Stream常用操作以及原理
Stream是什么?
Stream是一个高级迭代器,它不是数据结构,不能存储数据。它可以用来实现内部迭代,内部迭代相比平常的外部迭代,它可以实现并行求值(高效,外部迭代要自己定义线程池实现多线程来实现高效处理)、惰性求值(中没有终止操作,中间操作是不会执行的)、短路操作(拿到正确的结果就返回,不需要等到整个过程完成之后)等
-
Stream翻译过来的意思就是“溪流,流”的意思,而我们刚开始学习java的时候接触最多的就是IO流,它更像“农夫山泉”,“我们只做大自然的搬运工”,只是将一个文件从这个地方传到另一个地方,对于文件当中内容不做任何增删改操作,而Stream就会,也就是将要处理的数据当作流,在管道中进行传输,并在管道中的每个节点对数据进行处理,如过滤、排序、转换等;
-
通常我们需要处理的数据是以Collection、Array等数据来源;
-
Stream它是Java8中的一个新特性,那关于Java8中的其他新特性内容可以参考这篇文章《Java8新特性实战》;
-
那既然是Java8的新特性,而且我们也知道Java8大改动之一的就是增加了函数式编程,而Stream就主角,那有关函数式编程是什么,可以参考知乎上的一篇文章《什么是函数式编程?》;
-
既然是函数式编程,所以通常是配合Lambda表达式使用;
Stream怎么用? 所有操作分类
首先Stream的所有操作可分为两类,一是中间操作,二是终止操作
中间操作:中间操作只是一种标记,只有结束操作才会触发实际计算
- 无状态:指元素的处理不受前面元素的影响;
- 有状态:有状态的中间操作必须等到所有元素处理之后才知道最终结果,比如排序是有状态操作,在读取所有元素之前并不能确定排序结果。
终止操作:顾名思义,就是得出最后计算结果的操作
- 短路操作:指不用处理全部元素就可以返回结果;
- 非短路操作:指必须处理所有元素才能得到最终结果。
此外这里我看到有的地方将collect定义为了中间操作,但通过我看了大部分对Stream的介绍,发现Collect这个收集操作是最终止操作,毕竟这也符合我们平时所用到它的场景,所以还请加以辨别有的文章中提到的collect是中间操作的错误解释。

常用操作
以下两张图是对stream的常用操作做了一个简单使用案例,原本流程图在这Java8新特性


那至于常用操作这块,本次博客也不在进行过多的细说,因为网上有很多这种使用类型的文章,我常看的有这三篇文章:
-
为什么我到点就可以下班
- 作者是不高兴就喝水,虽然这个题目名字有点不符文章内容,但内容还是很肝的,主要是一些应用例子。
-
用Stream来优化老代码,瞬间干净优雅了!
- 作者是JavaGuide,里面简单的提了一些操作
-
Java8 stream 排序以及自定义比较器,很实用!
- 作者是芋道源码,主要是对我们平时会用List、Set、Map这些集合类型做排序的例子
-
java两个List的交集,并集
- 这个是自己当时在使用集合的时候看到的一篇文章,可以作为补充看看
为什么使用Stream? 声明式处理数据
第一个原因我觉得是Stream流可以以声明式的方式去处理数据,也就是像它其中就有filter、sort这种以及写好的操作,只需要拿来使用即可,如果我们平时使用for循环,还要在for循环中自己去写怎么过滤的这些操作,最后才得出自己想要的结果,对比这种命令式的操作
可以说让我们代码更加干净、简洁。
对比for循环对于与for循环效率的对比,我觉得和以下内容差不多,但搜寻网上资料来证明某一观点正确的我目前没有找到,很多人持有观点就是“牺牲代码效率来换取代码简洁度”,“Stream的优势在于有并行处理”,“Stream的效率与for差不多,为了代码简洁更偏向Stream”等。
但是牺牲代码效率换代码简洁度我觉得还是有问题的,不能一概而论。但是函数式编程的优点就是代码简洁,多核友好并行处理这是不可否认的。
处理集合数据
- 针对不同的数据结构,Stream流的执行效率是不一样的
- 针对不同的数据源,Stream流的执行效率也是不一样的
- 对于简单的数字(list-Int)遍历,普通for循环效率的确比Stream串行流执行效率高(1.5-2.5倍)。但是Stream流可以利用并行执行的方式发挥CPU的多核优势,因此并行流计算执行效率高于for循环。
- 对于list-Object类型的数据遍历,普通for循环和Stream串行流比也没有任何优势可言,更不用提Stream并行流计算。
虽然在不同的场景、不同的数据结构、不同的硬件环境下。Stream流与for循环性能测试结果差异较大,甚至发生逆转。但是总体上而言:
- Stream并行流计算 >> 普通for循环 ~= Stream串行流计算 (之所以用两个大于号,你细品)
- 数据容量越大,Stream流的执行效率越高。
- Stream并行流计算通常能够比较好的利用CPU的多核优势。CPU核心越多,Stream并行流计算效率越高。
- 如果数据在1万以内的话,for循环效率高于foreach和stream;如果数据量在10万的时候,stream效率最高,其次是foreach,最后是for。另外需要注意的是如果数据达到100万的话,parallelStream异步并行处理效率最高,高于foreach和for
Stream可以说是Java8中对于处理集合的抽象概念,所以我们经常对集合中的数据采用像SQL这种类似方式去处理;所以经常会用Stream进行遍历操作,那相较于我们以前写的嵌套for循环可以说是代码更加的简洁,更直观易读。当然循环只是循环,而Stream是个流的形式去做处理。那如何去做迭代,那就得看看stream的原理了。
惰性计算惰性计算我们也可以称作惰性求值或者延迟求值,这种方式在函数式编程中极为常见,也就是当计算出结果后不立马去返回值,而是在它要被用到的时候来计算;
在Stream中,我们就可以看作中间操作,比如当要对一个List集合做出Stream操作,比如filter,但是没有最终操作,它返回的还是一个Stream流。也就是我们可以看作下图这种方式。

从实现角度比较, Stream和Collection也有众多不同:
- 不存储数据。 流不是一个存储元素的数据结构。 它只是传递源(source)的数据。
- 功能性的(Functional in nature)。 在流上操作只是产生一个结果,不会修改源。 例如filter只是生成一个筛选后的stream,不会删除源里的元素。
- 延迟搜索。 许多流操作, 如filter, map等,都是延迟执行。 中间操作总是lazy的。
- Stream可能是无界的。 而集合总是有界的(元素数量是有限大小)。 短路操作如limit(n) , findFirst()可以在有限的时间内完成在无界的stream
- 可消费的(Consumable)。 不是太好翻译, 意思流的元素在流的声明周期内只能访问一次。 再次访问只能再重新从源中生成一个Stream
Stream原理
也许我们会觉得,Stream的实现是每一次去调用函数,它就会进行一次迭代,这肯定是不对的,这样Stream的效率是很低的。
其实事实是我们可以通过看源码来发现它是怎样迭代的,其实Stream内部是通过流水线(Pipeline)的方式来实现的,基本思想是在迭代的时候顺着流水线(Pipeline)尽可能的执行更多的操作,从而避免多次迭代。
也就是说Stream在执行中间操作时仅仅是记录,当用户调用终止操作时,会在一个迭代里将已经记录的操作顺着流水线全部执行掉。沿着这个思路,有几个问题需要解决:
- 用户的操作如何记录?
- 操作如何叠加?
- 叠加之后的操作如何执行?
以上我们可以知道Stream的完整操作,是一个由<数据来源、操作、回调函数>组成的三元组;
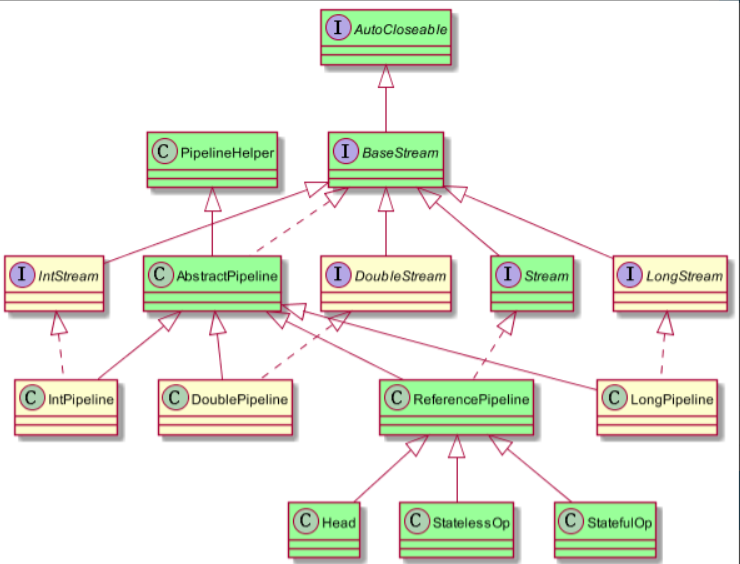
此外我们还需要知道Stream的相关类与接口的继承关系。如下图:
- 从图中可以看出我们除了基本类型以外,引用类型是通过实例化的ReferencePipeline来表示
- 而与ReferencePipeline并行三个类是为其基本类型定制的。
- 首先JDK源码中经常会用stage(阶段)来标识一次操作。
- 其次,Stream操作通常需要一个回调函数(Lambda表达式)
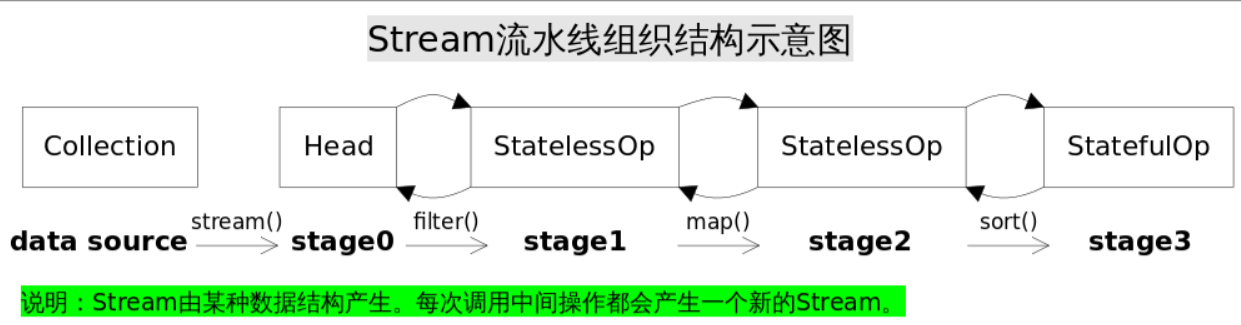
从以上我们可以看出,当我们调用stream方法时,最终会去创建一个Head实例来表示操作头,也就是第一个stage,当调用filter()方法时则会创建中间操作实例StatelessOp(无状态),接着调用map()方法时则会创建中间操作实例StatelessOp(无状态),最后调用sort()方法时会创建最终操作实例StatefulOp(有状态),同样调用其他操作对应的方法也会生成一个ReferencePipeline实例,通过调用这一系列操作最终形成一个双向链表,即每个Stage都记录了前一个Stage和本次的操作以及回调函数。
源码:
1.调用stream,创建Head实例
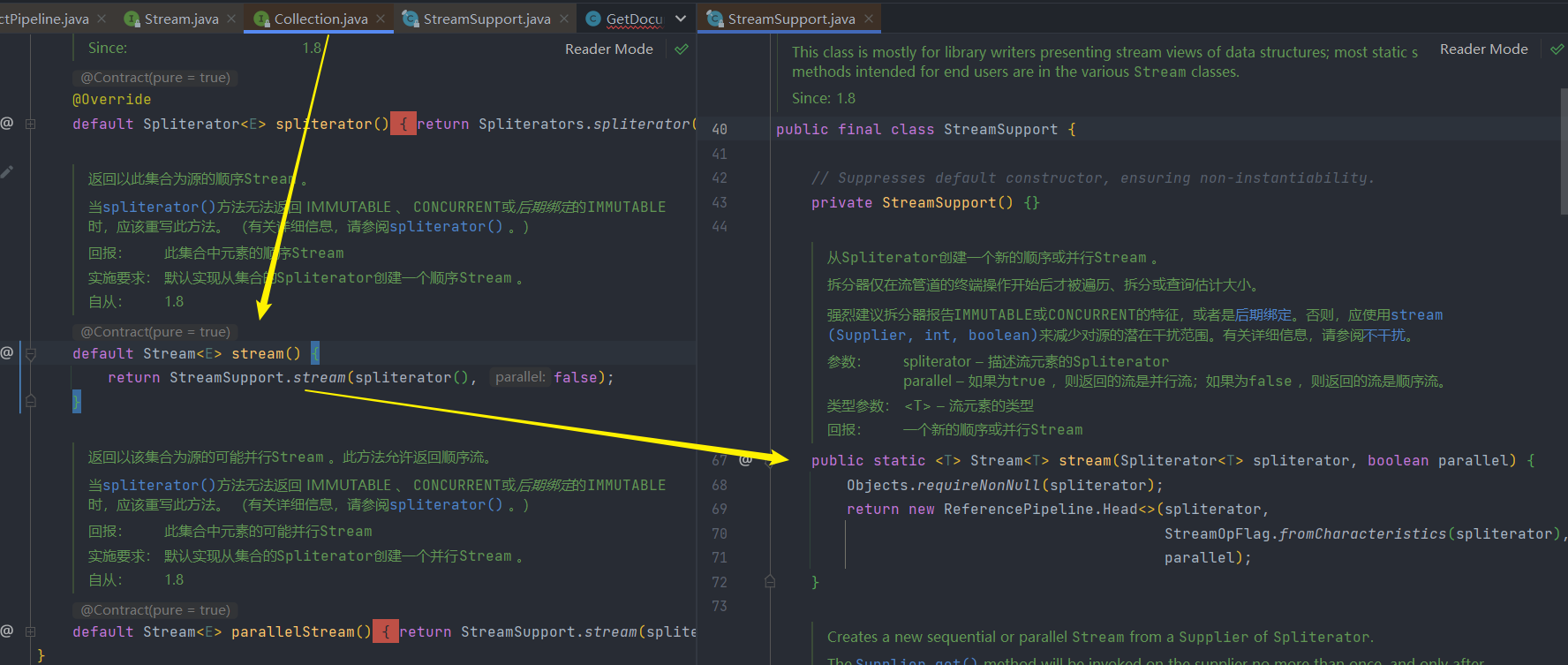
2.调用filter或map中间操作
- 这些中间操作以及最终操作都在ReferencePipeline这个类中,它实现其元素类型的中间管道阶段或管道源阶段的抽象基类。
下面代码逻辑就是将回调函数mapper包装到一个Sink当中。由于Stream.map()是一个无状态的中间操作,所以map()方法返回了一个StatelessOp内部类对象(一个新的Stream),调用这个新Stream的opWripSink()方法将得到一个包装了当前回调函数的Sink。
这个Sink就是下面提到的操作如何叠加方式。
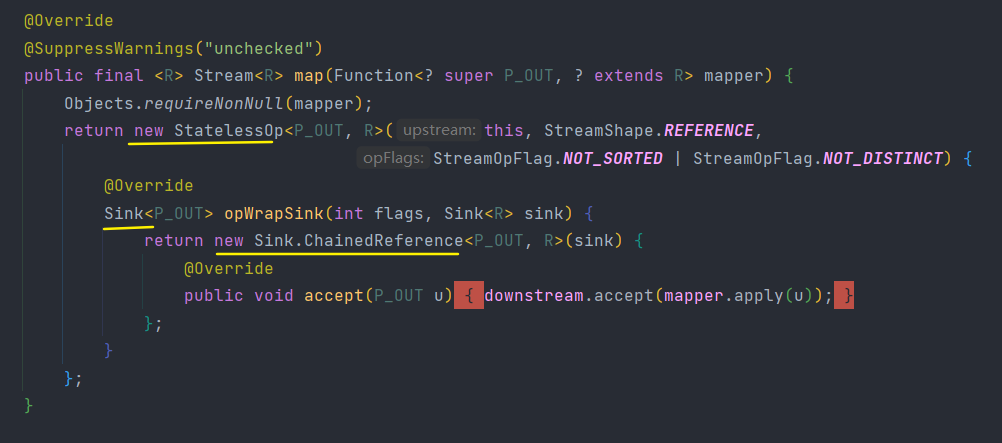
从上面我们可以知道Stream通过stage来记录操作,但stage只保存当前操作,它是不知道怎么操作下一个stage,它又需要什么操作。
所以要执行的话还需要某种协议将各个stage关联起来。
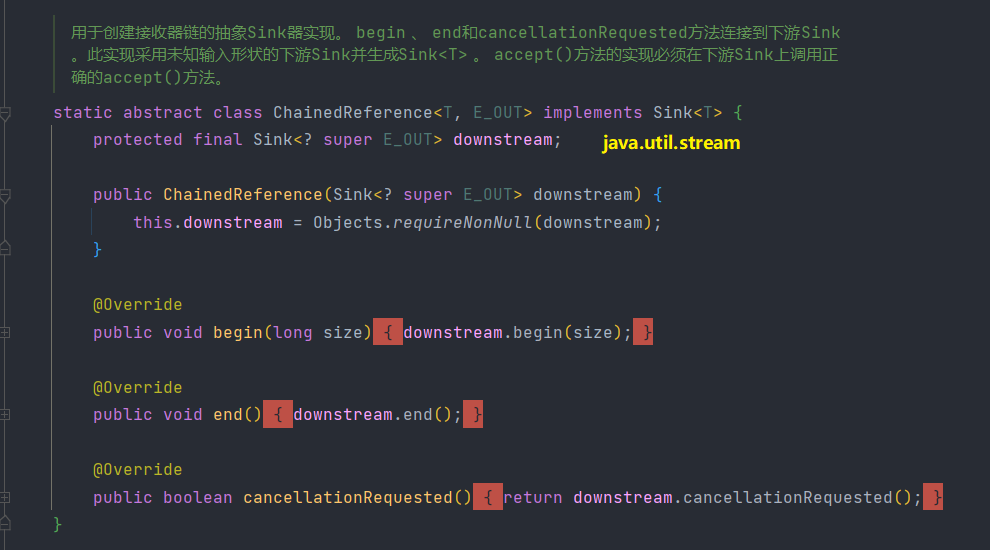
JDK中就是使用Sink(我们可以称为“汇聚结点”)接口来实现的,Sink接口定义begin()、end()、cancellationRequested()、accept()四个方法,如下表所示。
Sink接口注释文档:
Consumer的扩展,用于通过流管道的各个阶段传递值,具有管理大小信息、控制流等的附加方法。在第一次调用Sink上的accept()方法之前,您必须首先调用begin()方法来通知它有数据来了(可选地通知接收器有多少数据来了),并且在所有数据都发送之后,你必须调用end()方法。在调用end()之后,您不应该在没有再次调用begin() ) 的情况下调用accept() )。 Sink还提供了一种机制,通过该机制,sink 可以合作发出它不希望接收更多数据的信号( cancellationRequested()方法),源可以在向Sink发送更多数据之前轮询该机制。
接收器可能处于以下两种状态之一:初始状态和活动状态。它从初始状态开始; begin()方法将其转换为活动状态, end()方法将其转换回初始状态,在该状态下可以重复使用。数据接受方法(如accept()仅在活动状态下有效。
API 注释:
流管道由一个源、零个或多个中间阶段(例如过滤或映射)和一个终端阶段(例如归约或 for-each)组成。具体来说,考虑管道:
int longestStringLengthStartingWithA
= strings.stream()
.filter(s -> s.startsWith("A"))
.mapToInt(String::length)
.max();
在这里,我们分为三个阶段,过滤、映射和归约。过滤阶段使用字符串并发出这些字符串的子集;映射阶段使用字符串并发出整数;归约阶段消耗这些整数并计算最大值。
Sink实例用于表示此管道的每个阶段,无论该阶段接受对象、整数、长整数还是双精度数。 Sink 具有accept(Object) 、 accept(int)等的入口点,因此我们不需要每个原始特化的专用接口。 (对于这种杂食性趋势,它可能被称为“厨房水槽”。)管道的入口点是过滤阶段的Sink ,它将一些元素“下游”发送到映射阶段的Sink ,然后将整数值向下游发送到Sink以进行缩减阶段。与给定阶段关联的Sink实现应该知道下一阶段的数据类型,并在其下游Sink上调用正确的accept方法。同样,每个阶段都必须实现与其接受的数据类型相对应的正确accept方法。
Sink.OfInt等特化子类型覆盖accept(Object)以调用accept的适当原语特化,实现Consumer的适当原语特化,并重新抽象accept的适当原语特化。
Sink.ChainedInt等链子类型不仅实现Sink.OfInt ,还维护了一个表示下游Sink的downstream字段,并实现了begin() 、 end()和cancellationRequested()方法来委托给下游Sink 。大多数中间操作的实现将使用这些链接包装器。例如,上面示例中的映射阶段如下所示:
IntSink is = new Sink.ChainedReference<U>(sink) {
public void accept(U u) {
downstream.accept(mapper.applyAsInt(u));
}
};
在这里,我们实现Sink.ChainedReference<U> ,这意味着我们期望接收U类型的元素作为输入,并将下游接收器传递给构造函数。因为下一阶段需要接收整数,所以我们必须在向下游发送值时调用accept(int)方法。 accept()方法将映射函数从U应用到int并将结果值传递给下游Sink 。
interface Sink<T> extends Consumer<T> {}
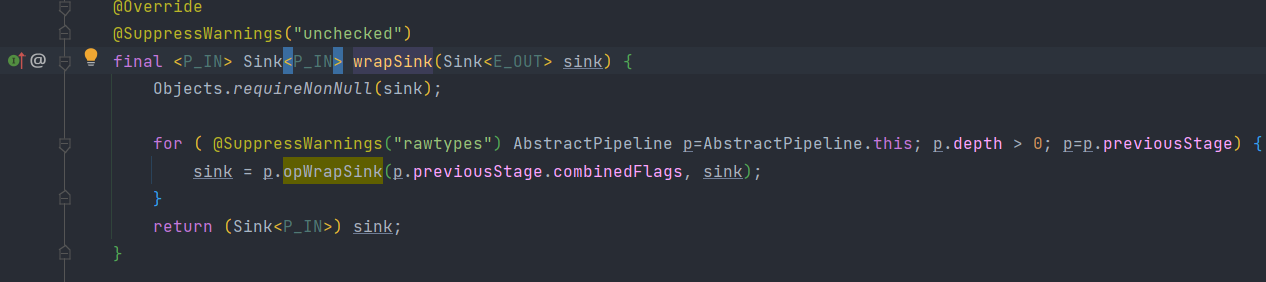
从上面那张图中调用ReferencePipeline.map()的方法,我们会发现我们在创建一个ReferencePipeline实例的时候,需要重写opWrapSink方法来生成对应Sink实例。而且通过阅读源码会发现常用的操作都会创建一个ChainedReference实例;
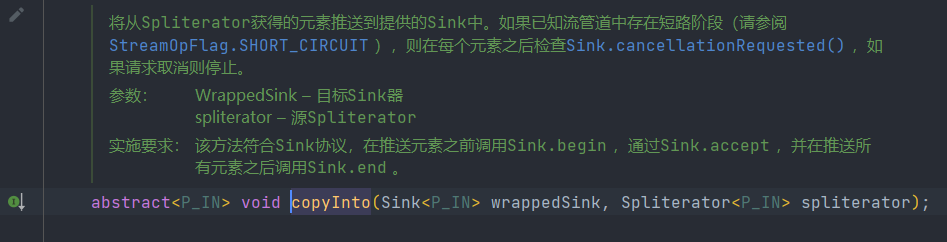
3.操作叠加后如何进行执行?有了上面的协议,相邻Stage之间调用就很方便了,每个Stage都会将自己的操作封装到一个Sink里,前一个Stage只需调用后一个Stage的
accept()方法即可,并不需要知道其内部是如何处理的。当然对于有状态的操作,Sink的
begin()和end()方法也是必须实现的。比如Stream.sorted()是一个有状态的中间操作,其对应的Sink.begin()方法可能创建一个乘放结果的容器,而accept()方法负责将元素添加到该容器,最后end()负责对容器进行排序。对于短路操作,
Sink.cancellationRequested()也是必须实现的,比如Stream.findFirst()是短路操作,只要找到一个元素,cancellationRequested()就应该返回true,以便调用者尽快结束查找。Sink的四个接口方法常常相互协作,共同完成计算任务。
实际上Stream API内部实现的的本质,就是如何重载Sink的这四个接口方法
Sink完美封装了Stream每一步操作,并给出了[处理->转发]的模式来叠加操作。这一连串的齿轮已经咬合,就差最后一步拨动齿轮启动执行。是什么启动这一连串的操作呢?也许你已经想到了启动的原始动力就是结束操作(Terminal Operation),一旦调用某个结束操作,就会触发整个流水线的执行。
结束操作之后不能再有别的操作,所以结束操作不会创建新的流水线阶段(Stage),直观的说就是流水线的链表不会在往后延伸了。结束操作会创建一个包装了自己操作的Sink,这也是流水线中最后一个Sink,这个Sink只需要处理数据而不需要将结果传递给下游的Sink(因为没有下游)。对于Sink的[处理->转发]模型,结束操作的Sink就是调用链的出口。
我们再来考察一下上游的Sink是如何找到下游Sink的。
一种可选的方案是在PipelineHelper中设置一个Sink字段,在流水线中找到下游Stage并访问Sink字段即可。
但Stream类库的设计者没有这么做,而是设置了一个
Sink AbstractPipeline.opWrapSink(int flags, Sink downstream)方法来得到Sink,该方法的作用是返回一个新的包含了当前Stage代表的操作以及能够将结果传递给downstream的Sink对象。为什么要产生一个新对象而不是返回一个Sink字段?
这是因为使用opWrapSink()可以将当前操作与下游Sink(上文中的downstream参数)结合成新Sink。试想只要从流水线的最后一个Stage开始,不断调用上一个Stage的opWrapSink()方法直到最开始(不包括stage0,因为stage0代表数据源,不包含操作),就可以得到一个代表了流水线上所有操作的Sink,用代码表示就是这样:
类PipelineHelper
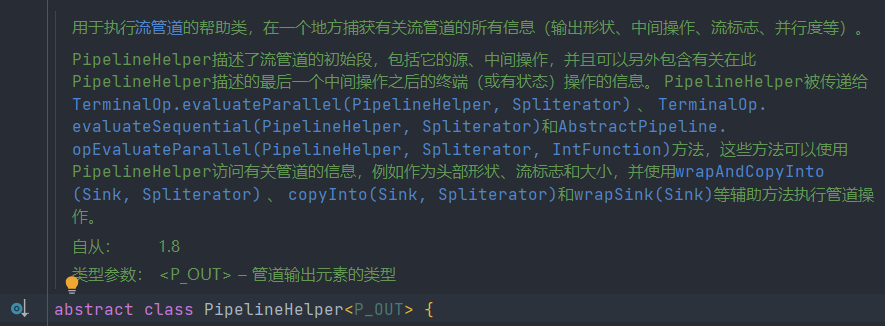

类 AbstractPipeline extends PipelineHelper
-
通过wrapSink方法得到从开始到结束的所有操作并包装在一个sink里面,然后通过copyInto执行,就相当于整个流水线进行了执行
-
代码执行逻辑:首先调用wrappedSink.begin()方法告诉Sink数据即将到来,然后调用spliterator.forEachRemaining()方法对数据进行迭代,最后调用wrappedSink.end()方法通知Sink数据处理结束。

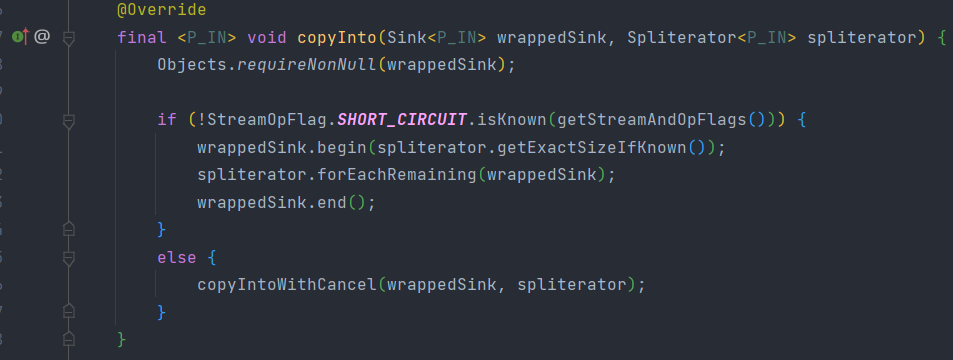
针对不同类型的返回结果,下表给出了各种有返回结果的Stream结束操作:
- 对于表中返回boolean或者Optional的操作(Optional是存放 一个 值的容器)的操作,由于值返回一个值,只需要在对应的Sink中记录这个值,等到执行结束时返回就可以了。
- 对于归约操作,最终结果放在用户调用时指定的容器中(容器类型通过[收集器](https://www.cnblogs.com/CarpenterLee/p/5-Streams API(II).md#收集器)指定)。collect(), reduce(), max(), min()都是归约操作,虽然max()和min()也是返回一个Optional,但事实上底层是通过调用[reduce()](https://www.cnblogs.com/CarpenterLee/p/5-Streams API(II).md#多面手reduce)方法实现的。
- 对于返回是数组的情况,毫无疑问的结果会放在数组当中。这么说当然是对的,但在最终返回数组之前,结果其实是存储在一种叫做Node的数据结构中的。Node是一种多叉树结构,元素存储在树的叶子当中,并且一个叶子节点可以存放多个元素。这样做是为了并行执行方便。
参考文章:
Java 8 Stream原理解析
深入理解Java Stream流水线
Java 8 Stream探秘
Java8 Stream原理深度解析
梳理//例子:List<T> a = b.stream().map(m::getId()).collect(Collectors.toList())
//1.首先调用stream方法,看源码:
public interface Collection<E> extends Iterable<E> {
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
}
//2.进入StreamSupport
//3.发现用的ReferencePipeline创建的Head头,进行此次操作记录
public final class StreamSupport {
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
}
//4.调用中间操作map方法,发现中间操作和最终操作的那些操作都在此
//5.发现map操作是个StatelessOp(无状态操作),同时此类继承于AbstractPipeline,并重写了opWrapSink方法;
//6.并通过Sink接口实现相邻stage直接的连接,来进行操作记录的叠加
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
@Override
@SuppressWarnings("unchecked")
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
}
//7.通过PipelineHelper中的wrapSink接口进行开始到结束的操作记录包装到一个Sink中
abstract class PipelineHelper<P_OUT> {
abstract<P_IN> Sink<P_IN> wrapSink(Sink<P_OUT> sink);
}
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
@Override
@SuppressWarnings("unchecked")
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
}
//8.通过PipelineHelper中的copyInto接口执行stage
abstract class PipelineHelper<P_OUT> {
abstract<P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator);
}
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
}
//9.最后通过不同类型的操作类型来得出Stream的返回结果
最后
这些个人想说的话还是留在结尾吧,毕竟放前言好像有点不符,毕竟文章重点也不是这。
有一段时间没有写博客了,还是得自我反省。反省的结果就是人喜欢偷懒,变得不会去对一段时间的学习内容进行一个总结,加之在整个写博客过程中需要梳理自己的思路,并且还要对自己写的内容要有一定的正确性判断,如此写博客的时间也随之变长。渐渐地,自己也放松了下来,而这样导致的最大问题就是自己的知识体系越来越碎,导致自己好像一直在学东西,但同时忘记的速度也在随之变快,导致自己无法去正确在实践当中去运用这些所学的技术以及知识点。
上次也说了,会总结设计模式的相关内容,但毕竟这种思想级别的东西,如果不通过理论加实践,是很难总结出来一些对自己有用的东西的,而且这些内容毕竟放到自己网上博客当中,那就不仅仅是自己在看了,我也不希望有一些和我一样的菜鸟看完之后被文章所误导。
Stream这个东西也算自己平时用的较多的一个东西,所以来进行一个总结。
文中如有错误,请各位大佬及时指出,并请不吝赐教。