
推荐学习:mysql教程
前期准备
首先创建一张表,然后插入三条数据:
CREATE TABLE T( ID int(11) NOT NULL AUTO_INCREMENT, c int(11) NOT NULL, PRIMARY KEY (ID)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='测试表';INSERT INTO T(c) VALUES (1), (2), (3);
让后执行更新操作:
update T set c=c+1 where ID=2;
在说更新操作前,大家先来看一下sql语句在MySQL中的执行流程~
SQL语句的执行过程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oRuDIrVS-1646917447700)(/upload/2021/10/image-3b172ec1cf324d3ea025e518547a668a.png)]](http://img.558idc.com/uploadfile/allimg/mysql-1/de3a399263525d833da4c85452796cff-0.png)
如图所示:MySQL数据库主要分为两个层级:服务层和存储引擎层服务层:server层包括连接器、查询缓存、分析器、优化器、执行器,包括大多数MySQL中的核心功能所有跨存储引擎的功能也在这一层实现,包括 存储过程、触发器、视图等。 存储引擎层:存储引擎层包括MySQL常见的存储引擎,包括MyISAM、InnoDB和Memory等,最常用的是InnoDB,也是现在MySQL的默认存储引擎。
server层中的组件介绍
连接器: 需要MySQL客户端登录,需要一个 连接器 来连接用户和MySQL数据库,“mysql -u 用户名 -p 密码” 进行MySQL登录,在完成 TCP握手 后,连接器会根据输入的用户名和密码验证登录身份。
查询缓存: MySQL在得到一个执行请求后,会首先去 查询缓存 中查找,是否执行过这条SQL语句,之前执行过得语句以及结果会以 key-value对的形式,放在内存中。key是查询语句,value是查询的结果。如果通过key能够查找到这条SQL语句,直接返回SQL的执行结果。若不存在缓存中,就会继续后面的执行阶段。执行完成后,执行结果就会被放入查询缓存中。优点是效率高。但是查询缓存不建议使用, 因为在MySQL中对某张表进行了更新操作,那么所有的查询缓存就会失效,对于更新频繁的数据库来说,查询缓存的命中率很低。需要注意:在MySQL8.0版本,查询缓存功能就删除了,不存在查询缓存的功能了
分析器: 分为词法分析和语法分析
- 词法分析: 首先,MySQL会根据SQL语句进行解析,分析器会先做 词法分析,你写的SQL就是由多个字符串和空格组成的一条SQL语句,MySQL需要识别出里面的字符串是什么,代表什么。
- 语法分析: 然后进行 语法分析, 根据词法分析的结果,语法分析器会根据语法规则,判断输入的这个SQL语句是否满足MySQL语法。如果SQL语句不正确,就提示:You have an error in your SQL suntax
优化器: 经过分析器分析后,SQL就合法了,但在执行之前,还需要进行优化器的处理,优化器会判断使用了哪种索引,使用哪种连接,优化器的作用 就是确定效率最高的执行方案。
执行器: 在执行阶段,MySQL首先会判断有没有执行语句的权限,若无权限,返回没有权限的错误;若有权限,就打开表继续执行。打开表时,执行器会根据标的引擎定义,去使用该引擎提供的接口,对于有索引的表,执行的逻辑类似。
了解完SQL语句的执行流程我们接下来详细分析一下上面update T set c=c+1 where ID=2;是如何执行的。
Update语句分析
update T set c=c+1 where ID=2;
在执行update更新操作的时候,跟这个表有关的查询缓存会失效,所以这条语句就会把表 T 上所有缓存结果都清空。接下来,分析器会经过语法分析和词法分析,知道了这是一条更新语句后,优化器决定要使用哪一个索引,然后执行器负责具体的执行,先找到这一行,然后做更新。
按照我们平常的思路,就是 找出这条记录,把它的值改好,保存就OK了 。但我们追究一下细节,由于涉及到修改数据,所以涉及到日志了。更新操作涉及到两个重要的日志模块。redo log(重做日志),bin log(归档日志)。MySQL中的这两个日志也是必学的。
redo log(重做日志)
- 在 MySQL 里,如果每一次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程 IO 成本、查找成本都很高。
MySQL里使用WAL(预写式日志)技术,WAL 的全称是Write-Ahead Logging,它的关键点就是 先写日志,再写磁盘。 - 具体来说,当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做。
- InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写。
听完上面对redo log日志的介绍后,小伙伴们可能会问:redo log日志存储在哪?, 数据库信息保存在磁盘上,redo log日志也保存在磁盘上,为什么要先写到redo log中再写到数据库中呢?,redo log日志如果存满数据了怎么办?等等。接下来就解答一下这些疑问。
redo log存储在哪里?
InnoDB引擎先把记录写到redo log 中,redo log 在哪,它也是在磁盘上,这也是一个写磁盘的过程, 但是与更新过程不一样的是,更新过程是在磁盘上随机IO,费时。 而写redo log 是在磁盘上顺序IO。效率要高。
redo log 空间是固定,那它会不会用完呢?
首先不用担心 redo log 会用完空间,因为它是循环利用的。例如 redo log 日志配置为一组4个文件,每个文件分别为1G。它写的流程如下图: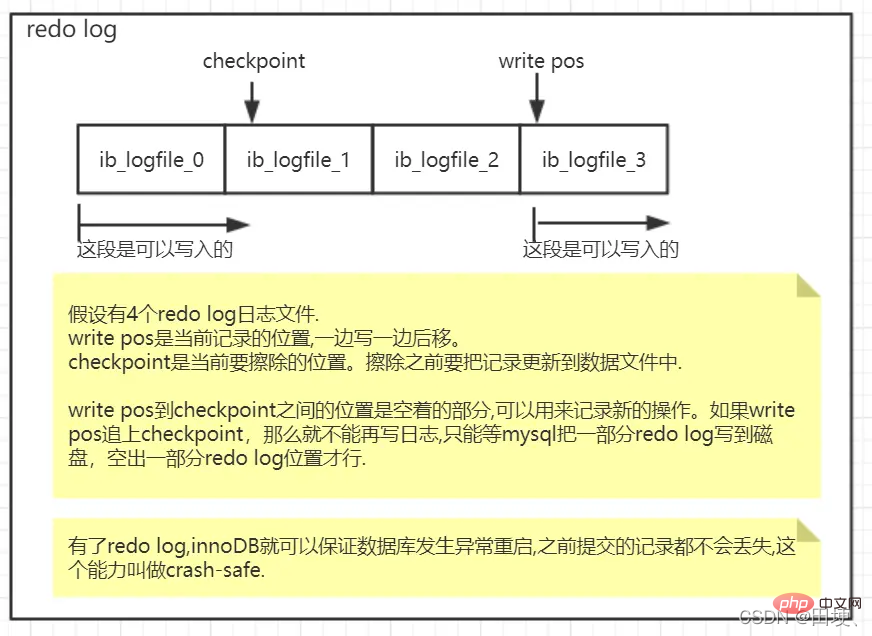
简单总结一下: redo log日志是Innodb存储引擎特有的机制,可以用来应对异常恢复,Crash-safe,redo可以保证mysql异常重启时,将未提交的事务回滚,已提交的事务安全落库。
crash-safe: 有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe。
binlog(归档日志)
redo log是innoDB 引擎特有的日志。而binlog是mysql server层的日志。
其实bin log日志出现的时间比redo log早,因为最开始MySQL是没有InnoDB存储引擎的,5.5之前是MyISAM。但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系统——也就是 redo log 来实现 crash-safe 能力。
redo log和bin log的总结
- redo log是为了保证innoDB引擎的crash-safe能力,也就是说在mysql异常宕机重启的时候,之前提交的事务可以保证不丢失;(因为成功提交的事务肯定是写入了redo log,可以从redo log恢复)
- bin log是归档日志,将每个更新操作都追加到日志中。这样当需要将日志恢复到某个时间点的时候,就可以根据全量备份+bin log重放实现。 如果没有开启binlog,那么数据只能恢复到全量备份的时间点,而不能恢复到任意时间点。如果连全量备份也没做,mysql宕机,磁盘也坏了,那就很尴尬了。。
redo log和bin log的区别:
- redo log 是 InnoDB 引擎特有的;bin log 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
- redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;bin log 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
- redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
InnoDB引擎部分在执行这个简单的update语句的时候的内部流程
update T set c=c+1 where ID=2;
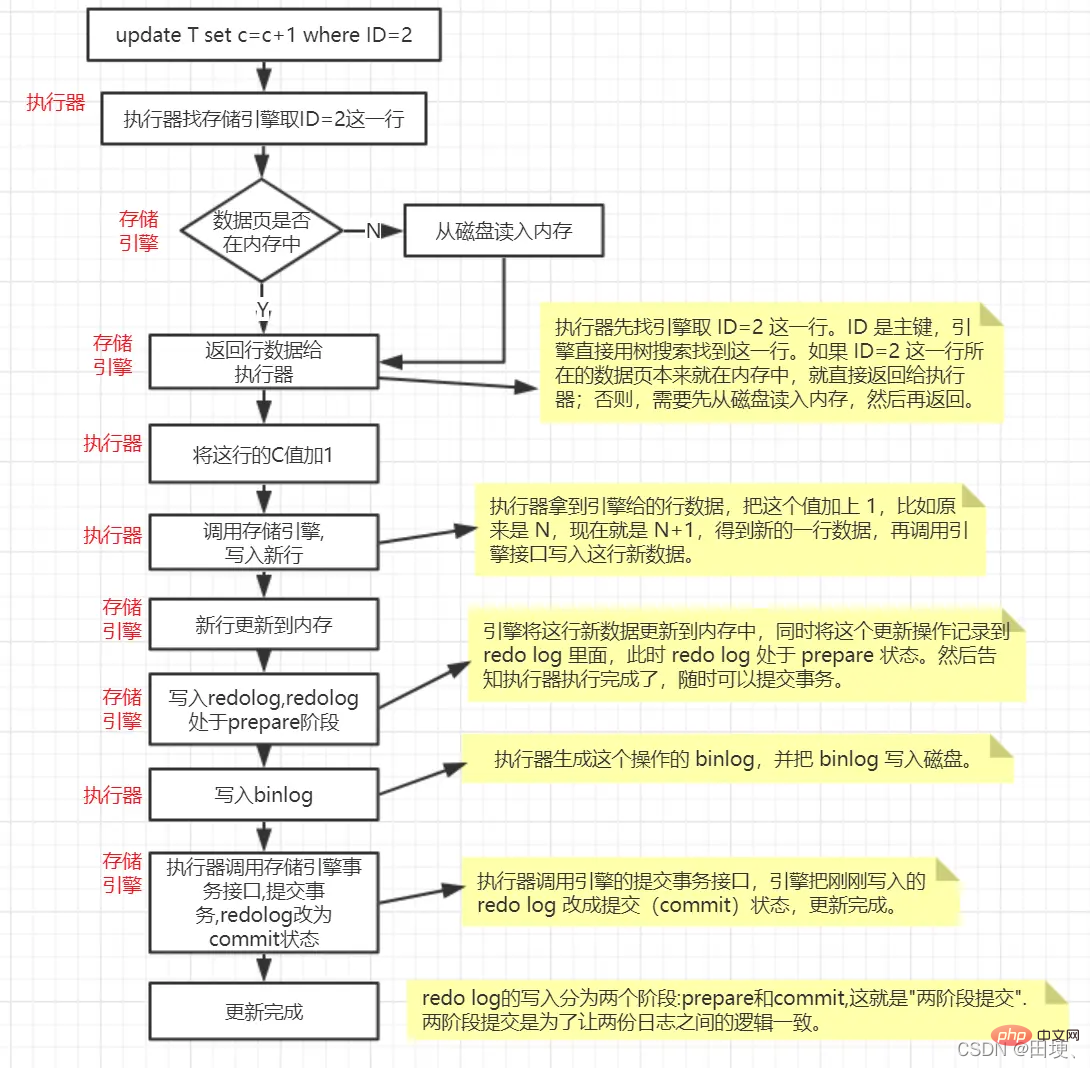
手动用begin开启事务,然后执行update语句,再然后执行commit语句,那上面的update更新流程之前 哪些是update语句执行之后做的,哪些是commit语句执行之后做的?
事实上,redo log在内存中有一个
redo log buffer,binlog 也有一个binlog cache.所以在手动开启的事务中,你执行sql语句,其实是写到redo log buffer和binlog cache中去的(肯定不可能是直接写磁盘日志,一个是性能差一个是回滚的时候不可能去回滚磁盘日志吧),然后当你执行commit的时候,首先要将redo log的提交状态游prepare改为commit状态,然后就要把binlog cache刷新到binlog日志(可能也只是flush到操作系统的page cache,这个就看你的mysql配置),redo log buffer刷新到redo log 日志(刷新时机也是可以配置的)。 如果你回滚的话,就只用把binlog cache和redo log buffer中的数据清除就行了。
在update过程中,mysql突然宕机,会发生什么情况?
如果redolog写入了,处于prepare状态,binlog还没写入,那么宕机重启后,redolog中的这个事务就直接回滚了。
如果redolog写入了,binlog也写入了,但redolog还没有更新为commit状态,那么宕机重启以后,mysql会去检查对应事务在binlog中是否完整。如果是,就提交事务;如果不是,就回滚事务。 (redolog处于prepare状态,binlog完整启动时就提交事务,为啥要这么设计? 主要是因为binlog写入了,那么就会被从库或者用这个binlog恢复出来的库使用,为了数据一致性就采用了这个策略)
redo log和binlog是通过xid这个字段关联起来的。
推荐学习:mysql教程
以上就是一起来分析MySQL的update语句是怎样执行的的详细内容,更多请关注自由互联其它相关文章!