
在我们日常开发中,经常会遇到一些烦人的数据关联和转换问题,比如典型的:
- 对象属性中个有字典 id,需要获取对应字典值并填充到对象中;
- 对象属性中有个外键,需要关联查询对应的数据库表实体,并获取其中的指定属性填充到对象中;
- 对象属性中有个枚举,需要将枚举中的指定属性填充到对象中;
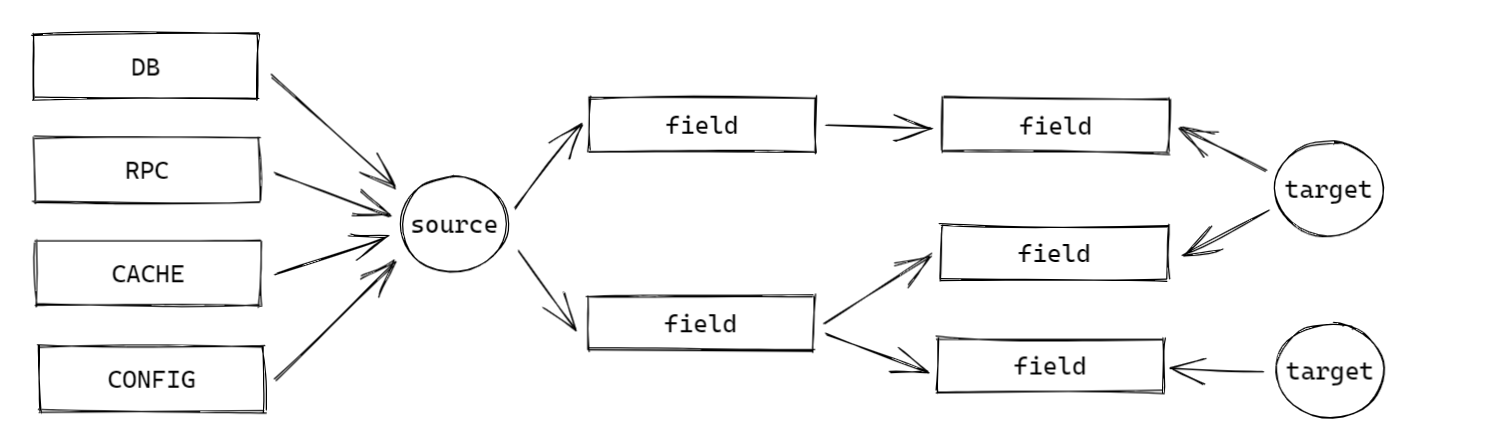
实际场景中这种联查的需求可能远远不止这些,这个问题的核心有三点:
- 填充的数据源是不确定的:可能是来自于 RPC 接口,可能是枚举类,也可能是数据库里的配置表,甚至是配置文件;
- 填充对象是不确定的:可能是普通的对象,但是也可能是 Collection 集合,或者 Map 集合,甚至可能是个 JsonNode,或者有一个嵌套结构;
- 填充的字段的不确定的:同样的数据源,但是可能这个接口返回的对象只需要填其中的一个字段,但是另一个接口需要填另外的两个字段;
基于上述三点,我们在日常场景中很容易遇到下图的情况:
本文将推荐一个基于 spring 的工具类库 crane,它被设计用来通过类似 MapStruts 的注解配置,完成这种麻烦的关联数据填充/转换操作的处理。
仓库地址:https://gitee.com/CreateSequence/crane
文档:https://gitee.com/CreateSequence/crane/wikis/pages
一、crane 是用来做什么的? 1、举个例子在开始前,我们先举个例子,假如我们有一个实体类 PersonVO 与 PersonDO:
@Data
public class PersonVO {
private Integer id;
private String personName;
}
@Data
public class PersonDO {
private Integer id;
private String name;
}
然后手头有一批待处理的 PersonVO 对象,我们需要从 PersonService 中根据 PersonVO.id 获取 PersonDO 集合,然后最后把 PersonDO.name 回填到 PersonVO.personName 中:
List<PersonVO> targets = new ArrayList<>;
// 对targets按id分组
Map<Integer, PersonVO> targetMap = new HashMap<>();
targets.forEach(t -> targetMap.put(t.getId(), t));
// 对sources按id分组
List<PersonDO> sources = personService.getByIds(targetMap.keySet());
Map<Integer, PersonDO> sourcesMap = new HashMap<>();
sources.forEach(s -> sourcesMap.put(s.getId(), s));
// 填充属性
targets.forEach((pid, target) -> {
PersonDO source = sourcesMap.get(pid);
if(source != null) {
target.setPersonName(source.getName())
}
})
总结一下,如果我们要手动处理,则无论如何避免不了四个步骤:
- 从目标对象中拿到 key 值;
- 根据 key 值从接口或者方法获得 key 值对应的数据源;
- 将数据源根据 key 值分组;
- 遍历目标对象,根据 key 值获取到对应的数据源,然后根据根据需要挨个 set 数据源的属性值;
针对上述的情况,假如使用 crane ,则我们可以这么做:
第一步,为被填充的 PersonVO 添加注解,配置字段:
@Data
public class PersonVO {
@AssembleMethodSource(namespace = "person", props = @Prop(src = "name", ref = "personName"))
private Integer id;
private String personName;
}
第二步,在提供数据源的 PersonService 中为 getByIds 方法也添加一个注解,配置数据源:
public class PersonService {
@MethodSourceBean.Mehtod(namespace = "person", sourceType = PersonDO.class, sourceKey = "id")
public List<PersonDO> getByIds(Set<Integer> ids) {
// return somthing......
}
}
第三步,使用 crane 提供的 OperateTemplate 辅助类在代码里完成填充:
List<PersonVO> targets = new ArrayList<>;
operateTemplate.process(targets);
或者直接在方法注解上添加一个注解,返回值将在切面中自动填充:
@ProcessResult(PersonVO.class)
public List<PersonVO> getPersonVO() {
// return PersonVO list......
}
相比起纯手工填充,crane 带来的好处是显而易见的,PersonService 中用一个注解配置好了数据源后,就可以在任何需要的实体类上用一行注解搞定填充字段的需求。
当然,示例中原始的手动填充的写法仍然有很多优化的余地。不过对应的, crane 的功能也不仅只有这些,crane 还支持配置更多的数据源,不仅是接口,还能是本地缓存,枚举;关于 key 的映射关系,不止提供示例中的一对一,还支持一对多;而其中的字段映射,也支持更多的玩法,这些都会在下文一一介绍。
二、如何引入crane 依赖于 springboot 环境,假如你是 springboot 项目,则只需要引入依赖:
<dependency>
<groupId>top.xiajibagao</groupId>
<artifactId>crane-spring-boot-starter</artifactId>
<version>${last-version}</version>
</dependency>
last-version 则是 crane 的版本号,截止至本文发布时,crane 的最新版本是 0.5.7。
然后在启动类添加 @EnableCrane 注解启用配置:
@EnableCrane
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
即可使用 crane 的全部功能。
三、配置使用字段配置是 crane 最核心的配置,它一般由三部分组成:
- 指定的 key 值字段;
- 要使用的数据源容器;
- 数据源与对象中字段的映射配置;
这对上述三点,crane 的最常见的写如下:
public class UserVO {
@Assemble(
container = UserContainer.class, // 根据userId的值去UserContainer获取数据源
props = { @Prop(src = "name", ref = "userName") } // 获取到数据源对象后,再把数据源对象User的name字段值映射到UserVO的userName上
)
private Integer userId; // 注解在userId上,则userId就是key字段,他的值就是key值
private String userName;
}
容器是另一部分内容,将在后文详细的介绍,这里我们先简单理解为根据 key 值获取数据源的地方。
从注解的字段获得 key 值,然后再将 key 值从 container 指定的容器中转换为对应数据源后,crane 会根据 props 配置自动的将数据源的字段映射到待处理对象上。
在 Assemble#props 中使用 @Prop 注解声明一对字段的映射关系。与 MapStruts 的 @Mapping 注解很像,@Prop#src 用于指定数据源字段,@Prop#ref 指定引用字段,两者实际都允许为空。
不指定数据源字段
当不指定 src 时,即不指定数据源字段,此时填充使用的数据源就是数据源对象本身,比如:
public class UserVO {
@Assemble(
container = UserContainer.class,
props = @Prop(ref = "userInfo")
)
private Integer userId;
private User userInfo;
}
该操作将直接把作为数据源对象的 User 实例直接填充至 UserVO.userInfo 中。
不指定引用字段
当不指定 ref 时,crane 会认为引用字段就是 key 字段,比如:
public class UserVO {
@Assemble(
container = UserContainer.class,
props = @Prop(src = "age")
)
private Integer userAge;
}
假如此时 UserVO.userAge 实际对应的值是 User.id ,则根据 key 值从容器中获取了数据源对象 User 后,此处 userAge 将被替换为 User.age 的值。
不指定任何字段
不指定任何字段,效果等同于将 key 字段值替换为对应数据源对象。
比如,我们有一个特定的容器 EvaluationContainer,他允许将分数的转为评价,比如 90 =》优、80 =》 良......则我们可以有:
public class UserVO {
@Assemble(container = EvaluationContainer.class)
private String score;
}
执行操作后,score 会被转为对应的“优”,“良”......评价。
2、特殊类型的字段映射crane 还支持处理一些特别的数据类型的字段映射,比如集合、枚举或者一些基本数据源类型,这里以常见的 Collection 集合为例:
比如,假设我们现在有一个根据 部门 id 查询员工对象集合 EmpUser 的容器 EmpContainer,现在我们需要根据 DeptVO.id 填充该部门下全部员工的姓名,则有配置:
public class DeptVO {
@Assemble(container = EmpContainer.class, props = @prop(src = "name", ref = "userNames"))
private Integer id;
private List<String> userNames;
}
根据 DeptVO.deptId 从容器中获得了 List<EmpUser>,然后 crane 会遍历元素,尝试从元素中取出每一个 EmpUser.name,然后组装成新的集合作为数据源。
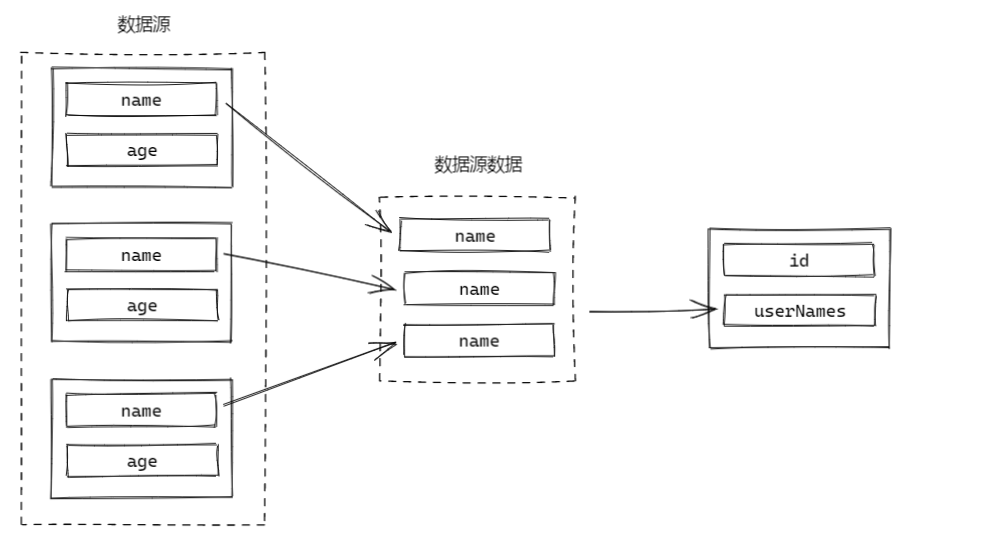
实际上,这样的操作也适用于数组。
其余数据类型的处理方式具体可以参见文档。
3、将字段映射配置抽离为模板有时候,尤其对象的字段大多都来自于关联查询时,我们需要在 key 字段上配置的注解就会变得及其臃肿,尤其是当有多个对象需要使用相同的配置时,这个情况会变得更加严重。
因此, crane 允许通过 @PropsTemplate将字段配置单独的分离到某个特定的类,然后再通过 @Assemble#propTemplates属性引用模板配置。
比如,针对一个通过 id 换取 User对象的 UserContainer 数据源容器,我们现在有这样一组配置:
public class UserVO {
@Assemble(container = UserContainer.class, props = {
@prop(src = "name", ref = "userName"),
@prop(src = "age", ref = "userAge"),
@prop(src = "sex", ref = "userSex")
})
private Integer id;
private String userName;
private Integer userAge;
private Integer userSex;
}
我们可以使用一个单独的配置类或者配置接口,去承担一部分繁琐的字段配置:
@PropsTemplate({
@prop(src = "name", ref = "userName"),
@prop(src = "age", ref = "userAge")
})
public interface UserPropTemplates {};
接着我们通过引入配置好的字段模板,即可以将原本的注解简化为:
public class UserVO {
@Assemble(container = UserContainer.class, propTemplates = { UserPropTemplates.class })
private Integer id;
private String userName;
private Integer userAge;
private Integer userSex;
}
一个操作配置允许引入多个模板,并且同时允许在模板的基础上继续通过 @Assemble#props 属性额外配置字段映射。
模板配置允许通过配置类的继承/实现关系传递,即在父类 A 通过 @PropTemplate 配置了字段映射,则在配置操作时引入子类 B 作为配置模板,将一并引入父类 A 上的配置。
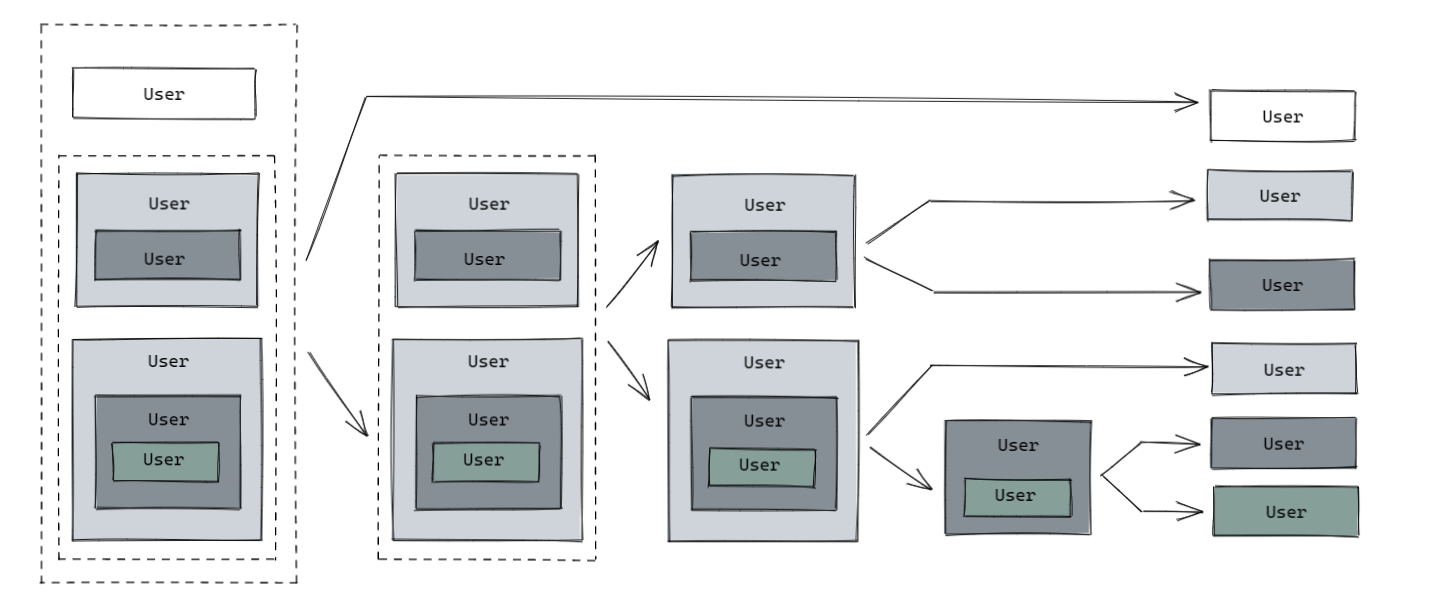
基本使用
在实际场景中,很容易出现这样的情况:
假如我们有一个 UserContainer,允许根据 User.id获得对应的名称,
public class User {
@Assemble(container = User.class, props = @Prop(ref = "userName"))
private Integer Id;
private String userName;
// 需要填充的嵌套集合
private List<User> subordinate;
}
我们有一个员工从属关系的树结构,我们手头持有一个根节点,但是实际上实例内部有一大堆嵌套的实例需要进行填充。
在 crane 中,通过 @Disassemble 注解标记嵌套字段,在处理时将按广度优先自动把他展开铺平后一并处理:
public class User {
@Assemble(container = User.class, props = @Prop(ref = "userName"))
private Integer id;
private String userName;
@Disassemble(User.class)
private List<User> subordinate;
}
crane 支持处理任意层级的单个对象、数组或Collection集合,也就是说,哪怕是这样的结构也是允许的:
private List<List<User[]>> subordinate;
动态类型
有时候不可避免的会存在无法确定字段类型的场景,比如典型的泛型:
public class ResultWrapper<T> {
@Disassemble
private T data;
}
在这种情况是无法直接确定 data 字段的类型的,此时使用 @Disassemble 注解可以不在 value 或者 targetClass 上直接指定具体的类型,crane 将在执行操作时通过反射获得 data 的实际类型,然后再通过指定的解析器去获取该类型的对应配置。
上述介绍都是基于类属性上的 @Assemble 和 @Disassemble 注解完成的,实际上 crane 也支持通过类上的 @Operations注解配置操作。
基本使用
比如,我们现有如下情况:
Child 继承了 Parent,但是在使用 Child 实例时又需要根据 id 填充 userName 和 userAge,此时并不方便直接修改 Parent:
public class Parent {
private String id;
private String userName;
private Integer userAge;
}
public class Child extends Parent {}
因此,我们允许在 Child 中如此配置:
@Operations(
assembles = @Assemble(key = "id", container = UserContainer.class, props = {
@prop(src = "name", ref = "userName"),
@prop(src = "age", ref = "userAge")
})
)
public class Child extends Parent {}
现在效果等同于在 Parent 类中直接注解:
public class Parent {
@Assemble(container = UserContainer.class, props = {
@prop(src = "name", ref = "userName"),
@prop(src = "age", ref = "userAge"),
@prop("user") // 将user对象直接映射到待处理对象的user字段上
})
private String id;
private String userName;
private Integer userAge;
}
这个配置仅对 Child 有效,而不会影响到 Parent。
key字段别名
由于配置允许通过继承父类或实现父接口获得,因此有可能会出现 key 字段名称不一致的情况,比如:
现有配置接口 FooInterface,指定了一个以 id 为 key 字段的装配操作,但是别名允许为 userId 或 uid:
@Operations(
assembles = @Assemble(key = "id", aliases = { "userId, uid" }, container = UserContainer.class, props = {
@prop(src = "name", ref = "userName"),
@prop(src = "age", ref = "userAge")
})
)
public interface FooInterface
现有 Child 实现了该接口,但是该类中只有 userId 字段而没有 id 字段,此时配置是照样生效的:
public class Foo implements FooInterface {
private Integer userId;
}
当一次操作中同时配置的 key 与多个别名,则将优先寻找 key 字段,若不存在则再根据顺序根据别名查找至少一个真实存在的别名字段。
配置继承与继承排除
@Operations 注解允许使用在普通类或者接口类上,并且允许通过实现与继承的方式传递配置。
假如现在存在以下类继承结构:
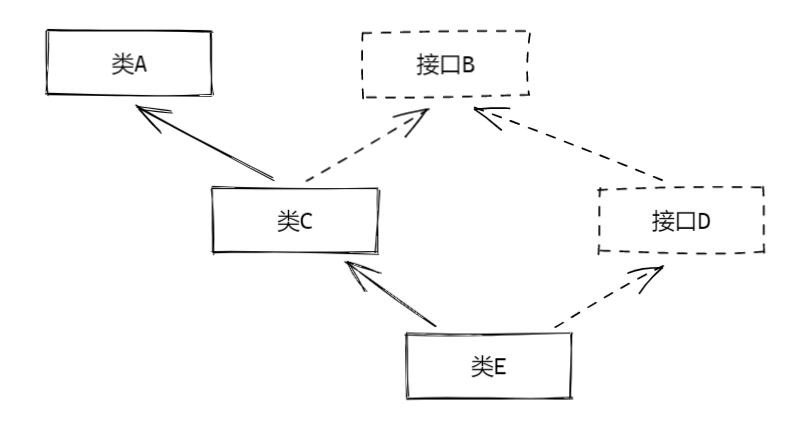
且上述两个接口与三个类上全都存在 @Operations 注解,此时在默认情况下,我们可以分析以下类 E 的配置情况:
- 不做任何特殊配置,类 E 将继承 A,B,C,D 上的全部注解配置;
- 若将 E 的
@Operations#enableExtend()属性改为 false,则类 E 将不继承任何父类或实现的接口上的配置,仅保留类 E 上的配置; - 若在
@Operation#extendExcludes()配置了排除继承,则:- 若排除接口 B,且类 E 上的
@Operations#enableExtend()属性为 true,此时类 E 将继承除接口 B 以外的所有配置,即获得 A,C,D,E 的配置; - 若排除类 C,且类 E 上的
@Operations#enableExtend()属性为 true,此时类 E 将不再继承类 C 上及其继承/实现树上的配置,但是仍然可以通过接口 D 获得接口 B 的配置,此时类 E 仅 B,D,E 三个类的配置; - 若类 C 上的
@Operations#enableExtend()属性为 false,且类 E 上的@Operations#enableExtend()属性为 true,则此时 E 将不会通过类 C 获得 A 与 B 的配置,因为 C 并没有继承父类和父接口的配置,此时 E 将拥有 B,C,D,E 四组配置;
- 若排除接口 B,且类 E 上的
参照 Spring Validation 的分组校验,crane 也提供了操作分组的功能,它允许以与 Validation 类似的方式,对装配操作进行分组,然后在操作的时候仅处理指定分组中的操作,比如:
@Assemble(
container = UserContainer.class,
groups = { UserGroup.class, AdminGroup.class }, // 当指定分组为 UserGroup 或 AdminGroup 时填充 userName 字段
props = @prop(src = "name", ref = "userName")
)
@Assemble(
container = UserContainer.class,
groups = { AdminGroup.class }, // 仅当指定分组为 AdminGroup 时填充 role 字段
props = @prop(src = "role", ref = "role")
)
private Integer id;
然后可以在相关的操作入口中指定本次操作的分组即可。
该功能一个比较典型的应用场景是一个接口同时对内对外,但是有些敏感的信息在对外的时候应该是不展示的,此时即可通过分组完成。
7、排序填充装配操作允许通过 spring 提供的 @Order 注解对装配操作的执行顺序进行排序,与 spring 排序规则一样,value 越小越靠前。
对字段配置排序
比如,现在我们有一个组合操作,即先根据 userId 获取 deptId,然后再根据 deptId 获取 empUsers:
public class UserVO {
@Order(0)
@Assemble(container = UserContainer.class, props = @Prop(src = "deptId", ref = "deptId"))
private Integer userId;
@Order(1)
@Assemble(container = EmpContainer.class, props = @Prop(ref = "empUsers"))
private Integer deptId;
private List<User> empUsers;
}
按上述配置,根据 userId 填充 deptId 的操作将会优先执行,然后才会执行根据 deptId 填充 empUsers字段。
对类配置排序
当使用类注解 @Operations 配置操作时,@Order 注解只能加在所配置的类上,同一个类上声明的装配操作优先级都与该注解一致,也就说,使用 @Operations时,只支持不同类上的操作配置的排序,不支持同一类上的操作排序。
比如:
@Order(0)
@Operations(assembles = @Assemble(container = UserContainer.class, props = @Prop(src = "deptId", ref = "deptId")))
public interface AssembleDeptConfig {}
@Order(1)
@Operations(assembles = @Assemble(container = EmpContainer.class, props = @Prop(ref = "empUsers")))
public interface AssembleEmpConfig {}
@Operations(enableExtend = true)
public class UserVO implements AssembleEmpConfig, AssembleDeptConfig {
private Integer userId;
private Integer deptId;
private List<User> empUsers;
}
这种情况下,AssembleDeptConfig 上的操作配置就会优先于 AssembleEmpConfig 执行。
crane 允许在通过 @Prop 注解配置字段映射时,使用 @Prop#exp 和 @Prop#expType 配置 SpEL 表达式,然后利用表达式从容器中获取的原始的数据源进行预处理。
比如我们在字段配置一章中提到过的内省容器。通过内省容器,我们可以获取到待处理对象本身,然后我们先获取待处理对象的userName字段值,然后根据性别动态的将其替换为原值+“先生/女生”:
@Assemble(
container = IntrospectContainer.class, props = @Prop(
ref = "userName",
exp = "sex == 1 ? #source.name + '先生' : #source.name + '女士'", // 根据性别,在name后追加“先生”或者“女士”
expType = String.class // 表达式返回值为String类型
)
)
private String sex;
private String name;
根据 sex字段从容器中获取的数据源,将先经过表达式的处理,然后将返回指定类型的结果,这个结果将作为新的数据源参与后续处理。
表达式上下文中默认注册了以下变量,允许直接在表达式中引用:
#source:原始数据源对象;#target:待处理对象;#key:key字段的值;#src:@Prop#src指定的参数值;#ref:@Prop#ref指定的参数值;
若有需要,也可以自行注册 ExpressionPreprocessingInterceptor.ContextFactory,在 SpEL 表达式上下文中注册更多变量和方法。
crane 深度结合的 spring 的提供的元注解机制,用户可以基于已有注解,自由的 diy 新注解以更进一步的简化开发。
首先简单的介绍一下 spring 的元注解机制。在 java 中,元注解指能用在注解上的注解,由于 java 的注解本身不支持继承,因此 spring 借助 AnnotationElementUtils 等工具类对 java 的元注解机制进行了扩展,实现了一套类似继承的注解组合机制,即 A 注解用在了注解 B 上时,注解 B 也可以被认为是一个特殊的 A 注解。
在 crane 中,允许被这样作为元注解使用的注解皆以 @MateAnnotation 标记。
假设现在存在有如下字段配置:
@Assemble(container = UserContainer.class, props = {
@prop(src = "name", ref = "userName"),
@prop(src = "age", ref = "userAge")
})
private Integer id;
我们可以上述 @Assemble 配置作为元注解,创建一个 @AssembleUser 注解:
@Assemble(container = UserContainer.class, props = {
@prop(src = "name", ref = "userName"),
@prop(src = "age", ref = "userAge")
})
@Target({ElementType.FIELD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface AssembleUser {}
然后将原本的配置替换为:
@AssembleUser
private Integer id;
即可实现与之前完全一样的效果。
四、数据源在 crane 中,任何将能够将 key 转换为对应的数据源的东西都可以作为容器,crane 提供了五个默认的容器实现,它们可以覆盖绝大部分的场景下的数据源:
- 键值对缓存:对应容器
KeyValueContainer,允许根据 namesapce 和 key 注册和获取任何数据; - 枚举:对应容器
EnumDictContainer,允许向容器中注册枚举类,然后通过指定的 namesapce 和 key 获得对应的枚举实例; - 实例方法:对应容器
MethodContainer,允许通过注解简单配置,将任意对象实例的方法作为数据源,通过 namespace 和 key 直接调用方法获取填充数据。适用于任何基于接口或本地方法的返回值进行填充的场景; - 内省容器:对应容器
BeanIntrospectContainer和KeyIntrospectContainer,允许直接将当前填充的对象作为数据源。适用于一些字段同步的场景;
接下来我们看看怎么使用。
1、将键值对缓存作为数据源键值对容器KeyValueContainer基于一个双重 Map 集合实现,本质上是一个基于本地缓存的数据源。在使用前,我们需要在容器中注册键值对,然后在字段注解上通过 namespace 与 key 进行引用。
比如,现有一个很典型的性别字典项:
Map<Integer, Object> gender = new HashMap<>();
gender.put(0, "女");
gender.put(1, "男");
keyValueContainer.register("sex", gender);
然后再在待处理对象中引用:
@Assemble(
container = keyValueContainer.class, // 指定使用键值对容器
namespace = "sex", // namespace为上文指定的sex
props = @Prop("sexName") // 从命名空间sex中根据sex字段值获取对应的value,并填充到sexName字段
)
private Integer sex;
private String sexName;
也可以使用 @AssembleKV 简化写法:
@AssembleKV(namespace = "sex", props = @Prop("sexName"))
private Integer sex;
private String sexName;
枚举容器EnumDictContainer用于处理枚举类型的数据源。与键值对一样,使用前我们需要先向容器注册要使用的枚举。
注册枚举
举个例子,我们手头有个 Gender 枚举:
@Data
@RequiredArgsConstructor
public enum Gender {
MALE(1, "男"),
FEMALE(0, "女");
private final Integer id;
private final String desc;
}
则可以按如下方法注册:
// namespace为gender,并且以枚举项的id属性作为key值
enumDictContainer.register(Gender.class, "gender", Gender::id);
// namespace为Gender类的非全限定名Gender,并且以枚举项的 Enum#name() 返回值作为key值
enumDictContainer.register(Gender.class);
基于注解注册
当然,如果觉得手动指定 namespace 和 key 麻烦,也可以通过注解完成,现在我们为 Gender 枚举类添加注解:
@EnumDict.Item(typeName = "gender", itemNameProperty = "id") // 指定namespace为gender,然后以id的值作为key
@Data
@RequiredArgsConstructor
public enum Gender {
MALE(1, "男"),
FEMALE(0, "女");
private final Integer id;
private final String desc;
}
然后再在容器中注册,就会自动根据类上的注解获取 namespace 和枚举实例的 key 值了:
enumDictContainer.register(Gender.class);
使用
当我们将枚举注册到枚举容器后,使用时仅需在 @Assemble注解中引用即可:
@Assemble(
container = EnumDictContainer.class, // 指定使用枚举容器
namespace = "gender", // namespace为上文指定的gender
props = @Prop(src = "name", ref = "genderName") // 获取Gender枚举中的name字段值,并填充到genderName字段
)
private Integer gender;
private String genderName;
注册后的枚举会被解析为 BeanMap 并缓存,我们可以像处理对象一样简单的通过属性名获取对应的值。
也可以用 @AssembleEnum 注解简化写法:
@AssembleEnum(namespace = "gender", props = @Prop(src = "name", ref = "genderName"))
private Integer gender;
private String genderName;
方法容器MethodContainer是基于 namespace 隔离,将各个类实例中的方法作为数据源的容器。
在使用方法容器之前,我们需要先使用 @MethodSourceBean.Method注解作为数据源的方法,然后再使用@MethodSourceBean注解该方法所在的类实例。
注册方法
比如,我们需要将一个根据用户 id 批量查询用户对象的接口方法作为数据源:
@MethodSourceBean
public class UserService {
// 该方法对应的命名空间为user,然后指定返回值类型为User.class, key字段为id
@MethodSourceBean.Mehtod(namespace = "user", sourceType = User.class, sourceKey = "id")
public List<User> getByIds(List<Integer> ids) {
// 返回user对象集合
}
}
当然,如果这个方法来自父类,无法显式的使用注解声明数据源方法,也允许通过类注解声明:
@ContainerMethodBean(
@ContainerMethodBean.Method(namespace = "user", name = "getByIds", sourceType = User.class, sourceKey = "id")
)
public class UserService extend BaseService<User> {}
当项目启动时,crane 将从 Spring 容器中获取被 @ContainerMethodBean注解的类,并获取其中被注解的方法,并根据指定的 namespace 注册到方法容器对应的命名空间。
使用
当我们使用时,与其他容器保持一致:
@Assemble(
container = MethodSourceContainer.class, // 指定使用键值对容器
namespace = "user", // namespace为上文指定的user
props = @Prop("userBean") // 从命名空间user中获取方法getByIds,然后将userId对应的user对象填充到userBean字段中
)
private Integer userId;
private User userBean;
当然,也可以通过 @AssembleMethodSource 注解简化写法:
@MethodSource(namespace = "user", props = @Prop("userBean"))
private Integer userId;
private User userBean;
多对一
容器总是默认方法返回的集合中的对象与 key 字段的值是一对一的,但是也可以调整为一对多。
比如我们现在有一批待处理的 Classes 对象,需要根据 Classes#id字段批量获取Student对象,然后根据Student#classesId字段填充到对应的 Classes 对象中:
@MethodSourceBean.Mehtod(
namespace = "student", sourceType = Student.class, sourceKey = "classesId",
mappingType = MappingType.ONE_TO_MORE // 声明待处理对象跟Student通过classesId构成一对多关系
)
public List<Student> listIds(List<Integer> classesIds) {
// 查询Student对象
}
然后在待处理对象中引用:
@Assemble(
container = MethodSourceContainer.class,
namespace = "student",
props = @Prop("students")
)
private Integer classesId;
private List<Student> students;
有些时候,我们会有一些字段同步的需求,待处理对象内省容器 BeanIntrospectContainer 就是用来干这件事的,不仅如此,它适用于任何需要对待处理对象本身进行处理的情况。
待处理对象内省容器BeanIntrospectContainer的数据源就是待处理对象本身,它用于需要对待处理对象本身进行处理的情况。
比如简单的同步一下字段:
// 将对象中的name字段的值同步到userName字段上
@Assemble(container = BeanIntrospectContainer.class, props = @Prop("userName")
private String name;
private String userName;
也可以用于处理集合取值:
// 将对象中的users集合中全部name字段的值同步到userNames字段上
@Assemble(container = BeanIntrospectContainer.class, props = @Prop(src = "name", ref = "userNames"))
private List<User> users;
private List<String> userNames;
或者配合 SpEL 预处理数据源的功能处理一些字段:
@Assemble(
container = BeanIntrospectContainer.class, props = @Prop(
ref = "name",
exp = "sex == 1 ? #source.name + '先生' : #source.name + '女士'", // 根据性别,在name后追加“先生”或者“女士”
expType = String.class
)
)
private String sex;
private String name;
也提供了 @AssembleBeanIntrospect 注解,效果等同于:
@Assemble(container = BeanIntrospectContainer.class)
待处理 key 字段内省容器KeyIntrospectContainer 和 BeanIntrospectContainer 基本一致,主要的不同在于 KeyIntrospectContainer 的数据源是待处理对象本此操作所对应的 key 字段值。
除了跟 BeanIntrospectContainer 差不多的用法以外,由于操作的数据源对象本身变为了 key 字段的值,因此也有了一些特别的用处:
// 将Type枚举的desc字段赋值给typeName字段
@Assemble(container = KeyIntrospectContainer.class, props = @Prop(src = "desc", ref = "typeName"))
private TypeEnum type;
private String typeName;
如果是 JsonNode,还可以这样:
// 使用type字段对应枚举的desc字段替换其原本的值
@Assemble(container = KeyIntrospectContainer.class, props = @Prop(src = "desc"))
private TypeEnum type;
默认提供了 @AssembleKeyIntrospect 注解,效果等同于
@Assemble(container = KeyIntrospectContainer.class)
完成了数据源和字段的配置以后,就需要在代码中执行填充的操作。crane 总共提供了三个入口:
- 在方法上添加
@ProcessResult注解,然后通过 AOP 自动对方法返回值进行填充; - 在
ObjectMapper中注册DynamicJsonNodeModule模块,然后使用该ObjectMapper实例序列号对象时自动填充; - 使用 crane 注册到 spring 容器中的
OperateTemplate手动的调用;
第二种会在下一节介绍,而第三种没啥特别的,这里主要介绍一些基于切面的方法返回值自动填充。
使用
默认情况下,crane 会自动把切面注册到 spring 容器中,因此使用时,若方法所在类的实例已经被 spring 容器管理,则只需要在方法上添加注解就行了:
// 自动填充返回的 Classroom 对象
@ProcessResult(Classroom.class)
public Classroom getClassroom(Boolean isHandler) {
return new Classroom();
}
切面支持处理单个对象,一维对象数组与一维的对象 Collection 集合。
表达式校验
切面还允许根据 SpEL 表达式动态的判断本次方法调用是否需要对返回值进行处理:
@ProcessResult(
targetClass = Classroom.class
condition = "!#result.isEmpty && !#isHandle" // 当返回值为空集合,且isHandle参数不为true时才处理返回值
)
public List<Classroom> getClassroom(Boolean isHandle) {
return Collections.emptyList();
}
这里的 SpEL 表达式中默认可以通过 #参数名 的方式引用入参,或者通过 #result 的方式获取返回值。
自定义组件
此外,切面注解中还可以自行自定一些 crane 的组件和参数,包括且不局限与分组,执行器等:
@ProcessResult(
targetClass = Classroom.class,
executor = UnorderedOperationExecutor.class,
parser = BeanOperateConfigurationParser.class,
groups = { DefaultGroup.class }
)
public List<Classroom> getClassroom(Boolean isHandler) {
return Collections.emptyList();
}
不同的组件会产生不同的效果,比如 executor ,当指定为 AsyncUnorderedOperationExecutor.class 时 crane 会根据本次所有操作对应的容器的不同,异步的执行填充,而指定为 SequentialOperationExecutor 时将支持按顺序填充。
这里更多详细内容可以参考文档。
六、Json支持上述例子都以普通的 JavaBean 为例,实际上 crane 也支持直接处理 JsonNode。若要启用 Json 支持,则需要引入 crane-jackson-implement 模块,其余配置不需要调整。
<dependency>
<groupId>top.xiajibagao</groupId>
<artifactId>crane-jackson-implement</artifactId>
<version>${last-version}</version>
</dependency>
crane-jackson-implement 版本与 crane-spring-boot-starter 版本一致,截止本文发布时,版本号为 0.5.7。
配置 ObjectMapper
引入模块后 crane 将会自动向 spring 容器中注册必要的组件,包括 DynamicJsonNodeModule 模块,该模块是实现 JsonNode 填充的核心。用户可以自行指定该模块要注册到哪个 ObjectMapper 实例。
一般情况下,都会直接把该模块注册到 spring-web 提供的那个 ObjectMapper 中,也就是为 Controller 添加了 @RestController 注解、或者为方法添加 @ResponseBody 注解后,Controller 中接口返回值自动序列化时使用的 ObjectMapper。
比如,我们现在已经引入了 spring-web 模块,则可以在配置类中配置:
@Configuration
public class ExampleCraneJacksonConfig {
@Primary
@Bean
public ObjectMapper serializeObjectMapper(DynamicJsonNodeModule dynamicJsonNodeModule) {
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.registerModule(dynamicJsonNodeModule); // 注册动态json模块
return objectMapper;
}
}
配置字段操作
针对 JsonNode 的配置会跟普通的 JavaBean 有点区别。我们以一个普通的 JavaBean 配置为例:
public class Foo {
@Assemble(
container = UserContainer.class,
props = @prop(src = "name", ref = "userName")
)
private String id;
private String userName;
@Disassemble(Foo.class)
private List<Foo> foos;
}
首先,需要为序列化时进行数据填充的类添加 @ProcessJacksonNode 注解:
@ProcessJacksonNode
public class Foo {
......
}
然后,在 @Assemble 和 @Disassemble 指定使用 Jackson 的操