用load()方法实现对服务提供接口的查找(严格意义上此步并未真正的开始查找,只做初始化),最后遍历来逐个访问服务提供接口的实现类。
上述访问服务实现类的方式很不方便,如:无法直接使用某个服务,需要通过遍历来访问服务提供接口的各个实现,到此很多同学会有疑问:
- Java内置的访问方式只能通过遍历实现吗?
- 服务提供接口必须放到META-INF/services/目录下?是否可以放到其他目录下?
在分析源码之前先给出答案:两个都是的;Java内置的SPI机制只能通过遍历的方式访问服务提供接口的实现类,而且服务提供接口的配置文件也只能放在META-INF/services/目录下。
ServiceLoader部分源码
public final class ServiceLoader<S> implements Iterable<S>{
// 服务提供接口对应文件放置目录
private static final String PREFIX = "META-INF/services/";
// The class or interface representing the service being loaded
private final Class<S> service;
// 类加载器
private final ClassLoader loader;
// The access control context taken when the ServiceLoader is created
private final AccessControlContext acc;
// 按照初始化顺序缓存服务提供接口实例
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
// 内部类,实现了Iterator接口
private LazyIterator lookupIterator;
}
从源码中可以发现:
- ServiceLoader类本身实现了Iterable接口并实现了其中的iterator方法,iterator方法的实现中调用了LazyIterator这个内部类中的方法,解析完服务提供接口文件后最终结果放在了Iterator中返回,并不支持服务提供接口实现类的直接访问。
- 所有服务提供接口的对应文件都是放置在META-INF/services/目录下,final类型决定了PREFIX目录不可变更。
所以Java内置的SPI机制思想是非常好的,但其内置实现上的不足也很明显。
三、Dubbo SPIDubbo SPI沿用了Java SPI的设计思想,但在实现上有了很大的改进,不仅可以直接访问扩展类,而且在访问的灵活性和扩展的便捷性都做了很大的提升。
3.1 基本概念① 扩展点
一个Java接口,等同于服务提供接口,需用@SPI注解修饰。
② 扩展
扩展点的实现类。
③ 扩展类加载器:ExtensionLoader
类似于Java SPI的ServiceLoader,主要用来加载并实例化扩展类。一个扩展点对应一个扩展加载器。
④ Dubbo扩展文件加载路径
Dubbo框架支持从以下三个路径来加载扩展类:
- META-INF/dubbo/internal
- META-INF/dubbo
- META-INF/services
Dubbo框架针对三个不同路径下的扩展配置文件对应三个策略类:
- DubboInternalLoadingStrategy
- DubboLoadingStrategy
- ServicesLoadingStrategy
三个路径下的扩展配置文件并没有特殊之处,一般情况下:
- META-INF/dubbo对开发者开放
- META-INF/dubbo/internal 用来加载Dubbo内部的扩展点
- META-INF/services 兼容Java SPI
⑤ 扩展配置文件
和Java SPI不同,Dubbo的扩展配置文件中扩展类都有一个名称,便于在应用中引用它们。
如:Dubbo SPI扩展配置文件
#扩展实例名称=扩展点实现类
adaptive=org.apache.dubbo.common.compiler.support.AdaptiveCompiler
jdk=org.apache.dubbo.common.compiler.support.JdkCompiler
javassist=org.apache.dubbo.common.compiler.support.JavassistCompiler
先通过代码来演示下 Dubbo SPI 的实现。
① 创建扩展点(即服务提供接口)
扩展点
package dubbo.spi;
import org.apache.dubbo.common.extension.SPI;
@SPI // 注解标记当前接口为扩展点
public interface DataBaseSPI {
public void dataBaseOperation();
}
② 创建扩展点实现类
- MysqlDataBaseSPIImpl
扩展类1
package dubbo.spi.impl;
import dubbo.spi.DataBaseSPI;
public class MysqlDataBaseSPIImpl implements DataBaseSPI {
@Override
public void dataBaseOperation() {
System.out.println("Dubbo SPI Operate Mysql database!!!");
}
}
- OracleDataBaseSPIImpl
扩展类2
package dubbo.spi.impl;
import dubbo.spi.DataBaseSPI;
public class OracleDataBaseSPIImpl implements DataBaseSPI {
@Override
public void dataBaseOperation() {
System.out.println("Dubbo SPI Operate Oracle database!!!");
}
}
③在项目META-INF/dubbo/目录下创建dubbo.spi.DataBaseSPI文件:

dubbo.spi.DataBaseSPI
#扩展实例名称=扩展点实现类
mysql = dubbo.spi.impl.MysqlDataBaseSPIImpl
oracle = dubbo.spi.impl.OracleDataBaseSPIImpl
PS:文件内容中,等号左边为该扩展类对应的扩展实例名称,右边为扩展类(内容格式为一行一个扩展类,多个扩展类分为多行)
④ 运行代码:
DubboSpiTest#main()
package dubbo.spi;
import org.apache.dubbo.common.extension.ExtensionLoader;
public class DubboSpiTest {
public static void main(String args[]){
// 使用扩展类加载器加载指定扩展的实现
ExtensionLoader<DataBaseSPI> dataBaseSpis = ExtensionLoader.getExtensionLoader(DataBaseSPI.class);
// 根据指定的名称加载扩展实例(与dubbo.spi.DataBaseSPI中一致)
DataBaseSPI spi = dataBaseSpis.getExtension("mysql");
spi.dataBaseOperation();
DataBaseSPI spi2 = dataBaseSpis.getExtension("oracle");
spi2.dataBaseOperation();
}
}
⑤ 运行结果:
Dubbo SPI Operate Mysql database!!!
Dubbo SPI Operate Oracle database!!!
从上面的代码实现直观来看,Dubbo SPI在使用上和Java SPI比较类似,但也有差异。
相同:
- 扩展点即服务提供接口、扩展即服务提供接口实现类、扩展配置文件即services目录下的配置文件 三者相同。
- 都是先创建加载器然后访问具体的服务实现类,包括深层次的在初始化加载器时都未实时解析扩展配置文件来获取扩展点实现,而是在使用时才正式解析并获取扩展点实现(即懒加载)。
不同:
- 扩展点必须使用@SPI注解修饰(源码中解析会对此做校验)。
- Dubbo中扩展配置文件每个扩展(服务提供接口实现类)都指定了一个名称。
- Dubbo SPI在获取扩展类实例时直接通过扩展配置文件中指定的名称获取,而非Java SPI的循环遍历,在使用上更灵活。
以上述的代码实现作为源码分析入口,了解下Dubbo SPI是如何实现的。
ExtensionLoader
① 通过ExtensionLoader.getExtensionLoader(Classtype)创建对应扩展类型的扩展加载器。
ExtensionLoader#getExtensionLoader()
public static <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {
if (type == null) {
throw new IllegalArgumentException("Extension type == null");
}
// 校验当前类型是否为接口
if (!type.isInterface()) {
throw new IllegalArgumentException("Extension type (" + type + ") is not an interface!");
}
// 接口上是否使用了@SPI注解
if (!withExtensionAnnotation(type)) {
throw new IllegalArgumentException("Extension type (" + type +
") is not an extension, because it is NOT annotated with @" + SPI.class.getSimpleName() + "!");
}
// 从内存中读取该扩展点的扩展类加载器
ExtensionLoader<T> loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
// 内存中不存在则直接new一个扩展
if (loader == null) {
EXTENSION_LOADERS.putIfAbsent(type, new ExtensionLoader<T>(type));
loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
}
return loader;
}
getExtensionLoader()方法中有三点比较重要的逻辑:
- 判断当前type类型是否为接口类型。
- 当前扩展点是否使用了@SPI注解修饰。
- EXTENSION_LOADERS为ConcurrentMap类型的内存缓存,内存中存在该类型的扩展加载器则直接使用,不存在就new一个并放入内存缓存中。
再看下new ExtensionLoader(type)源码
ExtensionLoader#ExtensionLoader()
// 私有构造器
private ExtensionLoader(Class<?> type) {
this.type = type;
// 创建ExtensionFactory自适应扩展
objectFactory = (type == ExtensionFactory.class ? null : ExtensionLoader.getExtensionLoader(ExtensionFactory.class).getAdaptiveExtension());
}
重点:构造方法为私有类型,即外部无法直接使用构造方法创建ExtensionLoader实例。
每次初始化ExtensionLoader实例都会初始化type和objectFactory ,type为扩展点类型;objectFactory 为ExtensionFactory类型。
② 使用getExtension()获取指定名称的扩展类实例getExtension为重载方法,分别为getExtension(String name)和getExtension(String name, boolean wrap),getExtension(String name)方法最终调用的还是getExtension(String name, boolean wrap)方法。
ExtensionLoader#getExtension()
public T getExtension(String name) {
// 调用两个参数的getExtension方法,默认true表示需要对扩展实例做包装
return getExtension(name, true);
}
public T getExtension(String name, boolean wrap) {
if (StringUtils.isEmpty(name)) {
throw new IllegalArgumentException("Extension name == null");
}
if ("true".equals(name)) {
return getDefaultExtension();
}
// 获取Holder实例,先从ConcurrentMap类型的内存缓存中取,没值会new一个并存放到内存缓存中
// Holder用来存放一个类型的值,这里用于存放扩展实例
final Holder<Object> holder = getOrCreateHolder(name);
// 从Holder读取该name对应的实例
Object instance = holder.get();
if (instance == null) {
// 同步控制
synchronized (holder) {
instance = holder.get();
// double check
if (instance == null) {
// 不存在扩展实例则解析扩展配置文件,实时创建
instance = createExtension(name, wrap);
holder.set(instance);
}
}
}
return (T) instance;
}
Holder类:这里用来存放指定扩展实例
③ 使用createExtension()创建扩展实例
ExtensionLoader#createExtension()
// 部分createExtension代码
private T createExtension(String name, boolean wrap) {
// 先调用getExtensionClasses()解析扩展配置文件,并生成内存缓存,
// 然后根据扩展实例名称获取对应的扩展类
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null) {
throw findException(name);
}
try {
// 根据扩展类生成实例并对实例做包装(主要是进行依赖注入和初始化)
// 优先从内存中获取该class类型的实例
T instance = (T) EXTENSION_INSTANCES.get(clazz);
if (instance == null) {
// 内存中不存在则直接初始化然后放到内存中
EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
// 主要是注入instance中的依赖
injectExtension(instance);
......
}
createExtension()方法:创建扩展实例,方法中EXTENSION_INSTANCES为ConcurrentMap类型的内存缓存,先从内存中取,内存中不存在重新创建;其中一个核心方法是getExtensionClasses():
ExtensionLoader#getExtensionClasses()
private Map<String, Class<?>> getExtensionClasses() {
// 优先从内存缓存中读
Map<String, Class<?>> classes = cachedClasses.get();
if (classes == null) {
// 采用同步手段解析配置文件
synchronized (cachedClasses) {
// double check
classes = cachedClasses.get();
if (classes == null) {
// 正式开始解析配置文件
classes = loadExtensionClasses();
cachedClasses.set(classes);
}
}
}
return classes;
}
cachedClasses为Holder<map<string, class>>类型的内存缓存,getExtensionClasses中会优先读内存缓存,内存中不存在则采用同步的方式解析配置文件,最终在loadExtensionClasses方法中解析配置文件,完成从扩展配置文件中读出扩展类:
ExtensionLoader#loadExtensionClasses()
// 在getExtensionClasses方法中是以同步的方式调用,是线程安全
private Map<String, Class<?>> loadExtensionClasses() {
// 缓存默认扩展名称
cacheDefaultExtensionName();
Map<String, Class<?>> extensionClasses = new HashMap<>();
// strategies策略类集合,分别对应dubbo的三个配置文件目录
for (LoadingStrategy strategy : strategies) {
loadDirectory(extensionClasses, strategy.directory(), type.getName(), strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());
loadDirectory(extensionClasses, strategy.directory(), type.getName().replace("org.apache", "com.alibaba"), strategy.preferExtensionClassLoader(), strategy.overridden(),
strategy.excludedPackages());
}
return extensionClasses;
}
源码中的strategies即static volatile LoadingStrategy[] strategies数组,通过Java SPI从META-INF/services/目录下加载配置文件完成初始化,默认包含三个类:
- DubboInternalLoadingStrategy
- DubboLoadingStrategy
- ServicesLoadingStrategy
分别对应dubbo的三个目录:
- META-INF/dubbo/internal
- META-INF/dubbo
- META-INF/services
上述的源码分析只是对Dubbo SPI做了简要的介绍,Dubbo中对SPI的应用很广泛,如:序列化组件、负载均衡等都应用了SPI技术,还有很多SPI功能未做分析,比如:自适应扩展、Activate活性扩展等 等,感兴趣的同学可以更深入的研究。
四、Spring SPISpring SPI沿用了Java SPI的设计思想,但在实现上和Java SPI及Dubbo SPI也存在差异,Spring通过spring.handlers和spring.factories两种方式实现SPI机制,可以在不修改Spring源码的前提下,做到对Spring框架的扩展开发。
4.1 基本概念- DefaultNamespaceHandlerResolver
类似于Java SPI的ServiceLoader,负责解析spring.handlers配置文件,生成namespaceUri和NamespaceHandler名称的映射,并实例化NamespaceHandler。
- spring.handlers
自定义标签配置文件;Spring在2.0时便引入了spring.handlers,通过配置spring.handlers文件实现自定义标签并使用自定义标签解析类进行解析实现动态扩,内容配置如:
http\://www.springframework.org/schema/c=org.springframework.beans.factory.xml.SimpleConstructorNamespaceHandler
http\://www.springframework.org/schema/p=org.springframework.beans.factory.xml.SimplePropertyNamespaceHandler
http\://www.springframework.org/schema/util=org.springframework.beans.factory.xml.UtilNamespaceHandler
spring.handlers实现的SPI是以namespaceUri作为key,NamespaceHandler作为value,建立映射关系,在解析标签时通过namespaceUri获取相应的NamespaceHandler来解析
- SpringFactoriesLoader
类似于Java SPI的ServiceLoader,负责解析spring.factories,并将指定接口的所有实现类实例化后返回。
- spring.factories
Spring在3.2时引入spring.factories,加强版的SPI配置文件,为Spring的SPI机制的实现提供支撑,内容配置如:
# PropertySource Loaders
org.springframework.boot.env.PropertySourceLoader=\
org.springframework.boot.env.PropertiesPropertySourceLoader,\
org.springframework.boot.env.YamlPropertySourceLoader
# Run Listeners
org.springframework.boot.SpringApplicationRunListener=\org.springframework.boot.context.event.EventPublishingRunListener
spring.factories实现的SPI是以接口的全限定名作为key,接口实现类作为value,多个实现类用逗号隔开,最终返回的结果是该接口所有实现类的实例集合
- 加载路径
Java SPI从/META-INF/services目录加载服务提供接口配置,而Spring默认从META-INF/spring.handlers和META-INF/spring.factories目录加载配置,其中META-INF/spring.handlers的路径可以通过创建实例时重新指定,而META-INF/spring.factories固定不可变。
4.2 spring.handlers首先通过代码初步介绍下spring.handlers实现。
4.2.1 spring.handlers SPI① 创建NameSpaceHandler
MysqlDataBaseHandler
package spring.spi.handlers;
import org.springframework.beans.factory.config.BeanDefinition;
import org.springframework.beans.factory.xml.NamespaceHandlerSupport;
import org.springframework.beans.factory.xml.ParserContext;
import org.w3c.dom.Element;
// 继承抽象类
public class MysqlDataBaseHandler extends NamespaceHandlerSupport {
@Override
public void init() {
}
@Override
public BeanDefinition parse(Element element, ParserContext parserContext) {
System.out.println("MysqlDataBaseHandler!!!");
return null;
}
}
OracleDataBaseHandler
package spring.spi.handlers;
import org.springframework.beans.factory.config.BeanDefinition;
import org.springframework.beans.factory.xml.NamespaceHandlerSupport;
import org.springframework.beans.factory.xml.ParserContext;
import org.w3c.dom.Element;
public class OracleDataBaseHandler extends NamespaceHandlerSupport {
@Override
public void init() {
}
@Override
public BeanDefinition parse(Element element, ParserContext parserContext) {
System.out.println("OracleDataBaseHandler!!!");
return null;
}
}
② 在项目META-INF/目录下创建spring.handlers文件:
文件内容:
spring.handlers
#一个namespaceUri对应一个handler
http\://www.mysql.org/schema/mysql=spring.spi.handlers.MysqlDataBaseHandler
http\://www.oracle.org/schema/oracle=spring.spi.handlers.OracleDataBaseHandler
③ 运行代码:
SpringSpiTest#main()
package spring.spi;
import org.springframework.beans.factory.xml.DefaultNamespaceHandlerResolver;
import org.springframework.beans.factory.xml.NamespaceHandler;
public class SpringSpiTest {
public static void main(String args[]){
// spring中提供的默认namespace URI解析器
DefaultNamespaceHandlerResolver resolver = new DefaultNamespaceHandlerResolver();
// 此处假设nameSpaceUri已从xml文件中解析出来,正常流程是在项目启动的时候会解析xml文件,获取到对应的自定义标签
// 然后根据自定义标签取得对应的nameSpaceUri
String mysqlNameSpaceUri = "http://www.mysql.org/schema/mysql";
NamespaceHandler handler = resolver.resolve(mysqlNameSpaceUri);
// 验证自定义NamespaceHandler,这里参数传null,实际使用中传具体的Element
handler.parse(null, null);
String oracleNameSpaceUri = "http://www.oracle.org/schema/oracle";
handler = resolver.resolve(oracleNameSpaceUri);
handler.parse(null, null);
}
}
④ 运行结果:
MysqlDataBaseHandler!!!
OracleDataBaseHandler!!!
上述代码通过解析spring.handlers实现对自定义标签的动态解析,以NameSpaceURI作为key获取具体的NameSpaceHandler实现类,这里有别于Java SPI,其中:
DefaultNamespaceHandlerResolver是NamespaceHandlerResolver接口的默认实现类,用于解析自定义标签。
- DefaultNamespaceHandlerResolver.resolve(String namespaceUri)方法以namespaceUri作为参数,默认加载各jar包中的META-INF/spring.handlers配置文件,通过解析spring.handlers文件建立NameSpaceURI和NameSpaceHandler的映射。
- 加载配置文件的默认路径是META-INF/spring.handlers,但可以使用DefaultNamespaceHandlerResolver(ClassLoader, String)构造方法修改,DefaultNamespaceHandlerResolver有多个重载方法。
- DefaultNamespaceHandlerResolver.resolve(String namespaceUri)方法主要被BeanDefinitionParserDelegate的parseCustomElement()和decorateIfRequired()方法中调用,所以spring.handlers SPI机制主要用在bean的扫描和解析过程中。
下面从上述代码开始深入源码了解spring handlers方式实现的SPI是如何工作的。
- DefaultNamespaceHandlerResolver
① DefaultNamespaceHandlerResolver.resolve()方法本身是根据namespaceUri获取对应的namespaceHandler对标签进行解析,核心源码:
DefaultNamespaceHandlerResolver#resolve()
public NamespaceHandler resolve(String namespaceUri) {
// 1、核心逻辑之一:获取namespaceUri和namespaceHandler映射关系
Map<String, Object> handlerMappings = getHandlerMappings();
// 根据namespaceUri参数取对应的namespaceHandler全限定类名or NamespaceHandler实例
Object handlerOrClassName = handlerMappings.get(namespaceUri);
if (handlerOrClassName == null) {
return null;
}
// 2、handlerOrClassName是已初始化过的实例则直接返回
else if (handlerOrClassName instanceof NamespaceHandler) {
return (NamespaceHandler) handlerOrClassName;
}else {
String className = (String) handlerOrClassName;
try {
///3、使用反射根据namespaceHandler全限定类名加载实现类
Class<?> handlerClass = ClassUtils.forName(className, this.classLoader);
if (!NamespaceHandler.class.isAssignableFrom(handlerClass)) {
throw new FatalBeanException("Class [" + className + "] for namespace [" + namespaceUri +
"] does not implement the [" + NamespaceHandler.class.getName() + "] interface");
}
// 3.1、初始化namespaceHandler实例
NamespaceHandler namespaceHandler = (NamespaceHandler) BeanUtils.instantiateClass(handlerClass);
// 3.2、 初始化,不同的namespaceHandler实现类初始化方法逻辑有差异
namespaceHandler.init();
// 4、将初始化好的实例放入内存缓存中,下次解析到相同namespaceUri标签时直接返回,避免再次初始化
handlerMappings.put(namespaceUri, namespaceHandler);
return namespaceHandler;
}catch (ClassNotFoundException ex) {
throw new FatalBeanException("NamespaceHandler class [" + className + "] for namespace [" +
namespaceUri + "] not found", ex);
}catch (LinkageError err) {
throw new FatalBeanException("Invalid NamespaceHandler class [" + className + "] for namespace [" +
namespaceUri + "]: problem with handler class file or dependent class", err);
}
}
}
第1步:源码中getHandlerMappings()是比较核心的一个方法,通过懒加载的方式解析spring.handlers并返回namespaceUri和NamespaceHandler的映射关系。
第2步:根据namespaceUri返回对应的NamespaceHandler全限定名或者具体的实例(是名称还是实例取决于是否被初始化过,若是初始化过的实例会直接返回)
第3步:是NamespaceHandler实现类的全限定名,通过上述源码中的第3步,使用反射进行初始化。
第4步:将初始化后的实例放到handlerMappings内存缓存中,这也是第2步为什么可能是NamespaceHandler类型的原因。
看完resolve方法的源码,再看下resolve方法在Spring中调用场景,大致可以了解spring.handlers的使用场景:
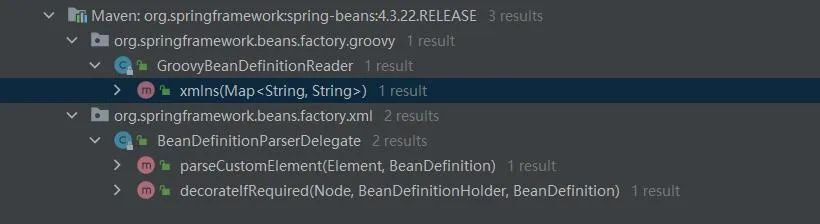
可以看到resolve()主要用在标签解析过程中,主要被在BeanDefinitionParserDelegate的parseCustomElement和decorateIfRequired方法中调用。
② resolve()源码中核心逻辑之一便是调用的getHandlerMappings(),在getHandlerMappings()中实现对各个jar包中的META-INF/spring.handlers文件的解析,如:
DefaultNamespaceHandlerResolver#getHandlerMappings()
private Map<String, Object> getHandlerMappings() {
Map<String, Object> handlerMappings = this.handlerMappings;
// 使用线程安全的解析逻辑,避免在并发场景下重复的解析,没必要重复解析
// 这里在同步代码块的内外对handlerMappings == null作两次判断很有必要,采用懒汉式初始化
if (handlerMappings == null) {
synchronized (this) {
handlerMappings = this.handlerMappings;
// duble check
if (handlerMappings == null) {
if (logger.isDebugEnabled()) {
logger.debug("Loading NamespaceHandler mappings from [" + this.handlerMappingsLocation + "]");
}
try {
// 加载handlerMappingsLocation目录文件,handlerMappingsLocation路径值可变,默认是META-INF/spring.handlers
Properties mappings =
PropertiesLoaderUtils.loadAllProperties(this.handlerMappingsLocation, this.classLoader);
if (logger.isDebugEnabled()) {
logger.debug("Loaded NamespaceHandler mappings: " + mappings);
}
// 初始化内存缓存
handlerMappings = new ConcurrentHashMap<String, Object>(mappings.size());
// 将加载到的属性合并到handlerMappings中
CollectionUtils.mergePropertiesIntoMap(mappings, handlerMappings);
// 赋值内存缓存
this.handlerMappings = handlerMappings;
}catch (IOException ex) {
throw new IllegalStateException(
"Unable to load NamespaceHandler mappings from location [" + this.handlerMappingsLocation + "]", ex);
}
}
}
}
return handlerMappings;
}
源码中this.handlerMappings是一个Map类型的内存缓存,存放解析到的namespaceUri以及NameSpaceHandler实例。
getHandlerMappings()方法体中的实现使用了线程安全方式,增加了同步逻辑。
通过阅读源码可以了解到Spring基于spring.handlers实现SPI逻辑相对比较简单,但应用却比较灵活,对自定义标签的支持很方便,在不修改Spring源码的前提下轻松实现接入,如Dubbo中定义的各种Dubbo标签便是很好的利用了spring.handlers。
Spring提供如此灵活的功能,那是如何应用的呢?下面简单了解下parseCustomElement()。
- BeanDefinitionParserDelegate.parseCustomElement()
resolve作为工具类型的方法,被使用的地方比较多,这里仅简单介绍在BeanDefinitionParserDelegate.parseCustomElement()中的应用。
BeanDefinitionParserDelegate#parseCustomElement()
public BeanDefinition parseCustomElement(Element ele, BeanDefinition containingBd) {
// 获取标签的namespaceUri
String namespaceUri = getNamespaceURI(ele);
// 首先获得DefaultNamespaceHandlerResolver实例在再以namespaceUri作为参数调用resolve方法解析取得NamespaceHandler
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler == null) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
return null;
}
// 调用NamespaceHandler中的parse方法开始解析标签
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}
parseCustomElement作为解析标签的中间方法,再看下parseCustomElement的调用情况:

在parseBeanDefinitions()中被调用,再看下parseBeanDefinitions的源码
DefaultBeanDefinitionDocumentReader#parseBeanDefinitions()
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
// spring内部定义的标签为默认标签,即非spring内部定义的标签都不是默认的namespace
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
// root子标签也做此判断
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}else{
// 子标签非spring默认标签(即自定义标签)也走parseCustomElement来解析
delegate.parseCustomElement(ele);
}
}
}
}else {
// 非spring的默认标签(即自定义的标签)走parseCustomElement来解析
delegate.parseCustomElement(root);
}
}
到此就很清晰了,调用前判断是否为Spring默认标签,不是默认标签调用parseCustomElement来解析,最后调用resolve方法。
4.2.3 小节Spring自2.0引入spring.handlers以后,为Spring的动态扩展提供更多的入口和手段,为自定义标签的实现提供了强力支撑。
很多文章在介绍Spring SPI时都重点介绍spring.factories实现,很少提及很早就引入的spring.handlers,但通过个人的分析及与Java SPI的对比,spring.handlers也是一种SPI的实现,只是基于xml实现。
相比于Java SPI,基于spring.handlers实现的SPI更加的灵活,无需遍历,直接映射,更类似于Dubbo SPI的实现思想,每个类指定一个名称(只是spring.handlers中是以namespaceUri作为key,Dubbo配置中是指定的名称作为key)。
4.3 spring.factories同样先以测试代码来介绍spring.factories实现SPI的逻辑。
4.3.1 spring.factories SPI① 创建DataBaseSPI接口
接口
package spring.spi.factories;
public interface DataBaseSPI {
public void dataBaseOperation();
}
② 创建DataBaseSPI接口的实现类
MysqlDataBaseImpl
#实现类1
package spring.spi.factories.impl;
import spring.spi.factories.DataBaseSPI;
public class MysqlDataBaseImpl implements DataBaseSPI {
@Override
public void dataBaseOperation() {
System.out.println("Mysql database test!!!!");
}
}
MysqlDataBaseImpl
#实现类2
package spring.spi.factories.impl;
import spring.spi.factories.DataBaseSPI;
public class OracleDataBaseImpl implements DataBaseSPI {
@Override
public void dataBaseOperation() {
System.out.println("Oracle database test!!!!");
}
}
③ 在项目META-INF/目录下创建spring.factories文件:
文件内容
spring.factories
#key是接口的全限定名,value是接口的实现类
spring.spi.factories.DataBaseSPI = spring.spi.factories.impl.MysqlDataBaseImpl,spring.spi.factories.impl.OracleDataBaseImpl
④ 运行代码
SpringSpiTest#main()
package spring.spi.factories;
import java.util.List;
import org.springframework.core.io.support.SpringFactoriesLoader;
public class SpringSpiTest {
public static void main(String args[]){
// 调用SpringFactoriesLoader.loadFactories方法加载DataBaseSPI接口所有实现类的实例
List<DataBaseSPI> spis= SpringFactoriesLoader.loadFactories(DataBaseSPI.class, Thread.currentThread().getContextClassLoader());
// 遍历DataBaseSPI接口实现类实例
for(DataBaseSPI spi : spis){
spi.dataBaseOperation();
}
}
}
⑤ 运行结果
Mysql database test!!!!
Oracle database test!!!!
从上述的示例代码中可以看出spring.facotries方式实现的SPI和Java SPI很相似,都是先获取指定接口类型的实现类,然后遍历访问所有的实现。但也存在一定的差异:
(1)配置上:
Java SPI是一个服务提供接口对应一个配置文件,配置文件中存放当前接口的所有实现类,多个服务提供接口对应多个配置文件,所有配置都在services目录下;
Spring factories SPI是一个spring.factories配置文件存放多个接口及对应的实现类,以接口全限定名作为key,实现类作为value来配置,多个实现类用逗号隔开,仅spring.factories一个配置文件。
(2)实现上
Java SPI使用了懒加载模式,即在调用ServiceLoader.load()时仅是返回了ServiceLoader实例,尚未解析接口对应的配置文件,在使用时即循环遍历时才正式解析返回服务提供接口的实现类实例;
Spring factories SPI在调用SpringFactoriesLoader.loadFactories()时便已解析spring.facotries文件返回接口实现类的实例(实现细节在源码分析中详解)。
4.3.2 源码分析我们还是从测试代码开始,了解下spring.factories的SPI实现源码,细品spring.factories的实现方式。
- SpringFactoriesLoader测试代码入口直接调用SpringFactoriesLoader.loadFactories()静态方法开始解析spring.factories文件,并返回方法参数中指定的接口类型,如测试代码里的DataBaseSPI接口的实现类实例。
SpringFactoriesLoader#loadFactories()
public static <T> List<T> loadFactories(Class<T> factoryClass, ClassLoader classLoader) {
Assert.notNull(factoryClass, "'factoryClass' must not be null");
ClassLoader classLoaderToUse = classLoader;
// 1.确定类加载器
if (classLoaderToUse == null) {
classLoaderToUse = SpringFactoriesLoader.class.getClassLoader();
}
// 2.核心逻辑之一:解析各jar包中META-INF/spring.factories文件中factoryClass的实现类全限定名
List<String> factoryNames = loadFactoryNames(factoryClass, classLoaderToUse);
if (logger.isTraceEnabled()) {
logger.trace("Loaded [" + factoryClass.getName() + "] names: " + factoryNames);
}
List<T> result = new ArrayList<T>(factoryNames.size());
// 3.遍历实现类的全限定名并进行实例化
for (String factoryName : factoryNames) {
result.add(instantiateFactory(factoryName, factoryClass, classLoaderToUse));
}
// 排序
AnnotationAwareOrderComparator.sort(result);
// 4.返回实例化后的结果集
return result;
}
源码中loadFactoryNames() 是另外一个比较核心的方法,解析spring.factories文件中指定接口的实现类的全限定名,实现逻辑见后续的源码。
经过源码中第2步解析得到实现类的全限定名后,在第3步通过instantiateFactory()方法逐个实例化实现类。
再看loadFactoryNames()源码是如何解析得到实现类全限定名的:
SpringFactoriesLoader#loadFactoryNames()
public static List<String> loadFactoryNames(Class<?> factoryClass, ClassLoader classLoader) {
// 1.接口全限定名
String factoryClassName = factoryClass.getName();
try {
// 2.加载META-INF/spring.factories文件路径(分布在各个不同jar包里,所以这里会是多个文件路径,枚举返回)
Enumeration<URL> urls = (classLoader != null ? classLoader.getResources(FACTORIES_RESOURCE_LOCATION) :
ClassLoader.getSystemResources(FACTORIES_RESOURCE_LOCATION));
List<String> result = new ArrayList<String>();
// 3.遍历枚举集合,逐个解析spring.factories文件
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
Properties properties = PropertiesLoaderUtils.loadProperties(new UrlResource(url));
String propertyValue = properties.getProperty(factoryClassName);
// 4.spring.factories文件中一个接口的实现类有多个时会用逗号隔开,这里拆开获取实现类全限定名
for (String factoryName : StringUtils.commaDelimitedListToStringArray(propertyValue)) {
result.add(factoryName.trim());
}
}
return result;
}catch (IOException ex) {
throw new IllegalArgumentException("Unable to load factories from location [" +
FACTORIES_RESOURCE_LOCATION + "]", ex);
}
}
源码中第2步获取所有jar包中META-INF/spring.factories文件路径,以枚举值返回。
源码中第3步开始遍历spring.factories文件路径,逐个加载解析,整合factoryClass类型的实现类名称。
获取到实现类的全限定名集合后,便根据实现类的名称逐个实例化,继续看下instantiateFactory()方法的源码:
SpringFactoriesLoader#instantiateFactory()
private static <T> T instantiateFactory(String instanceClassName, Class<T> factoryClass, ClassLoader classLoader) {
try {
// 1.使用classLoader类加载器加载instanceClassName类
Class<?> instanceClass = ClassUtils.forName(instanceClassName, classLoader);
if (!factoryClass.isAssignableFrom(instanceClass)) {
throw new IllegalArgumentException(
"Class [" + instanceClassName + "] is not assignable to [" + factoryClass.getName() + "]");
}
// 2.instanceClassName类中的构造方法
Constructor<?> constructor = instanceClass.getDeclaredConstructor();
ReflectionUtils.makeAccessible(constructor);
// 3.实例化
return (T) constructor.newInstance();
}
catch (Throwable ex) {
throw new IllegalArgumentException("Unable to instantiate factory class: " + factoryClass.getName(), ex);
}
}
实例化方法是私有型(private)静态方法,这个有别于loadFactories和loadFactoryNames。
实例化逻辑整体使用了反射实现,比较通用的实现方式。
通过对源码的分析,Spring factories方式实现的SPI逻辑不是很复杂,整体上的实现容易理解。
Spring在3.2便已引入spring.factories,那spring.factories在Spring框架中又是如何使用的呢?先看下loadFactories方法的调用情况:
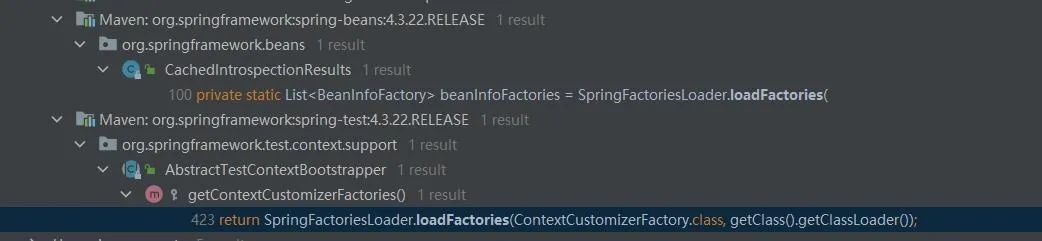
从调用情况看Spring自3.2引入spring.factories SPI后并没有真正的利用起来,使用的地方比较少,然而真正把spring.factories发扬光大的,是在Spring Boot中, 简单了解下SpringBoot中的调用。
- getSpringFactoriesInstances()getSpringFactoriesInstances()并不是Spring框架中的方法,而是SpringBoot中SpringApplication类里定义的私有型(private)方法,很多地方都有调用,源码如下:
SpringApplication#getSpringFactoriesInstance()
// 单个参数getSpringFactoriesInstances方法
private <T> Collection<T> getSpringFactoriesInstances(Class<T> type) {
// 默认调用多参的重载方法
return getSpringFactoriesInstances(type, new Class<?>[] {});
}
// 多个参数的getSpringFactoriesInstances方法
private <T> Collection<T> getSpringFactoriesInstances(Class<T> type,
Class<?>[] parameterTypes, Object... args) {
ClassLoader classLoader = getClassLoader();
// 调用SpringFactoriesLoader中的loadFactoryNames方法加载接口实现类的全限定名
Set<String> names = new LinkedHashSet<>(
SpringFactoriesLoader.loadFactoryNames(type, classLoader));
// 实例化
List<T> instances = createSpringFactoriesInstances(type, parameterTypes,
classLoader, args, names);
AnnotationAwareOrderComparator.sort(instances);
return instances;
}
在getSpringFactoriesInstances()中调用了SpringFactoriesLoader.loadFactoryNames()来加载接口实现类的全限定名集合,然后进行初始化。
SpringBoot中除了getSpringFactoriesInstances()方法有调用,在其他逻辑中也广泛运用着SpringFactoriesLoader中的方法来实现动态扩展,这里就不在一一列举了,有兴趣的同学可以自己去发掘。
4.3.3 小节Spring框架在3.2引入spring.factories后并没有有效的利用起来,但给框架的使用者提供了又一个动态扩展的能力和入口,为开发人员提供了很大的自由发挥的空间,尤其是在SpringBoot中广泛运用就足以证明spring.factories的地位。spring.factories引入在 提升Spring框架能力的同时也暴露出其中的不足:
五、应用实践首先,spring.factories的实现类似Java SPI,在加载到服务提供接口的实现类后需要循环遍历才能访问,不是很方便。
其次,Spring在5.0.x版本以前SpringFactoriesLoader类定义为抽象类,但在5.1.0版本之后Sping官方将SpringFactoriesLoader改为final类,类型变化对前后版本的兼容不友好。
介绍完Spring中SPI机制相关的核心源码,再来看看项目中自己开发的轻量版的分库分表SDK是如何利用Spring的SPI机制实现分库分表策略动态扩展的。
基于项目的特殊性并没有使用目前行业中成熟的分库分表组件,而是基于Mybatis的插件原理自己开发的一套轻量版分库分表组件。为满足不同场景分库分表要求,将其中分库分表的相关逻辑以策略模式进行抽取分离,每种分库分表的实现对应一条策略,支持使用方对分库分表策略的动态扩展,而这里的动态扩展就利用了spring.factories。
首先给出轻量版分库分表组件流程图,然后我们针对流程图中使用到Spring SPI的地方进行详细分析。
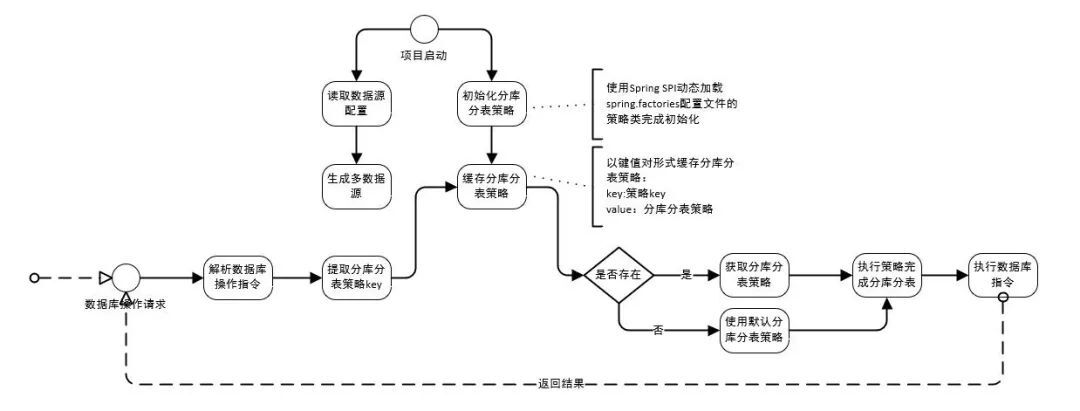
说明:
- 上述流程图中项目启动过程中生成数据源和分库分表策略的初始化,策略初始化完成后缓存到内存中。
- 发起数据库操作指令时,解析是否需要分库分表(流程中只给出了需要分库分表的流程),需要则通过提取到的策略key获取对应的分库分表策略并进行分库分表,完成数据库操作。
通过上述的流程图可以看到,分库分表SDK通过spring.factories支持动态加载分库分表策略以兼容不同项目的不同使用场景。
其中分库分表部分的策略类图:
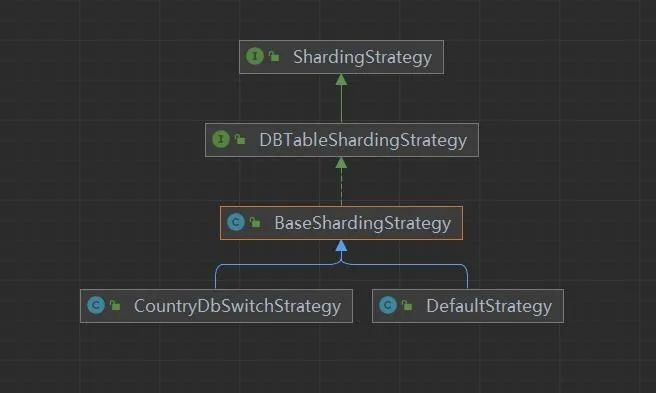
其中:ShardingStrategy和DBTableShardingStrategy为接口;BaseShardingStrategy为默认实现类;DefaultStrategy和CountryDbSwitchStrategy为SDK中基于不同场景默认实现的分库分表策略。
在项目实际使用时,动态扩展的分库分表策略只需要继承BaseShardingStrategy即可,SDK中初始化分库分表策略时通过SpringFactoriesLoader.loadFactories()实现动态加载。
六、总结SPI技术将服务接口与服务实现分离以达到解耦,极大的提升程序的可扩展性。
本文重点介绍了Java内置SPI和Dubbo SPI以及Spring SPI三者的原理和相关源码;首先演示了三种SPI技术的实现,然后通过演示代码深入阅读了三种SPI的实现源码;其中重点介绍了Spring SPI的两种实现方式:spring.handlers和spring.factories,以及使用spring.factories实现的分库分表策略加载。希望通过阅读本文可以让读者对SPI有更深入的了解。
分享 vivo 互联网技术干货与沙龙活动,推荐最新行业动态与热门会议。