目录 爬虫实战(七):爬王者英雄图片 一、 网站分析 1、 页面分析 2、 源码分析 3、 链接分析 4、 爬取过程 二、 编写代码 1、 获取JSON数据 2、 获取皮肤数量 3、 下载皮肤图片 三、
- 爬虫实战(七):爬王者英雄图片
- 一、 网站分析
- 1、 页面分析
- 2、 源码分析
- 3、 链接分析
- 4、 爬取过程
- 二、 编写代码
- 1、 获取JSON数据
- 2、 获取皮肤数量
- 3、 下载皮肤图片
- 三、 总代码
- 一、 网站分析
我们对王者荣耀英雄界面分析,发现,其数据并不是存储在源码中的,那么其不是静态网址,我们不能通过直接获取源码来获取数据
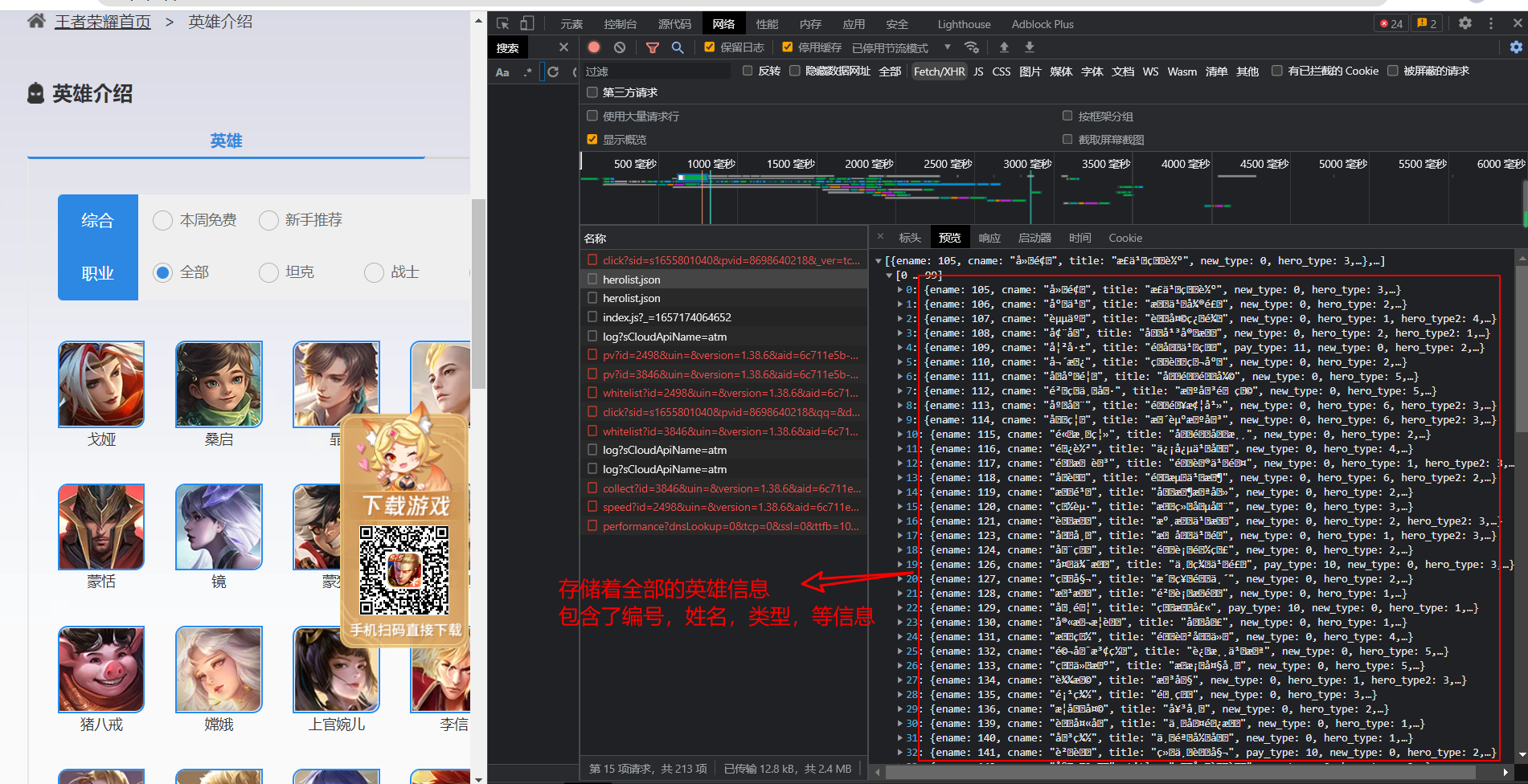
通过F12抓包可以得到一个和页面链接同名的json文件,里面存储了许多的乱码信息,通过编码utf-8,可以看出,这个JSON存储的正是所有英雄的信息
 2、 源码分析
2、 源码分析
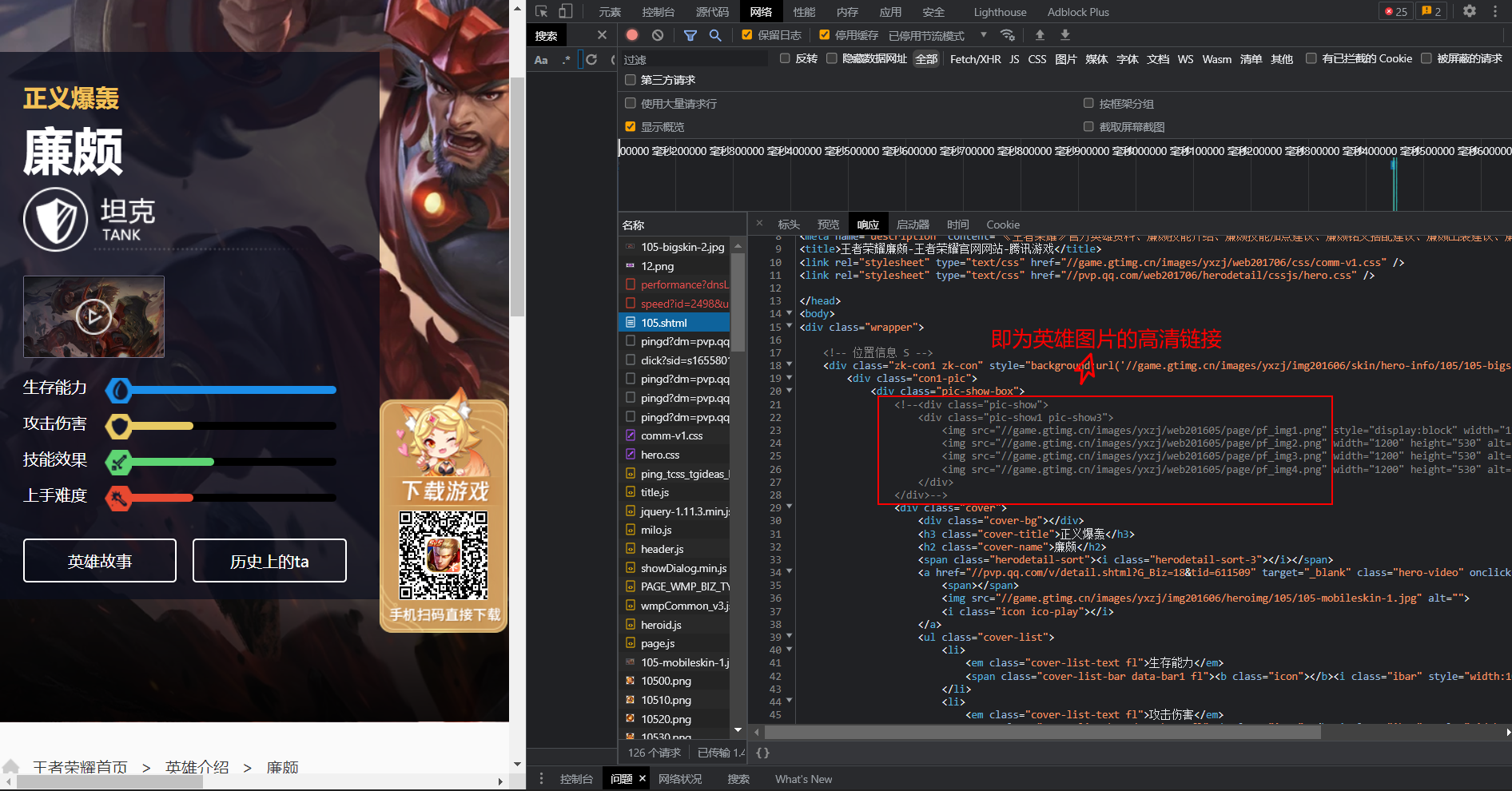
那么,我们的主页面分析完了,然后,我们分析单独英雄的界面,我们发现每个英雄的界面中的背景图片就是英雄的高清大图,并且可以通过右下角的图标来切换图片,那么,图片链接就一定存储在页面的源码中,果然,通过翻译我们找到了背景图片的链接,我们可以推测,如果把图片的链接最后一个数字改为2,就可以换到第二个皮肤,那么,我们如何获取皮肤数量呢?
 3、 链接分析
3、 链接分析
那么,问题来了,我们如何进入每个英雄的详情界面呢?
这里,我们先展示一下我们先前获取的部分的英雄数据
[{'ename': 105, 'cname': '廉颇', 'title': '正义爆轰', 'new_type': 0, 'hero_type': 3, 'skin_name': '正义爆轰|地狱岩魂'},
{'ename': 106, 'cname': '小乔', 'title': '恋之微风', 'new_type': 0, 'hero_type': 2, 'skin_name': '恋之微风|万圣前夜|天鹅之梦|纯白花嫁|缤纷独角兽'},
{'ename': 107, 'cname': '赵云', 'title': '苍天翔龙', 'new_type': 0, 'hero_type': 1, 'hero_type2': 4, 'skin_name': '苍天翔龙|忍●炎影|未来纪元|皇家上将|嘻哈天王|白执事|引擎之心'}]
然后,我们再来看一下详情页的链接
https://pvp.qq.com/web201605/herodetail/105.shtml 廉颇
https://pvp.qq.com/web201605/herodetail/106.shtml 小乔
https://pvp.qq.com/web201605/herodetail/107.shtml 赵云
故,我们发现,数据里面的ename可以帮助我们获取英雄详情页的链接,同时,shin_name为英雄皮肤,但是从廉颇这里可以看出英雄皮肤并不是很全,
那么,我们如何给图片进行命名呢?
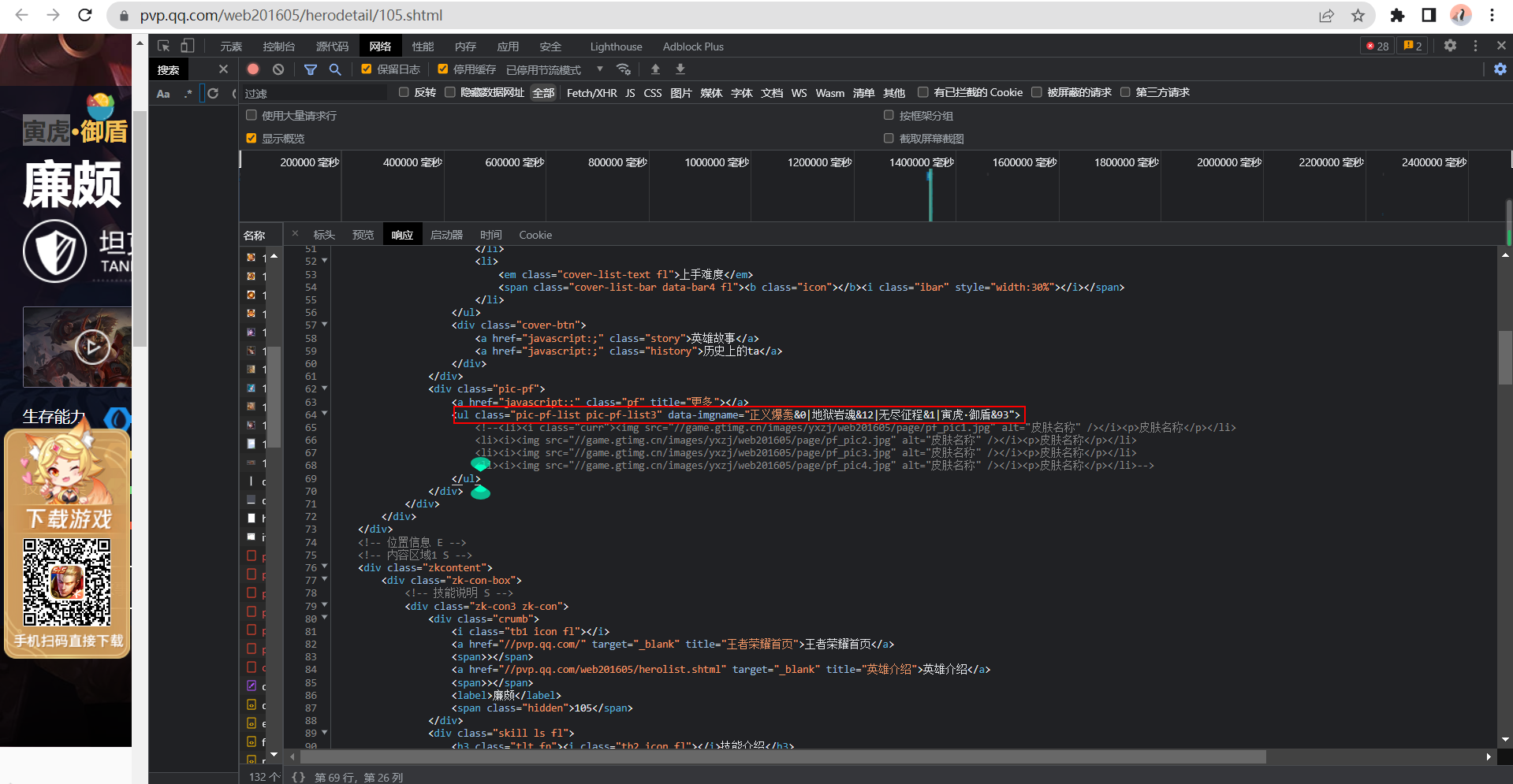
从源码中,我们发现,有一个地方存储了英雄的皮肤数据,并且,其和英雄图片的索引也是对应的,我们也可以根据这个来查看有多少个皮肤
那么,能不能再简单一点呢?
我们来直接分析一下英雄原皮的图片链接:
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/105/105-bigskin-1.jpg # 廉颇
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/106/106-bigskin-1.jpg # 小乔
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/107/107-bigskin-1.jpg # 赵云
我们发现,就只有英雄编号的改变,其余内容都是不变的
那么,我们的爬取方式是:
- 获取全部的英雄数据
- 获取英雄有多少个皮肤
- 对图片发送请求
import requests # 导入模块,发送请求,处理JSON数据
from fake_useragent import UserAgent # 随机请求头
headers = {
"user-agent": UserAgent().random, # 请求头
"referer": "https://pvp.qq.com/web201605/herolist.shtml", # 表明来源
}
infolist = []
def get_infolist():
resp = requests.get("https://pvp.qq.com/web201605/js/herolist.json", headers=headers) # 发送请求
resp.encoding = resp.apparent_encoding # 设置编码,防止出现乱码
data = resp.json() # 获取数据,并转换为列表格式
for i in data:
"""我们只取英雄编号和英雄名称"""
infolist.append({
"id": i["ename"],
"name": i["cname"]
})
print("英雄数据获取完成!")
get_infolist()
print(infolist)
import re # 使用正则解析,获取数据
skin_num_url = "https://pvp.qq.com/web201605/herodetail/%d.shtml"
def get_skin_num(id):
resp = requests.get(skin_num_url % id, headers=headers) # 发送请求
resp.encoding = resp.apparent_encoding # 设置编码,防止出现乱码
skin = re.search('<ul class="pic-pf-list.*?" data-imgname="(?P<skin>.*?)">', resp.text).group("skin")
# 清洗数据
lis = skin.split("|")
# print(lis)
for k, i in enumerate(lis):
try:
temp = re.search("(?P<name>.*?)&", i).group("name")
except AttributeError:
temp = i # 可能不需要对数据进行清洗
lis[k] = temp
# print(lis)
return lis
# get_skin_num(105)
for i in infolist:
"""遍历数据,向字典中加入皮肤名字和皮肤数量"""
ret = get_skin_num(i["id"]) # 把id传入
i.update({
"skin": ret,
})
print(infolist)
import os, time
skin_url = "https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{id}/{id}-bigskin-{index}.jpg"
def save_skin(dic):
"""把数据字典传入,进行其余的操作"""
if not os.path.exists(f"./王者荣耀皮肤/{dic['name']}"):
os.mkdir(f"./王者荣耀皮肤/{dic['name']}")
for i in range(len(dic["skin"])):
url_ = skin_url.format(id=dic["id"], index=i + 1)
resp = requests.get(url_, headers=headers)
file = open(f"./王者荣耀皮肤/{dic['name']}/{dic['skin'][i]}.jpg", "wb")
file.write(resp.content)
file.close()
print(dic["skin"][i], "下载完成")
time.sleep(30)
for i in infolist:
save_skin(i)
print(f"{i['name']}英雄皮肤下载完成")
print("所有皮肤下载完成!")
import requests # 导入模块,发送请求
import re # 使用正则解析,获取数据
import os, time, json # 将数据写入文件中
from fake_useragent import UserAgent # 随机请求头
headers = {
"user-agent": UserAgent().random, # 请求头
"referer": "https://pvp.qq.com/web201605/herolist.shtml", # 表明来源
}
skin_num_url = "https://pvp.qq.com/web201605/herodetail/%d.shtml"
skin_url = "https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{id}/{id}-bigskin-{index}.jpg"
infolist = []
def get_infolist():
global infolist
try:
with open("infolist.json", "r", encoding="utf-8") as file:
infolist = json.load(file)
if not infolist: # 如果文件里面没有值直接报错
raise IOError
except Exception as e:
resp = requests.get("https://pvp.qq.com/web201605/js/herolist.json", headers=headers) # 发送请求
resp.encoding = resp.apparent_encoding # 设置编码,防止出现乱码
data = resp.json() # 获取数据,并转换为列表格式
for i in data:
"""我们只取英雄编号和英雄名称"""
infolist.append({
"id": i["ename"],
"name": i["cname"]
})
print("英雄数据获取完成!")
def get_skin_num(id):
"""获取皮肤名字和数量"""
resp = requests.get(skin_num_url % id, headers=headers) # 发送请求
resp.encoding = resp.apparent_encoding # 设置编码,防止出现乱码
skin = re.search('<ul class="pic-pf-list.*?" data-imgname="(?P<skin>.*?)">', resp.text).group("skin")
# 清洗数据
lis = skin.split("|")
# print(lis)
for k, i in enumerate(lis):
try:
temp = re.search("(?P<name>.*?)&", i).group("name")
except AttributeError:
temp = i # 可能不需要对数据进行清洗
lis[k] = temp
# print(lis)
return lis
def save_skin(dic):
"""把数据字典传入,进行其余的操作"""
if not os.path.exists(f"./王者荣耀皮肤/{dic['name']}"):
os.mkdir(f"./王者荣耀皮肤/{dic['name']}")
for i in range(len(dic["skin"])):
url_ = skin_url.format(id=dic["id"], index=i + 1)
resp = requests.get(url_, headers=headers)
file = open(f"./王者荣耀皮肤/{dic['name']}/{dic['skin'][i]}.jpg", "wb")
file.write(resp.content)
file.close()
print(dic["skin"][i], "下载完成")
time.sleep(30)
def main():
get_infolist()
if not os.path.exists(f"./王者荣耀皮肤"):
"""如果文件夹不存在,则创建"""
os.mkdir(f"./王者荣耀皮肤")
for i in infolist:
"""遍历数据,向字典中加入皮肤名字和皮肤数量"""
ret = get_skin_num(i["id"]) # 把id传入
i.update({
"skin": ret,
"is_down": False # 记录是否已经下载
})
# 将数据写入文件中,下次可以继续使用
file = open("infolist.json", "w", encoding="utf-8")
json.dump(infolist, file, indent=8, ensure_ascii=False)
file.close()
for i in infolist:
if not i["is_down"]: # 如果皮肤没有下载,则下载
save_skin(i)
print(f"{i['name']}英雄皮肤下载完成")
i["is_down"] = True
else:
print(f"{i['name']}英雄皮肤已经下载")
print("所有皮肤下载完成!")
if __name__ == "__main__":
main()
最后,尽情欣赏图片吧!