numpy数组操作 创建维数组 m = np . array ([ np . arange ( 2 ), np . arange ( 2 )]) 选择numpy数组元素 numpy数值类型 np . float64 ( 42 ) np . int8 ( 42.0 ) np . bool ( 42 ) np . bool ( 0 ) np . bool ( 42.0 ) np . float ( Tru
numpy数组操作
创建维数组
m=np.array([np.arange(2),np.arange(2)])选择numpy数组元素
numpy数值类型
np.float64(42)np.int8(42.0)
np.bool(42)
np.bool(0)
np.bool(42.0)
np.float(True)
np.float(Flase)
数据类型对象
一维切片和索引
a=np.arange(9)a[3:7]
out:array([3,4,5,6])
a[:7:2]
out:array([0,2,4,6])
a[::-1]
out:array([8,7,6,5,4,3,2,1,0])
改变阵列形状
b=np.arange(24).reshape(2,3,4)ravel():将多维数组变成一维数组
flatten():同ravel()功能相同,区别ravel返回视图,flatten返回真实数组
transpose():转置
resize():跟reshape()
堆叠数组
vstack():
a=np.arange(9).reshape(3,3)b=2*a
np.vstack((a,b))
dstack():深度叠加
np.dstack((a,b))out:array([[[0,0],
[1,2],
[2,4]],
[[3,6],
[4,8],
[5,10]],
[[6,12],
[7,14],
[8,16]]])
hstack():
np.hstack((a,b))out:array([[0,1,2,0,2,4],
[3,4,5,6,8,10],
[6,7,8,12,14,16]])
column_stack():类似于hstack()
row_stack():类似于vstack()
concatenate():
out:array([[0,1,2,0,2,4],
[3,4,5,6,8,10],
[6,7,8,12,14,16]])
拆分numpy数组
hsplit():
np.hsplit(a,3)vsplit()
dsplit():
split():
np.split(a,3,axis=0)数组属性

ndim:维度
size:元素数量
itemsize:各个元素占用字节数
nbytes:
T:transpose()
pandas
统计量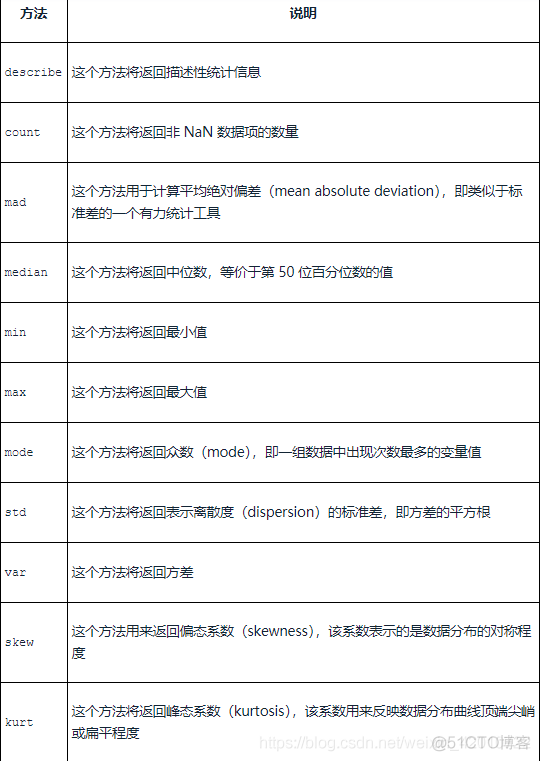
数据聚合
weather_group=df.groupby('weather')i=0
for name,group in weather_group:
i=i+1
print("group",i,name)
print(group)
df.groupby(['weather','food'])
df.groupby(['weather','food']).agg([np.mean,np.median])
连接DataFrames
pd.merge(data1,data2,how='inner,outer')处理缺失数据
pd.isnull(df)df.notnull()
df.fillna(0)
pd.merge()
pd.merge(data1,data2,left_on=’’,right_on=’’,how=’’)
left_on ,right_on类似于SQL a.id=b.id
how类似于SQL中选择连接join的方式
reindex
reindex 使数据对象符合新的索引,如果索引的值不存在就填入缺失值
import pandas as pddata=pd.Series([4.5,7.2,-5.3,3.6],index=['d','b','a','c'])
out:
d 4.5
b 7.2
a -5.3
c 3.6
data1=data.reindex(['a','b','c','d','e'])
out:
a -5.3
b 7.2
c 3.6
d 4.5
e NaN
data2=data.reindex(['a', 'b', 'c', 'd', 'e'], fill_value=0)
out:
a -5.3
b 7.2
c 3.6
d 4.5
e 0.0
assign(**kwargs)
为DataFrame分配新列
返回一个新对象,该对象包含除新列之外的所有原始列
index=['Portland', 'Berkeley']) df
temp_c
Portland 17.0
Berkeley 25.0
df.assign(temp_f=lambda x: x.temp_c * 9 / 5 + 32)
temp_c temp_f
Portland 17.0 62.6
Berkeley 25.0 77.0
数据透视表
print(pd.pivot_table(df,cols=['food'],aggfunc=np.sum))cols参数告诉pandas要对哪些列进行聚合运算。
PCA
基于鸢尾花4个特征,探索能不能只使用二列进行变换
PCA步骤:
1.将数据集标准化
2.计算数据集相关矩阵
3.计算相关矩阵对应的特征向量和值
4.基于降序的特征值选择前2个特征向量
5.基于特征向量与原数据标准化后的集乘积得到新的数据集
from sklearn.datasets import load_iris
from sklearn.preprocessing import scale
import scipy
import matplotlib.pyplpot as plt
data=load_iris()
x=data[0:-2]
y=data[-1]
x_s=scale(x,with_mean=True,with_std=True,axis=0)
x_c=np.corrcoef(x_s.T)
eig_val,r_eig_vec=scipy.linalg.eig(x_c)
w=r_eig_vec[:,0:2]
x_rd=x_s.dot(w)