对于回归而言,有线性模型和非线性模型两大模型,从名字中的线性和非线性也可以直观的看出其对应的使用场景,但是在实际分析中,线性模型作为最简单直观的模型,是我们分析的首选模型,无论数据是否符合线性,肯定都会第一时间使用线性模型来拟合看看效果。
当实际数据并不符合线性关系时,就会看到普通的线性回归算法,其拟合结果并不好,比如以下两个拟合结果
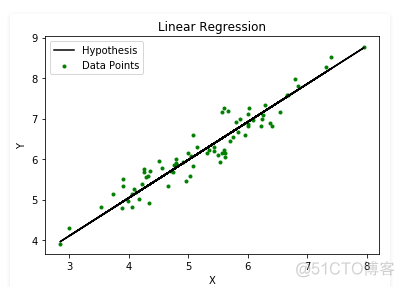
线性数据:
非线性数据:
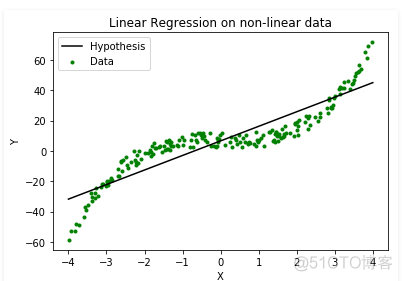
同样应用线性回归模型,可以看到数据本身非线性的情况下,普通线性拟合的效果非常差。对于这样的情况,我们有两种选择
1. 第一种,多项式展开,在自变量x1,x2等的基础上构建新的自变量组合,比如x1的平方,x2的平方,x1*x2等选项;
2. 第二种,局部加权线性回归
局部加权线性回归,英文为local wighted linear regression, 简称为LWLR。从名字可以看出,该方法有两个关键点,局部和加权。
局部表示拟合的时候不是使用所有的点来进行拟合,而是只使用部分样本点;加权,是实现局部的方式,在每个样本之前乘以一个系数,该系数为非负数,也就是权重值,权重值的大小与样本间的距离成正比,在其他参数相同的情况下,距离越远的样本,其权重值越小,当权重值为0时,该样本就不会纳入回归模型中,此时就实现了局部的含义。
在该方法中,首先需要计算样本的权重,通常使用如下公式来计算权重
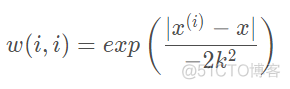
该函数称之为高斯核函数,注意这里的竖线是向量表示法,表示范数,即两个向量的欧式距离。在该核函数中,包含了一个超参数k, 称为波长参数,这个参数的取值范围为0-1,是需要我们自己调整和设定的。依次遍历每一个样本,计算其他样本相对该样本的权重。
计算完权重之后,还是采用了最小二乘法的思维,最小化误差平方和来求解线性方程,损失函数如下
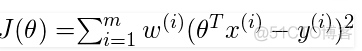
和普通最小二乘法相比,就是多了样本的权重矩阵。对于该损失函数,其回归系数的解的值为
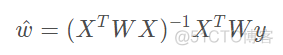
局部加权回归,属于一种非参数的学习方法,非参数的意思就是说回归方程的参数不是固定的。普通的最小二乘法求解出的回归方程,参数是固定的,就是ax + b这样的格式,a和b的值是不变的,对于数据点,只需要带入这个方程,就可以求解出预测值。对于非参数而言,其参数不固定,对于新的数据点而言,一定要再次重新训练模型,才可以求解出结果。
同时,相比普通的线性回归,局部加权回归的计算量也是非常大,需要对每一个样本进行遍历,计算样本权重矩阵,并求解回归系数,再拟合新的预测值,样本越多,计算量越大。
在scikit-learn中,并没有内置该方法,我们可以自己写代码来实现。示例数据的分布如下
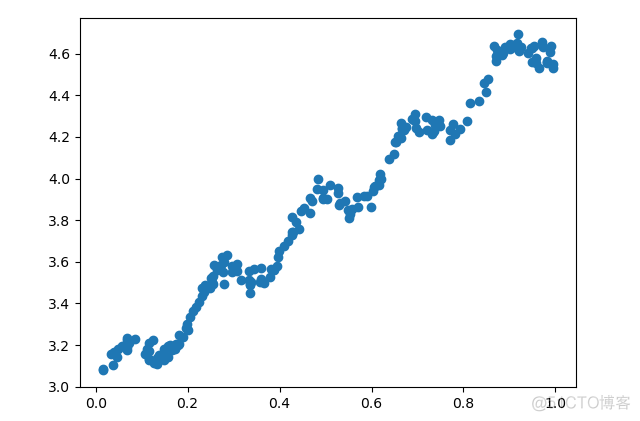
可以看到,并不是一个典型的线性关系。对于局部加权回归而言,其算法的核心代码如下
>>> import numpy as np>>> def lwlr(testPoint, xArr, yArr, k=1.0):
... xMat = np.mat(xArr); yMat = np.mat(yArr).T
... m = np.shape(xMat)[0]
... weights = np.mat(np.eye((m)))
... for j in range(m):
... diffMat = testPoint - xMat[j, :]
... weights[j, j] = np.exp(diffMat * diffMat.T / (-2.0 * k ** 2))
... xTx = xMat.T * (weights * xMat)
... if linalg.det(xTx) == 0.0:
... print("行列式为0,奇异矩阵,不能做逆")
... return
... ws = xTx.I * (xMat.T * (weights * yMat))
... return testPoint * ws
...
第一个参数为待处理的样本的输入矩阵,第二个参数为所有样本的输入矩阵,第三个参数为观测到的输出矩阵,第四个参数为超参数k。该代码针对1个样本进行计算,首先计算样本的权重矩阵,然后通过回归系数的求解公式求解出对应的系数,将样本的原始值乘以该系数,就得到了拟合之后的数值。
在该代码的基础上,通过for循环变量所有样本,就可以得到完整的拟合结果,代码如下
>>> def lwlrTest(testArr, xArr, yArr, k=1.0):... m = np.shape(testArr)[0]
... yHat = np.zeros(m)
... for i in range(m):
... yHat[i] = lwlr(testArr[i], xArr, yArr, k)
... return yHat
...
比较一下k的不同取值对拟合结果的影响,代码如下
>>> yHat_k1 = lwlrTest(xArr, xArr, yArr, 1)>>> yHat_k2 = lwlrTest(xArr, xArr, yArr, 0.01)
>>> yHat_k3 = lwlrTest(xArr, xArr, yArr, 0.003)
>>> xMat = mat(xArr)
>>> srtInd = xMat[:, 1].argsort(0)
>>> xSort = xMat[srtInd][:, 0, :]
>>> fig, axes = plt.subplots(1, 3)
>>> axes[0].plot(xSort[:, 1], yHat_k1[srtInd], color='red')
[<matplotlib.lines.Line2D object at 0x00D8E0E8>]
>>> axes[0].scatter(xMat[:, 1].flatten().A[0], mat(yArr).T.flatten().A[0])
<matplotlib.collections.PathCollection object at 0x00D8E238>
>>> axes[0].set_title('k=1')
Text(0.5, 1.0, 'k=1')
>>> axes[1].plot(xSort[:, 1], yHat_k2[srtInd], color='red')
[<matplotlib.lines.Line2D object at 0x00D8E9A0>]
>>> axes[1].scatter(xMat[:, 1].flatten().A[0], mat(yArr).T.flatten().A[0])
<matplotlib.collections.PathCollection object at 0x00D8E0B8>
>>> axes[1].set_title('k=0.01')
Text(0.5, 1.0, 'k=0.01')
>>> axes[2].plot(xSort[:, 1], yHat_k3[srtInd], color='red')
[<matplotlib.lines.Line2D object at 0x00EA26E8>]
>>> axes[2].scatter(xMat[:, 1].flatten().A[0], mat(yArr).T.flatten().A[0])
<matplotlib.collections.PathCollection object at 0x00EA2790>
>>> axes[2].set_title('k=0.003')
Text(0.5, 1.0, 'k=0.003')
>>> plt.show()
输出结果如下
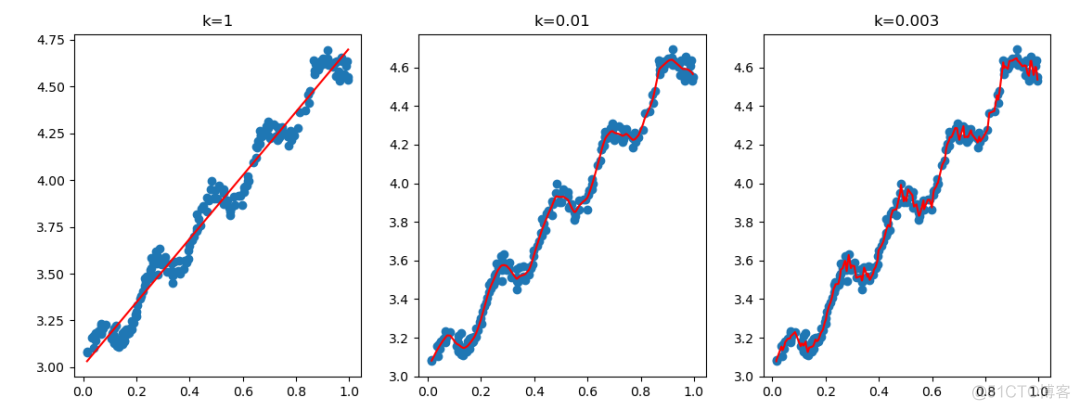
可以看到,K=1时,就是一个整体的普通线性回归;当k=0.01是拟合效果很好,当k=0.003时,拟合结果非常复杂,出现了过拟合的现象。
对于非线性数据,使用局部加权回归是一个不错的选择,比如在NIPT的数据分析中,就有文献使用该方法对原始的测序深度数值进行校正,然后再来计算z-score。
·end·

一个只分享干货的
生信公众号