@TOC
为什么要引入线程池
- 我们知道我们每次创建 启动 销毁一个线程的消耗是较大的 所以引入线程池的最大的好处就是减少每次启动 销毁线程的损耗
那么他是如何实现减少的?
在线程池里有一个阻塞队列 他会记录并储存要执行的任务 并且他内部又会有一个或者几个线程去取队列的首元素任性任务
简单举个例子:
就是 有一个快递站 来一个快递 快递站老板就会雇佣一个学生去送快递 然后马上解雇人家 再来一个快递他又会雇佣一个学生 然后解雇 此时他会发现 这样雇佣解雇太费事 于是他就雇佣一个或者一个学生 然后又将来的快递都拿一个本本记录下来 让着几个学生去轮流看这个本本上要送的快递 然后各自再去送快递 这样就是一个线程池
为什么线程池子比系统申请释放快?
为了理解这个问题,我们就得理解一组重要的概念。
在操作系统中,我们分成两种状态:1、用户态2、内核态
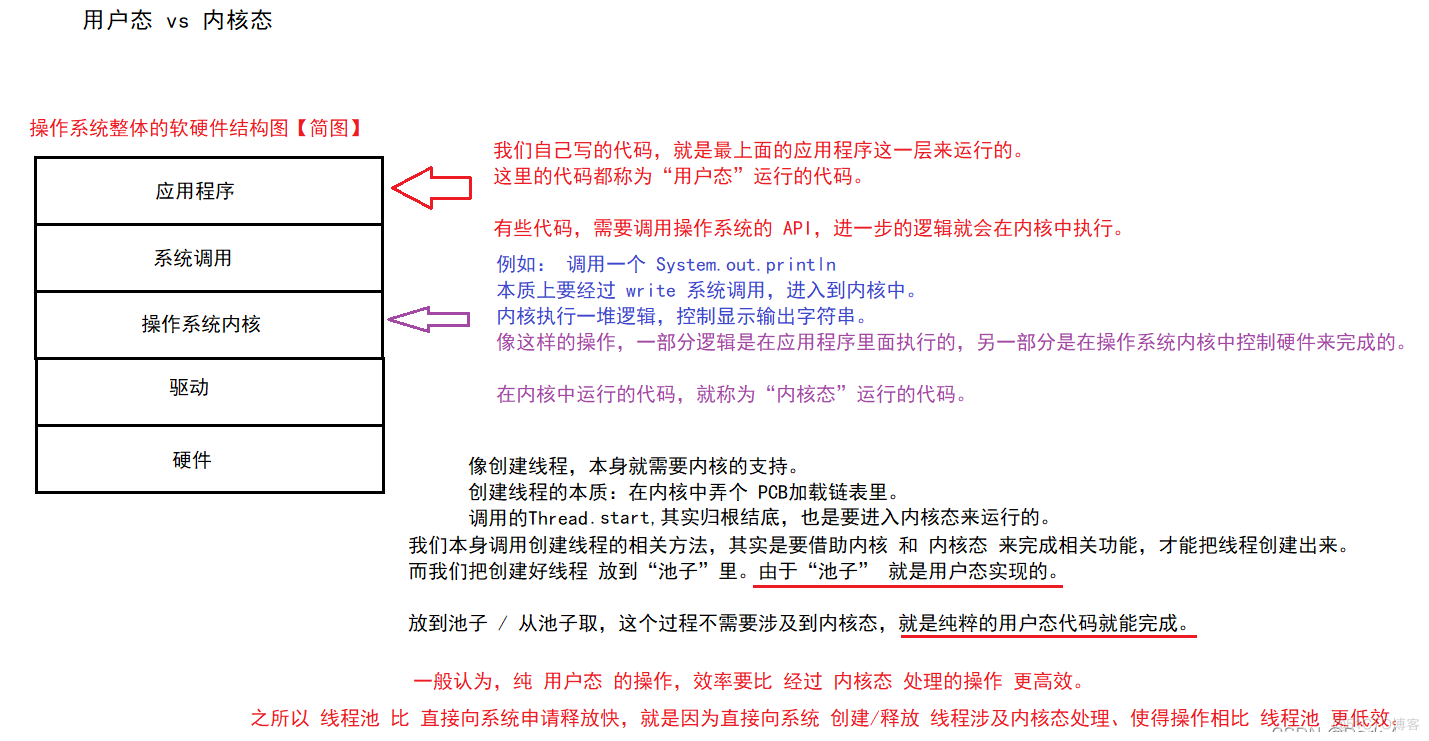
为了加深对“内核态” 和 “用户态”的理解.
举一个形象的例子:
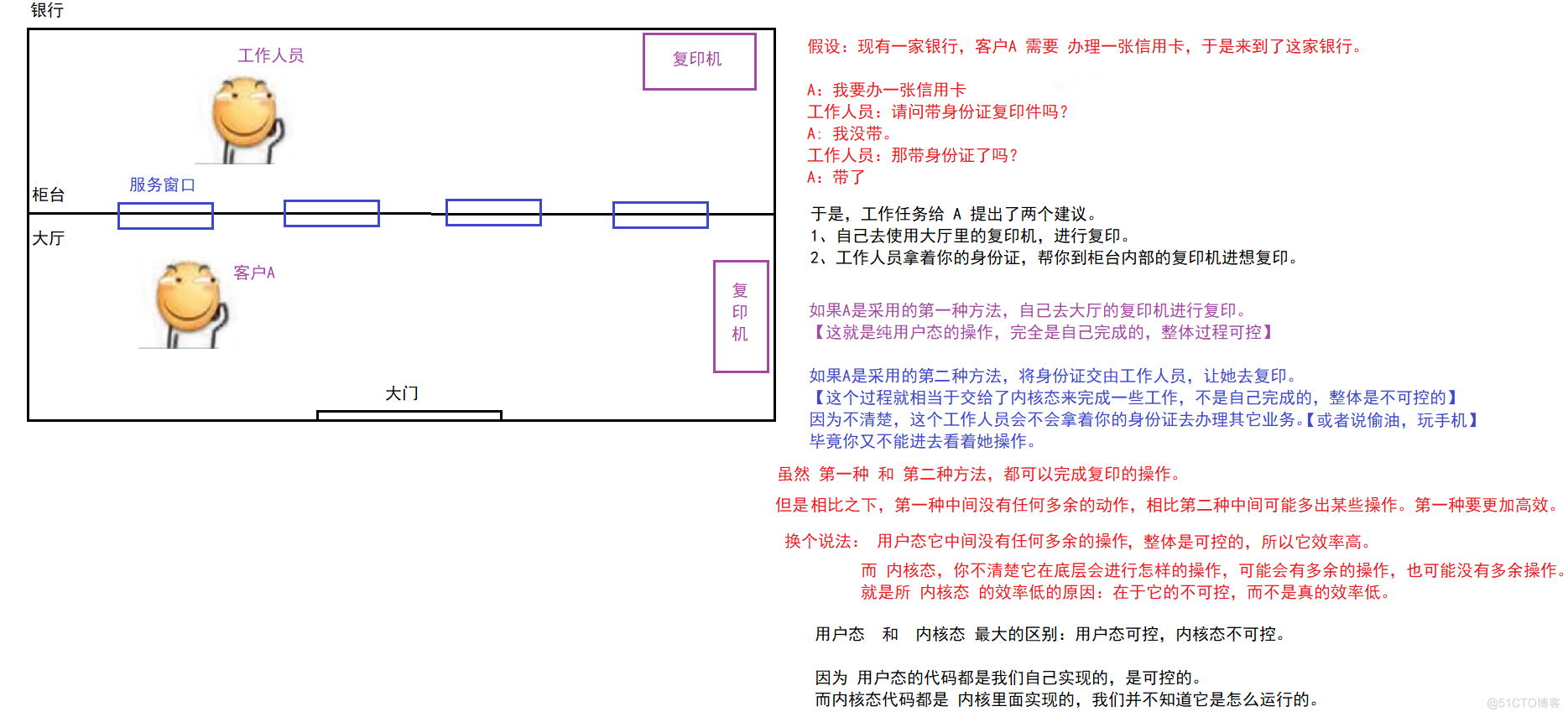
下面,我们来看一下 Java标准库中是怎样的体现。
老规矩,先来学习一下 Java 保准库中,线程池的使用。然后再自己实现一个线程池。
Java标准库中的线程池使用
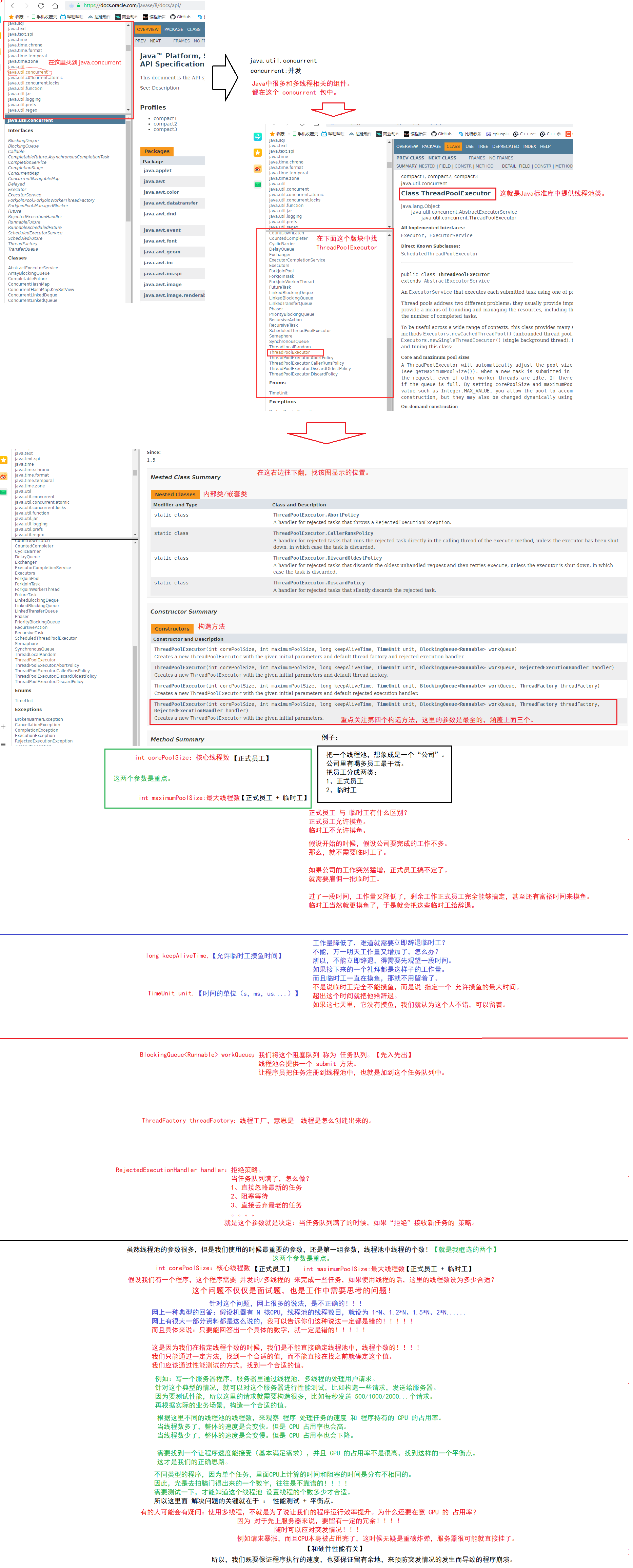
ThreadPoolExecutor
创建线程池其中参数的理解
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)corePoolSize: 核心线程数
maximumPoolSize: 最大线程数
keepAliveTime: 空闲时间数量
unit: 空闲时间单位
workQueue: 阻塞/任务/工作队列
threadFactory: 线程创建的工厂
handler: 拒绝策略
ThreadPoolExecutor
Executors
标准库中还提供了一个简化版本的线程池 ----》ExecutorsExecutors:本质是针对 ThreadPoolExecutor 进行了封装,提供了一些默认参数。
我们现在来看一下Executors是怎么用的?顺便我们就按照这个来模拟是一个线程池。
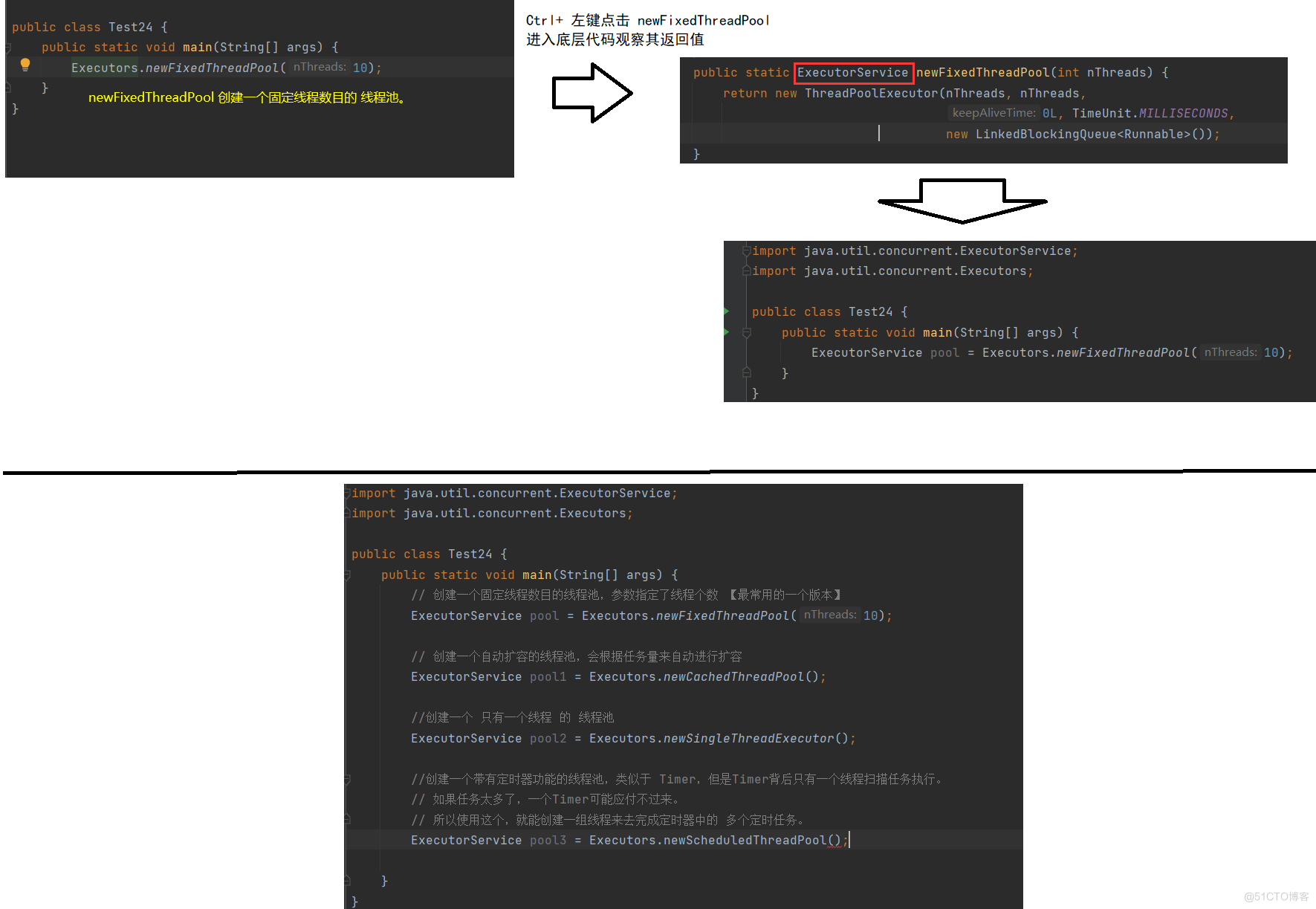
下面就使用第一个 newFixedThreadPool 方法。来实现一个任务
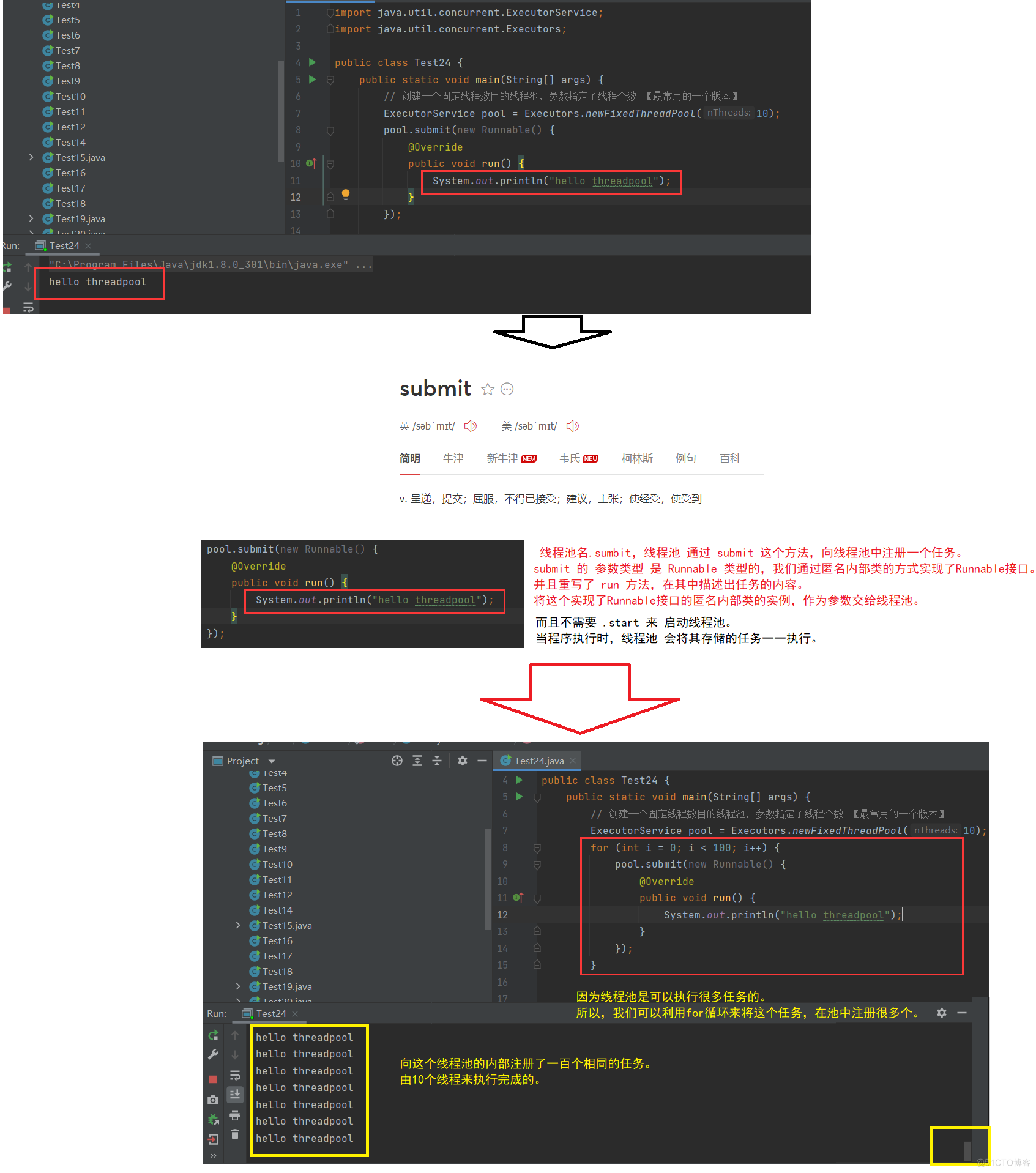
线程池执行流程
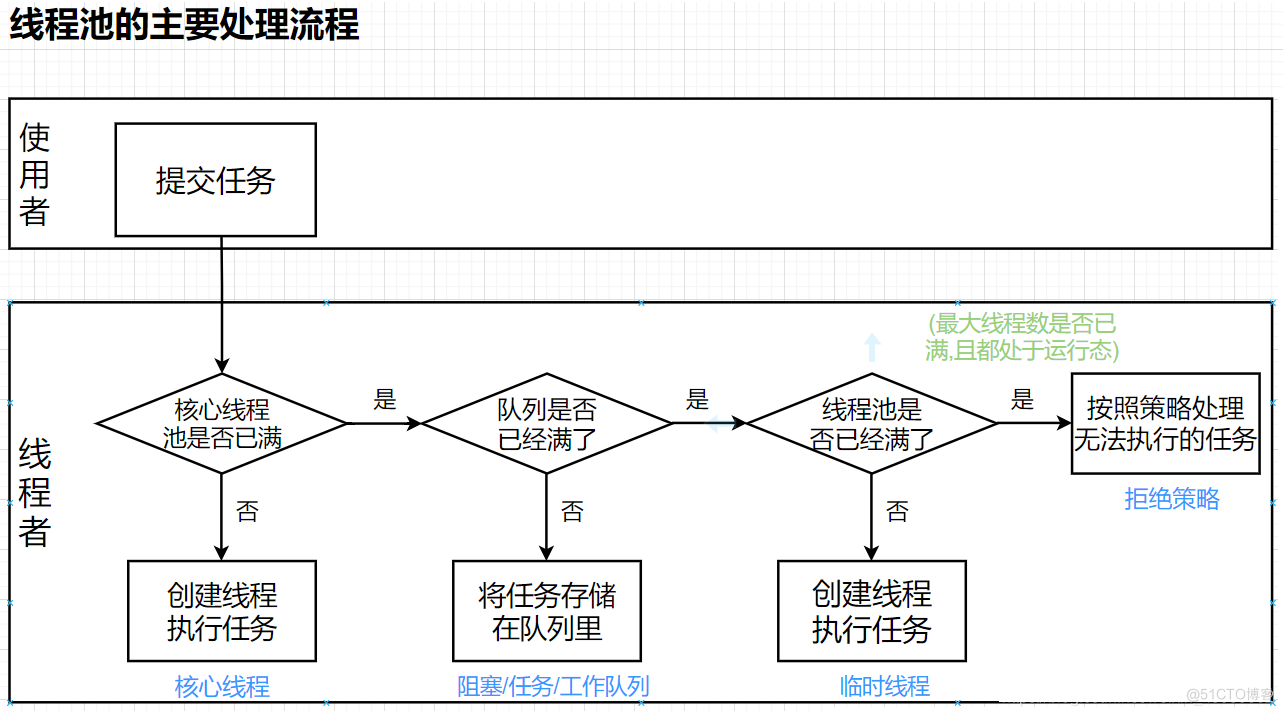
根据上图场景,我们可以将自己想象成快递站的老板,试想一下,假如此时一有人过来寄东西了,那我就雇佣一个临时工,等处理完了,立马就将他解雇,可以是可以,但是好像不太划算,毕竟频繁的雇佣解雇临时工开销开始比较大的.
灵机一动,我决定按照自己店里的实际需要,聘请 3 位正式员工,要是他们仨都忙着,那我就将要寄出的包裹先放在我的小店里,等他们三个将手里的包裹处理完了之后,就继续处理小店里堆积的包裹,开销也不是很大,日子过的云淡风轻~
但是没想到,618活动来的让我措手不及,很快我的小店就堆满了,三个正式员工也处理不过来,那这个时候还有人来寄包裹可怎么办,不能伤了寄件人的心呀~为了展示我们的实力,小店虽小,还是能多站下几个人的,不要慌,我再雇佣临时工不就好了嘛,场地限制,我的店里最多只能站6个人,也就是我最多同时只能雇3个临时工,这下舒坦了.
但是好日子没几天,还是我太稚嫩,低估了消费者的实力,很快,包裹堆满了小店,看着他们六个人忙的不可开交,我也是心疼,此时,还有源源不断的人来寄包裹,这下,我是真的没有办法啦,该伤的心还是得伤,心有余而力不足,只好拒绝并告知他们另寻他处吧~
当完老板再留恋不舍也要缓过神来呀,再对照上面流程图理解一下线程池吧~核心线程对应到的是3个正式员工,阻塞队列对应到快递小店的存储包裹区,线程池对应到小店的前台(最多能站6个人).
手动实现线程池
线程池里面都有什么?
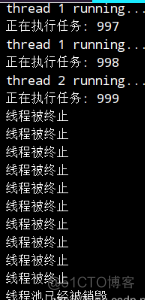
1、先能够描述任务------> 直接使用 Runnable 即可
2、需要组织任务 ----- > 直接使用 BlockingQueue阻塞队列
3、描述工作线程
4、组织工作线程
5、需要实现,往线程池添加任务。
我要实现的线程池,不光要管理任务 和 线程,还需要它们相互配合。
代码
import java.util.ArrayList; import java.util.List; import java.util.concurrent.BlockingQueue; import java.util.concurrent.LinkedBlockingQueue; public class TeacterThreadPool { // 使用这个类来描述当前的工作线程是啥样的. static class Worker extends Thread { private int id = 0; // 每个 Worker 线程都需要从任务队列中取任务. // 需要能够获取到任务队列的实例 private BlockingQueue<Runnable> queue = null; public Worker(BlockingQueue<Runnable> queue, int id) { this.queue = queue; this.id = id; } @Override public void run() { // 注意此处的 try 把 while 包裹进去了. // 目的是只要线程收到异常, 就会立刻结束 run 方法(也就是结束线程) try { while (!Thread.currentThread().isInterrupted()) { Runnable command = queue.take(); System.out.println("thread " + id + " running..."); command.run(); } } catch (InterruptedException e) { // 线程被结束. System.out.println("线程被终止"); } } } // 本质上就是一个生产者消费者模型. // 调用 execute 的代码就是生产者. 生产了任务 (Runnable 对象) // worker 线程就是消费者. 消费了队列中的任务. // 交易场所就是 BlockingQueue static class MyThreadPool2 { // 这个阻塞队列用于组织若干个任务 private BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>(); // 这个 List 用来组织若干个工作线程 private List<Worker> workers = new ArrayList<>(); // 一个线程池内部应该有多少个线程, 需要根据实际情况来确定. // 当前写的 "10" 纯粹是拍脑门 private static final int maxWorkerCount = 10; // 实现 execute 方法 和 shutdown 方法 public void execute(Runnable command) throws InterruptedException { // 也是使用延时加载的方式来创建线程. // 当线程池中的线程数目比较少的时候, 新创建线程来作为工作线程. // 如果线程数目已经比较多了(达到设定的阈值), 就不用新建线程了. if (workers.size() < maxWorkerCount) { Worker worker = new Worker(queue, workers.size()); worker.start(); workers.add(worker); } queue.put(command); } // 当 shutdown 结束之后, 意味着所有的线程一定都结束了. public void shutdown() throws InterruptedException { // 终止掉所有的线程. for (Worker worker : workers) { worker.interrupt(); } // 还需要等待每个线程执行结束. for (Worker worker : workers) { worker.join(); } } } static class Command implements Runnable { private int num; public Command(int num) { this.num = num; } @Override public void run() { System.out.println("正在执行任务: " + num); } } public static void main(String[] args) throws InterruptedException { MyThreadPool2 pool = new MyThreadPool2(); for (int i = 0; i < 1000; i++) { pool.execute(new Command(i)); } Thread.sleep(2000); pool.shutdown(); System.out.println("线程池已经被销毁"); } }