说到Barrier,很多语言中已经是标准库中自带的概念,一般情况下,只需要直接使用就行了。而最近一些机缘巧合的机会,我需要在c++中使用这么个玩意儿。但是c++标准库里还没有这个概念,只有boost里面有这样现成的东西,而我又不想为了这么一个小东西引入个boost。所以,我借着这个机会研究了下,发现其实这些多线程/并发中的东西还是蛮有意思的。
阅读本文你可能需要如下的一些知识:
- 多线程编程的概念。
- c++的基本语法和有关多线程的语法。
第二条可能也没有那么重要,因为如果理解了多线程的这些东西,什么语言都可以实现其核心概念。好了,废话少扯,进入正题。
一、什么是Barrier?
首先,得介绍下Barrier的概念,Barrier从字面理解是屏障的意思,主要是用作集合线程,然后再一起往下执行。再具体一点,在Barrier之前,若干个thread各自执行,然后到了Barrier的时候停下,等待规定数目的所有的其他线程到达这个Barrier,之后再一起通过这个Barrier各自干自己的事情。
这个概念特别像小时候集体活动的过程,大家从各自的家里到学校集合,待人数都到齐之后,之后再一起坐车出去,到达指定地点后一起行动或者各自行动。
而在计算机的世界里,Barrier可以解决的问题很多,比如,一个程序有若干个线程并发的从网站上下载一个大型xml文件,这个过程可以相互独立,因为一个文件的各个部分并不相关。而在处理这个文件的时候,可能需要一个完整的文件,所以,需要有一条虚拟的线让这些并发的部分集合一下从而可以拼接成为一个完整的文件,可能是为了后续处理也可能是为了计算hash值来验证文件的完整性。而后,再交由下一步处理。
二、如何实现一个Barrier?
并发的很多东西都拥有一个坏处就是你很难证明某种实现不是错误的,因为很多时候确实情况太多了,无论是死锁,饥饿对于人脑都是太大的负担。而反过来,对于我扯这篇文章,也是一个好处,正因为很难证明不是错误的,所以我的扯淡可以更放心一点。
在研究Barrier的实现中,我查阅了蛮多的资料的。说实话,其实现方式挺多的。在剔除了一些我能明确证明其有可能是错误的,我选择了我自己觉得最容易理解的一种。
第一节说过,barrier很像是以前的班级集合,站在一个老师的角度,你需要知道的东西至少有这两个:
- 班级有多少人。
- 目前已经到了多少人。
只有当目前已经到了的人等于班级人数之后才能出发。
所以如果按照这个类比,实现一个barrier至少需要以下的几个变量:
- 需要同时在barrier等待的线程的个数。
- 当前到达barrier的线程的个数。
而按照barrier的逻辑,主要应该有这些操作:
- 当一个线程到达barrier的时候,增加计数。
- 如果个数不等于当前需要等待的线程个数,等待。
- 如果个数达到了需要等待的线程个数,通知/唤醒所有等待的进程,让所有进程通过barrier。
在不考虑加锁的情况下,按照上面的逻辑,伪代码大概应该像这样:
thread_count = n; <-- n是需要一起等待的线程的个数 arrived_count = 0; <-- 到达线程的个数 ------------------------------------------------------------- 以上是全局变量,只会初始化一次,以下是barrier开始的代码 ------------------------------------------------------------- arrived_count += 1; if(arrived_count == thread_count) notify_all_threads_and_unblok(); else block_and_wait();
而在多线程环境下,很明显arrived_count这种全局变量更新需要加锁。所以,对于这个代码,综合稍微再改动一下,伪代码可以更新下成为这样:
thread_count = n; <-- n是需要一起等待的线程的个数 arrived_count = 0; <-- 到达线程的个数 ------------------------------------------------------------- 以上是全局变量,只会初始化一次,以下是barrier开始的代码 ------------------------------------------------------------- lock(); arrived_count += 1; unlock(); if(arrived_count == thread_count) notify_all_threads_and_unblok(); else block_and_wait();
这里,在有的语言中,锁的粒度可能小了点,取决于notify_all_threads和wait在这个语言中的定义,但是作为伪代码,为了可能展示起来比较方便。
而如果你有并发编程的知识,你应该敏感的认识到notify_all_threads_and_unblock,block_and_wait这种在这里虽然是简单的几个单词,但是其包含的操作步骤明显不止一个,更别说背后的机器指令了。所以作为一个并发概念下运行的程序,不可以简单的就放这样一个操作在这里,如果都是任何函数,指令,代码都是自带原子性的,那么写多线程/并发程序也没有啥好研究的了。所以对于这两个操作,我们必须具体的扩展下。
对于notify_all_threads_and_unblock和block_and_wait包含相当多的操作,所以下面,得把这两个操作具体的展开。
thread_count = n; <-- n是需要一起等待的线程的个数 arrived_count = 0; <-- 到达线程的个数 could_release = false; ------------------------------------------------------------- 以上是全局变量,只会初始化一次,以下是barrier开始的代码 ------------------------------------------------------------- lock(); if(arrived_count == 0) could_release = false; arrived_count += 1; unlock(); if(arrived_count == thread_count) could_realse = true; arrived_count = 0; else while(could_release == false) spin()
这里多了一个变量could_release完成上面说的两个操作。原理也很简单,如果等待的个数没有到达指定数目,这个值始终是false,在代码中使用循环让线程阻塞在spin处(当然,假设spin是原子性的)。如果到达了thread_count,改变could_release的值,这样循环条件不满足,代码可以继续执行。而在13行的if里面把arrived_count重新设置为0是因为如果不这样做,那么这个barrier就只能用一次,因为没有地方再把这个表示到达线程数目变量的初始值重新设置了。
我觉得这里需要停一下,来思一下上面的代码,首先,这个代码有很多看起来很像有问题的地方。比如对于could_release和arrived_count的重置处,这都是赋值,而在并发程序中,任何写操作都需要仔细思考是否需要加锁,在这里,加锁当然没问题。但是盲目的加锁会导致性能损失。
多线程程序最可怕的就是陷入细节,所以,我一般都是整体的思考下是不是有问题。对于一个barrier,错误就是指没有等所有的线程都到达了就停止了等待,人没来齐就发车了。而怎么会导致这样的情况呢?只有当arrived_count值在两个线程不同步才会导致错误。秉承这个原则,看看上面的代码,arrived_count的更新是加锁的,所以在到达if之前其值是可以信赖的。而if这段判断本身是读操作,其判断就是可以信赖的,因为arrived_count的值更新是可靠的,所以进来的线程要么进入if,要么进入else。不存在线程1更新了arrived_count的值而线程2读到了arrived_count的值而导致没有到thread_count就更新了could_release的情况。
没办法,这类的程序就是很绕,所以我一般都不陷入细节。
现在看起来,一切都很完美,但是多线程程序最恶心的地方就是可能的死锁,饥饿等等。而这些又很难证明,而上面这段代码,在某些情况下就是会导致死锁。考虑thread_count等于2,也就是这个barrier需要等待两个线程一起通过。
现在有两个线程,t1和t2,t1先执行直到17行,卡住,这时候t2获得宝贵的cpu机会。很明显,这时会进入14行,更新could_release的值。如果这个时候t1获得执行机会,万事大吉,t1会离开while区域,继续执行。直到下次再次到达这个barrier。
但是如果这个时候t1并没有获得执行机会,t2一直执行,虽然唤醒了could_relase,但是t1会一直停留在18行。要知道,这个含有barrier的代码可能是在一个循环之中,如果t2再次到达barrier的区域,这时候arrived_count等于0(因为arrived_count在上一次t2进入13行之后重置了),这个时候could_relase会变成false。现在t1,t2都在18行了,没有人有机会去更新could_relase的值,线程死锁了。
怎么办?仔细思考下,是唤醒机制有问题,很明显,如果能够在唤醒的时候原子式的唤醒所有的线程,那么上面所说的问题就不存在了。在很多语言里都有这样的方法可以完成上面说的原子性的唤醒所有线程,比如c++里面的notify_all。但是,如果没有这个函数,该如何实现呢?
上面死锁问题的诞生在于一个线程不恰当的更新了全局的could_relase,导致全部的判断条件跟着错误的改变。解决这样的问题,需要的是一个只有每个线程各自能看到,可以独立更新,互相不干扰而又能被使用的变量。幸好,在设计多线程概念时,有一个概念叫做thread local,刚好能够满足这个要求。而运用这样的变量,上述的概念可以表述成为:
thread_count = n; <-- n是需要一起等待的线程的个数 arrived_count = 0; <-- 到达线程的个数 could_release = false; thread_local_flag = could_release; <-- 线程局部变量,每个线程独立更新 ------------------------------------------------------------- 以上是全局变量,只会初始化一次,以下是barrier开始的代码 ------------------------------------------------------------- thread_local_flag = !thread_local_flag lock(); arrived_count += 1; unlock(); if(arrived_count == thread_count) could_realse = thread_local_flag; arrived_count = 0; else while(could_release != thread_local_flag) spin()
这里要着重解释下,为什么不会死锁,由于thread_local_flag是每个线程独立更新的,所以很明显,其是不用加锁的。其余代码和上面的伪代码类似,不同的是,如果发生上面一样的情况,t2更新thread_local_flag的时候,只有其局部的变量会被置反而不会影响其余的线程的变量,而因为could_realse是全局变量,在t2第一次执行到13行的时候已经设置成thread_local_flag一样的值了。这个时候,哪怕t2再次执行到16行也会因为其内部变量已经被置反而阻塞在这个while循环之中。而t1只要获得执行机会,就可以通过这个barrier。
有点绕,但是仔细想想还是蛮有意思的。
三、如何运用c++实现Barrier?
虽然上面说了那么多,但是c++中实现Barrier不需要这么复杂,这要感谢c++ 11中已经自带了很多原子性的操作,比如上面说的notify_all。所以,代码就没有那么复杂了,当然,c++也有thread_local,如果不畏劳苦,可以真的从最基础的写起。
#include <iostream>
#include <condition_variable>
#include <thread>
#include <chrono>
using namespace std;
class TestBarrier{
public:
TestBarrier(int nThreadCount):
m_threadCount(nThreadCount),
m_count(0),
m_release(0)
{}
void wait1(){
unique_lock<mutex> lk(m_lock);
if(m_count == 0){
m_release = 0;
}
m_count++;
if(m_count == m_threadCount){
m_count = 0;
m_release = 1;
m_cv.notify_all();
}
else{
m_cv.wait(lk, [&]{return m_release == 1;});
}
}
private:
mutex m_lock;
condition_variable m_cv;
unsigned int m_threadCount;
unsigned int m_count;
unsigned int m_release;
};
这里多亏了c++标准库中引进的condition_variable,使得上面的概念可以简单高效而又放心的实现,你也不需要操心什么线程局部量。而关于c++并发相关的种种知识可能需要专门的若干篇幅才能说清楚,如果你并不熟悉c++,可以跳过这些不知所云的部分。验证上述代码可以使用如下代码:
unsigned int threadWaiting = 5;
TestBarrier barrier(5);
void func1(){
this_thread::sleep_for(chrono::seconds(3));
cout<<"func1"<<endl;
barrier.wait1();
cout<<"func1 has awakended!"<<endl;
}
void func2(){
cout<<"func2"<<endl;
barrier.wait1();
cout<<"func2 has awakended!"<<endl;
}
void func3(){
this_thread::sleep_for(chrono::seconds(1));
cout<<"func3"<<endl;
barrier.wait1();
cout<<"func3 has awakended!"<<endl;
}
int main(){
for(int i = 0; i < 5; i++){
thread t1(func1);
thread t2(func3);
thread t3(func2);
thread t4(func3);
thread t5(func2);
t1.join();
t2.join();
t3.join();
t4.join();
t5.join();
}
}
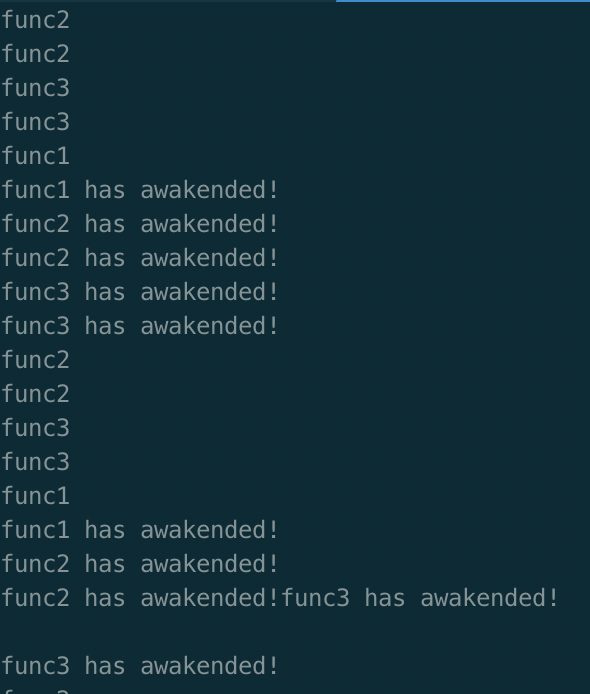
好了,在我机器上的运行结果是这样的,由于输出没有同步,所以输出可能并没有想象的那么整洁。但是不影响整体结果,可以看到,所有线程到齐之后才各自执行各自后面的代码:
到此这篇关于浅谈c++如何实现并发中的Barrier的文章就介绍到这了,更多相关c++实现并发中的Barrier内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!