原文链接:批流一体数据集成工具ChunJun同步Hive事务表原理详解及实战分享
课件获取:关注公众号__ “数栈研习社”,后台私信 “ChengYing”__ 获得直播课件
视频回放:点击这里
ChengYing 开源项目地址:github 丨 gitee 喜欢我们的项目给我们点个__ STAR!STAR!!STAR!!!(重要的事情说三遍)__
技术交流钉钉 qun:30537511
本期我们带大家回顾一下无倦同学的直播分享《Chunjun同步Hive事务表详解》
一、Hive事务表的结构及原理Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。
在分享Hive事务表的具体内容前,我们先来了解下HIve 事务表在 HDFS 存储上的一些限制。
Hive虽然支持了具有ACID语义的事务,但是没有像在MySQL中使用那样方便,有很多局限性,具体限制如下:
-
尚不支持BEGIN,COMMIT和ROLLBACK,所有语言操作都是自动提交的
-
仅支持ORC文件格式(STORED AS ORC)
-
默认情况下事务配置为关闭,需要配置参数开启使用
-
表必须是分桶表(Bucketed)才可以使用事务功能
-
表必须内部表,外部表无法创建事务表
-
表参数transactional必须为true
-
外部表不能成为ACID表,不允许从非ACID会话读取/写入ACID表
以下矩阵包括可以使用Hive创建的表的类型、是否支持ACID属性、所需的存储格式以及关键的SQL操作。

了解完Hive事务表的限制,现在我们具体了解下Hive事务表的内容。
1、事务表文件名字详解- 基础目录:
$partition/base_$wid/$bucket
- 增量目录:
$partition/delta_$wid_$wid_$stid/$bucket
- 参数目录:
$partition/delete_delta_$wid_$wid_$stid/$bucket

$ orc-tools data bucket_00000
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":0,"currentTransaction":1,"row":{"id":1,"name":"Jerry","age":18}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":1,"currentTransaction":1,"row":{"id":2,"name":"Tom","age":19}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":2,"currentTransaction":1,"row":{"id":3,"name":"Kate","age":20}}
-
operation 0 表示插入、1 表示更新,2 表示删除。由于使用了 split-update,UPDATE 是不会出现的。
-
originalTransaction是该条记录的原始写事务 ID:
a、对于 INSERT 操作,该值和 currentTransaction 是一致的;
b、对于 DELETE,则是该条记录第一次插入时的写事务 ID。
- bucket 是一个 32 位整型,由 BucketCodec 编码,各个二进制位的含义为:
a、1-3 位:编码版本,当前是 001;
b、4 位:保留;
c、5-16 位:分桶 ID,由 0 开始。分桶 ID 是由 CLUSTERED BY 子句所指定的字段、以及分桶的数量决定的。该值和 bucket_N 中的 N 一致;
d、17-20 位:保留;
e、21-32 位:语句 ID;
举例来说,整型 536936448 的二进制格式为 00100000000000010000000000000000,即它是按版本 1 的格式编码的,分桶 ID 为 1。
-
rowId 是一个自增的唯一 ID,在写事务和分桶的组合中唯一;
-
currentTransaction 当前的写事务 ID;
-
row 具体数据。对于 DELETE 语句,则为 null。
UPDATE employee SET age = 21 WHERE id = 2;
这条语句会先查询出所有符合条件的记录,获取它们的 row_id 信息,然后分别创建 delete 和 delta 目录:
/user/hive/warehouse/employee/delta_0000001_0000001_0000/bucket_00000
/user/hive/warehouse/employee/delete_delta_0000002_0000002_0000/bucket_00000 (update)
/user/hive/warehouse/employee/delta_0000002_0000002_0000/bucket_00000 (update)
delete_delta_0000002_0000002_0000/bucket_00000
包含了删除的记录:
{"operation":2,"originalTransaction":1,"bucket":536870912,"rowId":1,"currentTransaction":2,"row":null}
delta_0000002_0000002_0000/bucket_00000
包含更新后的数据:
{"operation":0,"originalTransaction":2,"bucket":536870912,"rowId":0,"currentTransaction":2,"row":{"id":2,"name":"Tom","salary":21}}
4、Row_ID 信息怎么查?
随着写操作的积累,表中的 delta 和 delete 文件会越来越多,事务表的读取过程中需要合并所有文件,数量一多势必会影响效率,此外小文件对 HDFS 这样的文件系统也不够友好,因此Hive 引入了压缩(Compaction)的概念,分为 Minor 和 Major 两类。
● Minor
Minor Compaction 会将所有的 delta 文件压缩为一个文件,delete 也压缩为一个。压缩后的结果文件名中会包含写事务 ID 范围,同时省略掉语句 ID。
压缩过程是在 Hive Metastore 中运行的,会根据一定阈值自动触发。我们也可以使用如下语句人工触发:
ALTER TABLE dtstack COMPACT 'MINOR'。
● Major
Major Compaction 会将所有的 delta 文件,delete 文件压缩到一个 base 文件。压缩后的结果文件名中会包含所有写事务 ID 的最大事务 ID。
压缩过程是在 Hive Metastore 中运行的,会根据一定阈值自动触发。我们也可以使用如下语句人工触发:
ALTER TABLE dtstack COMPACT 'MAJOR'。
6、文件内容详解ALTER TABLE employee COMPACT 'minor';
语句执行前:
/user/hive/warehouse/employee/delta_0000001_0000001_0000
/user/hive/warehouse/employee/delta_0000002_0000002_0000 (insert 创建, mary的数据)
/user/hive/warehouse/employee/delete_delta_0000002_0000002_0001 (update)
/user/hive/warehouse/employee/delta_0000002_0000002_0001 (update)
语句执行后:
/user/hive/warehouse/employee/delete_delta_0000001_0000002
/user/hive/warehouse/employee/delta_0000001_0000002
7、读 Hive 事务表我们可以看到 ACID 事务表中会包含三类文件,分别是 base、delta、以及 delete。文件中的每一行数据都会以 row_id 作为标识并排序。从 ACID 事务表中读取数据就是对这些文件进行合并,从而得到最新事务的结果。这一过程是在 OrcInputFormat 和 OrcRawRecordMerger 类中实现的,本质上是一个合并排序的算法。
以下列文件为例,产生这些文件的操作为:
-
插入三条记录
-
进行一次 Major Compaction
-
然后更新两条记录。
1-0-0-1 是对 originalTransaction - bucketId - rowId - currentTra

对所有数据行按照 (originalTransaction, bucketId, rowId) 正序排列,(currentTransaction) 倒序排列,即:
originalTransaction-bucketId-rowId-currentTransaction
(base_1)1-0-0-1
(delete_2)1-0-1-2# 被跳过(DELETE)
(base_1)1-0-1-1 # 被跳过(当前记录的 row_id(1) 和上条数据一样)
(delete_2)1-0-2-2 # 被跳过(DELETE)
(base_1)1-0-2-1 # 被跳过(当前记录的 row_id(2) 和上条数据一样)
(delta_2)2-0-0-2
(delta_2)2-0-1-2
获取第一条记录;
-
如果当前记录的 row_id 和上条数据一样,则跳过;
-
如果当前记录的操作类型为 DELETE,也跳过;
通过以上两条规则,对于 1-0-1-2 和 1-0-1-1,这条记录会被跳过;
如果没有跳过,记录将被输出给下游;
重复以上过程。
合并过程是流式的,即 Hive 会将所有文件打开,预读第一条记录,并将 row_id 信息存入到 ReaderKey 类型中。

了解完Hive事务表的基本原理后,我们来为大家分享如何在ChunJun中读写Hive事务表。
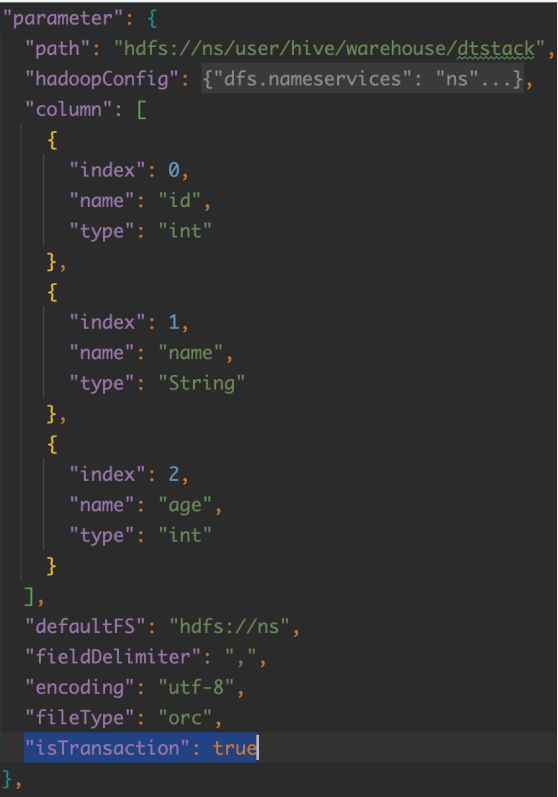
1、事务表数据准备-- 创建事务表
create table dtstack(
id int,
name string,
age int
)
stored as orc
TBLPROPERTIES('transactional'='true');
-- 插入 10 条测试数据
insert into dtstack (id, name, age)
values (1, "aa", 11), (2, "bb", 12), (3, "cc", 13), (4, "dd", 14), (5, "ee", 15),
(6, "ff", 16), (7, "gg", 17), (8, "hh", 18), (9, "ii", 19), (10, "jj", 20);


/root/wujuan/flink-1.12.7/bin/yarn-session.sh -t $ChunJun_HOME -d
提交 Yarn Session 任务 读取事务表/root/wujuan/ChunJun/bin/ChunJun-yarn-session.sh -job /root/wujuan/ChunJun/ChunJun-examples/json/hive3/hive3_transaction_stream.json -confProp {"yarn.application.id":"application_1650792512832_0134"}
写入事务表/root/wujuan/ChunJun/bin/ChunJun-yarn-session.sh -job /root/wujuan/ChunJun/ChunJun-examples/json/hive3/stream_hive3_transaction.json -confProp {"yarn.application.id":"application_1650792512832_0134"}
根据上一行结果替换 yarn.application.id
三、ChunJun 读写Hive事务表源码分析压缩器是在 Metastore 境内运行的一组后台程序,用于支持 ACID 系统。它由 Initiator、 Worker、 Cleaner、 AcidHouseKeeperService 和其他一些组成。
1、Compactor● Delta File Compaction
在不断的对表修改中,会创建越来越多的delta文件,需要这些文件需要被压缩以保证性能。有两种类型的压缩,即(minor)小压缩和(major)大压缩:
minor 需要一组现有的delta文件,并将它们重写为每个桶的一个delta文件
major 需要一个或多个delta文件和桶的基础文件,并将它们改写成每个桶的新基础文件。major 需要更久,但是效果更好
所有的压缩工作都是在后台进行的,并不妨碍对数据的并发读写。在压缩之后系统会等待,直到所有旧文件的读都结束,然后删除旧文件。
●Initiator
这个模块负责发现哪些表或分区要进行压缩。这应该在元存储中使用hive.compactor.initiator.on来启用。 每个 Compact 任务处理一个分区(如果表是未分区的,则处理整个表)。如果某个分区的连续压实失败次数超过 hive.compactor.initiator.failed.compacts.threshold,这个分区的自动压缩调度将停止。
● Worker
每个Worker处理一个压缩任务。 一个压缩是一个MapReduce作业,其名称为以下形式。
● Cleaner
这个进程是在压缩后,在确定不再需要delta文件后,将其删除。
● AcidHouseKeeperService
这个进程寻找那些在hive.txn.timeout时间内没有心跳的事务并中止它们。系统假定发起交易的客户端停止心跳后崩溃了,它锁定的资源应该被释放。
● SHOW COMPACTIONS
该命令显示当前运行的压实和最近的压实历史(可配置保留期)的信息。这个历史显示从HIVE-12353开始可用。
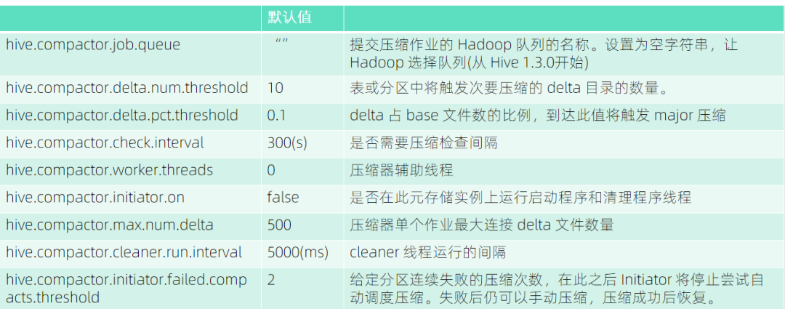
● Compact 重点配置
- debug hive client
hive --debug
- debug hive metastore
hive --service metastore --debug:port=8881,mainSuspend=y,childSuspend=n --hiveconf hive.root.logger=DEBUG,console

- debug hive mr 任务




最后为大家介绍ChunJun 文件系统未来规划:
● 基于 FLIP-27 优化文件系统
批流统一实现,简单的线程模型,分片和读数据分离。
● Hive 的分片优化
分片更精细化,粒度更细,充分发挥并发能力
● 完善 Exactly Once 语义
加强异常情况健壮性。
● HDFS 文件系统的断点续传
根据分区,文件个数,文件行数等确定端点位置,状态存储在 checkpoint 里面。
● 实时采集文件
实时监控目录下的多个追加文件。
● 文件系统格式的通用性
JSON、CSV、Text、XM、EXCELL 统一抽取公共包。
袋鼠云开源框架钉钉技术交流qun(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack