本文首发于 Nebula Graph Community 公众号
本文整理自智联招聘资深工程师李世明在「智联招聘推荐场景应用」的实践分享

在讲具体的应用场景之前,我们先看下智联招聘搜索和推荐页面的截图。
这是一个简单的智联搜索页面,登录到智联招聘 App 的用户都能看到,但是这个页面背后涉及到的推荐、召回逻辑以及排序概念,是本文的重点。
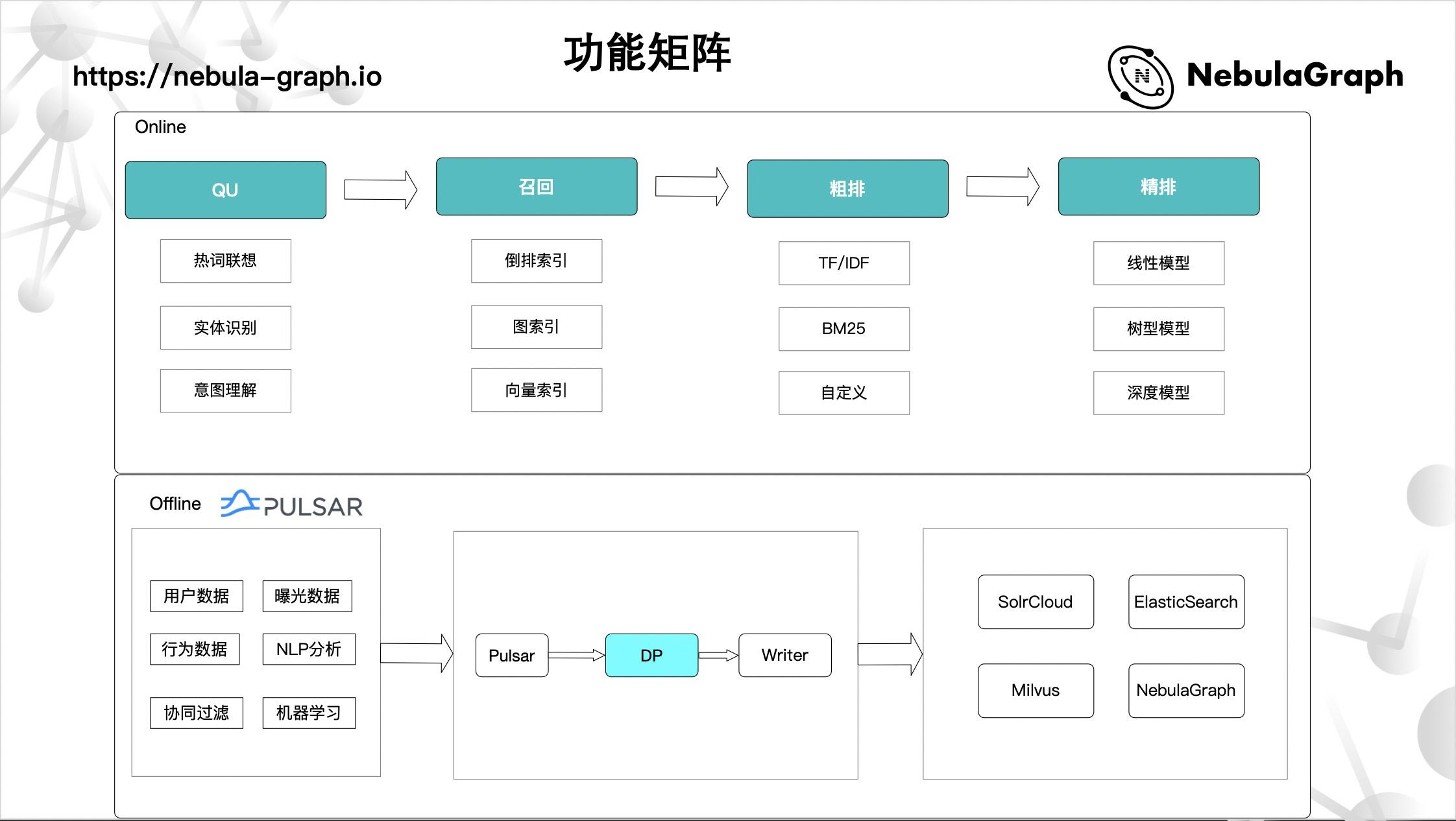
从功能上来说,从矩阵图我们可以了解到做搜索和推荐时,系统分为 Online 和 Offline 两个部分。
在 Online 部分,主要涉及到实时操作,例如:搜索某个关键词、实时展示个人推荐。而这些功能性操作需要其他功能支持,比如:热词联想,以及根据特定的输入进行实体识别、意图理解,或是个人用户画像的绘制。再下一步操作便是召回,利用倒排索引,根据文本、相似度匹配,以及引入 Nebula Graph 实现图索引、向量索引,都是为了解决召回问题。最后,便是搜索结果的展示——如何排序。这里会有个粗排,比如常见的排序模型 TF/IDF,BM25,向量的余弦相似 等召回引擎排序。粗排后面是精排,即:机器学习的排序,常见的有线性模型、树型模型、深度模型。
上述为在线 Online 流程,相对应的还有一套 Offline,离线流程。离线部分主要是整个业务的数据加工处理工作,把用户的相关行为,例如:数据采集、数据加工,再把数据最终写到召回引擎,像是上文提及过的倒排索引的 Solr 和 ES、图索引的 Nebula Graph 以及向量索引的 Milvus,以提供线上的召回能力。
线上架构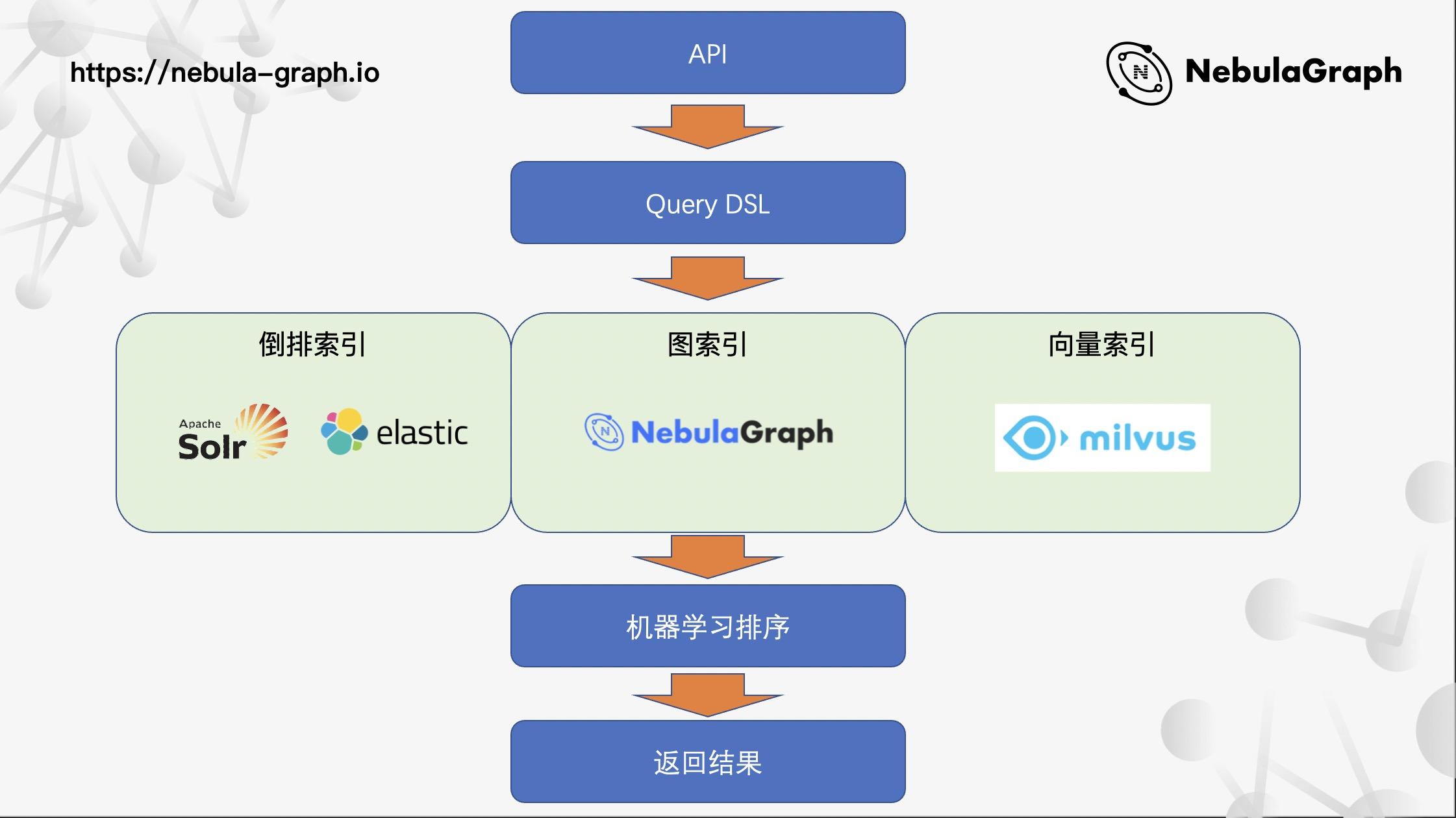
当一个用户点击了智联招聘的搜索按钮,会发生什么呢?如上图所示,经过一个 API 调用,再通过 Query DSL 的统一封装加工,再进入三路(之前提过的倒排索引、图索引和向量索引)召回,机器学习排序,最终将结果返回到前端进行展示。
离线架构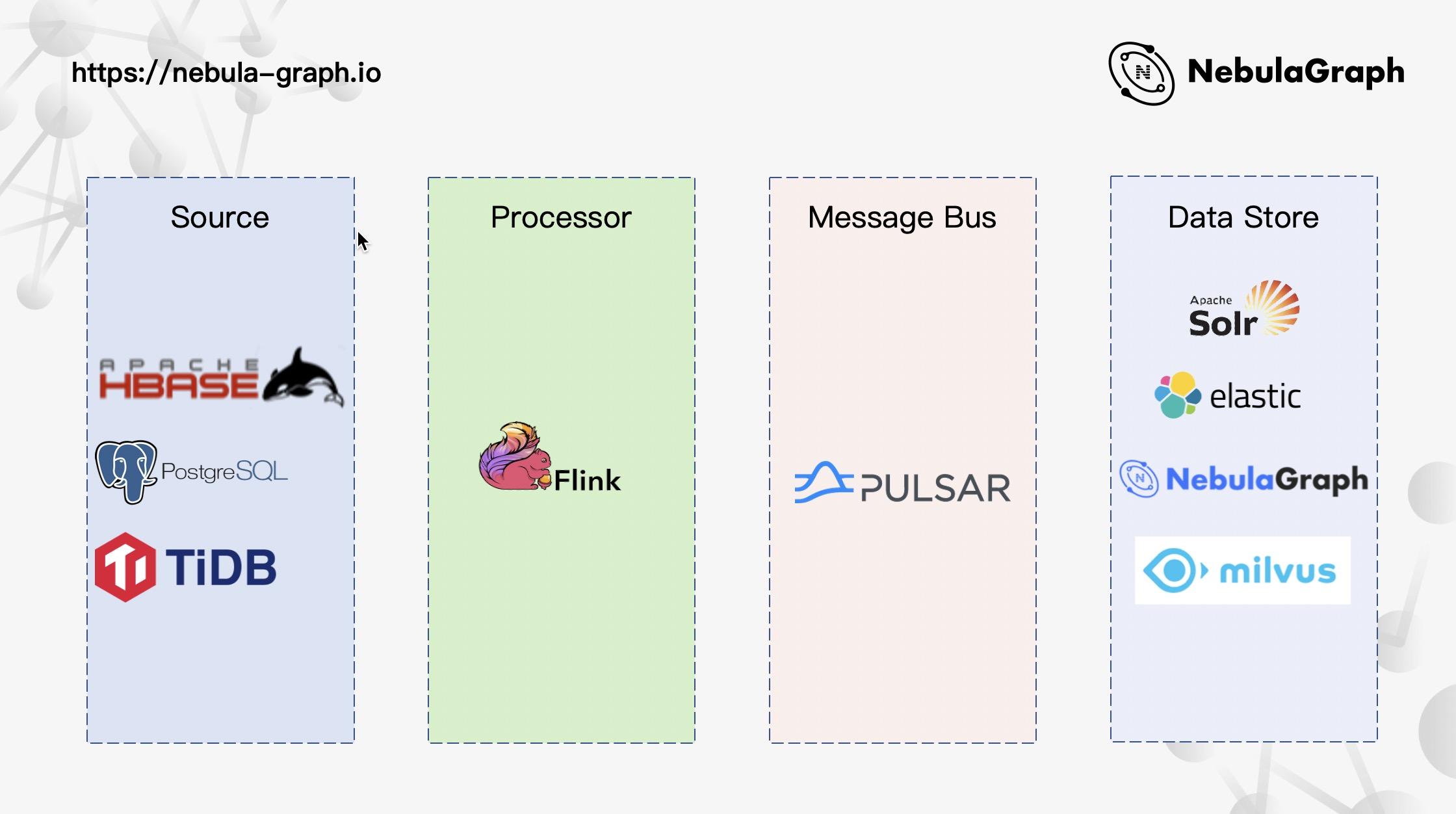
如同上面功能矩阵方面介绍的那般,离线部分主要是数据的加工处理,将诸如 HBase、关系型数据库 PostgreSQL、KV 数据库 TiDB 之类的数据平台通过数据链路进行加工,最终写入到数据存储层。
整体业务流程将在线和离线架构进行整合,下图细化了 API 请求的处理、缓存、分页、A/B Test、用户画像、Query Understanding、多路召回等流程。
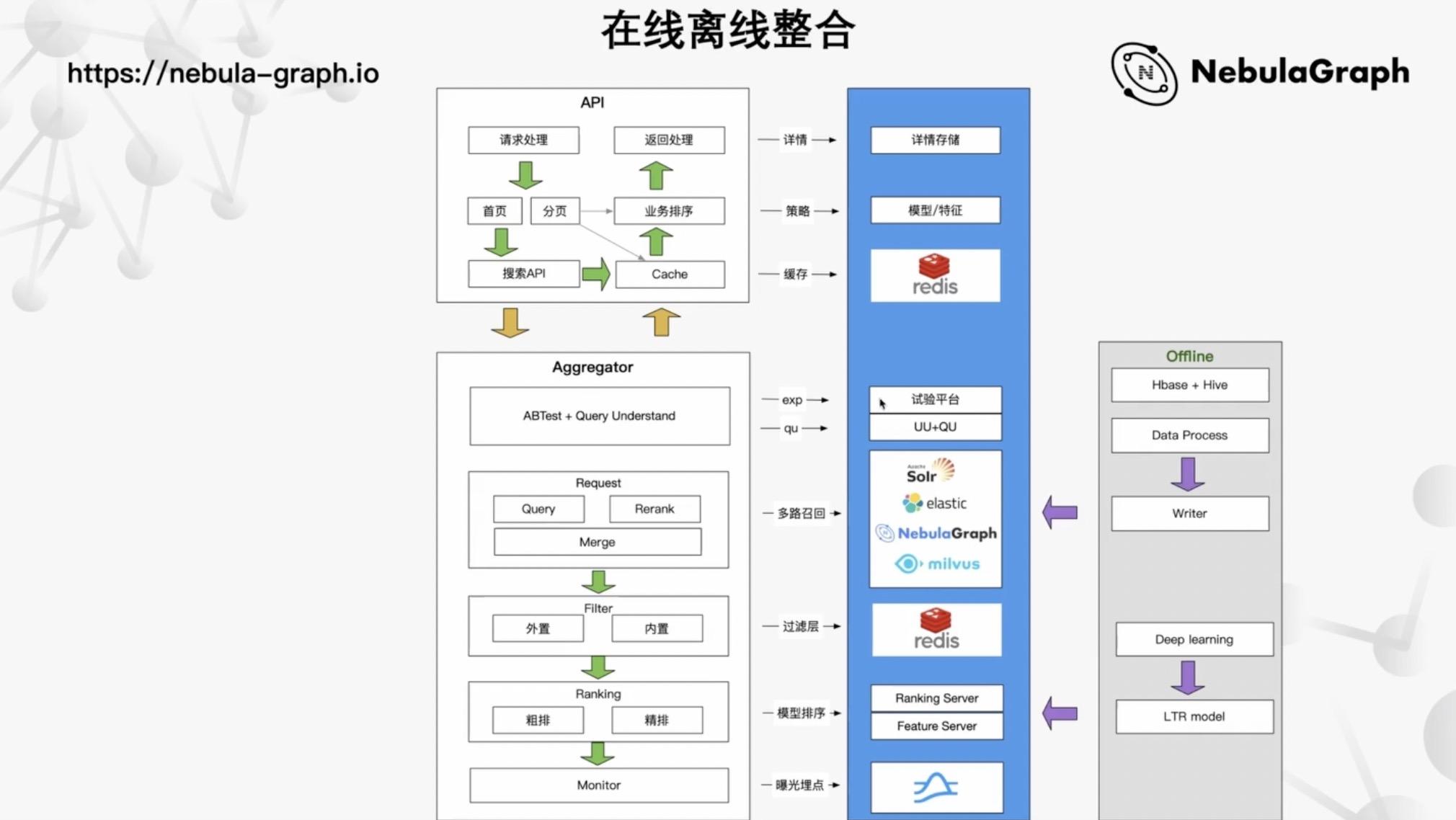
介绍了线上和离线的功能架构,现在来讲下智联招聘是如何支撑整个功能矩阵的。
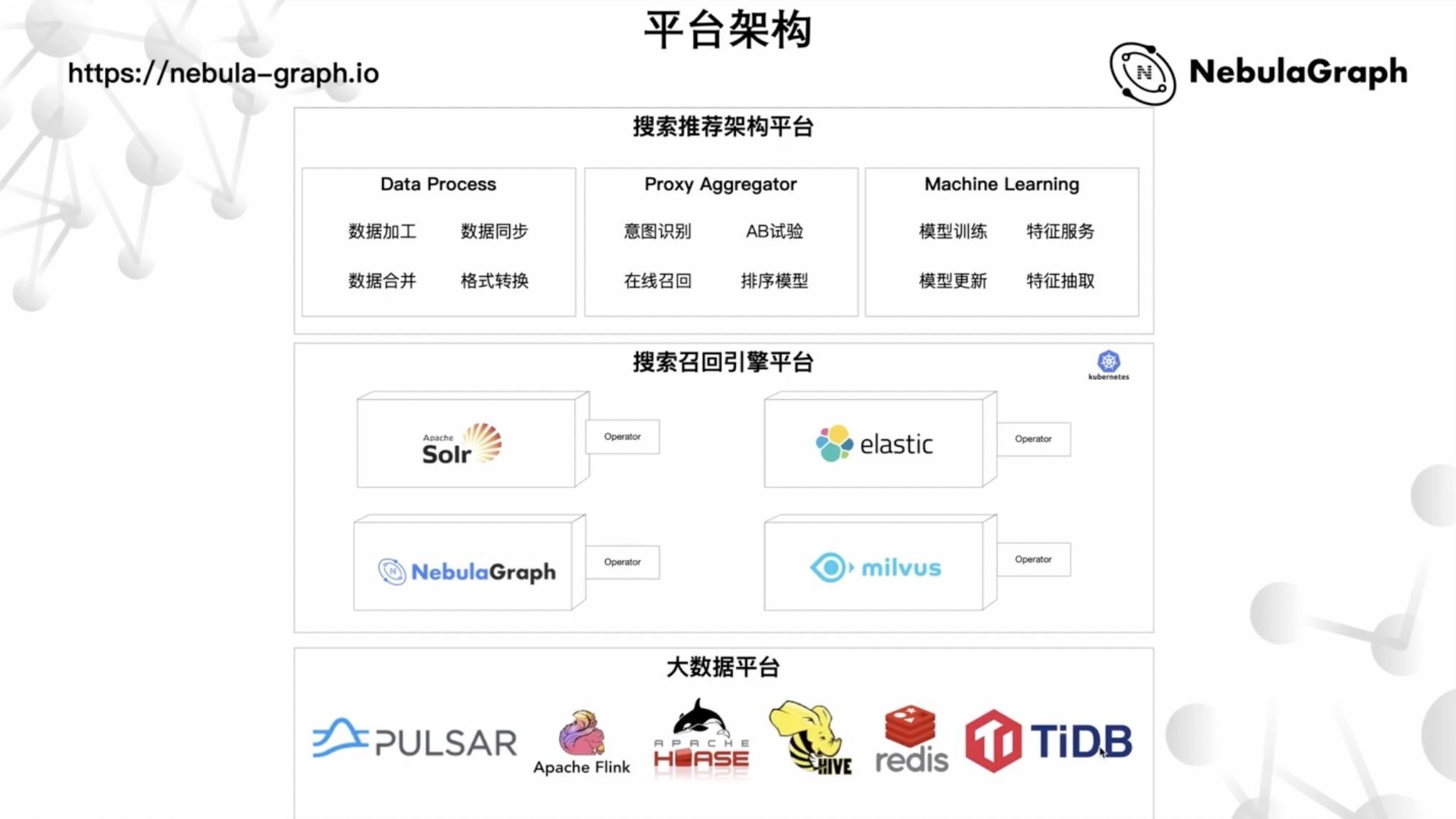
从底层来说,智联技术团队是通过构建了这三个平台来支撑整个功能矩阵的。
首先最上方就是我们整个的搜索推荐架构平台,分为数据处理、聚合层、机器学习三个模块。在数据处理模块,主要用来完成数据加工、数据同步、数据合并、格式转换等数据层事项;聚合层则处理意图识别、AB 测试、在线召回、排序模型;而机器学习模块,主要用来做特征加工、特征抽取、模型更新之类的事情。
在搜索推荐架构平台下方,便是搜索召回引擎,由 Solr、Elasticsearch、Nebula Graph、Milvus 组成,分别负责倒排索引、图索引和向量索引。
最下层,是大数据平台,对接 Pulsar、Flink、HBase、HIVE、Redis、TiDB 等数据源。
Nebula Graph 在推荐场景下的应用 智联的数据规模智联这边线上环境部署了 9 台高配物理机,机器配置的话 CPU 核数大概在 64~72,256G 左右的内存。每台机器部署 2 个 storaged 节点,一共有 18 个 storaged 节点,查询 graphd 和元数据 metad 节点分别部署了 3-5 个。线上环境目前有 2 个 namespace,一共 15 个分片,三副本模式。
而测试环境,采用了 K8s 部署,后续线上的部署也会慢慢变成 K8s 方式。
说完部署情况,再来讲下智联招聘这块的使用情况,目前是千万级别的点和十亿级别的边。线上运行的话,最高 QPS 是 1,000 以上;耗时 P99 在 50 ms 以下。
下图为智联自研的监控系统,用来看 Prometheus 的监控数据,查看节点状态、当前查询的 QPS 和耗时,还有更详细的 CPU 内存耗损等监控指标。

下面来简单介绍下业务场景
推荐场景下的协同过滤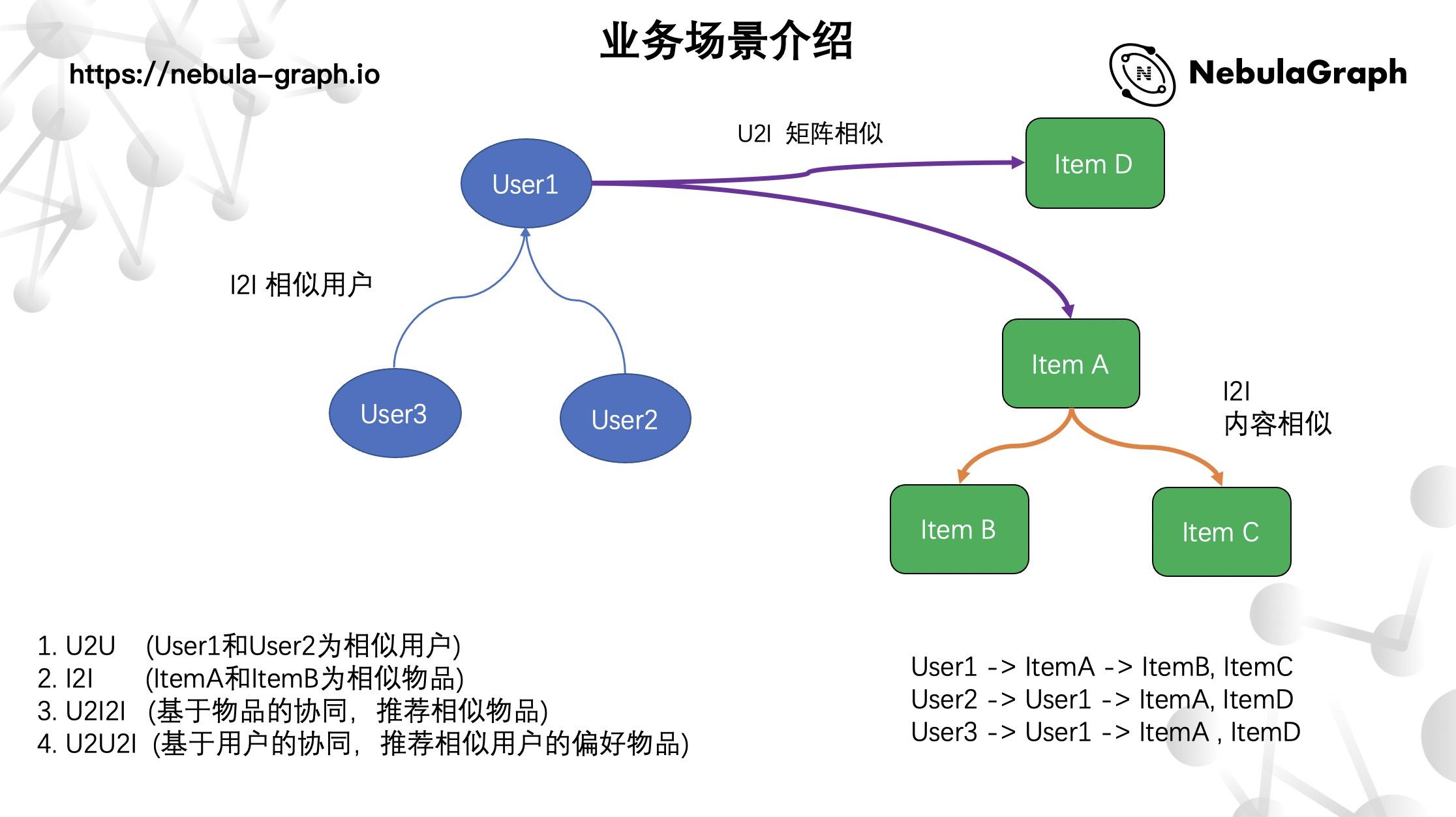
推荐场景下有个比较常见的业务是协同过滤,主要用来解决上图左下角的 4 个业务:
- U2U:user1 和 user2 为相似用户;
- I2I:itemA 和 itemB 为相似物品;
- U2I2I:基于物品的协同,推荐相似物品;
- U2U2I:基于用户的协同,推荐相似用户的偏好物品;
上面 U2U 是在创建 user to user 的某种关系,可能是矩阵(向量级别)相似,也可能是行为级别的相似。1. 和 2. 是基本的协同(相似性),把用户和用户、物品和物品建立好关系,基于这种基本协同再延伸出更复杂的关系,比如:通过物品的协同给用户推荐相似物品,或是根据用户的协同,推荐相似用户的偏好物品。简单来说,这个场景主要是实现用户通过某种关系,可得到相关物品的相似推荐或者是相似用户的关联物品推荐。
下面来分析一波这个场景
协同过滤的需求分析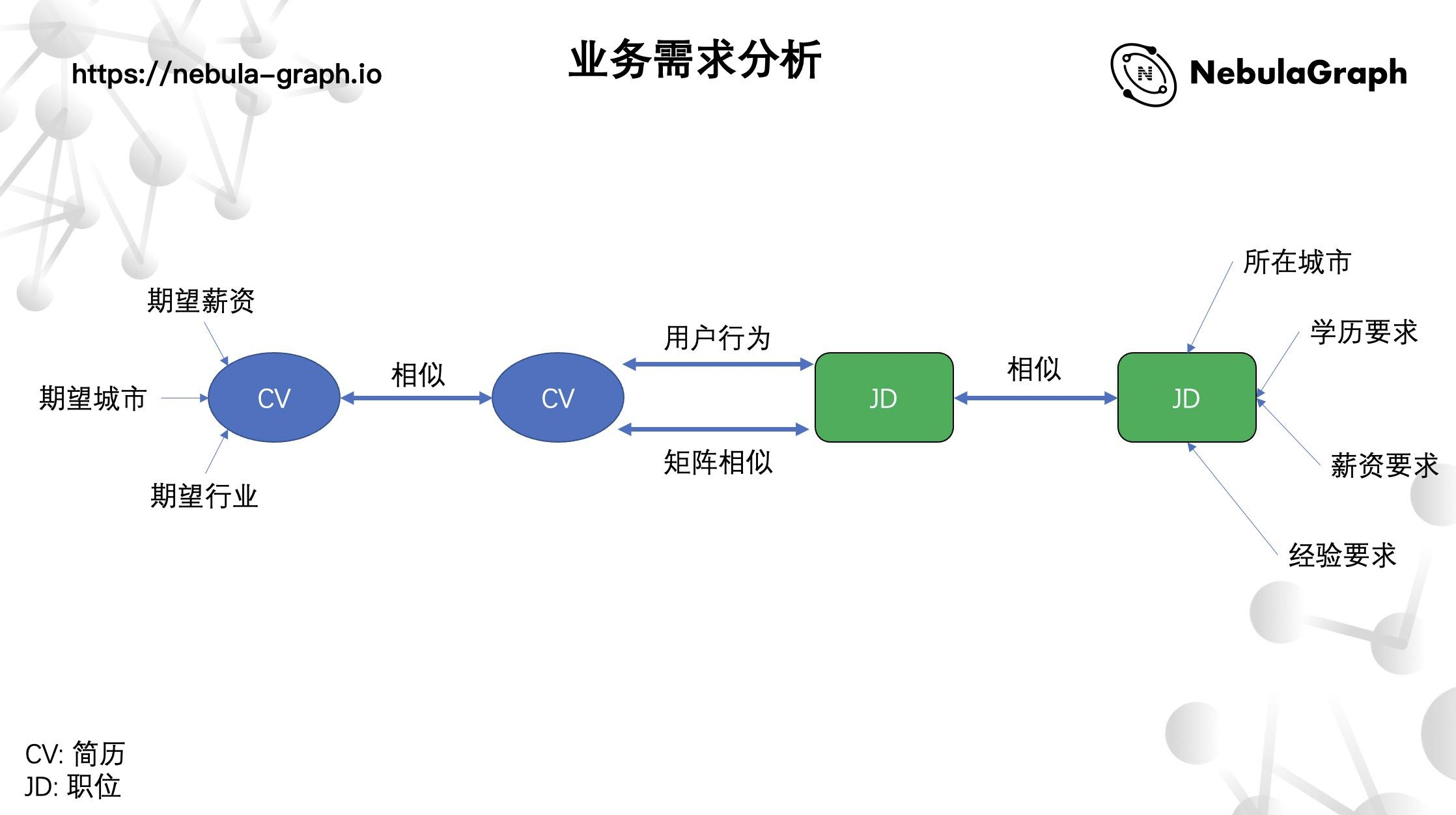
具体来说,招聘领域来说,CV(简历)和 JD(职位)之间存在关联关系,聚焦到上图的中间部分,CV 和 JD 之间存在用户行为和矩阵相似关系,像用户查看了某个职位、用户投递了某个职位,或者是企业端的 HR 浏览了某个简历这些用户行为,或者是基于某种算法,都会给 CV 和 JD 建立起某种关联。同时,还要创建 CV 和 CV 之间的联系,也就是上文说到的 U2U;JD 和 JD 之间的关系,就是上面的 I2I。关联创建之后,可以整点有意思的事情——通过用户 A 查看过 CV1(简历)推荐相似的 CV2(简历),用户 B 浏览过职位,也可以根据职位的相似性,给他推荐另外的 JD…这里再提下这个需求的“隐藏”重点,就是需要进行属性过滤。什么是属性过滤呢?系统会根据 CV 的相似度来推荐 CV,这里就要做相关的属性匹配了:基于期望城市、期望薪资、期望行业进行属性过滤。召回的实现一定要考虑上述因素,不能 CV1 的期望城市是北京,你推荐的相似 CV 期望城市却是厦门。
技术实现 原先的技术实现——Redis
智联这边最开始实现协同过滤的方式是用 Redis 将关系通过 kv 方式存储起来,方便进行查询。显而易见的是,这样操作是能带来一定的好处:
- 架构简单,能快速上线;
- Redis 使用门槛低;
- 技术相对成熟;
- Redis 因为是内存数据库的原因,很快,耗时低;
但,与此同时,也带来一些问题:
属性过滤实现不了,像上面说到的基于城市、薪资之类的属性过滤,使用 Redis 这套解决方案是实现不了的。举个例子,现在要给用户推 10 个相关职位,通过离线我们得到了 10 个相关职位,然后我们创建好了这个关联关系,但如果这时候用户修改了他的求职意向,或者是增加了更多的筛选条件,就需要在线来实时推荐,这种场景下是无法满足的。更不用提上面说到过的复杂的图关系,实际上这种查询用图来做的话,1 跳查询就能满足。
再尝试倒排索引实现——ES 和 Solr
因为智联在倒排索引这块有一定的积累,所以后面尝试了倒排索引的方式。基于 Lucene 角度,它有一个索引的概念。可以将关系保存为子索引 nested,然后过滤这块的话,子索引中存关系 ID,再通过 JOIN query 实现跨索引 JOIN,这样属性就可以通过 JOIN 方式进行过滤。这种形式相比较 Redis 实现的话,关系也能存上了,属性过滤也能实现。但实际开发过程中我们发现了一些问题:
- 不能支持大数据量存储,当关系很大时,相对应的单个倒排会特别大。对于 Lucene 来说它是标记删除,先将标记的删除了再插入新的,每次子索引都要重复该操作。
- 关系较多时 JOIN 性能不好,虽然实现了跨索引 JOIN 查询,但是它的性能并不好。
- 关系只能全量更新,其实设计跨索引时,我们设计的方案是单机跨索引 JOIN,都在一个分片里进行 JOIN 操作,但这种方案需要每个分片存放全量的 JOIN 索引数据。
- 使用资源较多,如果跨索引涉及到跨服务器的话,性能不会很好,想要调好性能就比较耗资源。
上图右侧是一个具体的实现实录,数据格式那边是关系的存储方式,再通过 JOIN JD 的数据进行属性过滤,这个方案最终虽然实现了功能但是没在线上运行。
图索引——Nebula Graph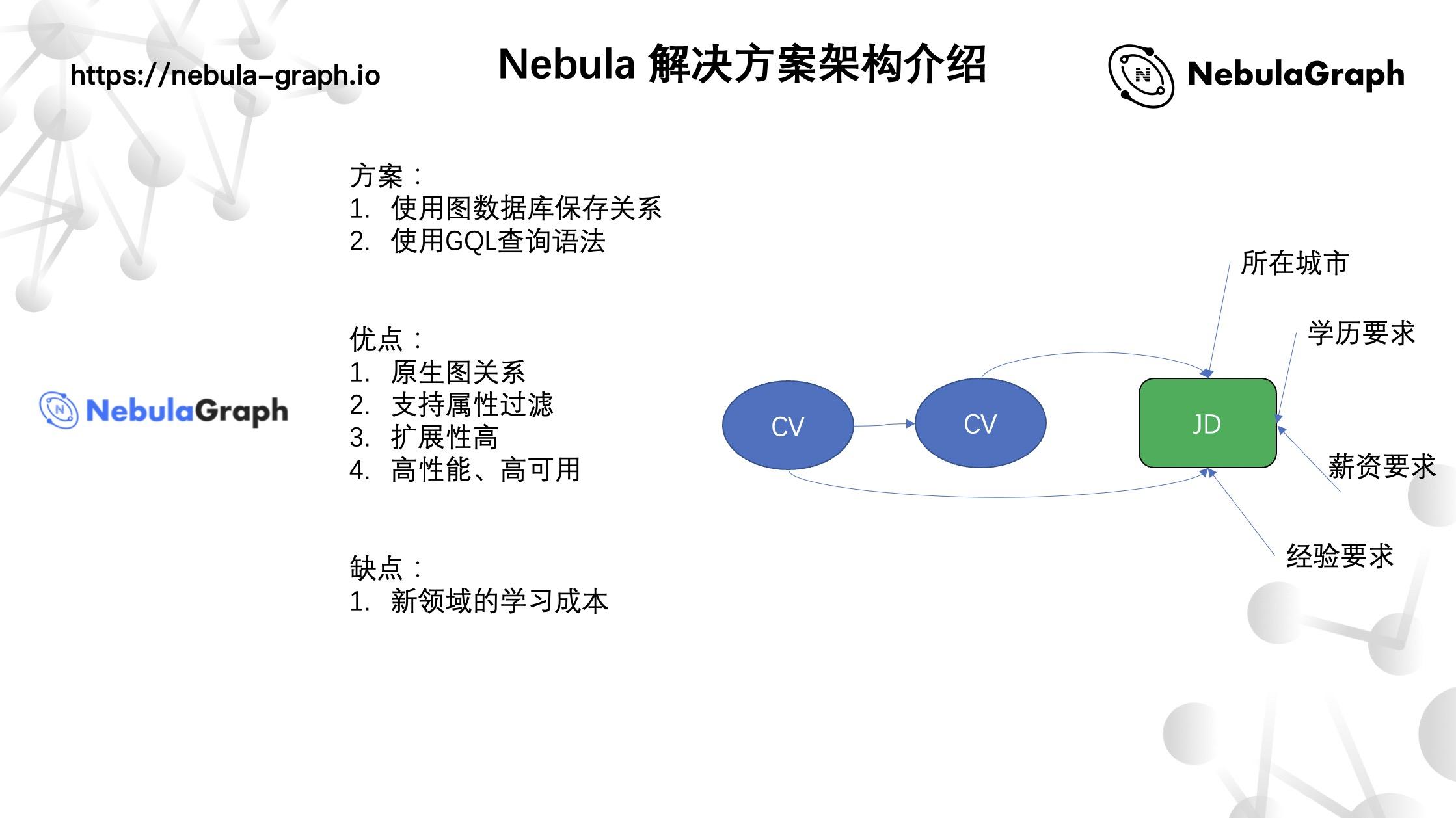
经过我们调研,业界对 Nebula Graph 评价挺高,智联这边用了 Nebula Graph 来实现图索引。像刚在 U2U 和 U2I 的场景,通过图的方式把 CV 和 JD 存储成点,边则存储关系。至于属性过滤,如上图所示将 JD 诸如所在城市、学历要求、薪资要求、经验要求等属性存储为点的属性;而相关性的话,则在关系边上存了一个“分”,最终通过分进行相关性排序。
新技术方案唯一的缺点便是新领域的学习成本,不过在熟悉图数据库之后就方便很多了。
基于 Nebula Graph 的推荐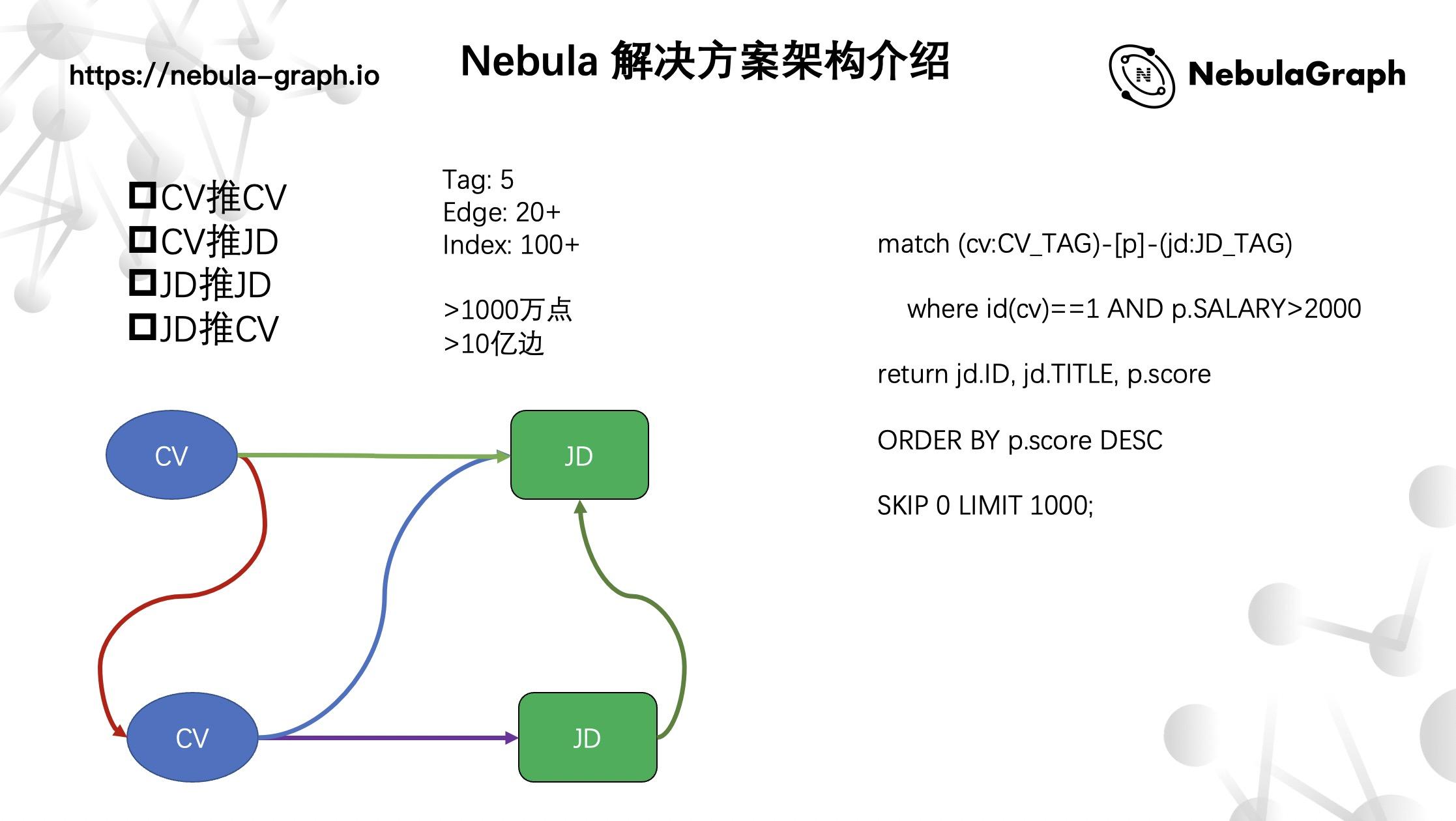
具体的 CV 推 CV、CV 推 JD、JD 推 JD、JD 推 CV 场景,都能满足,像下面这条语句:
match (cv:CV_TAG)-[p]-(jd:JD_TAG)
where id(cv)==1 AND p.SALARY>2000
return jd.ID, jd.TITLE, p.score
ORDER BY p.score DESC
SKIP 0 LIMIT 1000;
便是一个 CV 推 JD 的具体 nGQL 语句:通过简历(CV)开始进行查询,经过一些属性过滤条件,比如:薪资,根据边上的相似分进行 ORDER BY 排序,最终返回一个推荐 JD 信息。
整个业务这块,因为关系相对简单,所以这里一共涉及了 5 种 Tag 和 20+ 种边关系,以及创建 100 多种索引,整个数据量在千万级点和十亿级别的边。
Nebula Graph 使用过程中问题总结 数据写入
数据写入这里主要分为了 3 个方面:
首先 T+1 数据刷新。展开来说,因为数据是提前加工的,要给在线业务使用的话,涉及了 T+1 数据刷新问题。刷数据的话,一开始可能是个冷数据,或者是没有数据,刷新的时候是直接写入关系数据,这个边数据可能连起始点都没有。整个边数据刷新之后,就需要将不存在的点插入。所以这里有个改进点,我们先插入点数据之后再写入边数据,这样关系能更好地创建起来。数据刷新这块还有个问题,就是边数据是 T+1 跑出来的,所以前一天的数据已经失效了,这里就需要把已经存在的关系删掉,再将新的关系写入。
再来讲下数据格式转换,之前我们使用了倒排索引或者是 KV 来存储关系,在数据结构这块,图结构同之前略有不同。像刚才提到的关系,两个点之间需要创建什么关系边,边上存储何种数据,都是需要重新设定的。智联这边当时开发了个内部工具,用来自定义 Schema,可以方便地将数据存储为点,部分数据存储为边,可以灵活操作配置。即便有别的业务接入,有了这个小工具也无需通过 Coding 方式来解决 Schema 设定。
最后一个问题是数据持续增加带来的数据失效。像常见的累积线上活跃用户,经过一段时间,像是三个月之前的活跃用户现在可能是个沉寂用户了,但按照累积机制的话,活跃用户的数据是会一直增加的,这无疑会给服务器带来数据压力。因此,我们给具有时效性的特性增加 TTL 属性,定期删除已经失效的活跃用户。
数据查询
数据查询这块主要也是有 3 个方面的问题:
- 属性多值问题
- Java 客户端 Session 问题
- 语法更新问题
具体来说,Nebula 本身不支持属性多值,我们想到给点连接多条边,但是这样操作的话,会带来额外的一跳查询的成本。但,我们想了另外个易操作的方法来实现属性多值问题,举个例子,我们现在要存储 3 个城市,其中城市 A 的 ID 是城市 B 的 ID 前缀,这里如果用简单的文本存储,会存在检索结果不精准问题。像上面查询 5 时便会把 530 这个城市也查询出来,于是我们写入数据时,给数据前后加入了标识符,这样进行前缀匹配时不会误返回其他数据。
第二个是 Session 管理问题,智联这边在一个集群中创建了多个 Space,一般来说多 Space 的话是需要切换 Space 再进行查询的。但是这样会存在性能损耗,于是智联这边实现了 Session 共享功能。每个 Session 维护一个 Space 的连接,相同的 Session 池是不需要切 Space 的。
最后一个是语法更新问题,因为我们是从 v2.0.1 开始使用的 Nebula Graph,后来升级到了 v2.6,经历了语法迭代——从最开始的 GO FROM 切换到了 MATCH。本身来说,写业务的同学并不关心底层使用了何种查询语法。于是,这里智联实现了一个 DSL,在查询语言上层抽象一层进行语法转换,将业务的语法转换成对应的 nGQL 查询语法。加入 DSL 的好处还在于场景的查询语句不再拘泥于单一的语法,如果用 MATCH 实现效果好就用 MATCH,用 GO 实现好就采用 GO。
统一 DSL 的实现
上图便是统一 DSL 的大概想法,首先从一个点(CV)出发(上图上方蓝色块),去 join 某条边(上图中间蓝色块),再落到某个点上(上图下方蓝色块),最终通过 select 来输出字段,以及 sort 来进行排序,以及 limit 分页。
实现来说,图索引这块主要用到 match、range 和 join 函数。match 用来进行相等匹配,range 是用来进行区间查询,比如说时间区间或者是数值范围。而 join 主要实现一个点如何关联另外一个点。除了这 3 个基本函数之外,还搭配了布尔运算。
通过上面这种方式,我们统一了 DSL,无论是 Nebula 还是 Solr、还是 Milvus 都可以统一成一套用法,一个 DSL 便能调用不同的索引。
智联 Nebula Graph 的后续规划 更有意思更复杂的场景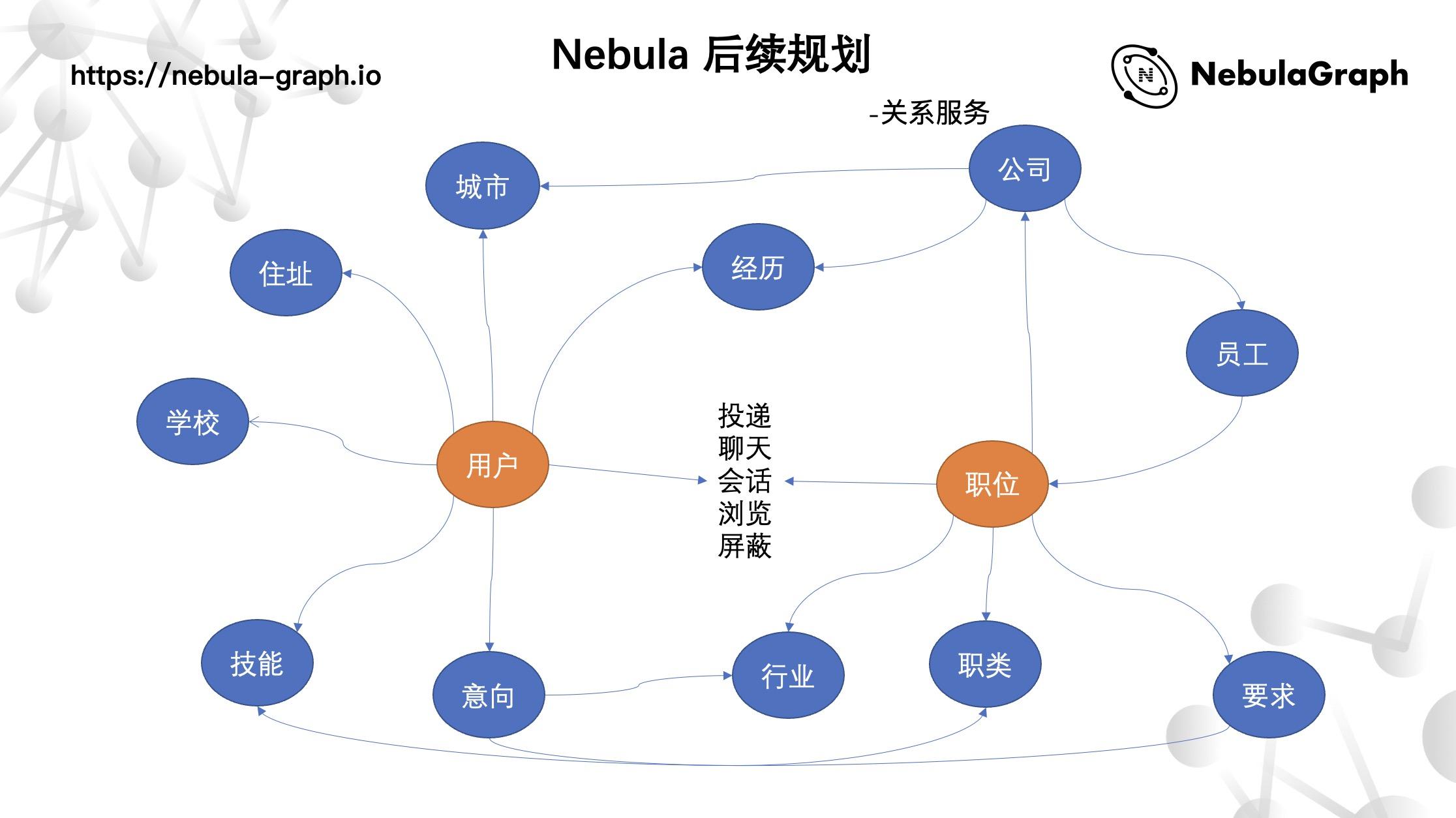
上面讲的业务实现是基于离线加工的数据,后面智联这边将处理在线实时关系。像上图所示,对于一个用户和一个职位而言,二者存在的关系可以很复杂。比如它们都同某个公司有关系,或者是职位所属的公司是某个用户之前任职过的,用户更倾向于求职某一个领域或者行业,职位要求用户熟练掌握某种技能等等,这些构建成一个复杂的关系网络。
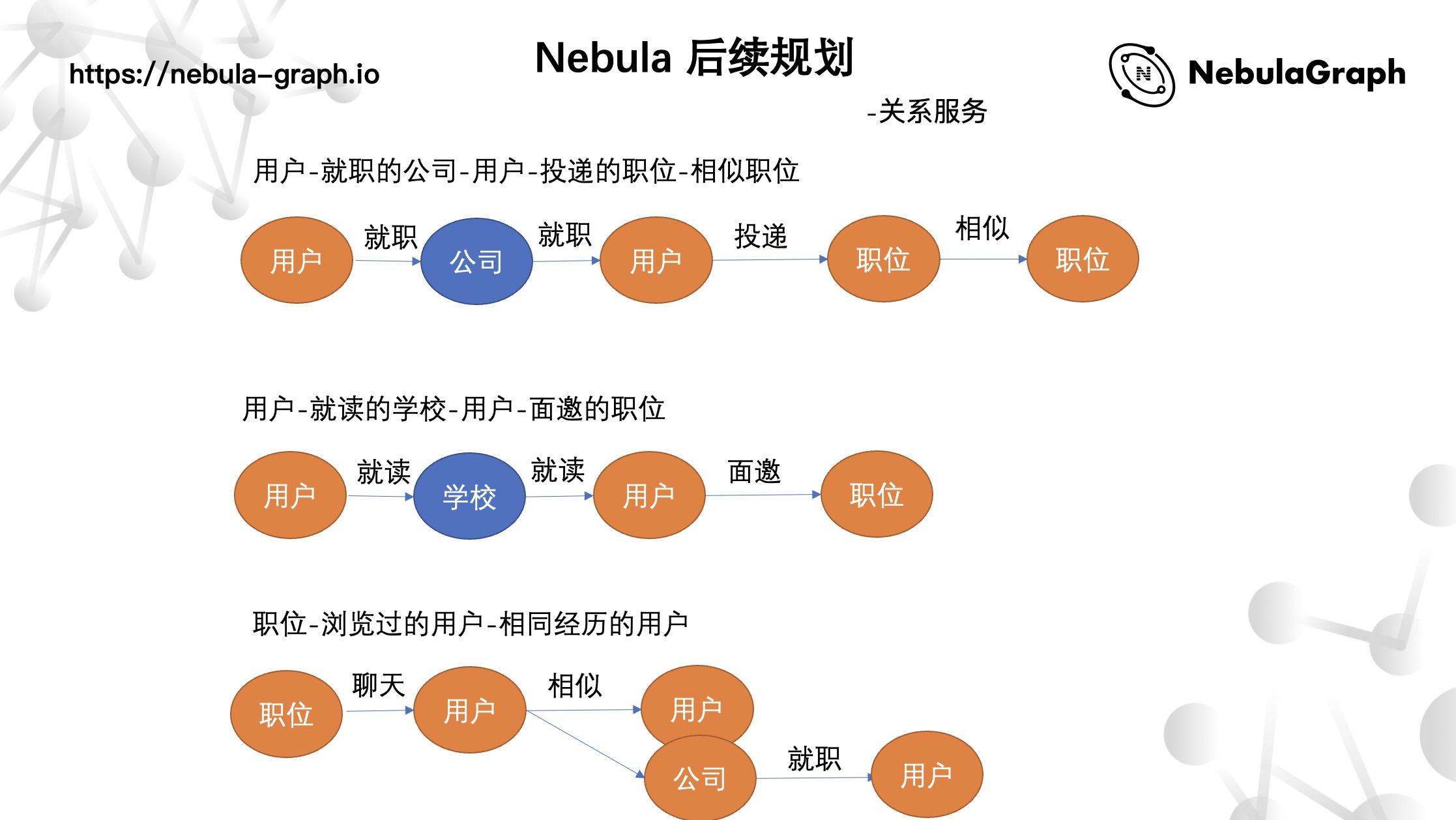
而智联的下一步尝试便是构建起这种复杂的关系网络,再做些比较有意思的事情。例如,某个用户在公司 A 就职过,于是通过这个关系查询出他的同事,再进行相关性推荐;或者是用户同校的上一届学生 / 下届学生倾向投递某个职位或者公司,这种都可以进行相关推荐;像用户投递的这个职位曾经和谁聊过天这种行为数据,这个用户的求职意向要求:薪资水平、城市、领域行业等信息,便可以通过在线的方式进行关联推荐。
更方便的数据展示目前数据查询都是通过特定的查询语法,但是下一步操作便是让更多的人低门槛的查询数据。
更高的资源利用率
目前来说,我们的机器部署资源利用率不高,现在是一个机器部署两个服务节点,每台物理机配置要求较高,这种情况下 CPU、内存使用率不会很高,如果我们将它加入 K8s 中,可以将所有的服务节点打散,可以更方便地利用资源,一个物理节点挂了,可以借助 K8s 快速拉起另外一个服务,这样容灾能力也会有所提升。还有一点是现在我们是多图空间,采用 K8s 的话,可以将不同 Space 进行隔离,避免图空间之间的数据干扰。
更好用的 Nebula Graph最后一点是,进行 Nebula Graph 的版本升级。目前,智联用的是 v2.6 版本,其实社区发布的 v3.0 中提到了对 MATCH 进行了性能优化,这块我们后续将会尝试进行版本升级。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
Nebula Graph:一个开源的分布式图数据库