
【相关推荐:javascript视频教程、web前端】
写js也有两年多了,一直对它的运行机制和原理不是很了解,今天特意把大神们的理论和自己的总结都记录到下面:
什么是JavaScript解析引擎
简单地说,JavaScript解析引擎就是能够“读懂”JavaScript代码,并准确地给出代码运行结果的一段程序。
比方说,当你写了 var a = 1 + 1; 这样一段代码,JavaScript引擎做的事情就是看懂(解析)你这段代码,并且将a的值变为2。
学过编译原理的人知道,对于静态语言来说(如Java、C++、C),处理上述这些事情的叫编译器(Compiler),相应地对于JavaScript这样的动态语言则叫解释器(Interpreter)。这两者的区别用一句话来概括就是:编译器是将源代码编译为另外一种代码(比如机器码,或者字节码),而解释器是直接解析并将代码运行结果输出。 比方说,firebug的console就是一个JavaScript的解释器。
但是,现在很难去界定说,JavaScript引擎它到底算是个解释器还是个编译器,因为,比如像V8(Chrome的JS引擎),它其实为了提高JS的运行性能,在运行之前会先将JS编译为本地的机器码(native machine code),然后再去执行机器码(这样速度就快很多)。
JavaScript解析引擎与ECMAScript是什么关系
JavaScript引擎是一段程序,我们写的JavaScript代码也是程序,如何让程序去读懂程序呢?这就需要定义规则。比如,之前提到的var a = 1 + 1;,它表示:
左边var代表了这是申明(declaration),它声明了a这个变量
右边的+表示要将1和1做加法
中间的等号表示了这是个赋值语句
最后的分号表示这句语句结束了
上述这些就是规则,有了它就等于有了衡量的标准,JavaScript引擎就可以根据这个标准去解析JavaScript代码了。那么这里的ECMAScript就是定义了这些规则。其中ECMAScript 262这份文档,就是对JavaScript这门语言定义了一整套完整的标准。其中包括:
var,if,else,break,continue等是JavaScript的关键词
abstract,int,long等是JavaScript保留词
怎么样算是数字、怎么样算是字符串等等
定义了操作符(+,-,>,<等)
定义了JavaScript的语法
定义了对表达式,语句等标准的处理算法,比如遇到==该如何处理
⋯⋯
标准的JavaScript引擎就会根据这套文档去实现,注意这里强调了标准,因为也有不按照标准来实现的,比如IE的JS引擎。这也是为什么JavaScript会有兼容性的问题。至于为什么IE的JS引擎不按照标准来实现,就要说到浏览器大战了,这里就不赘述了,自行Google之。
所以,简单的说,ECMAScript定义了语言的标准,JavaScript引擎根据它来实现,这就是两者的关系。
JavaScript解析引擎与浏览器是什么关系
简单地说,JavaScript引擎是浏览器的组成部分之一。因为浏览器还要做很多别的事情,比如解析页面、渲染页面、Cookie管理、历史记录等等。那么,既然是组成部分,因此一般情况下JavaScript引擎都是浏览器开发商自行开发的。比如:IE9的Chakra、Firefox的TraceMonkey、Chrome的V8等等。
从而也看出,不同浏览器都采用了不同的JavaScript引擎。因此,我们只能说要深入了解哪个JavaScript引擎。
为什么JavaScript是单线程
JavaScript语言的一大特点就是单线程,也就是说,同一个时间只能做一件事。那么,为什么JavaScript不能有多个线程呢?这样能提高效率啊。
JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
区分进程和线程
进程是cpu资源分配的最小单位,进程可以包含多个线程。 浏览器就是多进程的,每打开的一个浏览器窗口就是一个进程。
线程是cpu调度的最小单位,同一进程下的各个线程之间共享程序的内存空间。
可以把进程看做一个仓库,线程是可以运输的货车,每个仓库有属于自己的多辆货车为仓库服务(运货),每个仓库可以同时由多辆车同时拉货,但是每辆车同一时间只能干一件事,就是运输本次的货物。
核心点:
进程是 cpu 资源分配的最小单位(是能拥有资源和独立运行的最小单位)
线程是 cpu 调度的最小单位(线程是建立在进程的基础上的一次程序运行单位,一个进程中可以有多个线程)
不同进程之间也可以通信,不过代价较大。
浏览器是多进程的
理解了进程与线程了区别后,接下来对浏览器进行一定程度上的认识:(先看下简化理解)
浏览器是多进程的
浏览器之所以能够运行,是因为系统给它的进程分配了资源(cpu、内存)
简单点理解,每打开一个Tab页,就相当于创建了一个独立的浏览器进程。
以 Chrome 为例,它的多个标签页,然后可以在Chrome的任务管理器中看到有多个进程(分别是每一个 Tab 页面有一个独立的进程,以及一个主进程),在 Windows 的任务管理器中也可以看出。
注意:在这里浏览器应该也有自己的优化机制,有时候打开多个tab页后,可以在Chrome任务管理器中看到,有些进程被合并了 (所以每一个Tab标签对应一个进程并不一定是绝对的)
浏览器都包含哪些进程
知道了浏览器是多进程后,再来看看它到底包含哪些进程:(为了简化理解,仅列举主要进程)
(1)Browser 进程:浏览器的主进程(负责协调、主控),只有一个。作用:
- 负责浏览器界面显示,与用户交互。如前进,后退等
- 负责各个页面的管理,创建和销毁其他进程
- 将 Renderer 进程得到的内存中的 Bitmap,绘制到用户界面上
- 网络资源的管理,下载等
(2)第三方插件进程:每种类型的插件对应一个进程,仅当使用该插件时才创建
(3)GPU 进程:最多一个,用于 3D 绘制等
(4)浏览器渲染进程(浏览器内核,Renderer进程,内部是多线程的):默认每个 Tab 页面一个进程,互不影响。主要作用为:页面渲染,脚本执行,事件处理等
强化记忆:在浏览器中打开一个网页相当于新起了一个进程(进程内有自己的多线程)
当然,浏览器有时会将多个进程合并(譬如打开多个空白标签页后,会发现多个空白标签页被合并成了一个进程)
浏览器多进程的优势
相比于单进程浏览器,多进程有如下优点:
- 避免单个 page crash 影响整个浏览器
- 避免第三方插件 crash 影响整个浏览器
- 多进程充分利用多核优势
- 方便使用沙盒模型隔离插件等进程,提高浏览器稳定性
简单理解:
如果浏览器是单进程,那么某个 Tab 页崩溃了,就影响了整个浏览器,体验有多差;同理如果是单进程,插件崩溃了也会影响整个浏览器。
当然,内存等资源消耗也会更大,有点空间换时间的意思。再大的内存也不够 Chrome 吃的,内存泄漏问题现在已经改善了一些了,也仅仅是改善,还有就是会导致耗电增加。
浏览器内核(渲染进程)
重点来了,我们可以看到,上面提到了这么多的进程,那么,对于普通的前端操作来说,最终要的是什么呢?答案是渲染进程。
可以这样理解,页面的渲染,JS 的执行,事件的循环,都在这个进程内进行。接下来重点分析这个进程
请牢记,浏览器的渲染进程是多线程的(JS 引擎是单线程的)
那么接下来看看它都包含了哪些线程(列举一些主要常驻线程):
1、GUI 渲染线程
- 负责渲染浏览器界面,解析 HTML,CSS,构建 DOM 树和 RenderObject 树(简单理解为 CSS 形成的样式树,Flutter 核心之一),布局和绘制等。
- 当界面需要重绘(Repaint)或由于某种操作引发回流(reflow)时,该线程就会执行
- 注意,GUI 渲染线程与 JS 引擎线程是互斥的,当 JS 引擎执行时 GUI 线程会被挂起(冻结),GUI 更新会被保存在一个队列中 等到 JS 引擎空闲时 立即被执行。
2、JS 引擎线程
- 也称为 JS 内核,负责处理 Javascript 脚本程序。(例如 V8 引擎)
- JS 引擎线程负责解析 Javascript 脚本,运行代码。
- JS 引擎一直等待着任务队列中任务的到来,然后加以处理,一个 Tab 页(renderer 进程)中无论什么时候都只有一个 JS 线程在运行 JS 程序
- 同样注意,GUI 渲染线程与 JS 引擎线程是互斥的,所以如果 JS 执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞。
3、事件触发线程
- 归属于浏览器而不是 JS 引擎,用来控制事件循环(可以理解,JS 引擎自己都忙不过来,需要浏览器另开线程协助)
- 当 JS 引擎要执行代码块如 setTimeOut 时(也可来自浏览器内核的其他线程,如鼠标点击、Ajax 异步请求等),会将对应任务添加到事件线程中。并且会负责排序
- 当对应的事件符合触发条件被触发时,该线程会把事件添加到待处理队列的队尾,等待 JS 引擎的处理
- 注意,由于 JS 的单线程关系,所以这些待处理队列中的事件都得排队等待 JS 引擎处理(当 JS 引擎空闲时才会去执行)
- 这里可以简单理解为,它负责管理一堆事件和一个“事件队列”,只有在事件队列的任务 JS 引擎才会在空闲的时候去执行,而它要做的,就是负责当某个事件被触发时,把它加入到事件队列。例如鼠标单击。
4、定时触发器线程
- 传说中的 setInterval 与 setTimeout 所在的线程
- 浏览器定时计数器并不是由 JavaScript 引擎计数的,(因为 JavaScript 引擎是单线程的,如果处于阻塞线程状态就会影响记计时的准确)
- 因此通过单独线程来计时并触发定时,计时完毕后,添加到事件队列中(对应 事件触发线程 的“事件符合触发条件被触发时”),等待 JS 引擎空闲后执行。
- 注意,W3C 在 HTML 标准中规定,规定要求 setTimeout 中低于 4ms 的时间间隔算为 4ms。
5、异步http请求线程
- 在 XMLHttpRequest 在连接后是通过浏览器新开一个线程请求
- 将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将这个回调再放入事件队列中。再由 JavaScript 引擎执行。
Browser进程和浏览器内核(Renderer进程)的通信过程
看到这里,首先,应该对浏览器内的进程和线程都有一定理解了,那么接下来,再谈谈浏览器的 Browser 进程(控制进程)是如何和内核通信的, 这点也理解后,就可以将这部分的知识串联起来,从头到尾有一个完整的概念。
如果自己打开任务管理器,然后打开一个浏览器,就可以看到:任务管理器中出现了两个进程(一个是主控进程,一个则是打开 Tab 页的渲染进程), 然后在这前提下,看下整个的过程:(简化了很多)
- Browser 进程收到用户请求,首先需要获取页面内容(譬如通过网络下载资源),随后将该任务通过 RendererHost 接口传递给 Render (内核)进程
- Renderer 进程的 Renderer 接口收到消息,简单解释后,交给渲染线程,然后开始渲染
- 渲染线程接收请求,加载网页并渲染网页,这其中可能需要 Browser 进程获取资源和需要 GPU 进程来帮助渲染
- 当然可能会有 JS 线程操作 DOM(这样可能会造成回流并重绘)
- 最后 Render 进程将结果传递给 Browser 进程
- Browser 进程接收到结果并将结果绘制出来
这里绘一张简单的图:(很简化)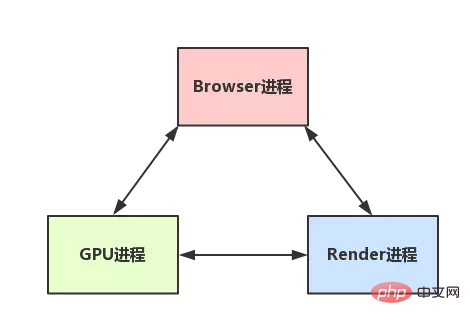
浏览器内核中线程之间的关系
到了这里,已经对浏览器的运行有了一个整体的概念,接下来,先简单梳理一些概念
GUI 渲染线程与 JS 引擎线程互斥
由于 JavaScript 是可操纵 DOM 的,如果在修改这些元素属性同时渲染界面(即 JS 线程和 UI 线程同时运行),那么渲染线程前后获得的元素数据就可能不一致了。
因此为了防止渲染出现不可预期的结果,浏览器设置 GUI 渲染线程与 JS 引擎为互斥的关系,当 JS 引擎执行时 GUI 线程会被挂起, GUI 更新则会被保存在一个队列中等到 JS 引擎线程空闲时立即被执行。
JS阻塞页面加载
从上述的互斥关系,可以推导出,JS 如果执行时间过长就会阻塞页面。
譬如,假设 JS 引擎正在进行巨量的计算,此时就算 GUI 有更新,也会被保存到队列中,等待 JS 引擎空闲后执行。 然后,由于巨量计算,所以 JS 引擎很可能很久很久后才能空闲,自然会感觉到巨卡无比。
所以,要尽量避免 JS 执行时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞的感觉。
解决这种问题,除了将运算放在后端,如果避不开,并且巨量计算还和 UI 有关系,那么我的思路就是使用 setTimeout 将任务分割,中间给出一点空闲时间让 JS 引擎去处理下 UI,不至于页面直接卡死。
如果直接决定最低要求 HTML5+ 的版本,那么可以看看下面的 WebWorker。
WebWorker, JS的多线程
前文中有提到 JS 引擎是单线程的,而且 JS 执行时间过长会阻塞页面,那么 JS 就真的对 cpu 密集型计算无能为力么?
所以,后来 HTML5 中支持了Web Worker。
MDN 的官方解释是:
Web Worker 为 Web 内容在后台线程中运行脚本提供了一种简单的方法。
线程可以执行任务而不干扰用户界面,一个 worker 是使用一个构造函数创建的一个对象(Worker())运行一个命名的 JavaScript 文件(这个文件包含将在工作线程中运行的代码)。
workers 运行在另一个全局上下文中,不同于当前的 window。
因此,使用 window 快捷方式获取当前全局的范围(而不是 self)在一个 Worker 内将返回错误
这样理解下:
创建 Worker 时,JS 引擎向浏览器申请开一个子线程(子线程是浏览器开的,完全受主线程控制,而且不能操作 DOM)
JS 引擎线程与 worker 线程间通过特定的方式通信(postMessage API,需要通过序列化对象来与线程交互特定的数据)
所以,如果有非常耗时的工作,请单独开一个 Worker 线程,这样里面不管如何翻天覆地都不会影响 JS 引擎主线程, 只待计算出结果后,将结果通信给主线程即可,perfect!
而且注意下,JS 引擎是单线程的,这一点的本质仍然未改变,Worker 可以理解是浏览器给 JS 引擎开的外挂,专门用来解决那些大量计算问题。
其它,关于 Worker 的详解就不是本文的范畴了,因此不再赘述。
WebWorker与SharedWorker
既然都到了这里,就再提一下 SharedWorker(避免后续将这两个概念搞混)
WebWorker 只属于某个页面,不会和其他页面的 Render 进程(浏览器内核进程)共享
所以 Chrome 在 Render 进程中(每一个 Tab 页就是一个 Render 进程)创建一个新的线程来运行 Worker 中的 JavaScript 程序。
SharedWorker 是浏览器所有页面共享的,不能采用与 Worker 同样的方式实现,因为它不隶属于某个 Render 进程,可以为多个 Render 进程共享使用
所以 Chrome 浏览器为 SharedWorker 单独创建一个进程来运行 JavaScript 程序,在浏览器中每个相同的 JavaScript 只存在一个 SharedWorker 进程,不管它被创建多少次。
看到这里,应该就很容易明白了,本质上就是进程和线程的区别。SharedWorker 由独立的进程管理,WebWorker 只是属于 Render 进程下的一个线程。
浏览器渲染流程
补充下浏览器的渲染流程(简单版本)
为了简化理解,前期工作直接省略成:
浏览器输入 url,浏览器主进程接管,开一个下载线程,然后进行 http 请求(略去 DNS 查询,IP 寻址等等操作),然后等待响应,获取内容,随后将内容通过 RendererHost 接口转交给 Renderer 进程
浏览器渲染流程开始
浏览器器内核拿到内容后,渲染大概可以划分成以下几个步骤:
解析 html 建立 dom 树
解析 css 构建 render 树(将 CSS 代码解析成树形的数据结构,然后结合 DOM 合并成 render 树)
布局 render 树(Layout/reflow),负责各元素尺寸、位置的计算
绘制 render 树(paint),绘制页面像素信息
浏览器会将各层的信息发送给 GPU,GPU 会将各层合成(composite),显示在屏幕上。
所有详细步骤都已经略去,渲染完毕后就是 load 事件了,之后就是自己的 JS 逻辑处理了。
既然略去了一些详细的步骤,那么就提一些可能需要注意的细节把。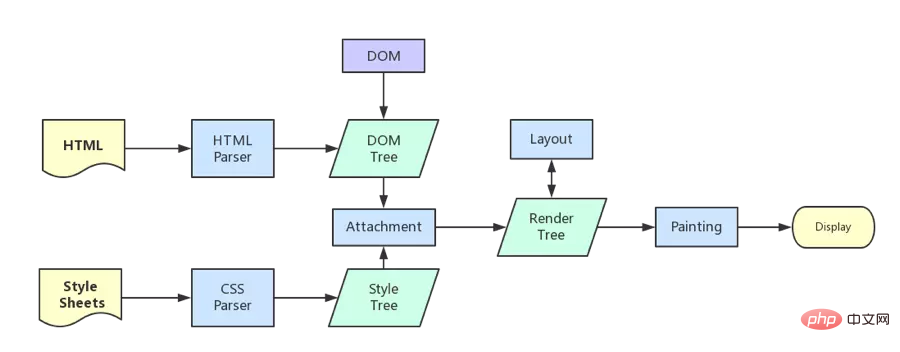
load事件与DOMContentLoaded事件的先后
上面提到,渲染完毕后会触发 load 事件,那么你能分清楚 load 事件与 DOMContentLoaded 事件的先后么?
很简单,知道它们的定义就可以了:
当 DOMContentLoaded 事件触发时,仅当 DOM 加载完成,不包括样式表,图片,async 脚本等。
当 onload 事件触发时,页面上所有的 DOM,样式表,脚本,图片都已经加载完成了,也就是渲染完毕了
所以,顺序是:DOMContentLoaded -> load
css加载是否会阻塞dom树渲染
这里说的是头部引入 css 的情况
首先,我们都知道:css 是由单独的下载线程异步下载的。
然后再说下几个现象:
- css 加载不会阻塞 DOM 树解析(异步加载时 DOM 照常构建)
- 但会阻塞 render 树渲染(渲染时需等 css 加载完毕,因为 render 树需要 css 信息)
这可能也是浏览器的一种优化机制。因为你加载 css 的时候,可能会修改下面 DOM 节点的样式,如果 css 加载不阻塞 render 树渲染的话,那么当 css 加载完之后, render 树可能又得重新重绘或者回流了,这就造成了一些没有必要的损耗。
所以干脆就先把 DOM 树的结构先解析完,把可以做的工作做完,然后等你 css 加载完之后, 在根据最终的样式来渲染 render 树,这种做法性能方面确实会比较好一点。
普通图层和复合图层
渲染步骤中就提到了 composite 概念。
可以简单的这样理解,浏览器渲染的图层一般包含两大类:普通图层 以及 复合图层
首先,普通文档流内可以理解为一个复合图层(这里称为 默认复合层,里面不管添加多少元素,其实都是在同一个复合图层中)
其次,absolute 布局(fixed 也一样),虽然可以脱离普通文档流,但它仍然属于 默认复合层。
然后,可以通过 硬件加速 的方式,声明一个 新的复合图层,它会单独分配资源 (当然也会脱离普通文档流,这样一来,不管这个复合图层中怎么变化,也不会影响 默认复合层 里的回流重绘)
可以简单理解下:GPU 中,各个复合图层是单独绘制的,所以互不影响,这也是为什么某些场景硬件加速效果一级棒
可以Chrome DevTools --> More Tools --> Rendering --> Layer borders中看到,黄色的就是复合图层信息
如何变成复合图层(硬件加速)
将该元素变成一个复合图层,就是传说中的硬件加速技术
最常用的方式:translate3d、translateZ
opacity 属性/过渡动画(需要动画执行的过程中才会创建合成层,动画没有开始或结束后元素还会回到之前的状态)
will-chang 属性(这个比较偏僻),一般配合 opacity 与 translate 使用, 作用是提前告诉浏览器要变化,这样浏览器会开始做一些优化工作(这个最好用完后就释放)
video、 iframe、 canvas、 webgl 等元素
其它,譬如以前的 flash 插件
absolute和硬件加速的区别
可以看到,absolute 虽然可以脱离普通文档流,但是无法脱离默认复合层。 所以,就算 absolute 中信息改变时不会改变普通文档流中 render 树, 但是,浏览器最终绘制时,是整个复合层绘制的,所以 absolute 中信息的改变,仍然会影响整个复合层的绘制。 (浏览器会重绘它,如果复合层中内容多,absolute 带来的绘制信息变化过大,资源消耗是非常严重的)
而硬件加速直接就是在另一个复合层了(另起炉灶),所以它的信息改变不会影响默认复合层 (当然了,内部肯定会影响属于自己的复合层),仅仅是引发最后的合成(输出视图)
复合图层的作用
一般一个元素开启硬件加速后会变成复合图层,可以独立于普通文档流中,改动后可以避免整个页面重绘,提升性能,但是尽量不要大量使用复合图层,否则由于资源消耗过度,页面反而会变的更卡
硬件加速时请使用index
使用硬件加速时,尽可能的使用 index,防止浏览器默认给后续的元素创建复合层渲染
具体的原理时这样的: webkit CSS3 中,如果这个元素添加了硬件加速,并且 index 层级比较低, 那么在这个元素的后面其它元素(层级比这个元素高的,或者相同的,并且 releative 或 absolute 属性相同的), 会默认变为复合层渲染,如果处理不当会极大的影响性能
简单点理解,其实可以认为是一个隐式合成的概念:如果 a 是一个复合图层,而且 b 在 a 上面,那么 b 也会被隐式转为一个复合图层,这点需要特别注意。
从EventLoop谈JS的运行机制
到此时,已经是属于浏览器页面初次渲染完毕后的事情,JS 引擎的一些运行机制分析。
注意,这里不谈 可执行上下文,VO,scop chain 等概念(这些完全可以整理成另一篇文章了),这里主要是结合 Event Loop 来谈 JS 代码是如何执行的。
读这部分的前提是已经知道了 JS 引擎是单线程,而且这里会用到上文中的几个概念:
- JS 引擎线程
- 事件触发线程
- 定时触发器线程
然后再理解一个概念:
JS 分为同步任务和异步任务
- 同步任务都在主线程上执行,形成一个 执行栈
- 主线程之外,事件触发线程管理着一个 任务队列,只要异步任务有了运行结果,就在 任务队列 之中放置一个事件。
- 一旦 执行栈 中的所有同步任务执行完毕(此时 JS 引擎空闲),系统就会读取 任务队列,将可运行的异步任务添加到可执行栈中,开始执行。
看图: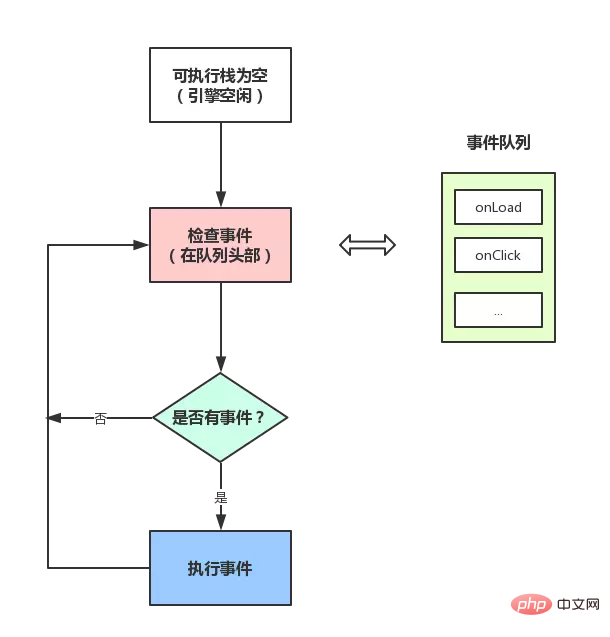
看到这里,应该就可以理解了:为什么有时候 setTimeout 推入的事件不能准时执行?因为可能在它推入到事件列表时,主线程还不空闲,正在执行其它代码, 所以自然有误差。
事件循环机制进一步补充
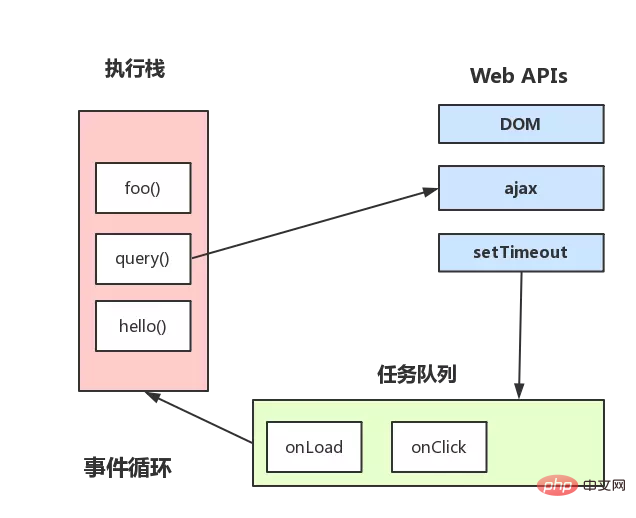
上图大致描述就是:
- 主线程运行时会产生执行栈, 栈中的代码调用某些 api 时,它们会在事件队列中添加各种事件(当满足触发条件后,如 ajax 请求完毕)
- 而栈中的代码执行完毕,就会读取事件队列中的事件,去执行那些回调,如此循环
注意,总是要等待栈中的代码执行完毕后才会去读取事件队列中的事件
单独说说定时器
上述事件循环机制的核心是:JS 引擎线程和事件触发线程
但事件上,里面还有一些隐藏细节,譬如调用 setTimeout 后,是如何等待特定时间后才添加到事件队列中的?
是 JS 引擎检测的么?当然不是了。它是由定时器线程控制(因为 JS 引擎自己都忙不过来,根本无暇分身)
为什么要单独的定时器线程?因为 JavaScript 引擎是单线程的,如果处于阻塞线程状态就会影响记计时的准确,因此很有必要单独开一个线程用来计时。
什么时候会用到定时器线程?当使用 setTimeout 或 setInterval 时,它需要定时器线程计时,计时完成后就会将特定的事件推入事件队列中。
setTimeout而不是setInterval
用 setTimeout 模拟定期计时和直接用 setInterval 是有区别的。
因为每次 setTimeout 计时到后就会去执行,然后执行一段时间后才会继续 setTimeout,中间就多了误差 (误差多少与代码执行时间有关)
而 setInterval 则是每次都精确的隔一段时间推入一个事件,但是,事件的实际执行时间不一定就准确,还有可能是这个事件还没执行完毕,下一个事件就来了。
而且 setInterval 有一些比较致命的问题就是:
累计效应,如果 setInterval 代码在再次添加到队列之前还没有完成执行, 就会导致定时器代码连续运行好几次,而之间没有间隔。 就算正常间隔执行,多个 setInterval 的代码执行时间可能会比预期小(因为代码执行需要一定时间)
譬如像 iOS 的 webview,或者 Safari 等浏览器中都有一个特点,在滚动的时候是不执行JS的,如果使用了 setInterval,会发现在滚动结束后会执行多次由于滚动不执行 JS 积攒回调,如果回调执行时间过长,就会非常容器造成卡顿问题和一些不可知的错误(这一块后续有补充,setInterval 自带的优化,不会重复添加回调)
而且把浏览器最小化显示等操作时,setInterval 并不是不执行程序, 它会把 setInterval 的回调函数放在队列中,等浏览器窗口再次打开时,一瞬间全部执行
所以,鉴于这么多问题,目前一般认为的最佳方案是:用 setTimeout 模拟 setInterval,或者特殊场合直接用 requestAnimationFrame
补充:JS 高程中有提到,JS 引擎会对 setInterval 进行优化,如果当前事件队列中有 setInterval 的回调,不会重复添加。
事件循环进阶:macrotask与microtask
上文中将 JS 事件循环机制梳理了一遍,在 ES5 的情况是够用了,但是在 ES6 盛行的现在,仍然会遇到一些问题,譬如下面这题:
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');嗯哼,它的正确执行顺序是这样子的:
script start script end promise1 promise2 setTimeout
为什么呢?因为 Promise 里有了一个一个新的概念:microtask
或者,进一步,JS 中分为两种任务类型:macrotask 和 microtask,在 ECMAScript 中,microtask 称为 jobs,macrotask 可称为task。
它们的定义?区别?简单点可以按如下理解:
1、macrotask(又称之为宏任务)
可以理解是每次执行栈执行的代码就是一个宏任务(包括每次从事件队列中获取一个事件回调并放到执行栈中执行)
- 每一个 task 会从头到尾将这个任务执行完毕,不会执行其它
- 浏览器为了能够使得 JS 内部 task 与 DOM 任务能够有序的执行,会在一个 task 执行结束后,在下一个 task 执行开始前,对页面进行重新渲染 (task -> 渲染 -> task -> …)
2、microtask(又称为微任务)
可以理解是在当前 task 执行结束后立即执行的任务
- 也就是说,在当前 task 任务后,下一个 task 之前,在渲染之前
- 所以它的响应速度相比 setTimeout(setTimeout 是 task)会更快,因为无需等渲染
- 也就是说,在某一个 macrotask 执行完后,就会将在它执行期间产生的所有 microtask 都执行完毕(在渲染前)
3、分别什么样的场景会形成 macrotask 和 microtask 呢
- macrotask:主代码块,setTimeout,setInterval 等(事件队列中的每一个事件都是一个 macrotask)
- microtask:Promise,process.nextTick 等
补充:在 node 环境下,process.nextTick 的优先级高于 Promise,也就是可以简单理解为:在宏任务结束后会先执行微任务队列中的 nextTickQueue 部分,然后才会执行微任务中的 Promise 部分。
再根据线程来理解下:
(1)macrotask 中的事件都是放在一个事件队列中的,而这个队列由事件触发线程维护
(2)microtask 中的所有微任务都是添加到微任务队列(Job Queues)中,等待当前 macrotask 执行完毕后执行,而这个队列由 JS 引擎线程维护 (这点由自己理解+推测得出,因为它是在主线程下无缝执行的)
所以,总结下运行机制:
- 执行一个宏任务(栈中没有就从事件队列中获取)
- 执行过程中如果遇到微任务,就将它添加到微任务的任务队列中
- 宏任务执行完毕后,立即执行当前微任务队列中的所有微任务(依次执行)
- 当前宏任务执行完毕,开始检查渲染,然后GUI线程接管渲染
- 渲染完毕后,JS线程继续接管,开始下一个宏任务(从事件队列中获取)
如图: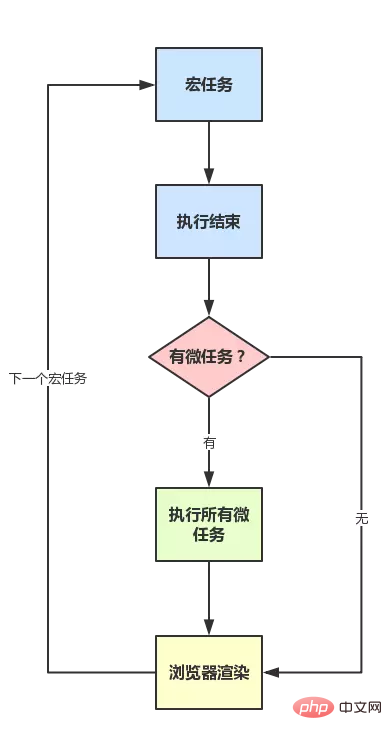
另外,请注意下 Promise 的 polyfill 与官方版本的区别:
官方版本中,是标准的 microtask 形式
polyfill,一般都是通过 setTimeout 模拟的,所以是 macrotask 形式
注意,有一些浏览器执行结果不一样(因为它们可能把 microtask 当成 macrotask 来执行了), 但是为了简单,这里不描述一些不标准的浏览器下的场景(但记住,有些浏览器可能并不标准)
补充:使用MutationObserver实现microtask
MutationObserver可以用来实现microtask (它属于microtask,优先级小于Promise, 一般是Promise不支持时才会这样做)
它是HTML5中的新特性,作用是:监听一个DOM变动, 当DOM对象树发生任何变动时,Mutation Observer会得到通知
像以前的Vue源码中就是利用它来模拟nextTick的, 具体原理是,创建一个TextNode并监听内容变化, 然后要nextTick的时候去改一下这个节点的文本内容, 如下:
var counter = 1
var observer = new MutationObserver(nextTickHandler)
var textNode = document.createTextNode(String(counter))
observer.observe(textNode, {
characterData: true
})
timerFunc = () => {
counter = (counter + 1) % 2
textNode.data = String(counter)
}不过,现在的Vue(2.5+)的nextTick实现移除了MutationObserver的方式(据说是兼容性原因), 取而代之的是使用MessageChannel (当然,默认情况仍然是Promise,不支持才兼容的)。
MessageChannel属于宏任务,优先级是:MessageChannel->setTimeout, 所以Vue(2.5+)内部的nextTick与2.4及之前的实现是不一样的,需要注意下。
【相关推荐:javascript视频教程、web前端】
以上就是完全掌握JavaScript运行机制及原理的详细内容,更多请关注自由互联其它相关文章!