 在实际环境中,用户似乎总是愿意用较小的延时增加的代价,去换取 TPS 的显著提升。毕竟,从 2ms 到 10ms 的延时增加通常是可以忍受的。本文介绍了提高producer吞吐量 与 提高消息可靠性 的实践,重点介绍了在Confluent.Kafka组件下如何进行配置的代码实践,相信会对你有所帮助。
1 提高Producer吞吐量的实践
在实际环境中,用户似乎总是愿意用较小的延时增加的代价,去换取 TPS 的显著提升。毕竟,从 2ms 到 10ms 的延时增加通常是可以忍受的。本文介绍了提高producer吞吐量 与 提高消息可靠性 的实践,重点介绍了在Confluent.Kafka组件下如何进行配置的代码实践,相信会对你有所帮助。
1 提高Producer吞吐量的实践
在实际环境中,用户似乎总是愿意用较小的延时增加的代价,去换取 TPS 的显著提升。毕竟,从 2ms 到 10ms 的延时增加通常是可以忍受的。
事实上,Kafka Producer 就是采取了这样的设计思想。每当 producer 发布一个立即就发送 到 producer聚集一堆发布后批量发送,如下图所示:
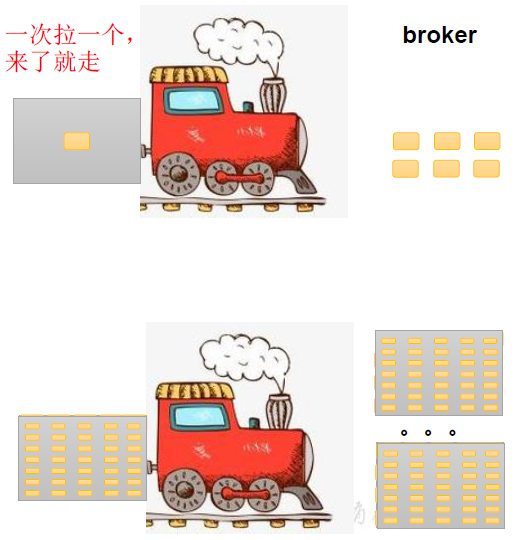
我们可以在客户端做一些配置,来实现producer的高吞吐量,涉及到的一些重要配置如下:
-
批次大小,它和等待时间只要有一个满足就会发送,默认16K,可以修改为32K~512K。
-
等待时间,它和批次大小只要有一个满足就会发送,建议设置为5~100ms(根据你的场景来修改)。
-
压缩算法,使用压缩算法网络传递效率高,但也会相应耗费CPU,建议设置为LZ4或zstd。
-
缓冲区大小,默认1G,基本无需修改,最大可改为2GB。
下面的示例展示了基于Confluent.Kafka客户端组件如何对上面的配置项进行设置(均需要在Publish操作之前设置好),请注意查看带有注释的区域:
public async Task PublishAsync<T>(string topicName, T message) where T : class { var config = new ProducerConfig { BootstrapServers = KAFKA_SERVERS, QueueBufferingMaxKbytes = 2097151, // 修改缓冲区最大为2GB,默认为1GB CompressionType = CompressionType.Lz4, // 配置使用压缩算法LZ4,其他:gzip/snappy/zstd BatchSize = 32768, // 修改批次大小为32K LingerMs = 20 // 修改等待时间为20ms }; using (var producer = new ProducerBuilder<string, string>(config).Build()) { producer.Produce(topicName, new Message<string, string> { Key = Guid.NewGuid().ToString(), Value = JsonConvert.SerializeObject(message) }); ; } }2 高可靠性消息的实践
在MQ中,一般存在两种情况的消息丢失:
-
producer端消息丢失
-
consuer端消息丢失
对于producer端消息丢失,一般会采用带回调函数的produce方法,且设置acks=all和设计一个较大的retry次数来避免消息丢失。
对于consumer端消息丢失,一般会采用关闭自动提交位移来避免消息丢失。
此外,要避免消息丢失,broker端也需要进行一些优化配置。
下面,我们就一起来看看。
Producer端基于Confluent.Kafka的示例配置设置示例:重点关注注释部分
public async Task PublishAsync<T>(string topicName, T message) where T : class { var config = new ProducerConfig { BootstrapServers = KAFKA_SERVERS, Acks = Acks.All, // 表明只有所有副本Broker都收到消息才算提交成功 MessageSendMaxRetries = 50, // 消息发送失败最大重试50次 ...... }; using (var producer = new ProducerBuilder<string, string>(config).Build()) { var numProduced = 0; var key = Guid.NewGuid().ToString(); var value = JsonConvert.SerializeObject(message); // 使用带回调函数的Produce方法 producer.Produce(topicName, new Message<string, string> { Key = key, Value = value }, (deliveryReport) => { if (deliveryReport.Error.Code != ErrorCode.NoError) { // 发送失败 Console.WriteLine($"[Error] Failed to deliver message: {deliveryReport.Error.Reason}"); } else { // 发送成功 Console.WriteLine($"[Info] Produced event to topic {topicName}: key = {key} value = {value}"); numProduced += 1; } }); // 等待所有回调函数执行完成,参数是超时时间,也就是最大的等待时间 var queueSize = producer.Flush(TimeSpan.FromSeconds(5)); if (queueSize > 0) Console.WriteLine($"[Warn] Producer event queue has {queueSize} pending events on exit."); Console.WriteLine($"[Info] {numProduced} messages were produced to topic {topicName}"); } await Task.CompletedTask; }Consumer端
基于Confluent.Kafka的示例配置设置示例:重点关注注释部分
public async Task SubscribeAsync<T>(IEnumerable<string> topics, Action<T> messageFunc, CancellationToken cancellationToken = default) where T : class { var config = new ConsumerConfig { BootstrapServers = KAFKA_SERVERS, ..... EnableAutoCommit = false, // 禁止AutoCommit Acks = Acks.All, // 需要所有副本响应才算消费完成 ...... }; using (var consumer = new ConsumerBuilder<Ignore, string>(config).Build()) { consumer.Subscribe(topics); try { while (true) { try { var cr = consumer.Consume(cancellationToken); var message = JsonConvert.DeserializeObject<T>(cr.Message.Value); if (message != null) messageFunc(message); consumer.Commit(cr); // 手动提交位移,会产生阻塞,影响吞吐量 Console.WriteLine($"[Info] Consumed record successfully! Received message: {message}"); } catch (ConsumeException e) { Console.WriteLine($"[Error] Error occured in consuming: {e.Error.Reason}"); } } } catch (OperationCanceledException) { // Ctrl+C Pressed Console.WriteLine("[Info] Ctr+C pressed, now closing consumer."); consumer.Close(); } } await Task.CompletedTask; }Broker端
对于Broker端,可以修改以下三个配置以适应高可靠性的要求:
-
unclean.leader.election.enable = false
-
replication.factor >= 3
-
min.insync.replicas > 1
-
确保 replication.factor > min.insync.replicas
(1)设置 unclean.leader.election.enable = false
这是 Broker 端的参数,它控制的是哪些 Broker 有资格竞选分区的 Leader。如果一个 Broker 落后原先的 Leader 太多,那么它一旦成为新的 Leader,必然会造成消息的丢失。故一般都要将该参数设置成 false,即不允许这种情况的发生。
从Kafka 0.11版本开始,这个选项的默认值就变成了false。
(2)设置 replication.factor >= 3
这也是 Broker 端的参数(Topic参数)。其实这里想表述的是,最好将消息多保存几份,毕竟目前防止消息丢失的主要机制就是冗余。
(3)设置 min.insync.replicas > 1
这依然是 Broker 端参数(Topic参数),控制的是消息至少要被写入到多少个副本才算是“已提交”。设置成大于 1 可以提升消息持久性。在实际环境中千万不要使用默认值 1。
(4)确保 replication.factor > min.insync.replicas
如果两者相等,那么只要有一个副本挂机,整个分区就无法正常工作了。我们不仅要改善消息的持久性,防止数据丢失,还要在不降低可用性的基础上完成。推荐设置成 replication.factor = min.insync.replicas + 1。
示例:设置replication.factor=3, min.insync.replicas=2
kafka-topics.sh --create --zookeeper zk-server-master:2181/kafka --replication-factor 3 --partitions 3 --topic testtopic--config min.insync.replicas=2
上述配置其实就是实现一个类似MongoDB副本集的WriteConcern=Major的效果。
本文介绍了提高producer吞吐量 与 提高消息可靠性 的实践,重点介绍了在Confluent.Kafka组件下如何进行配置的代码实践,相信会对你有所帮助。
参考资料极客时间,胡夕《Kafka核心技术与实战》
B站,尚硅谷《Kafka 3.x入门到精通教程》
