在之前的学习过程当中,对于损失函数的最为重要的参数的梯度的更新是基于数据集中的所有数据,每一个数据都会进行到计算过程当中去,在本案例中,因为波士顿房价预测这个案例所涉及的数据并没有很多,还能够适用于这样的基于所有数据的计算。然而在实际的应用当中,很多时候都是需要很大量的数据集的,因此,这里就提出了随机梯度下降的这样一个概念。即在整个的样本中抽取一小部分的数据进行梯度的更新,这样做的好处在于虽然没有特别精确,但是能够大大的优化整个计算的性能。
其核心概念有三个:①mini-batch,即每次迭代时从样本中抽取出来的一批数据,就称为一个mini-batch。②batch-size,即一个mini-batch中所包含的样本数目。③epoch,即当程序迭代的时候,按mini-batch逐渐抽取出样本,当把整个数据集都遍历到了的时候,则完成了一轮训练,也叫一个epoch。启动训练时,可以将训练的轮数num_epochs和batch_size作为参数传入。
其对于代码的更新为:
1 def train(self, training_data, num_epoches, batch_size=10, eta=0.01): 2 n = len(training_data) 3 losses = [] 4 for epoch_id in range(num_epoches): 5 # 打乱样本顺序 6 np.random.shuffle(training_data) 7 # 将train_data分成多个mini_batch 8 # 循环取值,每次取出batch_size条数据 9 mini_batches = [training_data[k:k + batch_size] for k in range(0, n, batch_size)] 10 for iter_id, mini_batche in enumerate(mini_batches): 11 # 取mini_batch的前13列 12 x = mini_batche[:, :-1] 13 # 取mini_batch的最后1列 14 y = mini_batche[:, -1:] 15 # 前向计算 16 a = self.forward(x) 17 # 计算损失 18 loss = self.loss(a, y) 19 # 计算梯度 20 gradient_w, gradient_b = self.gradient(x, y) 21 # 更新参数 22 self.update(gradient_w, gradient_b, eta) 23 losses.append(loss) 24 print('Epoch {:3d} / iter {:3d}, loss = {:.4f}'.format(epoch_id, iter_id, loss)) 25 return losses
其中设置batch-size为10,即对于训练的404条数据而言,每10条作为一个mini-batche,只有最后一组剩下了4个样本,但是这里同样是需要作为一组mini-batche。然后是为了达到对样本顺序打乱得到一个随机的效果,这里会用到一个函数shuffle,它这里是对于一个二维数组而言,它只随机改变第0维的顺序关系,之后与0维同一个维度的数据是不会随机的改变的,其实类比过来就是矩阵中的行变换。然后是通过对每一个随机的mini-batche进行梯度的运算以及梯度在相应学习率下进行不断的更新。因为之前的梯度下降是建立在所有数据的条件下,而现在是对于整个样本的一个随机切分,从而能够使得在大体的趋势之下依旧是能够进行最终解的寻找任务的。
接下来就是设置mini-batches,batche-size参数输入:
1 # 启动训练,训练50轮,每轮样本数目为100,步长为0.1 2 losses = net.train(training_data, num_epoches=50, batch_size=100, eta=0.1)
可以看见设置epoches,即训练的轮次数为50,样本每次取出的个数为100,学习率为0.1进行训练,得到的训练数据为:

为了更加直观的观察出整个Loss函数的一个减少过程,通过绘图的方式对齐进行绘出:
1 # 画出损失函数的变化趋势 2 plot_x = np.arange(len(losses)) 3 plot_y = np.array(losses) 4 plt.plot(plot_x, plot_y) 5 plt.show()
得到的图表为:
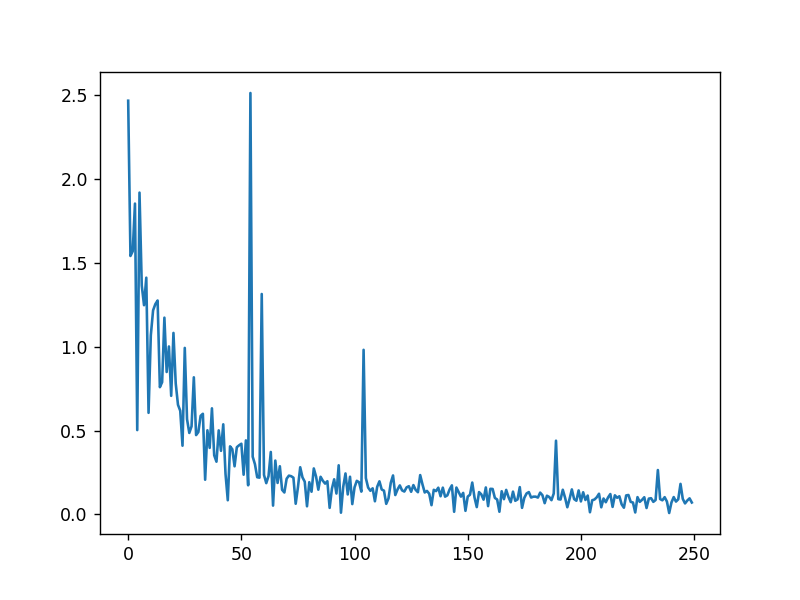
可以发现它并没有之前梯度下降时候的那种平滑,像一个锯齿一样,这跟随机选取数据进行学习有关,但是最终的走势依旧是不断减少的,因此这能够极大的提高学习的性能。
2、飞桨平台 2.1 提供深度学习框架
①能够将大量最为底层的代码逻辑进行一种类似于封装的过程,搭建起一个可以直接实现功能的应用框架,开发人员只需要进行进行逻辑的思考和建模本身即可。
②既然是框架,那么就会有比较灵活的移植性,同种框架可以在不同的场景进行适配运用,省去环境搭建的过程。
2.2 深度学习框架思想①通用性,即模型最为基础的部分,是一切模型走向不同的基础点。
②特有性,即根据建模者思想的不同,对功能进行专有化的过程。
2.3 飞桨深度学习开源平台 3、使用飞桨重写波士顿房价预测任务通过对飞桨平台的学习,要能够利用诸多飞桨平台的组件进行更加实用化的功能的开发。
3.1 加载库对于库,其中要进行说明的是,
-
paddle:飞桨的主库,paddle 根目录下保留了常用API的别名,当前包括:paddle.tensor、paddle.framework、paddle.device目录下的所有API;
-
Linear:神经网络的全连接层函数,包含所有输入权重相加的基本神经元结构。在房价预测任务中,使用只有一层的神经网络(全连接层)实现线性回归模型;
-
paddle.nn:组网相关的API,包括 Linear、卷积 Conv2D、循环神经网络LSTM、损失函数CrossEntropyLoss、激活函数ReLU等;
-
paddle.nn.functional:与paddle.nn一样,包含组网相关的API,如:Linear、激活函数ReLU等,二者包含的同名模块功能相同,运行性能也基本一致。 差别在于paddle.nn目录下的模块均是类,每个类自带模块参数;paddle.nn.functional目录下的模块均是函数,需要手动传入函数计算所需要的参数。在实际使用时,卷积、全连接层等本身具有可学习的参数,建议使用paddle.nn;而激活函数、池化等操作没有可学习参数,可以考虑使用paddle.nn.functional。
1 #加载飞桨、NumPy和相关类库 2 import paddle 3 from paddle.nn import Linear 4 import paddle.nn.functional as F 5 import numpy as np 6 import os 7 import random
3.2 数据处理
数据处理的代码不依赖框架实现,与使用Python构建房价预测任务的代码相同:
1 def load_data(): 2 # 从文件导入数据 3 datafile = './work/housing.data' 4 data = np.fromfile(datafile, sep=' ', dtype=np.float32) 5 6 # 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数 7 feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \ 8 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ] 9 feature_num = len(feature_names) 10 11 # 将原始数据进行Reshape,变成[N, 14]这样的形状 12 data = data.reshape([data.shape[0] // feature_num, feature_num]) 13 14 # 将原数据集拆分成训练集和测试集 15 # 这里使用80%的数据做训练,20%的数据做测试 16 # 测试集和训练集必须是没有交集的 17 ratio = 0.8 18 offset = int(data.shape[0] * ratio) 19 training_data = data[:offset] 20 21 # 计算train数据集的最大值,最小值,平均值 22 maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \ 23 training_data.sum(axis=0) / training_data.shape[0] 24 25 # 记录数据的归一化参数,在预测时对数据做归一化 26 global max_values 27 global min_values 28 global avg_values 29 max_values = maximums 30 min_values = minimums 31 avg_values = avgs 32 33 # 对数据进行归一化处理 34 for i in range(feature_num): 35 data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i]) 36 37 # 训练集和测试集的划分比例 38 training_data = data[:offset] 39 test_data = data[offset:] 40 return training_data, test_data
3.3 模型设计 模型定义的实质是定义线性回归的网络结构,飞桨建议通过创建Python类的方式完成模型网络的定义,该类需要继承paddle.nn.Layer父类,并且在类中定义init函数和forward函数。forward函数是框架指定实现前向计算逻辑的函数,程序在调用模型实例时会自动执行,forward函数中使用的网络层需要在init函数中声明。
- 定义init函数:在类的初始化函数中声明每一层网络的实现函数。在房价预测任务中,只需要定义一层全连接层。
- 定义forward函数:构建神经网络结构,实现前向计算过程,并返回预测结果,在本任务中返回的是房价预测结果。
1 class Regressor(paddle.nn.Layer): 2 3 # self代表类的实例自身 4 def __init__(self): 5 # 初始化父类中的一些参数 6 super(Regressor, self).__init__() 7 8 # 定义一层全连接层,输入维度是13,输出维度是1 9 self.fc = Linear(in_features=13, out_features=1) 10 11 # 网络的前向计算 12 def forward(self, inputs): 13 x = self.fc(inputs) 14 return x
3.4 训练配置
其流程为:
①指定运行训练的机器资源:默认使用AI Studio训练模型;
②声明模型实例:声明定义好的回归模型实例为Regressor,并将模型的状态设置为train;
③加载训练和测试数据:使用load_data函数加载训练数据和测试数据;
④设置优化算法和学习率:优化算法采用随机梯度下降SGD,学习率设置为0.01。
1 # 声明定义好的线性回归模型 2 model = Regressor() 3 # 开启模型训练模式 4 model.train() 5 # 加载数据 6 training_data, test_data = load_data() 7 # 定义优化算法,使用随机梯度下降SGD 8 # 学习率设置为0.01 9 opt = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
3.5 训练过程
仍旧是和随机梯度下降一样,利用两层循环:
①内层循环: 负责整个数据集的一次遍历,采用分批次方式(batch)。假设数据集样本数量为1000,一个批次有10个样本,则遍历一次数据集的批次数量是1000/10=100,即内层循环需要执行100次。
②外层循环: 定义遍历数据集的次数,通过参数EPOCH_NUM设置。
而在每次的内循环中,还需要实现四个步骤,即:
-
数据准备:将一个批次的数据先转换成nparray格式,再转换成Tensor格式;
-
前向计算:将一个批次的样本数据灌入网络中,计算输出结果;
-
计算损失函数:以前向计算结果和真实房价作为输入,通过损失函数square_error_cost API计算出损失函数值(Loss);
-
反向传播:执行梯度反向传播
backward函数,即从后到前逐层计算每一层的梯度,并根据设置的优化算法更新参数(opt.step函数)。
1 EPOCH_NUM = 10 # 设置外层循环次数 2 BATCH_SIZE = 10 # 设置batch大小 3 4 # 定义外层循环 5 for epoch_id in range(EPOCH_NUM): 6 # 在每轮迭代开始之前,将训练数据的顺序随机的打乱 7 np.random.shuffle(training_data) 8 # 将训练数据进行拆分,每个batch包含10条数据 9 mini_batches = [training_data[k:k+BATCH_SIZE] for k in range(0, len(training_data), BATCH_SIZE)] 10 # 定义内层循环 11 for iter_id, mini_batch in enumerate(mini_batches): 12 x = np.array(mini_batch[:, :-1]) # 获得当前批次训练数据 13 y = np.array(mini_batch[:, -1:]) # 获得当前批次训练标签(真实房价) 14 # 将numpy数据转为飞桨动态图tensor的格式 15 house_features = paddle.to_tensor(x) 16 prices = paddle.to_tensor(y) 17 18 # 前向计算 19 predicts = model(house_features) 20 21 # 计算损失 22 loss = F.square_error_cost(predicts, label=prices) 23 avg_loss = paddle.mean(loss) 24 if iter_id%20==0: 25 print("epoch: {}, iter: {}, loss is: {}".format(epoch_id, iter_id, avg_loss.numpy())) 26 27 # 反向传播,计算每层参数的梯度值 28 avg_loss.backward() 29 # 更新参数,根据设置好的学习率迭代一步 30 opt.step() 31 # 清空梯度变量,以备下一轮计算 32 opt.clear_grad()
得到的结果为:

3.6 模型保存
1 # 保存模型参数,文件名为LR_model.pdparams 2 paddle.save(model.state_dict(), 'LR_model.pdparams') 3 print("模型保存成功,模型参数保存在LR_model.pdparams中")
结果为:
![]()
3.7 模型预测
对上述保存的模型进行利用,来对数据进行预测,这里是随机选取样本之中的一个数据,来进行处理,分为三个步骤:
① 配置模型预测的机器资源。现在默认使用本机,因此无需写代码指定。
② 将训练好的模型参数加载到模型实例中。由两个语句完成,第一句是从文件中读取模型参数;第二句是将参数内容加载到模型。加载完毕后,需要将模型的状态调整为eval()(校验)。上文中提到,训练状态的模型需要同时支持前向计算和反向传导梯度,模型的实现较为臃肿,而校验和预测状态的模型只需要支持前向计算,模型的实现更加简单,性能更好;
③ 将待预测的样本特征输入到模型中,打印输出的预测结果。
通过load_one_example函数实现从数据集中抽一条样本作为测试样本:
1 def load_one_example(): 2 # 从上边已加载的测试集中,随机选择一条作为测试数据 3 idx = np.random.randint(0, test_data.shape[0]) 4 idx = -10 5 one_data, label = test_data[idx, :-1], test_data[idx, -1] 6 # 修改该条数据shape为[1,13] 7 one_data = one_data.reshape([1,-1]) 8 9 return one_data, label
然后进行预测:
1 # 参数为保存模型参数的文件地址 2 model_dict = paddle.load('LR_model.pdparams') 3 model.load_dict(model_dict) 4 model.eval() 5 6 # 参数为数据集的文件地址 7 one_data, label = load_one_example() 8 # 将数据转为动态图的variable格式 9 one_data = paddle.to_tensor(one_data) 10 predict = model(one_data) 11 12 # 对结果做反归一化处理 13 predict = predict * (max_values[-1] - min_values[-1]) + avg_values[-1] 14 # 对label数据做反归一化处理 15 label = label * (max_values[-1] - min_values[-1]) + avg_values[-1] 16 17 print("预测值为 {}, 原样本标签值为 {}".format(predict.numpy(), label))
结果为:
![]()
通过结果可以发现,预测值与真实值是比较接近的,即该模型能够在该简单的线性问题上得到处理。
4、Numpy基本概念NumPy(Numerical Python的简称)是高性能科学计算和数据分析的基础包。
4.1 Numpy功能-
ndarray数组:一个具有矢量算术运算和复杂广播能力的多维数组,具有快速且节省空间的特点;
-
对整组数据进行快速运算的标准数学函数(无需编写循环);
-
线性代数、随机数生成以及傅里叶变换功能;
-
读写磁盘数据、操作内存映射文件。
4.2 创建ndarry数组
通过这种数组的方式,能够不再写复杂的循环,就能够对数据进行处理,该数组的四个主要函数为:
①:array(),创建嵌套序列(比如由一组等长列表组成的列表),并转换为一个多维数组。
②:arange(),创建元素从0到10依次递增2的数组。
③:zeros(),创建指定长度或者形状的全0数组。
④:ones(),创建指定长度或者形状的全1数组。
4.3 ndarry数组属性
shape:数组的形状 ndarray.shape,1维数组(N, ),二维数组(M, N),三维数组(M, N, K)。
dtype:数组的数据类型。
size:数组中包含的元素个数 ndarray.size,其大小等于各个维度的长度的乘积。
ndim:数组的维度大小,ndarray.ndim, 其大小等于ndarray.shape所包含元素的个数。
-
标量和ndarray数组之间的运算
-
两个ndarray数组之间的运算,(数组 乘以 数组,用对应位置的元素相乘)
-
mean:计算算术平均数,零长度数组的mean为NaN。 -
std和var:计算标准差和方差,自由度可调(默认为n)。 -
sum:对数组中全部或某轴向的元素求和,零长度数组的sum为0。 -
max和min:计算最大值和最小值。 -
argmin和argmax:分别为最大和最小元素的索引。 -
cumsum:计算所有元素的累加。 -
cumprod:计算所有元素的累积。
-
diag:以一维数组的形式返回方阵的对角线(或非对角线)元素,或将一维数组转换为方阵(非对角线元素为0)。 -
dot:矩阵乘法。 -
trace:计算对角线元素的和。 -
det:计算矩阵行列式。 -
eig:计算方阵的特征值和特征向量。 -
inv:计算方阵的逆。
5、总结
在本周的学习当中,通过对梯度算法的进一步理解,分清随机梯度的优越性,同时对飞桨平台有着深入的了解与进行了相关的实际操作。此外,对Numpy概念进行了梳理与学习,之后将进行Numpy的实际运用以及更多深度学习的实例项目学习与实现。
6、参考资料Numpy小例子:https://aistudio.baidu.com/aistudio/projectdetail/4325291
重写波士顿房价预测:https://aistudio.baidu.com/aistudio/projectdetail/4317026
python函数详解:https://www.runoob.com/python/python-func-enumerate.html