Hash 数据结构 使用 ziplist 当同时满足下面两个条件时,使用 ziplist 存储数据 元素个数少于512个 (hash-max-ziplist-entries: 512) 每个元素长度小于64字节 (hash-max-ziplist-value: 64) 不满足上面的条件
- 使用 ziplist
当同时满足下面两个条件时,使用 ziplist 存储数据- 元素个数少于512个 (hash-max-ziplist-entries: 512)
- 每个元素长度小于64字节 (hash-max-ziplist-value: 64)
- 不满足上面的条件, 使用 hashtable
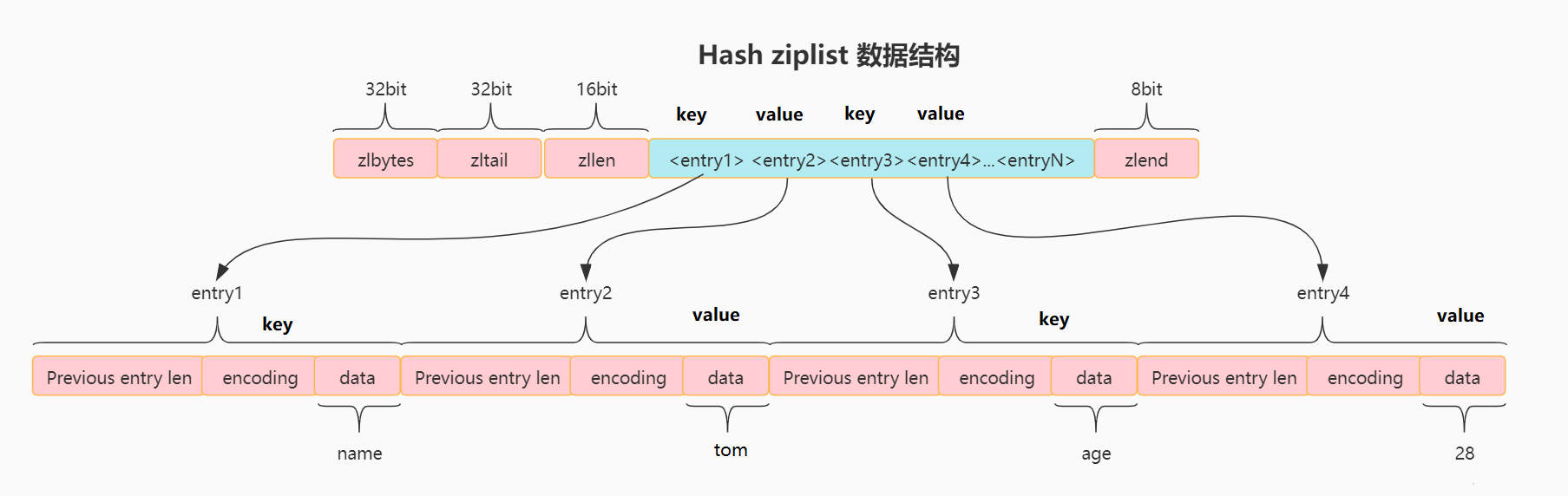
可以看到, 当hash以ziplist编码存储时,键值对依次按顺序存放在ziplist中,key在前,value在后.
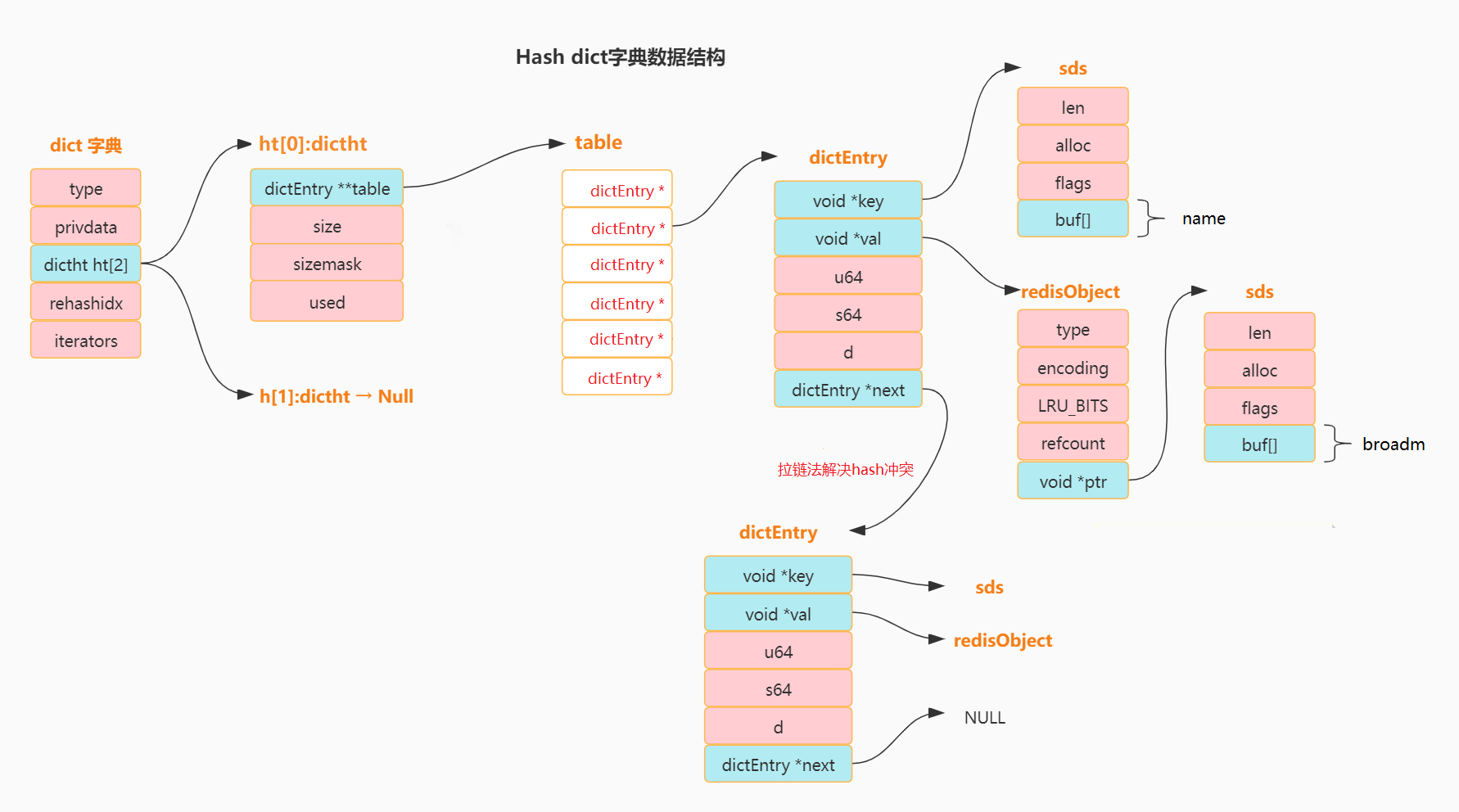
Hash使用 hashtable 图解 哈希表相关的数据结构//字典
typedef struct dict {
dictType *type; // 类型特定函数
void *privdata; // 私有数据
dictht ht[2]; // 每个字典使用两个哈希表,实现渐进式 rehash
int rehashidx; // rehash 索引,当 rehash 不在进行时,值为 -1
int iterators; // 目前正在运行的安全迭代器的数量
} dict;
//哈希表
typedef struct dictht {
dictEntry **table; // 哈希表数组
unsigned long size; // 哈希表大小
unsigned long sizemask; // 哈希表大小掩码,用于计算索引值, 总是等于 size - 1
unsigned long used; // 该哈希表已有节点的数量
} dictht;
//哈希表节点
typedef struct dictEntry {
void *key; // 键
union {
void *val; // 值, 正常是指向一个 redisObject
uint64_t u64;
int64_t s64;
} v;
struct dictEntry *next; // 指向下个哈希表节点,形成链表 (拉链法解决hash冲突)
} dictEntry;
当hashtable需要扩容时,redis使用渐进式rehash
- 为ht[1]分配空间,此时字典同时持有ht[0]和ht[1]
- 将rehashidx设为0,表示rehash正式开始
- 在rehash期间,每次对字典执行任意操作时,程序除了执行对应操作之外,还会顺带将ht[0]在rehashidx索引上的所有键值对rehash到ht[1],操作完后将rehashidx的值 + 1
- Redis本身也会有事件轮询,哪怕没有命令访问,也会通过轮询事件逐渐完成数据迁移
- 当rehashidx的值增加到 ht[0].size,此时ht[0]的所有键值对都已经迁移到ht[1]了。程序会把ht[1]赋值给ht[0],并重新在ht[1]上新建一个空表。将rehashidx重新置为-1,以此表示rehash完成
Hash的常用命令当存在超大的hashTable进行扩容时,如果不去渐进式扩容,单次扩容时间太长,扩容期间Redis服务不可用,将导致线程阻塞
- HSET key field value 将一个或多个field/value插入到哈希表中
- HGET key field 返回key中指定 field 的 value 值
- HKEYS key 返回哈希表 key 中的所有field
- HGETALL key 返回哈希表 key 中,所有的field和value
- HVALS key 返回哈希表 key 中的所有value
- HEXISTS key field 检查哈希表 key 中,field 是否存在
- HDEL key field 删除哈希表 key 中的一个或多个field
- HLEN key 返回哈希表 key 中field的数量
- HSETNX key field value :将哈希表 key 中的 field 的值设置为 value , 仅当 field 不存在时才会执行