TimingWheel是kafka时间轮的实现,内部包含了⼀个TimerTaskList数组,每个数组包含了⼀些链表组成的TimerTaskEntry事件,每个TimerTaskList表示时间轮的某⼀格,这⼀格的时间跨度为tickMs,同⼀个TimerTaskList中的事件都是相差在⼀个tickMs跨度内的,整个时间轮的时间跨度为interval = tickMs * wheelSize,该时间轮能处理的时间范围在cuurentTime到currentTime + interval之间的事件。
当添加⼀个时间他的超时时间⼤于整个时间轮的跨度时, expiration >= currentTime + interval,则会将该事件向上级传递,上级的tickMs是下级的interval,传递直到某⼀个时间轮满⾜expiration < currentTime + interval,
然后计算对应位于哪⼀格,然后将事件放进去,重新设置超时时间,然后放进jdk延迟队列
else if (expiration < currentTime + interval) {
// Put in its own bucket
val virtualId = expiration / tickMs
val bucket = buckets((virtualId % wheelSize.toLong).toInt)
bucket.add(timerTaskEntry)
// Set the bucket expiration time
if (bucket.setExpiration(virtualId * tickMs)) {
// The bucket needs to be enqueued because it was an expired bucket
// We only need to enqueue the bucket when its expiration time has changed, i.e. the wheel has advanced
// and the previous buckets gets reused; further calls to set the expiration within the same wheel cycle
// will pass in the same value and hence return false, thus the bucket with the same expiration will not
// be enqueued multiple times.
queue.offer(bucket)
}
SystemTimer会取出queue中的TimerTaskList,根据expiration将currentTime往前推进,然后把⾥⾯所有的事件重新放进时间轮中,因为ct推进了,所以有些事件会在第0格,表示到期了,直接返回。
else if (expiration < currentTime + tickMs) {
然后将任务提交到java线程池中处理。
服务端在处理客户端的请求,针对不同的请求,可能不会⽴即返回响应结果给客户端。在处理这类请求时,服务端会为这类请求创建延迟操作对象放⼊延迟缓存队列中。延迟缓存的数据结构类似MAP,延迟操作对象从延迟缓存队列中完成并移除有两种⽅式:
- 延迟操作对应的外部事件发⽣时,外部事件会尝试完成延迟缓存中的延迟操作 。
- 如果外部事件仍然没有完成延迟操作,超时时间达到后,会强制完成延迟的操作 。
DelayedOperation接⼝表示延迟的操作对象。此接⼝的实现类包括延迟加⼊,延迟⼼跳,延迟⽣产,延迟拉取。延迟接⼝相关的⽅法:
tryComplete:尝试完成,外部事件发⽣时会尝试完成延迟的操作。该⽅法返回值为true,表示可以完成延迟操作,会调⽤强制完成的⽅法(forceComplete)。返回值为false,表示不可以完成延迟操作。forceComplete:强制完成,两个地⽅调⽤,尝试完成⽅法(tryComplete)返回true时;延迟操作超时时。run:线程运⾏,延迟操作超时后,会调⽤线程的运⾏⽅法,只会调⽤⼀次,因为超时就会发⽣⼀次。超时后会调⽤强制完成⽅法(forceComplete),如果返回true,会调⽤超时的回调⽅法。onComplete:完成的回调⽅法。onExpiration:超时的回调⽅法。
外部事件触发完成和超时完成都会调⽤forceComplete(),并调⽤onComplete()。forceComplete和onComplete只会调⽤⼀次。多线程下⽤原⼦变量来控制只有⼀个线程会调⽤onComplete和forceComplete。
延迟⽣产和延迟拉取完成时的回调⽅法,尝试完成的延迟操作
副本管理器在创建延迟操作时,会把回调⽅法传给延迟操作对象。当延迟操作完成时,在onComplete⽅法中会调⽤回调⽅法,返回响应结果给客户端。
创建延迟操作对象需要提供请求对应的元数据。延迟⽣产元数据是分区的⽣产结果;延迟拉取元数据是分区的拉取信息。
创建延迟的⽣产对象之前,将消息集写⼊分区的主副本中,每个分区的⽣产结果会作为延迟⽣产的元数据。创建延迟的拉取对象之前,从分区的主副本中读取消息集,但并不会使⽤分区的拉取结果作为延迟拉取的元数据,因为延迟⽣产返回给客户端的响应结果可以直接从分区的⽣产结果中获取,⽽延迟的拉取返回给客户端的响应结果不能直接从分区的拉取结果中获取。
元数据包含返回结果的条件是:从创建延迟操作对象到完成延迟操作对象,元数据的含义不变。对于延迟的⽣产,服务端写⼊消息集到主副本返回的结果是确定的。是因为ISR中的备份副本还没有全部发送应答给主副本,才会需要创建延迟的⽣产。服务端在处理备份副本的拉取请求时,不会改变分区的⽣产结果。最后在完成延迟⽣产的操作对象时,服务端就可以把 “创建延迟操作对象” 时传递给它的分区⽣产结果直接返回给⽣产者 。对应延迟的拉取,读取了主副本的本地⽇志,但是因为消息数量不够,才会需要创建延迟的拉取,⽽不⽤分区的拉取结果⽽是⽤分区的拉取信息作为延迟拉取的元数据,是因为在尝试完成延迟拉取操作对象时,会再次读取主副本的本地⽇志,这次的读取有可能会让消息数量达到⾜够或者超时,从⽽完成延迟拉取操作对象。这样创建前和完成时延迟拉取操作对象的返回结果是不同的。但是拉取信息不管读取多少次都是⼀样的。
延迟的⽣产的外部事件是:ISR的所有备份副本发送了拉取请求;备份副本的延迟拉取的外部事件是:追加消息集到主副本;消费者的延迟拉取的外部事件是:增加主副本的最⾼⽔位。
3. 尝试完成延迟的生产服务端处理⽣产者客户端的⽣产请求,将消息集追加到对应主副本的本地⽇志后,会等待ISR中所有的备份刚本都向主副本发送应答 。⽣产请求包括多个分区的消息集,每个分区都有对应的ISR集合。当所有分区的ISR副本都向对应分区的主副本发送了应答,⽣产请求才能算完成。⽣产请求中虽然有多个分区,但是延迟的⽣产操作对象只会创建⼀个。
判断分区的ISR副本是否都已经向主副本发送了应答,需要检查ISR中所有备份副本的偏移量是否到了延迟⽣产元数据的指定偏移量(延迟⽣产的元数据是分区的⽣产结果中包含有追加消息集到本地⽇志返回下⼀个偏移量)。所以ISR所有副本的偏移量只要等于元数据的偏移量,就表示备份副本向主副本发送了应答。由于当备份副本向主副本发送拉取请求,服务端读取⽇志后,会更新对应备份副本的偏移量数据。所以在具体的实现上,备份副本并不需要真正发送应答给主副本,因为主副本所在消息代理节点的分区对象已经记录了所有副本的信息,所以尝试完成延迟的⽣产时,根据副本的偏移量就可以判断备份副本是否发送了应答。进⽽检查分区是否有⾜够的副本赶上指定偏移量,只需要判断主副本的最⾼⽔位是否等于指定偏移量(最⾼⽔位的值会选择ISR中所有备份副本中最⼩的偏移量来设置,最⼩的值都等于了指定偏移量,那么就代表所有的ISR都发送了应答)。
总结:
总结:服务端创建的延迟⽣产操作对象,在尝试完成时根据主副本的最⾼⽔位是否等于延迟⽣产操作对象中元数据的指定偏移量来判断。具体步骤:
- 服务端处理⽣产者的⽣产请求,写⼊消息集到Leader副本的本地⽇志。
- 服务端返回追加消息集的下⼀个偏移量,并且创建⼀个延迟⽣产操作对象。元数据为分区的⽣产结果(其中就包含下⼀个偏移量的值)
- 服务端处理备份副本的拉取请求,⾸先读取主副本的本地⽇志。
- 服务端返回给备份副本读取消息集,并更新备份副本的偏移量。
- 选择ISR备份副本中最⼩的偏移量更新主副本的最⾼⽔位。
- 如果主副本的最⾼⽔位等于指定的下⼀个偏移量的值,就完成延迟的⽣产。
服务端处理消费者或备份副本的拉取请求,如果创建了延迟的拉取操作对象,⼀般都是客户端的消费进度能够⼀直赶上主副本。⽐如备份副本同步主副本的数据,备份副本如果⼀直能赶上主副本,那么主副本有新消息写⼊,备份副本就会⻢上同步。但是针对备份副本已经消费到主副本的最新位置,⽽主副本并没有新消息写⼊时:服务端没有⽴即返回空的拉取结果给备份副本,这时会创建⼀个延迟的拉取操作对象,如果有新的消息写⼊,服务端会等到收集⾜够的消息集后,才返回拉取结果给备份副本,有新的消息写⼊,但是还没有收集到⾜够的消息集,等到延迟操作对象超时后,服务端会读取新写⼊主副本的消息后,返回拉取结果给备份副本(完成延迟的拉取时,服务端还会再读取⼀次主副本的本地⽇志,返回新读取出来的消息集)。
客户端的拉取请求包含多个分区,服务端判断拉取的消息⼤⼩时,会收集拉取请求涉及的所有分区。只要消息的总⼤⼩超过拉取请求设置的最少字节数,就会调⽤forceComplete()⽅法完成延迟的拉取。
外部事件尝试完成延迟的⽣产和拉取操作时的判断条件:

拉取偏移量是指拉取到消息⼤⼩。对于备份副本的延迟拉取,主副本的结束偏移量是它的最新偏移量(LEO)。对于消费者的拉取延迟,主副本的结束偏移量是它的最⾼⽔位(HW)。备份副本要时刻与主副本同步,消费者只能消费到主副本的最⾼⽔位。
5. ⽣产请求和拉取请求的延迟缓存客户端的⼀个请求包括多个分区,服务端为每个请求都会创建⼀个延迟操作对象。⽽不是为每个分区创建⼀个延迟操作对象。服务端的“延迟操作缓存”管理了所有的“延迟操作对象”,缓存的键是每⼀个分区,缓存的值是分区对应的延迟操作列表。
⼀个客户端请求对应⼀个延迟操作,⼀个延迟操作对应多个分区。在延迟缓存中,⼀个分区对应多个延迟操作。延迟缓存中保存了分区到延迟操作的映射关系。
根据分区尝试完成延迟的操作,因为⽣产者和消费者是以分区为最⼩单位来追加消息和消费消息。虽然延迟操作的创建是针对⼀个请求,但是⼀个请求中会有多个分区,在⽣产者追加消息时,⼀个⽣产请求总的不同分区包含的消息是不⼀样的。这样追加到分区对应的主副本的本地⽇志中,有的分区就可以去完成延迟的拉取,但是有的分区有可能还达不到完成延迟拉取操作的条件。同样完成延迟的⽣产也⼀样。所以在延迟缓存中要以分区为键来存储各个延迟操作。
由于⼀个请求创建⼀个延迟操作,⼀个请求⼜会包含多个分区,所以不同的延迟操作可能会有相同的分区。在加⼊到延迟缓存时,每个分区都对应相同的延迟操作。外部事件发⽣时,服务端会以分区为粒度,尝试完成这个分区中的所有延迟操作 。 如果指定分区对应的某个延迟操作可以被完成,那么延迟操作会从这个分区的延迟操作列表中移除。但这个延迟操作还有其他分区,其他分区中已经被完成的延迟操作也需要从延迟缓存中删除。但是不会⽴即被删除,因为分区作为延迟缓存的键,在服务端的数量会很多。只要分区对应的延迟操作完成了⼀个,就要⽴即检查所有分区,对服务端的性能影响⽐较⼤。所以采⽤⼀个清理器,会负责定时地清理所有分区中已经完成的延迟操作。
副本管理器针对⽣产请求和拉取请求都分别有⼀个全局的延迟缓存。⽣产请求对应延迟缓存中存储了延迟的⽣产。拉取请求对应延迟缓存中存储了延迟的拉取。
延迟缓存提供了两个⽅法:
- tryCompleteElseWatch():尝试完成延迟的操作,如果不能完成,将延迟操作加⼊延迟缓存中。⼀旦将延迟操作加⼊延迟缓存的监控,延迟操作的每个分区都会监视该延迟操作。换句话说就是每个分区发⽣了外部事件后,都会去尝试完成延迟操作。
- checkAndComplete():参数是延迟缓存的键,外部事件调⽤该⽅法,根据指定的键尝试完成延迟缓存中的延迟操作。
延迟缓存在调⽤tryCompleteElseWatch⽅法将延迟操作加⼊延迟缓存之前,会先尝试⼀次完成延迟的操作,如果不能完成,会调⽤⽅法将延迟操作加⼊到分区对应的监视器,之后还会尝试完成⼀次延迟操作,如果还不能完成,会将延迟操作加⼊定时器。如果前⾯的加⼊过程中,可以完成延迟操作后,那么就可以不⽤加⼊到其他分区的延迟缓存了。
延迟操作不仅存在于延迟缓存中,还会被定时器监控。定时器的⽬的是在延迟操作超时后,服务端可以强制完成延迟操作返回结果给客户端。延迟缓存的⽬的是让外部事件去尝试完成延迟操作。
6. 监视器延迟缓存的每个键都有⼀个监视器(类似每个分区有⼀个监视器),以链表结构来管理延迟操作。当外部事件发⽣时,会根据给定的键,调⽤这个键的对应监视器的tryCompleteWatch()⽅法,尝试完成监视器中所有的延迟操作。监视器尝试完成所有延迟操作的过程中,会调⽤每个延迟操作的tryComplete()⽅法,判断能否完成延迟的操作。如果能够完成,就从链表中删除对应的延迟操作。
7. 清理线程清理线程的作⽤是清理所有监视器中已经完成的延迟操作。
8. 定时器服务端创建的延迟操作会作为⼀个定时任务,加⼊定时器的延迟队列中。当延迟操作超时后,定时器会将延迟操作从延迟队列中弹出,并调⽤延迟操作的运⾏⽅法,强制完成延迟的操作。
定时器使⽤延迟队列管理服务端创建的所有延迟操作,延迟队列的每个元素是定时任务列表,⼀个定时任务列表可以存放多个定时任务条⽬。服务端创建的延迟操作对象,会先包装成定时任务条⽬,然后加⼊延迟队列指定的⼀个定时任务列表。延迟队列是定时器中保存定时任务列表的全局数据结构,服务端创建的延迟操作不是直接加⼊定时任务列表,⽽是加⼊时间轮。
时间轮和延迟队列的关系:
- 定时器拥有⼀个全局的延迟队列和时间轮,所有时间轮公⽤⼀个计数器。
- 时间轮持有延迟队列的引⽤。
- 定时任务条⽬添加到时间轮对应的时间格(槽)(槽中是定时任务列表)中,并且把该槽表也会加⼊到延迟队列中。
- ⼀个线程会将超时的定时任务列表会从延迟队列的poll⽅法弹出。定时任务列表超时并不⼀定代表定时任务超时,将定时任务重新加⼊时间轮,如果加⼊失败,说明定时任务确实超时,提交给线程池执⾏。
- 延迟队列的poll⽅法只会弹出超时的定时任务列表,队列中的每个元素(定时任务列表)按照超时时间排序,如果第⼀个定时任务列表都没有过期,那么其他定时任务列表也⼀定不会超时。
延迟操作本身的失效时间是客户端请求设置的,延迟队列的元素(每个定时任务列表)也有失效时间,当定时任务列表中的getDelay()⽅法返回值⼩于等于0,就表示定时任务列表已经过期,需要⽴即执⾏。
如果当前的时间轮放不下加⼊的时间时,就会创建⼀个更⾼层的时间轮。定时器只持有第⼀层的时间轮的引⽤,并不会持有更⾼层的时间轮。因为第⼀层的时间轮会持有第⼆层的时间轮的引⽤,第⼆层会持有第三层的时间轮的引⽤。定时器将定时任务加⼊到当前时间轮,要判断定时任务的失效时间⾸是否在当前时间轮的范围内,如果不在当前时间轮的范围内,则要将定时任务上升到更⾼⼀层的时间轮中。时间轮包含了定时器全局的延迟队列。
时间轮中的变量:tickMs=1:表示⼀格的⻓度是1毫秒;wheelSize=20表示⼀共20格,时间轮的范围就是20毫秒,定时任务的失效时间⼩于等于20毫秒的都会加⼊到这⼀层的时间轮中;interval=tickMs*wheelSize=20,如果需要创建更⾼⼀层的时间轮,那么低⼀层的时间轮的interval的值作为⾼⼀层数据轮的tickMs值;currentTime当前时间轮的当前时间,往前移动时间轮,主要就是更新当前时间轮的当前时间,更新后重新加⼊定时任务条⽬。
9. 一道面试题⾯试题⼤致上是这样的:消费者去Kafka⾥拉去消息,但是⽬前Kafka中⼜没有新的消息可以提供,那么Kafka会如何处理?
如下图所示,两个follower副本都已经拉取到了leader副本的最新位置,此时⼜向leader副本发送拉取请求,⽽leader副本并没有新的消息写⼊,那么此时leader副本该如何处理呢?可以直接返回空的拉取结果给follower副本,不过在leader副本⼀直没有新消息写⼊的情况下,follower副本会⼀直发送拉取请求,并且总收到空的拉取结果,这样徒耗资源,显然不太合理。
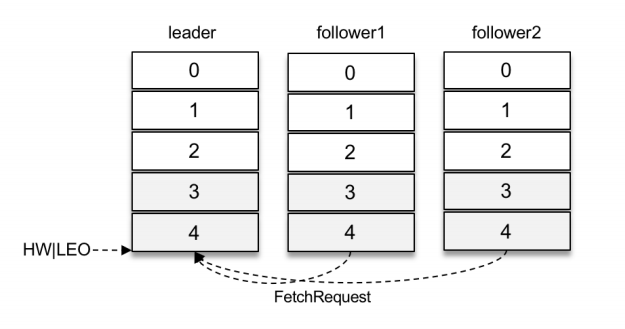
这⾥就涉及到了Kafka延迟操作的概念。Kafka在处理拉取请求时,会先读取⼀次⽇志⽂件,如果收集不到⾜够多(fetchMinBytes,由参数fetch.min.bytes配置,默认值为1)的消息,那么就会创建⼀个延时拉取操作(DelayedFetch)以等待拉取到⾜够数量的消息。当延时拉取操作执⾏时,会再读取⼀次⽇志⽂件,然后将拉取结果返回给follower副本。
延迟操作不只是拉取消息时的特有操作,在Kafka中有多种延时操作,⽐如延时数据删除、延时⽣产等。
对于延时⽣产(消息)⽽⾔,如果在使⽤⽣产者客户端发送消息的时候将acks参数设置为-1,那么就意味着需要等待ISR集合中的所有副本都确认收到消息之后才能正确地收到响应的结果,或者捕获超时异常。
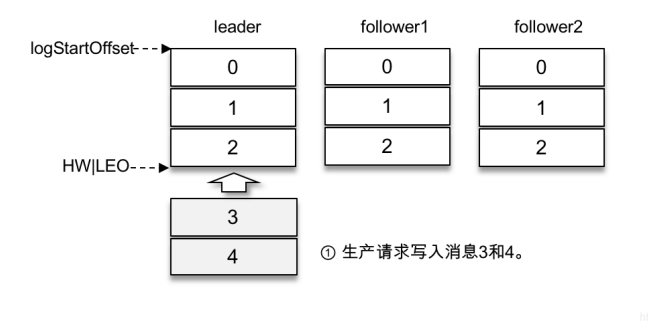
假设某个分区有3个副本:leader、follower1和follower2,它们都在分区的ISR集合中。为了简化说明,这⾥我们不考虑ISR集合伸缩的情况。Kafka在收到客户端的⽣产请求后,将消息3和消息4写⼊leader副本的本地⽇志⽂件,如上图所示。
由于客户端设置了acks为-1,那么需要等到follower1和follower2两个副本都收到消息3和消息4后才能告知客户端正确地接收了所发送的消息。如果在⼀定的时间内,follower1副本或follower2副本没能够完全拉取到消息3和消息4,那么就需要返回超时异常给客户端。⽣产请求的超时时间由参数request.timeout.ms配置,默认值为30000,即30s。
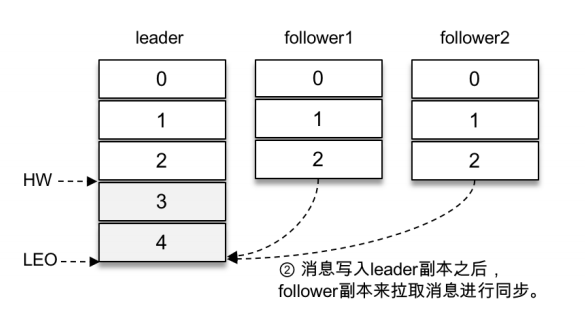
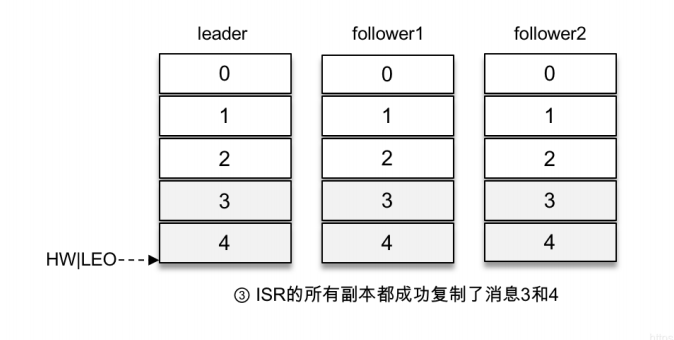
那么这⾥等待消息3和消息4写⼊follower1副本和follower2副本,并返回相应的响应结果给客户端的动作是由谁来执⾏的呢?在将消息写⼊leader副本的本地⽇志⽂件之后,Kafka会创建⼀个延时的⽣产操作(DelayedProduce),⽤来处理消息正常写⼊所有副本或超时的情况,以返回相应的响应结果给客户端。
延时操作需要延时返回响应的结果,⾸先它必须有⼀个超时时间(delayMs),如果在这个超时时间内没有完成既定的任务,那么就需要强制完成以返回响应结果给客户端。其次,延时操作不同于定时操作,定时操作是指在特定时间之后执⾏的操作,⽽延时操作可以在所设定的超时时间之前完成,所以延时操作能够⽀持外部事件的触发。
就延时⽣产操作⽽⾔,它的外部事件是所要写⼊消息的某个分区的HW(⾼⽔位)发⽣增⻓。也就是说,随着follower副本不断地与leader副本进⾏消息同步,进⽽促使HW进⼀步增⻓,HW每增⻓⼀次都会检测是否能够完成此次延时⽣产操作,如果可以就执⾏以此返回响应结果给客户端;如果在超时时间内始终⽆法完成,则强制执⾏。
回顾⼀下⽂中开头的延时拉取操作,它也同样如此,也是由超时触发或外部事件触发⽽被执⾏的。超时触发很好理解,就是等到超时时间之后触发第⼆次读取⽇志⽂件的操作。外部事件触发就稍复杂了⼀些,因为拉取请求不单单由follower副本发起,也可以由消费者客户端发起,两种情况所对应的外部事件也是不同的。如果是follower副本的延时拉取,它的外部事件就是消息追加到了leader副本的本地⽇志⽂件中;如果是消费者客户端的延时拉取,它的外部事件可以简单地理解为HW的增⻓。
二、重试队列kafka没有重试机制不⽀持消息重试,也没有死信队列,因此使⽤kafka做消息队列时,需要⾃⼰实现消息重试的功能。
自己实现(创建新的kafka主题作为重试队列):
- 创建⼀个topic作为重试topic,⽤于接收等待重试的消息。
- 普通topic消费者设置待重试消息的下⼀个重试topic。
- 从重试topic获取待重试消息储存到redis的zset中,并以下⼀次消费时间排序
- 定时任务从redis获取到达消费事件的消息,并把消息发送到对应的topic
- 同⼀个消息重试次数过多则不再重试