爬虫案例:自动登录抽屉新热榜
写在前面
刚开始我以为抽屉是一个项目,就是类似于那种抽屉的效果,然后就在纠结还要不要学这个单元,因为我没有现成的案例拿来用,如果要用的话还要自己写很费时间,但是不想混过去,心里有个心事不舒服,就想去网上down一个,结果就找到了抽屉...
在对网站进行爬取的时候,一定要伪装成浏览器!!!
在对网站进行爬取的时候,一定要伪装成浏览器!!!
在对网站进行爬取的时候,一定要伪装成浏览器!!!
https://dig.chouti.com/
编前思考
1、首先我们要考虑抽屉网站是通过 form 还是 ajax 提交登录的。
form :当点击提交按钮时页面会全部刷新。
ajax:当点击提交按钮时页面不会刷新。
OK,抽屉网站使用的是ajax提交,不会刷新。
2、编写代码登录抽屉官网
首先对网站提交进行分析。
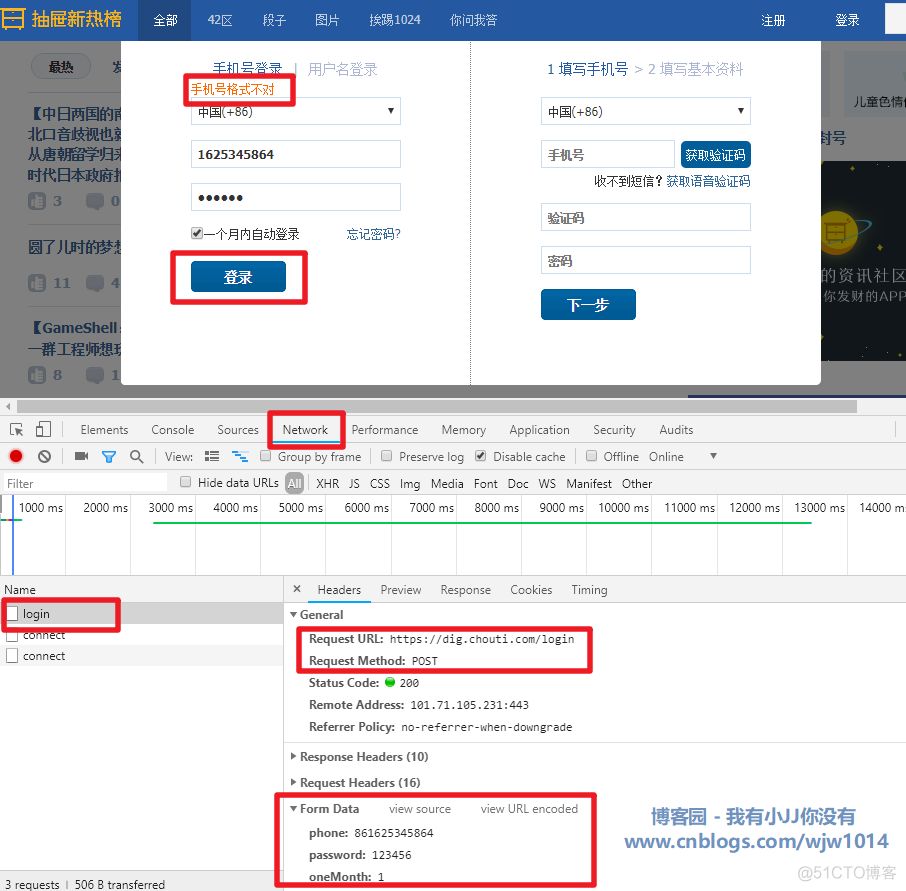
# date : 2019-01-16
import requests
# 提交的参数
post_data = {
"phone": '86'+'15668318888',
'password': '123',
'oneMonth': 1 # 一个月内免登陆
}
# 一定要添加浏览器,不然可能会遇到网络防火墙
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:58.0) Gecko/20100101 Firefox/58.0'}
response = requests.post(
url='https://dig.chouti.com/login',
# 伪装成浏览器
headers =headers,
data=post_data,
)
print(response.text)
# 获取cookie
cookie_dic = response.cookies.get_dict()
print(cookie_dic)

···· 注意:注册账号,填写正确的手机号和密码会登陆成功!

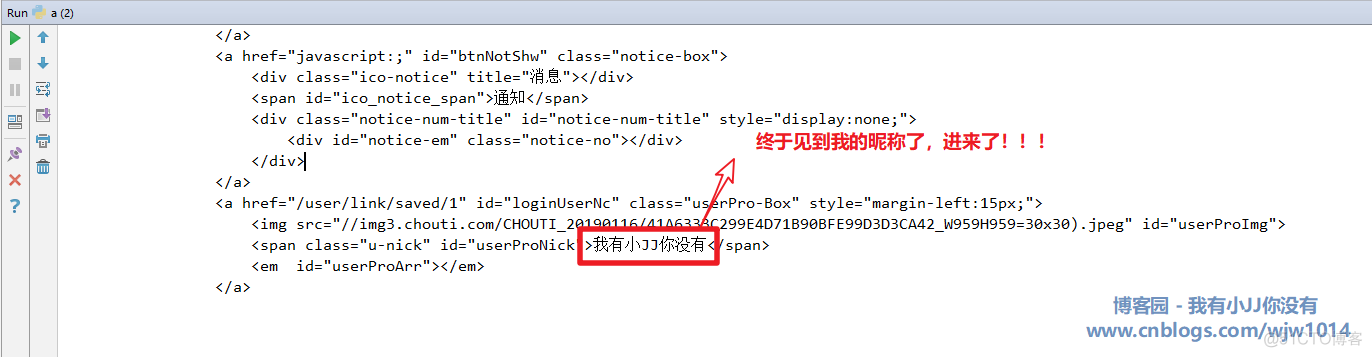
登录抽屉,获取设置页
抽屉做了一件对于爬取的用户来说很烦,但是对于网站的安全性来说确实很棒的一件事!!!
抽屉网比较特别,一般的网站在登陆的时候会返回一个cookies,以后再次登陆的时候只要带着这个cookies去登陆就可以,但是抽屉网得特别之处在于登陆后返回给用户得cookies是没用得,这是抽屉网做出来混淆视听得一种做法。
我们第一次打开抽屉网得时候,用get请求发送,这时候其实抽屉网会返回一个cookies。
import requests# 一定要添加浏览器,不然可能会遇到网络防火墙
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:58.0) Gecko/20100101 Firefox/58.0'}
r1 = requests.get(
url='http://dig.chouti.com/',
headers = headers
)
# 获取第一次进入主页得到的cookie
r1_cookie_dic = r1.cookies.get_dict()
print(r1_cookie_dic)

然后在此页面进行登陆的时候,发送post请求,其实就是对get请求返回得cookies进行授权,登陆名和密码登陆成功,也就是授权cookies,然后就可以用这个cookies进行自动登陆或者点赞设置等。
注意的是,发送post请求得时候其实也会返回一个cookies,但是这个cookies是无用得,所以正确得cookies应该是第一次拿到得cookies才可以正确登陆。但是大多数网站不是这样的,只有抽屉是这样!!
具体代码
# __author : "王佳伟"# date : 2019-01-16
import requests
# 一定要添加浏览器,不然可能会遇到网络防火墙
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:58.0) Gecko/20100101 Firefox/58.0'}
# 第一次去抽屉拿到需要授权的cookies
r1 = requests.get(
url='http://dig.chouti.com/',
headers=headers
)
# 获取第一次进入主页得到的cookie
r1_cookie_dic = r1.cookies.get_dict()
print(r1_cookie_dic)
# 登录的提交参数
post_data = {
"phone": '86' + '你抽屉官网注册的手机号',
'password': '你的抽屉官网密码',
'oneMonth': 1 # 一个月内免登陆
}
# 第二次登录抽屉
response = requests.post(
url='https://dig.chouti.com/login',
# 为了模拟浏览器得行为,每次都要带着请求头去这样这样不会容易被发现是爬虫。
headers=headers,
data=post_data,
# 第二次登陆发送post请求时,应该将第一次得cookies带过去授权,所以要带着cookies。
cookies=r1_cookie_dic
)
print(response.text)
# 获取第二次登录返回的cookie,尽管有返回,但是第二次返回的这个cookie没有用
cookie_dic = response.cookies.get_dict()
print(cookie_dic)
# 进入个人设置页面
response = requests.get(
url='https://dig.chouti.com/profile',
# 模拟浏览器
headers=headers,
# 提交cookie(一般网站使用下面这句代码就行,抽屉不行)
# cookies=cookie_dic,
# 抽屉官网有点淘气,阴了我们一下,将授权好的第一次的cookies带进去访问
cookies={'gpsd': r1_cookie_dic.get('gpsd')}
)
# 输出返回的页面
print(response.text)
【版权声明】本博文著作权归作者所有,任何形式的转载都请联系作者获取授权并注明出处!
【重要说明】本文为本人的学习记录,论点和观点仅代表个人而不代表当时技术的真理,目的是自我学习和有幸成为可以向他人分享的经验,因此有错误会虚心接受改正,但不代表此刻博文无误!
【Gitee地址】秦浩铖:https://gitee.com/wjw1014