link:https://arxiv.org/abs/2002.07962
本文提出了时间图注意(TGAT)层,以有效地聚合时间-拓扑邻域特征,并学习时间-特征之间的相互作用。对于TGAT,本文采用自注意机制作为构建模块,并基于调和分析中的经典Bochner定理(又是没见过的定理QAQ)发展了一种新的函数时间编码技术。
Conclusion本文提出了一种新颖的时间感知图注意网络,用于时间图上的归纳表示学习。采用自我注意机制来处理连续时间,提出了一种理论基础上的函数时间编码。未来作者往自注意力机制的可解释性和模型的可视化进行工作
Figure and table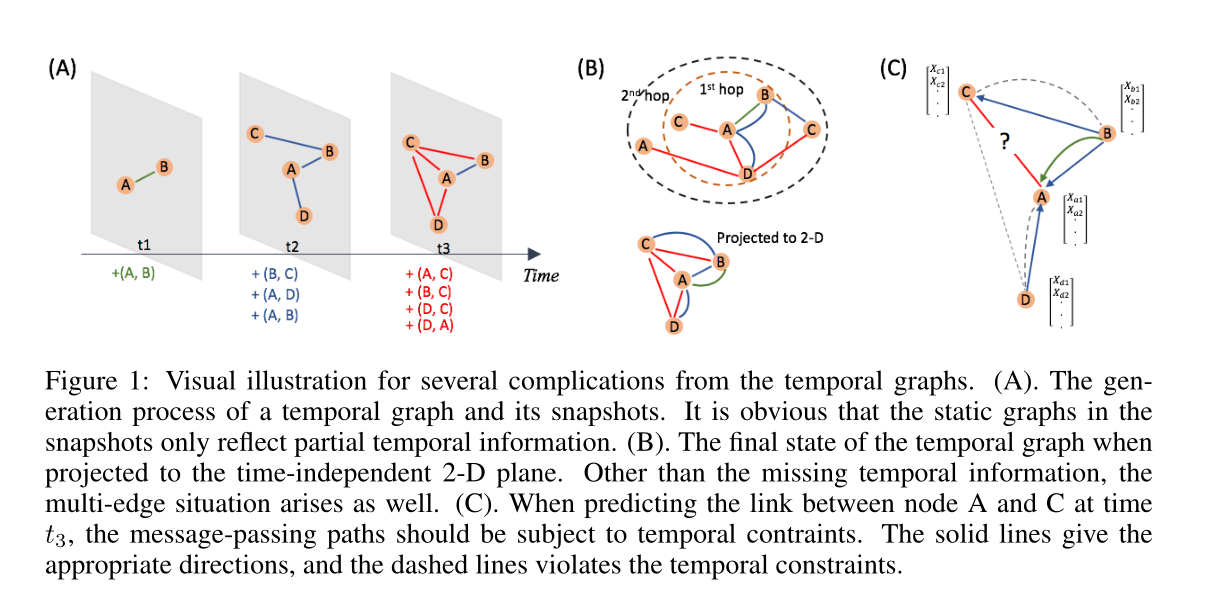
图1 时序图几个复杂情况的可视化。A) 时序图和其快照生成过程,可以看见在快照中的静态图只能反映时序信息的一部分 B) 时间图投影到独立于时间的二维平面时的最终状态。除了时间信息缺失之外,还会出现多边情况。C) 在预测t3时刻节点A和C之间的链路时,消息传递路径应受时间约束。实线给出了适当的方向,虚线违反了时间限制。
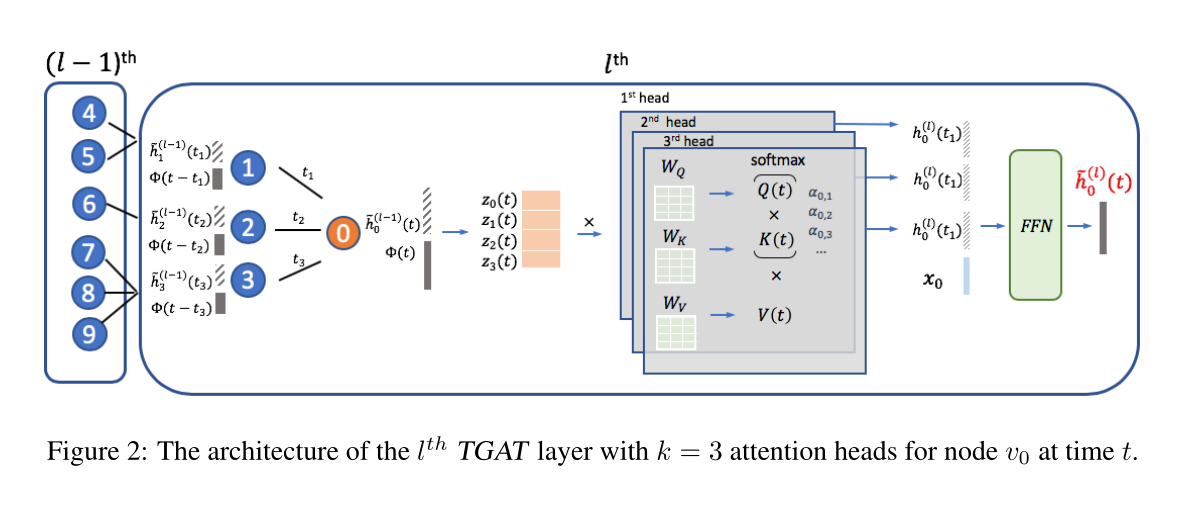
图2 对于节点\(v_0\)在时间\(t\)时刻时,第\(l\)层的TGAT层架构,其中\(k=3\)为多头注意力的参数,表示头数
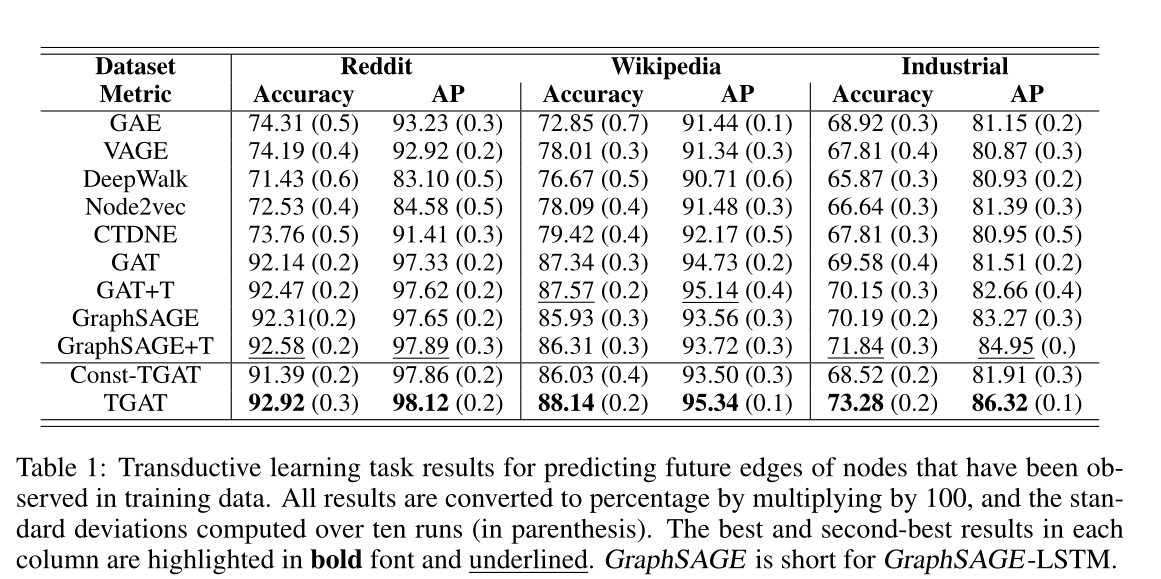
表1 用于预测训练数据中,观察到节点的未来边缘的直接学习(Transductive learning)任务结果。
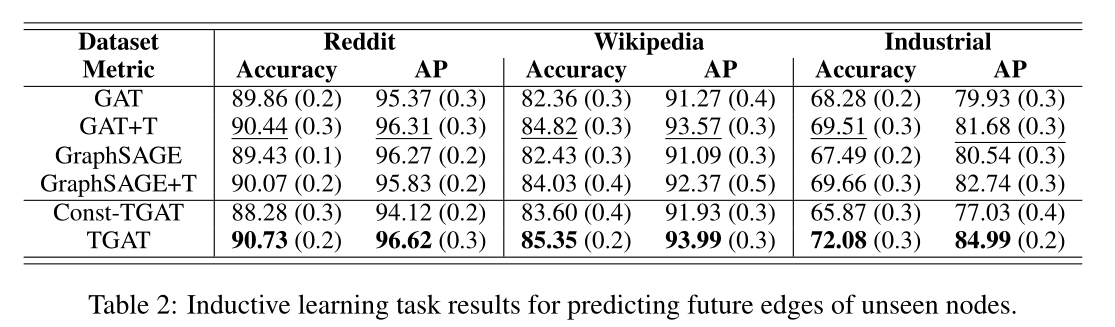
表2 预测未观察节点未来边的归纳学习任务结果。
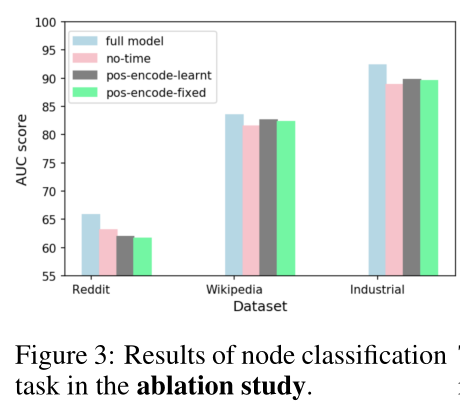
图3 消融实验中节点分类任务的结果。
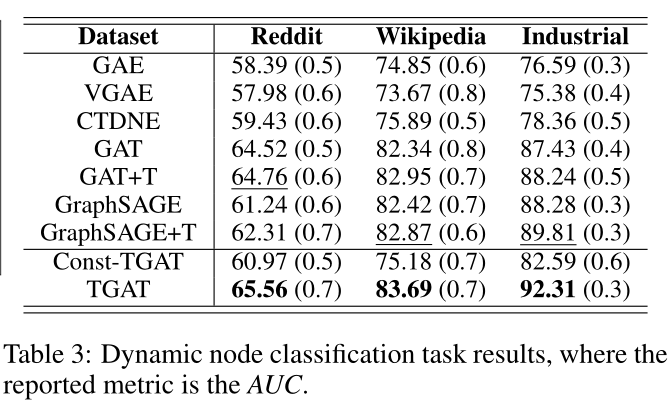
表3 动态节点分类任务结果,其中指标为AUC。
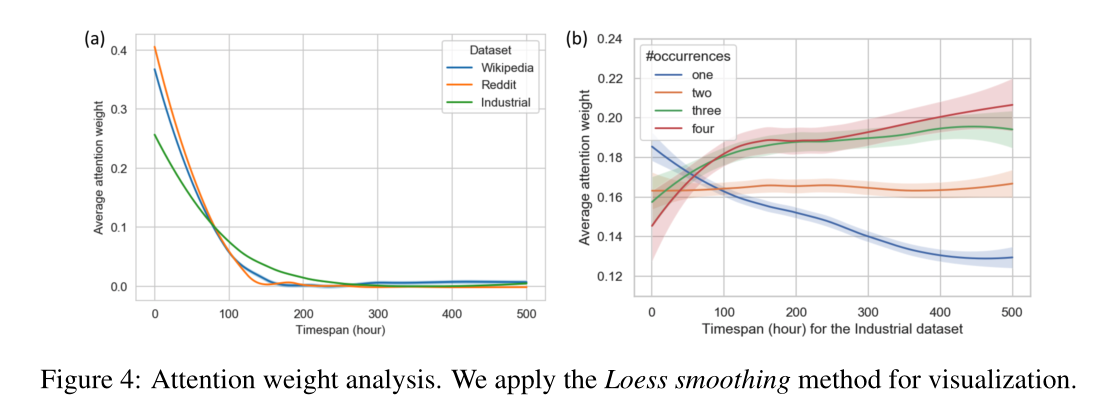
图4 注意力权重分析。本文采用本地散点平滑估计(Locally Estimated Scatterplot Smoothing,LOESS)进行可视化。
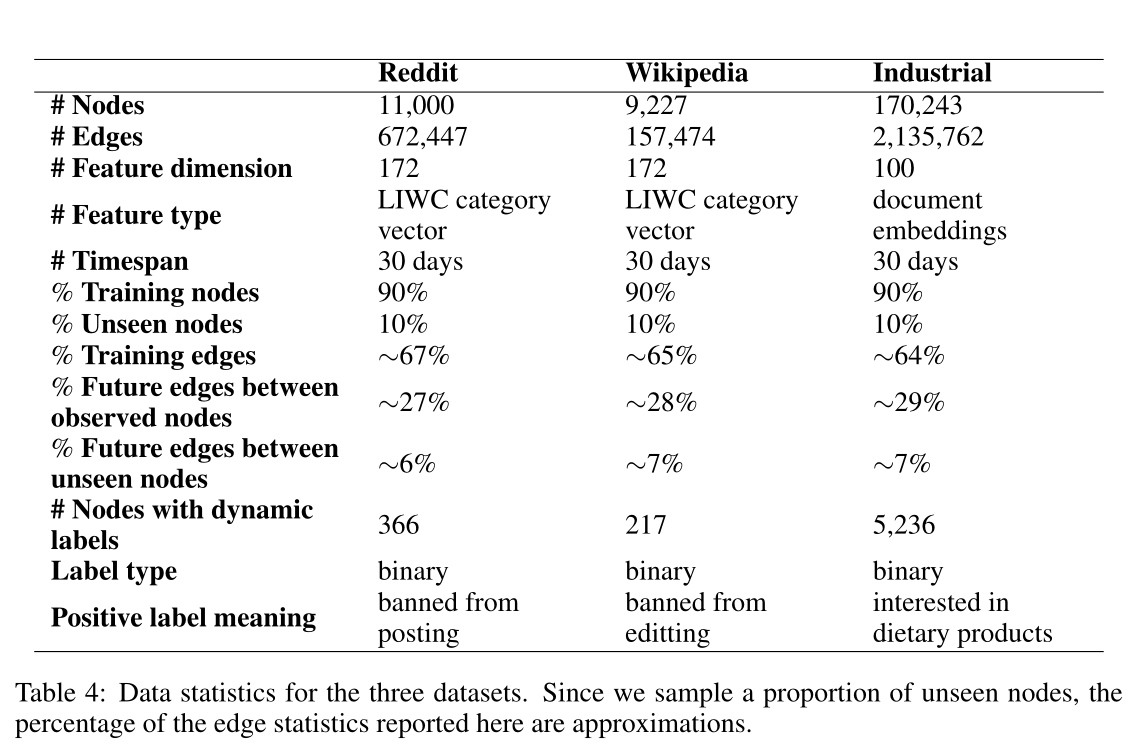
表4 三个数据集的数据统计。由于本文对一部分未观察到的节点进行采样,因此这里报告的边统计数据的百分比是近似的。
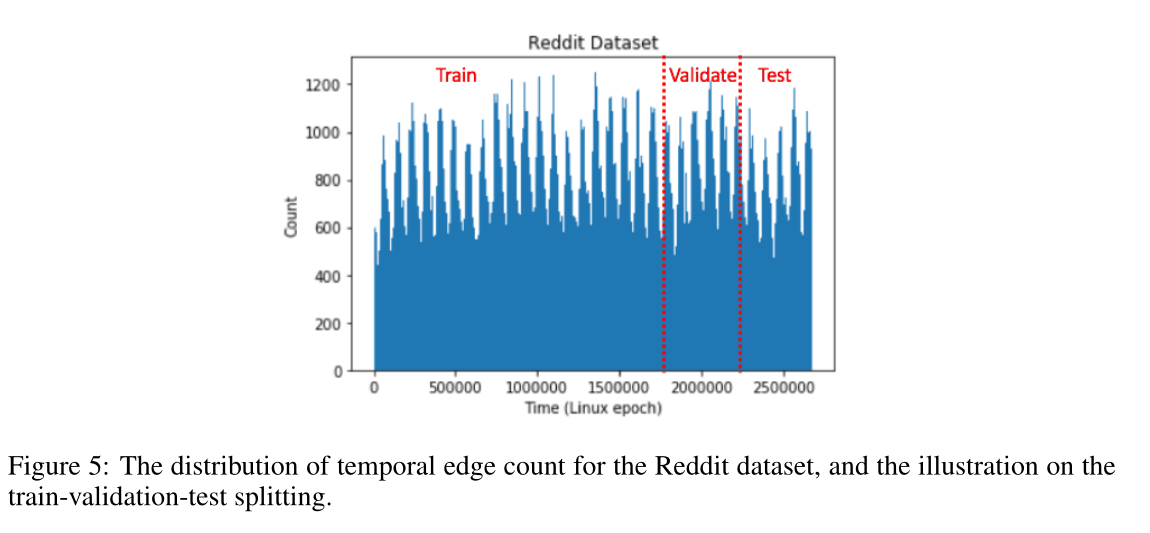
图5 Reddit数据集的时序边数分布,以及训练-验证-测试分别的图。
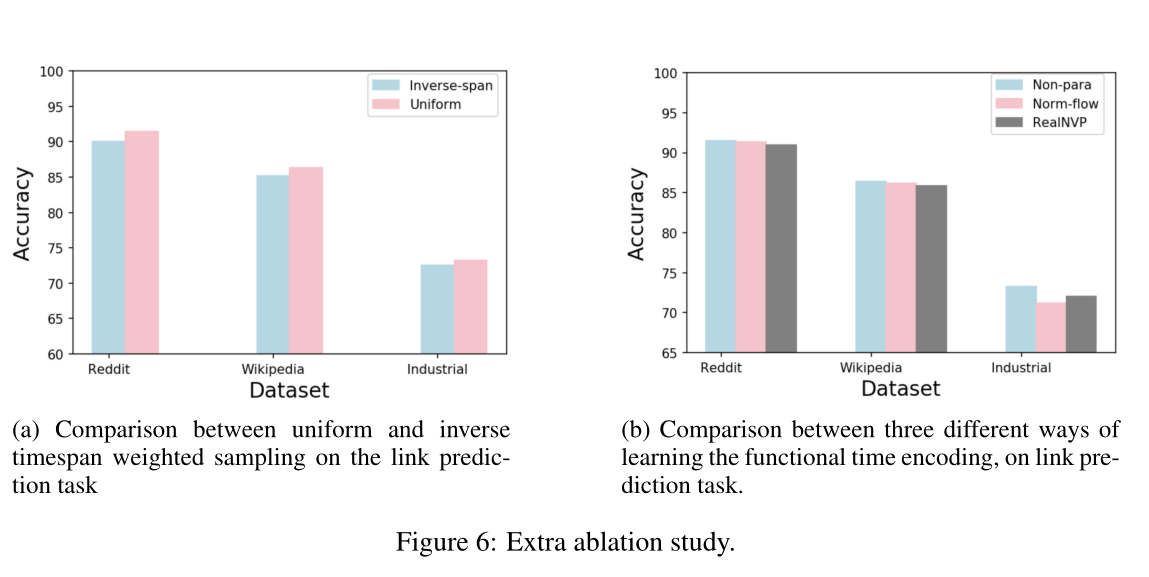
图6 额外的消融实验,(a)链路预测任务的均匀时间加权抽样和逆时间加权抽样的比较,(b)比较三种不同的学习方法的函数时间编码,实现链路预测任务。
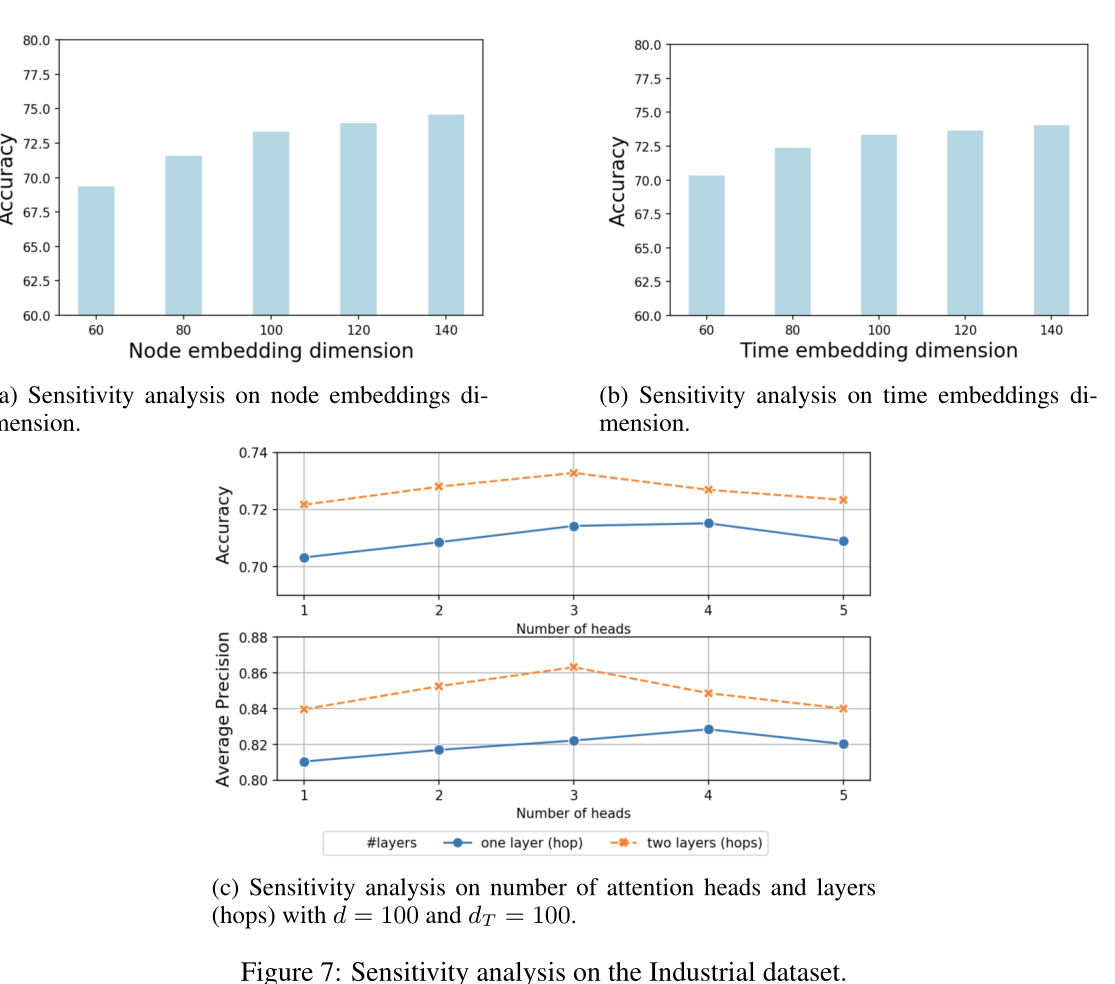
图7 Industrial 数据集的敏感性分析。(a) 节点嵌入维度对正确率的影响(b) 时间嵌入维度对正确率的影响(C)自注意力头数对平均精度的影响
Introduction学习时态图上的表示极其具有挑战性,直到最近才提出了几种解决方案(CTDNE.;Deep dynamic network embedding for link prediction;Dyngem;Representation learning over dynamic graphs)。可以从三个方面总结这些挑战。
首先,对时间动态模型进行建模时,节点嵌入不应仅仅是拓扑结构和节点特征的投影,而应是连续时间的函数。因此,除了通常的向量空间外,时间表示学习还需要在一些函数空间中进行操作。*
其次,图的拓扑结构不再是静态的,因为节点和边会随着时间的推移而变化,提出了邻域聚合方法的时间约束。*
第三,节点特征和拓扑结构具有时序特征。例如,很久以前发生的节点交互可能对当前拓扑结构和节点嵌入的影响较小。此外,一些节点可能具有允许它们与其他节点进行更定期或反复的交互的特性。我们在图1中提供了可视化的示意图。*
在真实的应用程序中,时间图上的表示学习模型应该能够在需要时以归纳的方式快速生成嵌入。GraphSAGE 和图注意网络(GAT) 能够根据不可见节点的特征归纳生成嵌入,然而,它们没有考虑时间因素。大多数时间图嵌入方法只能处理转导任务(如何理解 inductive learning 与 transductive learning? https://www.zhihu.com/question/68275921),它们需要重新训练或梯度计算来推断不可见节点的嵌入或新时间点的节点嵌入。在这项工作中,目标是开发一种架构来归纳学习时间图的表示,这样时间感知嵌入(对于不可见和观察的节点)可以通过单个网络前向传递获得。我们方法的关键是将自我注意机制和一种新的函数时间编码技术结合起来,该技术源自经典调和分析中的Bochner 's定理。
在时间图上适应自注意归纳表示学习的动机是识别和捕获时间邻域信息的相关片段。在聚合节点特征时,图卷积网络和GAT都隐式或显式地为相邻节点分配不同的权值(信息的加权求和)。自注意机制最初是为了识别自然语言处理中输入序列的相关部分而设计的。作为一种离散事件序列学习方法,自注意的输出嵌入为输入序列的每个嵌入加权求和。自我注意具有并行计算和可解释性等优点 。由于它只通过位置编码捕获顺序信息,所以不能处理时间特征。因此,本文考虑用时间的矢量表示来替代位置编码。由于时间是一个连续变量,从时域到向量空间的映射必须是函数式的。本文从谐波分析中获得见解,并提出了一种时间编码方法,这与自我注意机制兼容。然后,通过函数时间编码和节点特征以及图拓扑结构之间的相互作用对时间信号进行建模。
为了评估我们的方法,我们将观察节点上的未来链接预测视为转导学习任务,而将未观察节点上的未来链接预测视为归纳学习任务。
Method提一下在related work里的自注意力机制: https://zhuanlan.zhihu.com/p/265108616(Attention注意力机制与self-attention自注意力机制)
自我注意机制通常有两个组成部分:嵌入层和注意力层。嵌入层以一个有序的实体序列作为输入。自注意使用的是位置编码,即每个位置\(k\)都配备一个固定的或学习的向量\(\mathbf{p}_{k}\),所有序列都共享这个向量\(\mathbf{p}_{k}\)。对于实体序列\(\mathbf{e} = (e_1,…, e_l)\),嵌入层以实体嵌入(\(\bf{z} \in \mathbb{R}^d\))及其位置编码的加和或拼接为输入:
\[\begin{aligned} 加和:\mathbf{Z}_{\mathbf{e}}=\left[\mathbf{z}_{e_{1}}+\mathbf{p}_{1}, \ldots, \mathbf{z}_{e_{1}}+\mathbf{p}_{l}\right]^{\top} \in \mathbb{R}^{l \times d},\\\text {拼接} \quad \mathbf{Z}_{\mathbf{e}}=\left[\mathbf{z}_{e_{1}}\left\|\mathbf{p}_{1}, \ldots, \mathbf{z}_{e_{1}}\right\| \mathbf{p}_{l}\right]^{\top} \in \mathbb{R}^{l \times\left(d+d_{\mathrm{pos}}\right)} \end{aligned}(1) \]其中\(||\)是拼接操作, \(d_{pos}\)是位置编码的维度
自我注意层可以使用缩放的点积注意来构建,定义为:
\[\operatorname{Attn}(\mathbf{Q},\mathbf{K},\mathbf{V})=\operatorname{softmax}\left(\frac{\mathbf{Q}\mathbf{K}^{\top}}{\sqrt{d}}\right) \mathbf{V}(2) \]其中,\(\mathbf{Q}\)代表'queries',\(\mathbf{K}\)代表'key',\(\mathbf{V}\)代表'value'
计算如下
\[\mathbf{Q}=\mathbf{Z}_{\mathbf{e}} \mathbf{W}_{Q}, \quad \mathbf{K}=\mathbf{Z}_{\mathbf{e}} \mathbf{W}_{K}, \quad \mathbf{V}=\mathbf{Z}_{\mathbf{e}} \mathbf{W}_{V} \]其中\(\mathbf{W}_{Q},\mathbf{W}_{K},\mathbf{W}_{V}\)分别是得到\(\mathbf{Q}, \mathbf{K}, \mathbf{V}\)的投影矩阵。点积注意力是对V中的实体的“value”进行加权求和,其中权重是由实体“查询键”对的交互给出的。点积注意力下实体序列的隐表示为\(h_{\mathbf{e}}=\operatorname{Attn}(\mathbf{Q}, \mathbf{K}, \mathbf{V})\)。
3 TEMPORAL GRAPH ATTENTION NETWORK ARCHITECTURE 3.1 FUNCTIONAL TIME ENCODING在这一节,目标是为了将时间通过某种映射,将时间从时域映射到数域(用嵌入向量表示)\(\Phi: T \rightarrow \mathbb{R}^{d_{T}}\),以用来代替位置嵌入(等式1中的位置编码)做自注意力权重计算。一般来说,我们假设时间域可以用从原点开始的区间\(T\)表示:\(T = [0, t_{max}]\),其中\(t_{max}\)由观测数据确定。对于等式(2)中的内积自注意,通常“键”矩阵和“查询”矩阵(K, Q)由(1)中定义的Ze的恒等式或线性投影给出,这就使得在进行计算时,在时间(位置)编码只包含内积计算。考虑两个时间点\(t_1、t_2\)和它们的函数编码\(\left\langle\Phi\left(t_{1}\right), \Phi\left(t_{2}\right)\right\rangle\)之间的内积,通常,相对的时间跨度,而不是绝对的时间价值,揭示了关键的时间信息。因此,更感兴趣的是\(|t_2−t_1|\)的时间跨度相关的学习模式,理想情况下应该用\(\left\langle\Phi\left(t_{1}\right), \Phi\left(t_{2}\right)\right\rangle\)与自注意力结合。
所以定义时间核写作
\[\mathcal{K}: T \times T \rightarrow \mathbb{R} \text { with } \\ \begin{aligned} \mathcal{K}\left(t_{1}, t_{2}\right):=\left\langle\Phi\left(t_{1}\right), \Phi\left(t_{2}\right)\right\rangle \text {and} \ \mathcal{K}\left(t_{1}, t_{2}\right)=\psi\left(t_{1}-t_{2}\right), \forall t_{1}, t_{2} \in T ,\psi:\left[-t_{\max }, t_{\max }\right] \rightarrow \mathbb{R} \end{aligned} \]通过时间核\(\mathcal{K}\)的将时间的内积\(T \times T\)映射到实数域\(\mathbb{R}\)。时间核是平移不变的,对于常数\(c\):\(\mathcal{K}\left(t_{1}+c, t_{2}+c\right)=\psi\left(t_{1}-t_{2}\right)=\mathcal{K}\left(t_{1}, t_{2}\right)\),一般来说,函数学习是非常复杂的,因为它运行在无限维空间上,但现在把这个问题转化为学习\(Φ\)表示的时间核K。尽管如此,为了进行高效的基于梯度的优化,仍然需要为\(Φ\)找出一个显式的参数化。经典调和分析理论——Bochner理论解决了这个问题。
由于时间核K是正半定连续的,因为它是通过Gram矩阵(n维欧式空间中任意个向量的内积所组成的矩阵,具体形式见https://blog.csdn.net/lilong117194/article/details/78202637)定义的,映射\(Φ\)是连续的。因此,上面定义的核K满足Bochner定理的假设:
\[\mathcal{K}\left(t_{1}, t_{2}\right)=\psi\left(t_{1}, t_{2}\right)=\int_{\mathbb{R}} e^{i \omega\left(t_{1}-t_{2}\right)} p(\omega) d \omega=\mathbb{E}_{\omega}\left[\xi_{\omega}\left(t_{1}\right) \xi_{\omega}\left(t_{2}\right)^{*}\right](3) \]定理1 (Bochner定理):在\(\mathbb{R}^d\)上的连续平移不变核函数\(\cal{K}(x, y) = \psi (x−y)\)是正定的,当且仅当\(\mathbb{R}\)上存在一个非负测度,使得$\psi $是该测度的傅里叶变换。
其中\(\xi_{\omega}(t)=e^{i \omega t}\)。由于核K和概率测度\(p(ω)\)是实数,由欧拉公式\(e^{i \theta}=\cos (\theta)+i \sin (\theta)\),我们提取(3)的实部,得到:
\[\mathcal{K}\left(t_{1}, t_{2}\right)=\mathbb{E}_{\omega}\left[\cos \left(\omega\left(t_{1}-t_{2}\right)\right)\right]=\mathbb{E}_{\omega}\left[\cos \left(\omega t_{1}\right) \cos \left(\omega t_{2}\right)+\sin \left(\omega t_{1}\right) \sin \left(\omega t_{2}\right)\right](4) \]上述公式表明用蒙特卡洛积分逼近期望,即
\[\mathcal{K}\left(t_{1}, t_{2}\right) \approx \frac{1}{d} \sum_{i=1}^{d} \cos \left(\omega_{i} t_{1}\right) \cos \left(\omega_{i} t_{2}\right)+\sin \left(\omega_{i} t_{1}\right) \sin \left(\omega_{i} t_{2}\right)\\\omega_{1}, \ldots, \omega_{d} \stackrel{\text { i.i.d }}{\sim} p(\omega) \]因此,我们提出\(\mathbb{R}^d\)的有限维函数映射为
\[t \mapsto \Phi_{d}(t):=\sqrt{\frac{1}{d}}\left[\cos \left(\omega_{1} t\right), \sin \left(\omega_{1} t\right), \ldots, \cos \left(\omega_{d} t\right), \sin \left(\omega_{d} t\right)\right](5) \]易得\(\left\langle\Phi_{d}\left(t_{1}\right), \Phi_{d}\left(t_{2}\right)\right\rangle \approx \mathcal{K}\left(t_{1}, t_{2}\right)\)(两向量的点积),本文证明了\(\left\langle\Phi_{d}\left(t_{1}\right), \Phi_{d}\left(t_{2}\right)\right\rangle\)对\(\mathcal{K}\left(t_{1}, t_{2}\right)\)的随机一致收敛(在附录),并表明它只需要一定数量的样本就可以实现合适的估计,在下面的claim1中声明:
声明1: 设\(p(ω)\)为核函数K的Bochner定理中对应的概率测度。假设使用样本\(\{ω_i\}^d_{i=1}\)构建了特征图\(Φ\),那么我们只需要\(d=\Omega\left(\frac{1}{\epsilon^{2}} \log \frac{\sigma_{p}^{2} t_{\max }}{\epsilon}\right)\)个样本就可以得到
\[\sup _{t_{1}, t_{2} \in T}\left|\Phi_{d}\left(t_{1}\right)^{\prime} \Phi_{d}\left(t_{2}\right)-\mathcal{K}\left(t_{1}, t_{2}\right)\right|<\epsilon \text { with any probability for } \forall \epsilon>0 \]其中\(σ^2_p\)是关于\(p(ω)\)的二阶动量
通过Bochner定理,将核学习问题转化为分布学习问题,即定理1中\(p(ω)\)的估计。一个直接的解决方案是应用重参数化(reparameterization),使用随机变量与已知的边缘分布,如变分自编码器。然而,重参数化通常局限于某些分布,如“local-scale”。例如,当\(p(ω)\)是多模态时,很难通过直接重参数化重建底层分布。另一种方法是使用逆累积分布函数(CDF)变换。Rezende & Mohamed提出使用参数化的标准化流,即一系列可逆变换函数,来近似任意复杂的CDF,并从中采样。Dinh等人(2016)进一步考虑叠加双目标变换,称为仿射耦合层,以实现更有效的CDF估计。上述方法学习了基于流的网络参数化的逆CDF函数\(F^{−1}_ θ(.)\),并从相应的分布中抽取样本。另一方面,如果考虑一种非参数化的方法来估计分布,那么学习\(F^{−1}_ θ(.)\)并从中获得\(d\)个样本,相当于直接优化(4)中的$ {ω_1, . . . , ω_d}$作为自由模型参数。在实践中,发现这两种方法具有高度可比的性能(参见附录)。因此,将重点放在非参数方法上,因为它的参数效率更高,训练速度更快(因为训练过程中不需要采样)。
(上面这段从声明1开始简直是读天书 完全看不懂_(: 」∠)_,等脑子清醒一点再补课吧,几个名词:重参数化,逆累积分布函数(CDF)变换,标准化流,mark一下先)
上述功能时间编码与自我注意完全兼容,可以替代(1)中的位置编码,其参数作为整个模型的一部分共同优化。
3.2 TEMPORAL GRAPH ATTENTION LAYER用\(v_i\)和\(\mathbf{x}_i \in \mathbb{R}^{d_0}\)表示节点\(i\)及其原始节点特征。所提出的TGAT架构仅依赖于时间图注意层(TGAT层)。与GraphSAGE和GAT类似,TGAT层可以被认为是一个局部聚合运算符,将其隐藏表示(或特征)以及时间戳作为输入,输出是目标节点在任何时间点\(T\)的时间表示。在层表示\(l^{th}\)节点\(i\)在时间\(t\)的隐藏表示输出为\(\tilde{\mathbf{h}}_{i}^{(l)}(t)\)
与GAT类似,本文用了mask自我注意来处理结构信息。对于在时间\(t\)的节点\(v_0\),其邻居节点写作\(\mathcal{N}\left(v_{0} ; t\right)=\left\{v_{1}, \ldots, v_{N}\right\}\),所有的交互都在\(v_0\)和邻居\(v_i \in \mathcal{N}\left(v_{0} ; t\right)\)之间进行,并发生在\(t_i\)时刻(第一个时刻记为t1)。TGAT层的输入是邻居的嵌入\(\mathbf{Z} = \left\{\tilde{\mathbf{h}}_{1}^{(l-1)}\left(t_{1}\right), \ldots, \tilde{\mathbf{h}}_{N}^{(l-1)}\left(t_{N}\right)\right\}\)和目标节点带时间点的嵌入,\((\tilde{\mathbf{h}}_{0}^{(l-1)}\left(t\right),t)\)。当\(l = 1\)时,即对于第一层,输入只是原始的节点特征。经过该层后,在时刻t的目标节点v0的时间感知(time-aware)嵌入表示为\(\tilde{\mathbf{h}}_{0}^{(l)}\left(t\right)\),将其作为输出。由于时间核的平移不变假设,我们可以使用\(\{t-t_1,...,t-t_j\}\)代替交互时间,因为\(|t_i-t_j|=|(t-t_i)-(t-t_j)|\),并且在本文只关心时间跨度。
根据原始的自我注意机制,首先得到实体-时间特征矩阵为
\[\mathbf{Z}(t)=\left[\tilde{\mathbf{h}}_{0}^{(l-1)}(t)\left\|\Phi_{d_{T}}(0), \tilde{\mathbf{h}}_{1}^{(l-1)}\left(t_{1}\right)\right\| \Phi_{d_{T}}\left(t-t_{1}\right), \ldots, \tilde{\mathbf{h}}_{N}^{(l-1)}\left(t_{N}\right) \| \Phi_{d_{T}}\left(t-t_{N}\right)\right]^{\top}(6) \]时间特征可以拼接或者加和,并将其前项传播给三个不同的线性映射,以获得“query”、“key”和“value”:
\[\mathbf{q}(t)=[\mathbf{Z}(t)]_{0} \mathbf{W}_{Q}, \mathbf{K}(t)=[\mathbf{Z}(t)]_{1: N} \mathbf{W}_{K}, \mathbf{V}(t)=[\mathbf{Z}(t)]_{1: N} \mathbf{W}_{V} \]其中\(\mathbf{W}_{Q}, \mathbf{W}_{K}, \mathbf{W}_{V} \in \mathbb{R}^{\left(d+d_{T}\right) \times d_{h}}\)是权重矩阵,用于捕获时间编码和节点特征之间的相互作用。等式2中softmax函数输出的注意权值\(\{ α_i \}^N_{i=1}\)由\(\{ α_i \} = \exp \left(\mathbf{q}^{\top} \mathbf{K}_{i}\right) /\left(\sum_{q} \exp \left(\mathbf{q}^{\top} \mathbf{K}_{q}\right)\right)\)给出。所有节点的\(v_{i} \in \mathcal{N}\left(v_{0} ; t\right)\)隐藏表示形式由\(\alpha_i\mathbf{V}_i\)给定,然后我们将上述点积自注意力输出的行求和作为隐藏邻居表示,
\[\mathbf{h}(t)=\operatorname{Attn}(\mathbf{q}(t), \mathbf{K}(t), \mathbf{V}(t)) \in \mathbb{R}^{d_{h}} \]为了将邻域表示与目标节点特征相结合,将采用与GraphSAGE相同的做法,将邻居表示与目标节点的特征向量\(\mathbf{z}_0\)拼接起来。然后,我们将其传递给前馈神经网络,以捕获特征之间的非线性交互
\[\begin{array}{l} \tilde{\mathbf{h}}_{0}^{(l)}(t)=\operatorname{FFN}\left(\mathbf{h}(t) \| \mathbf{x}_{0}\right) \equiv \operatorname{ReLU}\left(\left[\mathbf{h}(t) \| \mathbf{x}_{0}\right] \mathbf{W}_{0}^{(l)}+\mathbf{b}_{0}^{(l)}\right) \mathbf{W}_{1}^{(l)}+\mathbf{b}_{1}^{(l)} \\ \mathbf{W}_{0}^{(l)} \in \mathbb{R}^{\left(d_{h}+d_{0}\right) \times d_{f}}, \mathbf{W}_{1}^{(l)} \in \mathbb{R}^{d_{f} \times d}, \mathbf{b}_{0}^{(l)} \in \mathbb{R}^{d_{f}}, \mathbf{b}_{1}^{(l)} \in \mathbb{R}^{d} \end{array} \]其中\(\tilde{\mathbf{h}}_{0}^{(l)}(t) \in \mathbb{R}^{d}\),是表示目标节点在时刻\(t\)时的时间感知节点嵌入的最终输出。因此,TGAT层可以使用Semi-supervised classification with graph convolutional networks中提出的半监督学习框架实现节点分类任务,以及使用Representation learning on graphs: Methods and applications总结的编码器-解码器框架实现链路预测任务。
transformer里说明使用多头注意力可以提高GAT训练的表现,并使训练稳定。本文提出的TGAT层可以很容易地扩展到多头设置。则k个不同头数的点积自我注意输出为\(\mathbf{h}^{(i)} \equiv \operatorname{Attn}^{(i)}(\mathbf{q}(t), \mathbf{K}(t), \mathbf{V}(t)), i=1, \ldots, k\)。我们首先将k个邻居表示拼接成一个组合向量,然后执行相同的步骤:
\[\tilde{\mathbf{h}}_{0}^{(l)}(t)=\operatorname{FFN}\left(\mathbf{h}^{(1)}(t)\|\ldots\| \mathbf{h}^{(k)}(t) \| \mathbf{x}_{0}\right) \]就像GraphSAGE一样,单个TGAT层聚合局部的单跳邻域,通过叠加L个TGAT层,聚合扩展到L跳。与GAT相似,输出方法不限制邻居的大小。
3.3 EXTENSION TO INCORPORATE EDGE FEATURESTGAT层可以自然地扩展,以消息传递方式处理边特征。Dynamic edge-conditioned filters in convolutional neural networks on graphs和Dynamic graph cnn for learning on point clouds.修改经典的谱图卷积网络,以纳入边特征。Relational inductive biases, deep learning, and graph networks提出一般的图神经网络框架,其中边特征能够处理。对于时间图,本文看做每个动态边与一个特征向量相关联,即\(v_i\)和\(v_j\)在时间\(t\)的相互作用产生了特征向量\(\mathbf{x}_{i,j}(t)\)。为了在TGAT聚合过程中传播边缘特征,我们只需将(6)中的\(\mathbf{Z}(t)\)扩展为:
\[\mathbf{Z}(t)=\left[\ldots, \tilde{\mathbf{h}}_{i}^{(l-1)}\left(t_{i}\right)\left\|\mathbf{x}_{0, i}\left(t_{i}\right)\right\| \Phi_{d_{T}}\left(t-t_{i}\right), \ldots\right](7) \]同样 可以拼接或者相加,使边信息传播到目标节点的隐藏表示,然后传递到下一层(如果存在)。其余结构与第3.2节相同。
3.4 TEMPORAL SUB-GRAPH BATCHING堆叠L层TGAT相当于在L-hop邻居上聚合信息。对于分批训练中构造的每个L-hop子图,所有消息传递方向必须与观察到的时间顺序对应。在时间图中,两个节点可以在不同的时间点有多个交互。是否允许包含目标节点的环应该具体分析。从邻居采样,或称为邻居dropout,可以加快和稳定模型训练。对于时间图,dropout可以通过逆时间跨度(inverse timespan)来平均或加权计算,这样,更近期的交互有更高的概率被抽样。
3.5 COMPARISONS TO RELATED WORK1 直接学习时间的函数表示,而不是将时间图裁剪成快照序列或构造时间约束随机游动。
2 与基于rnn的模型相比,TGAT层的计算效率更高,因为mask自注意力操作是可并行的。
3 TGAT的推断完全是归纳的。
4 具有平均池化的GraphSAGE (Hamilton et al., 2017a)可以被解释为所提出方法的一种特殊情况,其中时间邻域以相等的注意系数聚集。GAT就像TGAT的时间不可知论版本,但对自注意力有不同的表述。
Experiment 4 EXPERIMENT AND RESULTS 4.1 DATASETSReddit dataset
Wikipedia dataset
Industrial dataset.
4.2 TRANSDUCTIVE AND INDUCTIVE LEARNING TASKSTransductive task通过在训练中观察到的节点嵌入,来做链接预测任务和节点分类 见表1。
Inductive task在训练中未观察到某些节点嵌入,然后普来做链接预测任务和节点分类 见表2。
在评价指标方面,在链路预测任务中,首先对正邻接抽取等量的负节点对,然后计算平均精度(AP)和分类精度。在下游节点分类任务中,由于数据集中的标签不平衡,采用ROC曲线下面积( AUC)。
4.3 BASELINESTransductive task:GAE,VAGE,DeepWalk,Node2vec,CTDNE,GAT,GAT+T,GraphSAGE,GraphSAGE+T
Inductive task :GAT,GAT+T,GraphSAGE,GraphSAGE+T
4.4 EXPERIMENT SETUP使用链路预测损失函数训练L层TGAT网络:
\[\ell=\sum_{\left(v_{i}, v_{j}, t_{i j}\right) \in \mathcal{E}}-\log \left(\sigma\left(-\tilde{\mathbf{h}}_{i}^{l}\left(t_{i j}\right)^{\top} \tilde{\mathbf{h}}_{j}^{l}\left(t_{i j}\right)\right)\right)-Q \cdot \mathbb{E}_{v_{q} \sim P_{n}(v)} \log \left(\sigma\left(\tilde{\mathbf{h}}_{i}^{l}\left(t_{i j}\right)^{\top} \tilde{\mathbf{h}}_{q}^{l}\left(t_{i j}\right)\right)\right)(8) \]其中求和是在\(t_{ij}\)时刻\(v_i\)和\(v_j\)上相互作用的观察边上的
\(σ(.)\)是sigmoid函数
\(Q\)是负采样的数量
\(P_{n}(v)\)是节点空间上的负采样分布。在超参数调优方面,为了简单,将节点嵌入维数和时间编码维数固定为原始特征维数,然后根据验证数据集的链路预测AP得分,从\({1,2,3}\)中选择TGAT层数,从\({1,2,3,4,5}\)中选择注意头数。TGAT在聚合时没有限制邻域大小,但是为了加快训练速度,特别是在使用多跳聚合时,我们使用均匀抽样的邻居dropout(在{0.1, 0.3, 0.5}中选择)。在训练过程中,使用0.0001作为Reddit和Wikipedia数据集的学习率,0.001作为工业数据集的学习率,并使用Glorot初始化和Adam SGD优化器。
4.5 RESULTS具体sota见表1,2,3和图3
4.6 ATTENTION ANALYSIS首先,在本节中分析了注意力权重和时间的关系,图4(a)展示了随时间间隔变化越大,权重越低,也就是说注意力机制更在乎近期发生的交互。
其次,图4(b)分析了随着时间的推移,拓扑结构如何影响注意力权重。具体来说,通过找出模型对重复出现次数不同的相邻节点的关注权值,发现注意力重点关注重复出现节点的拓扑结构。
得到结果最近的和重复的行为通常会对用户未来的兴趣产生更大的影响。
Summary后面的注意力部分还好,前面的时间编码部分真的是读天书,读一句就要搜一下里面名词啥意思,然后看百科看博客半个小时又没了(主要一大半还看不懂QAQ),自己的基础还是太薄弱了,怎么才能成为数学大佬啊淦,说回论文,前面讲时间编码的思路个人觉得很不错,尽量脱离了DTDG的快照带来的离散缺点,不需要时间平滑做后续处理,学到了。