这篇文章主要介绍了JAVA DOM解析XML文件过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 代码如下 import java.io.IOExce
这篇文章主要介绍了JAVA DOM解析XML文件过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
代码如下
import java.io.IOException;
import javax.xml.parsers.*;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class Domtest {
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
//创建一个DocumentBuilderFactory对象
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
//创建一个Doucumentbuild对象
DocumentBuilder db=dbf.newDocumentBuilder();
//解析对应的xml文件
Document doc=db.parse("tes.xml");
//根据标签名获取Node节点list
NodeList nodelist=doc.getElementsByTagName("book");
System.out.println("共有"+nodelist.getLength()+"本书");
//遍历每一个book节点
for(int i=0;i<nodelist.getLength();i++) {
System.out.println("第"+i+"本书");
//获取个book节点
//使用Node类型获取book
Node book=nodelist.item(i);
System.out.println("Name: "+book.getNodeName()+" Value: "+book.getNodeValue()+" Type: "+book.getNodeType());
//获取Node节点中的属性
NamedNodeMap attrs= book.getAttributes();
//遍历获取属性
for(int j=0;j<attrs.getLength();j++) {
Node x=attrs.item(j);
//System.out.println(x.getNodeName()+" "+x.getNodeValue()+" "+x.getNodeType());
}
//使用Element对象获取节点
Element node =(Element) nodelist.item(i);
//使用Element对象下的getAttribute方法可以获取指定名字的属性值
String id=node.getAttribute("id");
System.out.println(id);
String type=node.getAttribute("type");
System.out.println(type);
//使用Node节点下的getChildNode可以获取Nodelist数组,以此进行循环解析
NodeList childnode=book.getChildNodes();
for(int j=0;j<childnode.getLength();j++) {//getLength后会获取9个节点,因为text类型也算节点,一个<name>……</name>算一个节点,所以共有9个节点,而这些节点中,只有对象节点是我们需要的
Node x=childnode.item(j);
if(x.getNodeType()==Node.ELEMENT_NODE){//当节点类型为Element时,获取该节点
//获取element类型的节点名
System.out.println("节点"+j+"的名字:"+x.getNodeName()+" 值:/"+x.getLastChild().getNodeValue()+"/种类为"+x.getLastChild().getNodeType());//<name>xyz<name>,xyz属于<name>的子节点,使用getfirstChild或getLastNode效果相同
System.out.println("节点"+j+"的名字:"+x.getNodeName()+" 值:/"+x.getTextContent()+"/种类为"+x.getNodeType());//getTextContent方法可以获取节点中所有的text内容 将<name>xyz</name>改为<name><a>123</a>xyz</name>,会获取到xyz123
}
}
}
}
}
//为了将获取到的xml文件中内容保存下来,可以将内容保存到对象数组中一次来存储数据
<?xml version="1.0" encoding="UTF-8" ?> <Bookstore> <book id="1" type="text"> <name>冰与火之歌</name> <author>乔治马丁</author> <year>2014</year> <price>80</price> </book> <book id="2"> <name>安徒生童话</name> <year>2004</year> <price>79</price> <language>English</language> </book> </Bookstore>
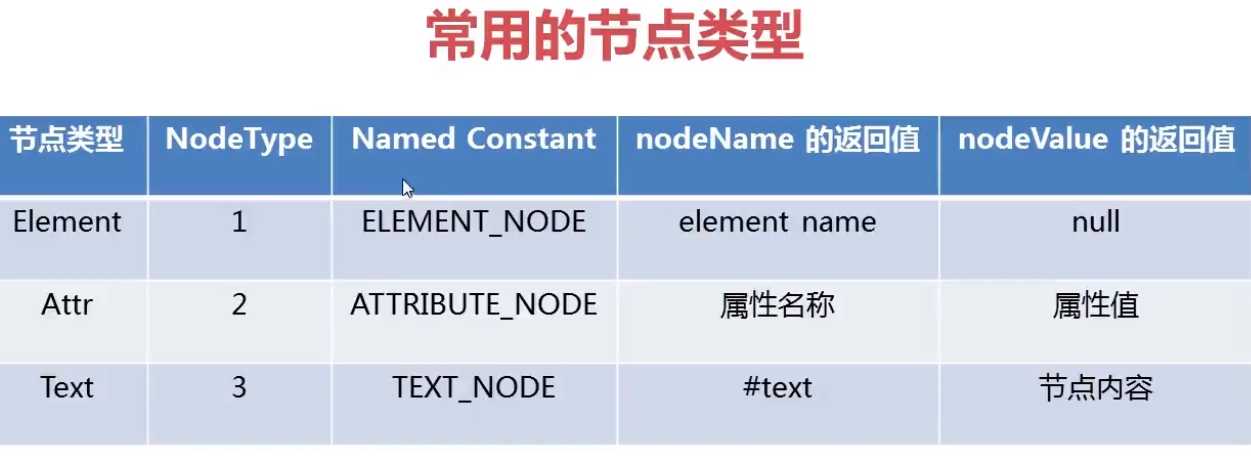
注意点
1 空白换行符也算节点,所以遍历节点时需要注意这些无用的节点会混在list中
2 text类节点返回Name值都是#text,而Element类节点返回value值都是null,需要注意
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持易盾网络。