为什么需要线程池
对象复用思想在编程中有很多应用,不论是线程池还是连接池都是一种对象复用的思想。今天来谈谈Java里面的线程池。
Java中创建和销毁一个线程是比较昂贵的操作,需要系统调用。频繁创建和销毁线程会影响系统性能。于是线程池应运而生。
Executor框架
提前总结一句:重点就是ThreadPoolExecutor,后面的提到的 Executors支持线程池的一个静态工厂类,我们完全没必要用。
Executor框架是java中的线程池实现。Executor是最顶层的接口定义,它的子类和实现主要包括ExecutorService,ScheduledExecutorService,ThreadPoolExecutor,ScheduledThreadPoolExecutor,ForkJoinPool等。其结构如下图所示:
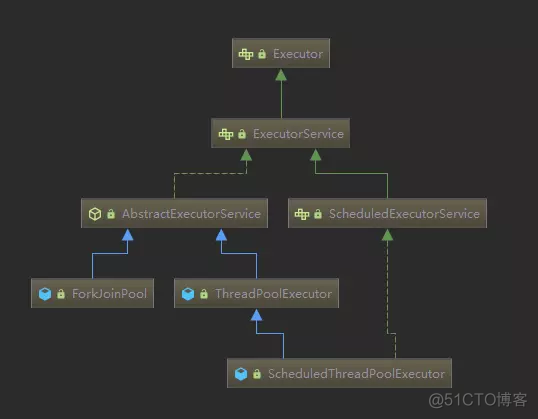
ScheduledThreadPoolExecutor
Executor:Executor是一个接口,其只定义了一个execute()方法:void execute(Runnable command);,只能提交Runnable形式的任务,不支持提交Callable带有返回值的任务。
ExecutorService:ExecutorService在Executor的基础上加入了线程池的生命周期管理,我们可以通过ExecutorService#shutdown或者ExecutorService#shutdownNow方法来关闭我们的线程池。ExecutorService支持提交Callable形式的任务,提交完Callable任务后我们拿到一个Future,它代表一个异步任务执行的结果。关于shutdown和shutdownNow方法我们需要注意的是:这两个方法是非阻塞的,调用后立即返回,不会等待线程池关闭完成。如果我们需要等待线程池处理完成再返回可以使用ExecutorService#awaitTermination来完成。
shutdown方法会等待线程池中已经运行的任何和阻塞队列中等待执行的任务执行完成,而shutdownNow则不会,shutdownNow方法会尝试中断线程池中已经运行的任务,阻塞队列中等待的任务不会再被执行,阻塞队列中等待执行的任务会作为返回值返回。
ThreadPoolExecutor:是线程池中最核心的类,这里着重说一下这个类的各个构造参数:
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}

threadpoolexecutor
ScheduledThreadPoolExecutor:ThreadPoolExecutor子类,它在ThreadPoolExecutor基础上加入了任务定时执行的功能。
Executors
Executors是一个工厂类,主要用来创建ExecutorService,ScheduledExecutorService等线程池。
public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
这个静态方法用来创建固定线程数目的线程池,可以看到其设置的corePoolSize和maximumPoolSize都是nThreads,其设定的阻塞队列是无界的,也就说多余的请求将一直积压在队列中进行等待,有可能造成内存溢出。这也是阿里编码规范不推荐用Executors来创建ThreadPoolExecutor的原因。

return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
这个方法用来创建一个“工作窃取(work stealing)”ForkJoinPool线程池,这里不做展开,后面会介绍ForkJoinPool。
public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
注意到这个方法创建的核心线程数是0,maximumPoolSize是一个最大值,空闲线程的最大空闲时间是一分钟,阻塞队列是一个SynchronousQueue。这个类其实挺有意思的,SynchronousQueue主要拥有数据交换而不是队列。当SynchronousQueue中有一个元素时,put请求会被阻塞住,直到有消费者从队列中拿走这个元素,同理如果队列为空,消费者也必须阻塞等待有生产者放入新的元素。
注意到这些静态方法可以方便我们创建线程池,但是你必须清楚每个方法创建的线程池的各个参数设置,就像newFixedThreadPool这个方法创建的线程池的阻塞队列是无界的。所以我更倾向推荐大家自己直接用ThreadPoolExecutor来定制自己的线程池。
ForkJoinPool
Doug Lea在JDK7中引入了Fork/Join框架,ForkJoinPool不同于ThreadPoolExecutor,它是一种基于"分治"思想的计算框架。java8的stream API中很多地方都有用到ForkJoinPool。ForkJoinPool中的工作线程会对自己的任务按照一定的粒度进行拆分,一个大任务拆分成多个子任务之后,子任务放入工作队列中等待执行。当一个线程的工作队列为空是可以从其他线程的工作队列中steal任务执行。这也是"work-stealing"的由来。
基本思想
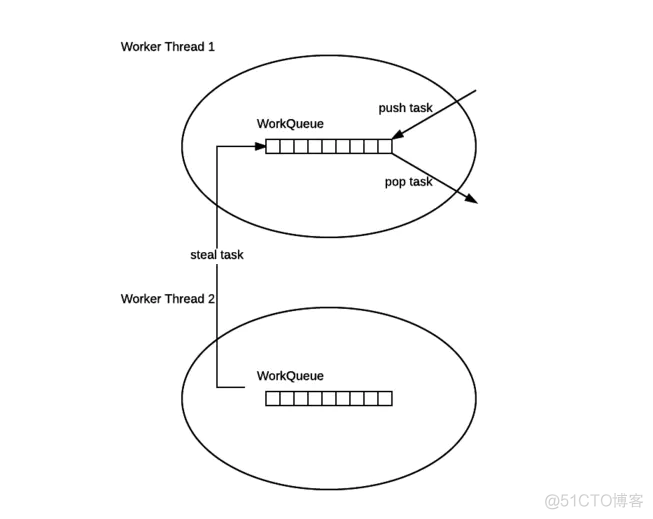
FJ线程池结构
fork
fork将任务放入任务隶属的工作线程的工作队列中。
public final ForkJoinTask<V> fork() {Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
join
<div align="center">
<img src="{{ site.url }}/images/posts/java/flowchart-of-join.png" alt="join"/>
</div>
以上就是 fork() 和 join() 的原理,这可以解释 ForkJoinPool 在递归过程中的执行逻辑,但还有一个问题:
最初的任务是 push 到哪个线程的工作队列里的?这就涉及到 submit() 函数的实现方法了。
submit
其实除了前面介绍过的每个工作线程自己拥有的工作队列以外,ForkJoinPool 自身也拥有工作队列,这些工作队列的作用是用来接收由外部线程(非 ForkJoinThread 线程)提交过来的任务,而这些工作队列被称为 submitting queue 。
submit() 和 fork() 其实没有本质区别,只是提交对象变成了 submitting queue 而已(还有一些同步,初始化的操作)。submitting queue 和其他 work queue 一样,是工作线程”窃取“的对象,因此当其中的任务被一个工作线程成功窃取时,就意味着提交的任务真正开始进入执行阶段。