Flink 作为新一代基于事件流的、真正意义上的流批一体的大数据处理引擎,正在逐渐得到广大开发者们的青睐。就从我自身的视角看,最近也是在数据团队把一些原本由 Flume、SparkStreaming、Storm 编写的流式作业往 Flink 迁移,它们之间的优劣对比本篇暂不讨论。
近期会总结一些 Flink 的使用经验和原理的理解,本篇先谈谈 Flink 中的状态和容错机制,这也是 Flink 核心能力之一,它支撑着 Flink Failover,甚至在较新的版本中,Flink 的 Queryable State 可以把内部状态提供到外部系统进行查询进而为一些 BI 大屏等数据场景提供直接的支持。
关于有状态计算先说说什么是有状态计算,「状态」的概念比较宽泛,它既可以是 Flink 在运行过程中不断产生的一些聚合指标,例如『每分钟活跃用户量』、『每小时系统成交额』等等之类被实时不断聚合的变量。也可以是 Flink 窗口计算中未达到触发条件前的数据集、也可以是 Kafka、Pulsar 等队列的消费位移。
状态分类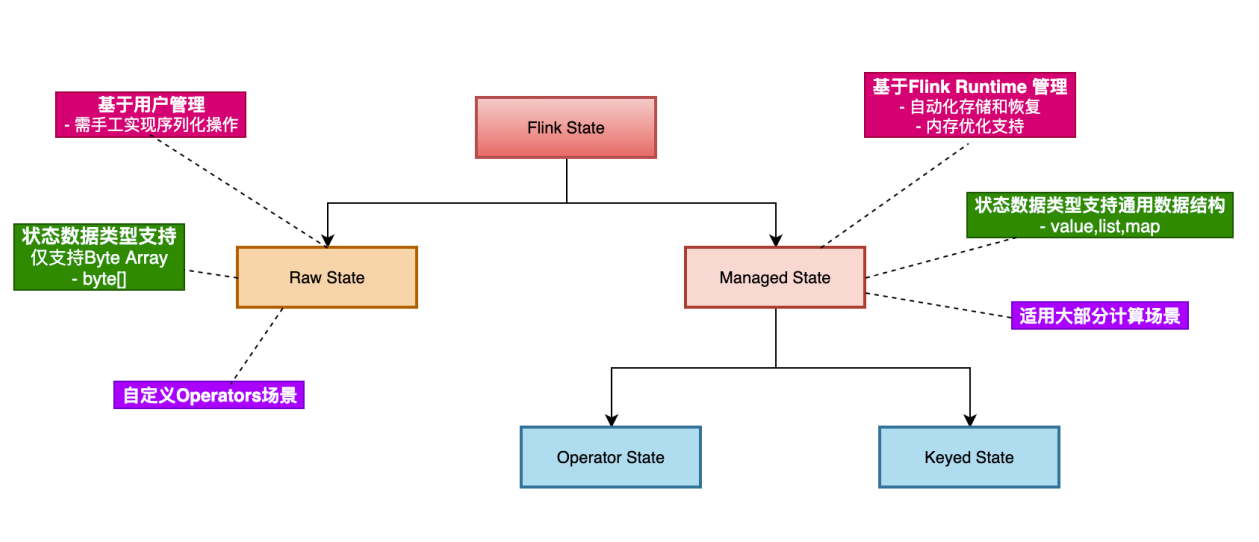
Flink 中的状态从管理方式上来说,分为 Raw State 和 Managed State。其中,Raw State 是完全由用户管理的,用户需要实现状态的序列化和反序列化且支持的数据类型有限制,一般很少会用到,除非在一些需要自定义算子实现的场景下,Flink 自带的一些状态无法派上用场并且需要使用状态的场景下才会使用。
Managed State 根据数据流是否经过 「keyBy」算子,分为 Keyed State 和 Operate State。其实这俩的区别不是太大,Keyed State 只是一种特殊情况下的 Operate State,本质上他们还是使用 Flink 预定义好的一些状态类型。

官网的解释已经很清楚了,这里直接复制过来,作一些补充解释。其中
ValueState 就是可以存储一个值,可以理解为一个普通变量; ListState 是由一个 List 实现的列表,可以存储一个状态集合; ReducingState 保存一个单值,并且需要你提供 ReducingFunction,它会在里往里面添加元素的同时调用你的函数自动聚合结果,但要求类型统一,你不能两次 add 元素类型是不同的; AggregatingState 允许你输入和输出的数据类型不一样,也就是我 add(float) 得到 int 是被允许的,具体逻辑怎么转换取决于你的 AggregateFunction。
那么,再来说说 Keyed State 和 Operate State 的区别,数据流 「keyBy」之后产生 KeyedStream,下游算子收到的数据元素具有相同的 key,那么对于这些算子中使用的状态就叫 Keyed State,它会自动绑定 key,一个 key 对应一个 State 存储,也就是不同 key 的 State 是分开的。
而 Operate State 并不是基于 KeyedStream,所以在这些算子里使用状态,其实绑定的是当前算子实例上,需要注意的是,绑定的是算子实例,也就是和你的并行度是有关系的。下文我会说状态的存储,其实状态是存储在 TaskManager 节点本地的。
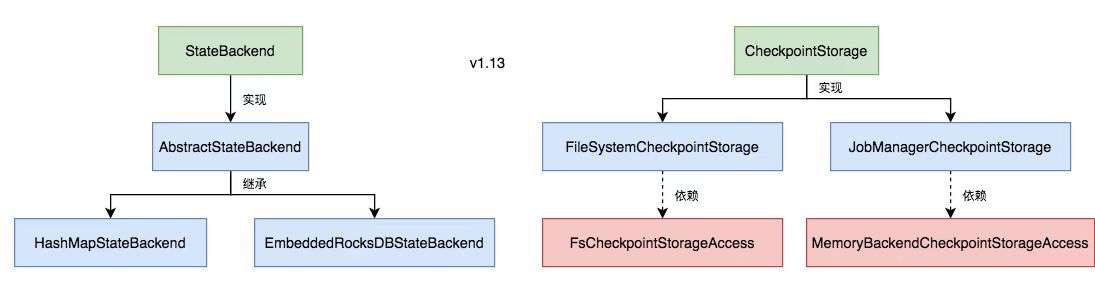
状态后端顾名思义,状态后端其实指的就是状态的存储方式以及位置。Flink1.13 以前把普通状态和 job checkpoint(快照文件) 的后端存储配置是在一起的。分为 MemoryStateBackend、FsStateBackend、RocksDBStateBackend,分别是基于内存、文件系统以及 RocksDb(一种KV类型的本地存储DB)。
而 Flink1.13 以后将普通数据状态和 checkpoint 的状态存储后端分离了,HashMapStateBackend、EmbeddedRocksDBStateBackend 是普通状态的两个后端,分别是基于内存 HashMap 和 基于 RocksDb 两种后端。checkpoint 的配置也分为内存和文件系统(file、hdfs、rocksDb等)。也就是你可能有多种组合,数据状态存储在内存而 checkpoint 却存储在文件系统等。
//设置内存状态后端
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new HashMapStateBackend());
//设置RocksDb状态后端
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new EmbeddedRocksDBStateBackend());
//设置checkpoint内存存储
env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage());
//设置checkpoint文件存储
env.getCheckpointConfig().setCheckpointStorage("file:///checkpoint-dir");
env.getCheckpointConfig().setCheckpointStorage("hdfs://namenode:40010/flink/checkpoints");
上文也多次提到了 Checkpoint,其实它是 Flink Failover 的基础,在 Flink 中叫做检查点,简单来说就是它把 job 运行过程中各个算子中的状态快照存储到状态后端,当 job 发生异常即可从最近的 Checkpoint 文件恢复故障前各个算子中数据处理现场。
Savepoint 和 Checkpoint 本质上是一个东西,只不过 Checkpoint 由 Flink 管理触发和存储,而 Savepoint 一般是用户主动通过命令去触发并指定文件输出路径。Checkpoint 是用于故障恢复,Savepoint 一般用于程序升级。
实现原理 Aligned Checkpoints(对齐)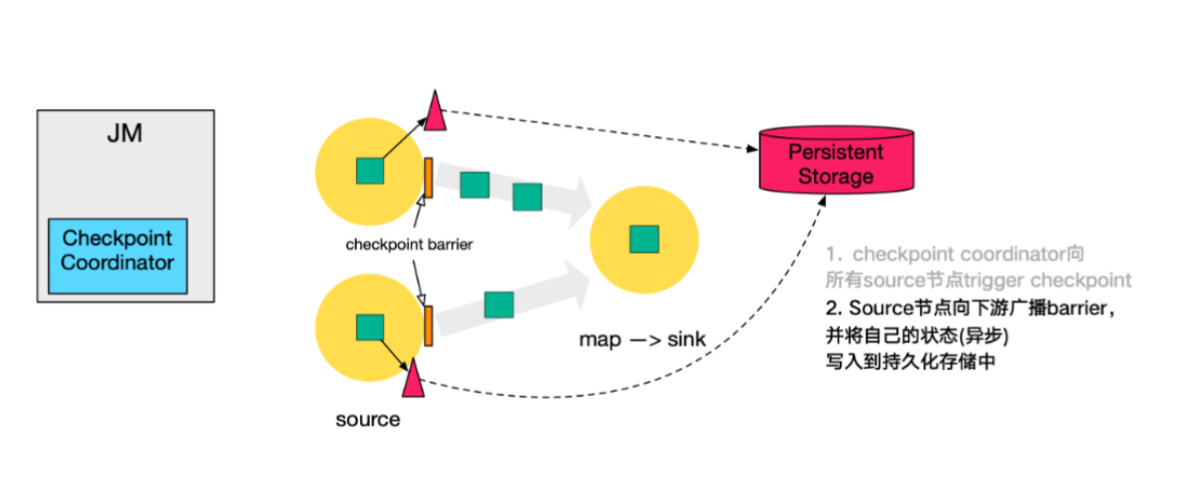
每个 Jobmanager 都有一个组件 checkpointCoordinator 负责整个 job 的 Checkpoint 触发,它会根据用户配置的生成 Checkpoint 间隔时间,定时往 source 数据流中插入特殊数据(barrier),然后 barrier 数据就像普通数据一样流向下游算子,下游算子在收到 barrier 数据之后会停止处理数据等待「对齐」。
这个「对齐」操作一直是性能瓶颈,它指的是某个算子只有等到所有上游实例的 barrier 事件之后才会开始做 Checkpoint,一个简单 union 例子:A、B 两股数据流合并到 C,那么 C 只有收到 A 和 B 两条流的 barrier 事件之后才会做 Checkpoint。
其实也比较容易理解,假如 A 做完 Checkpoint 并将自己处理到的数据偏移量记录到快照中,向 C 传播 barrier 事件,B 负载比较高还没开始做,那么如果当 C 只收到 A 的 barrier 事件后就开始做 Checkpoint 并刚好在它做完之后发生 job 故障并开始恢复,那么 B 其实是没有做完 Checkpoint 的,只能恢复到上一次的,这就直接导致上次以来所有的数据处理需要重复处理。这是比较大的问题,所以有个「对齐」操作。
以上只是基于没有「对齐」操作的前提下做的假设,回到正常的处理流程上来。每个算子在自己做完 Checkpoint 后就会通知 checkpointCoordinator 并告知快照文件存储位置,当最后一个算子完成了 Checkpoint,那么整个 Checkpoint 流程 Completed。
上文其实也提到了,对齐的 Checkpoint 存在比较大的性能瓶颈,一方面会阻塞数据流正常处理,另一方面可能会导致 Flink 反压进而导致 Checkpoint 超时 job 失败并积压更多的数据待处理,反压的问题待会儿说,先看下非对齐特性。
Flink1.11 以后加入了 UnAligned Checkpoints,但仍不是默认配置,需要显式配置,原因是非对齐的方式会产生比较大的 State 用于缓存一些数据,仍然只适用于一些容易高反压且复杂难以优化的 job。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// enables the unaligned checkpoints
env.getCheckpointConfig().enableUnalignedCheckpoints();
Chandy-Lamport 算法的状态变化如下:
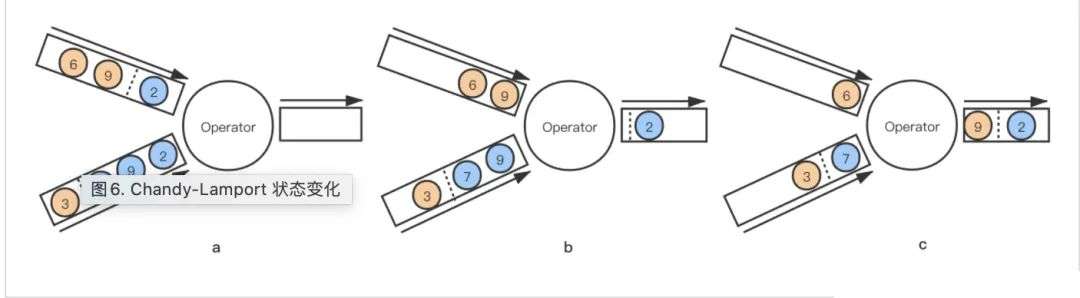
对于非对齐的 Checkpoint 来说,任意一条流的 barrier 事件到来都将直接触发当前算子的 Checkpoint。以上图来说,上面的流称为 A 流,下面的流称为 B 流,虚线是 barrier 事件,我们假设这是一个 equals-join 操作。
当 A 流中的数据「2」流过 Operator 并且和 B 流中的数据「2」join 成功,Operator 算子向下游输出数据「2」 然后收到 A 流的 barrier 事件,Operator 算子当即开启本算子的 Checkpoint 并向下游输出 barrier,此时这个 Checkpoint 已经是一个 Running 的状态 这时 B 流过来的每一条数据都会被缓存在状态中,直到收到 B 流的 barrier 事件,这期间 A 流和 B 流是正常 join 处理的,完全无阻塞的 当收到来自 B 流的 barrier,停止对 B 流数据的缓存,完成当前算子的异步快照(快照中会包含所有缓存的B流数据)
这样,其实不论哪个时间点出现 job 的故障恢复,从 Checkpoint 恢复出来算子对齐的状态+缓存(会被恢复到输出channel)的数据即可保证数据处理现场都是正确的。但是缺点比较明显,就是需要保存大容量的状态,Checkpoint 文件也是很大,job 恢复的速度也会比较慢。
关于 Flink 反压反压就是指 Flink 中上下游算子数据处理能力不匹配,下游算子处理太慢,上游算子发送区数据溢出。反压造成的最常见的影响就是造成 Checkpoint 超时,进而的 job 故障恢复。
Credit-Based 反压机制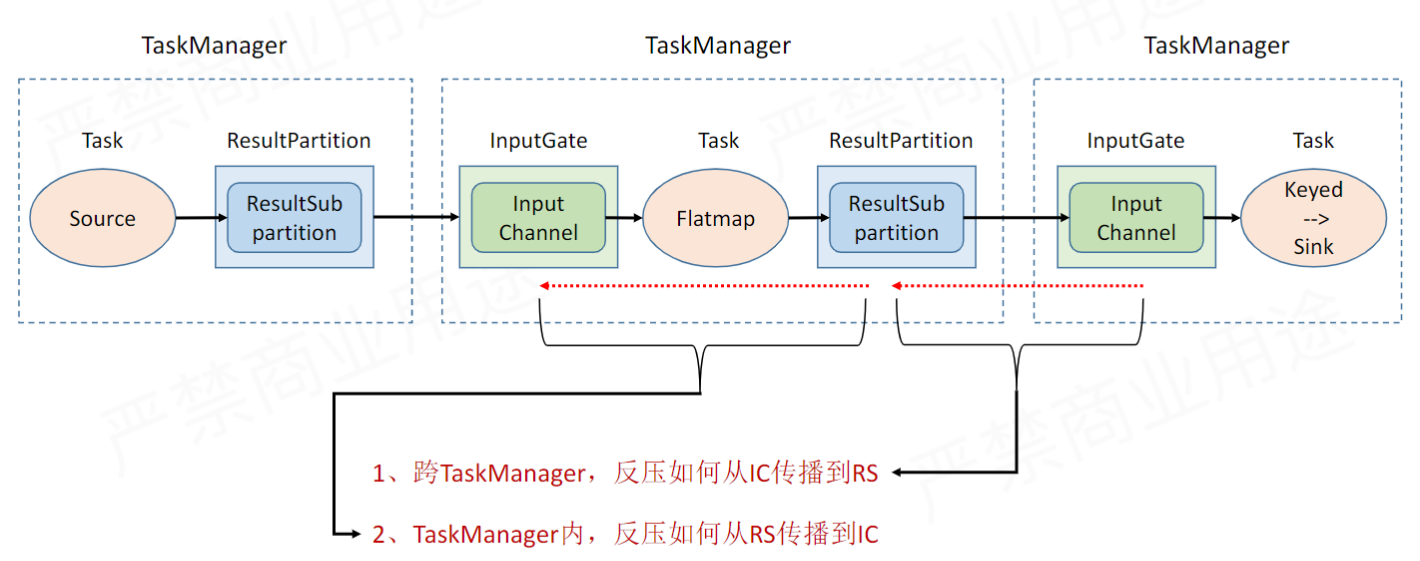
反压其实主要就分为两个部分,一个是算子与算子之间,下游算子要通过反压限制上游算子的发送速率,另一个是每个算子内部,写操作要反压限制读操作的读取速率。
TaskManager 间反压机制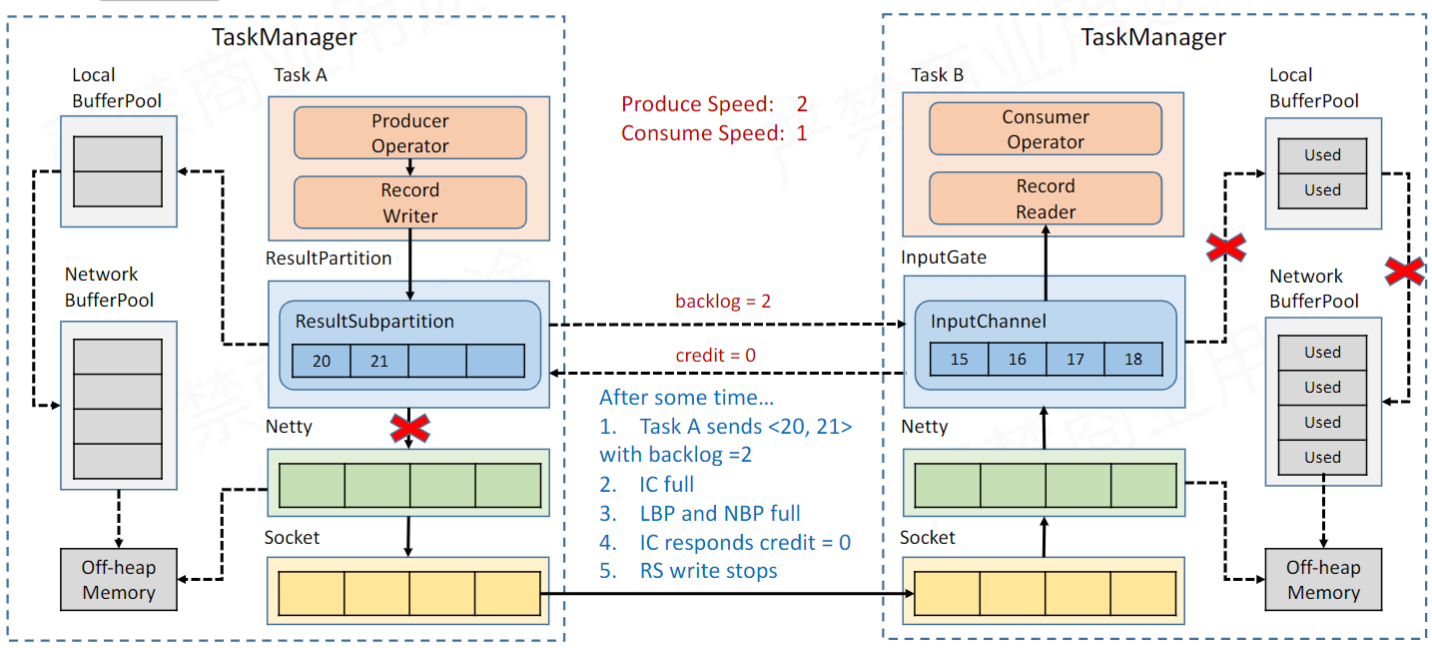
这张图展示了 Flink 算子跨节点通信的基本流程,NetWorkBufferPool 在每个 TaskManager 管理着网络通信相关的缓冲区内存申请释放; LocalBufferPool 是每个算子内部的缓冲池,从 NetWorkBufferPool 申请而来;ResultSubpartition 是写出缓冲区,从 LocalBufferPool 申请而来;InputChannel 是读缓冲区,从 LocalBufferPool 申请而来。
整体的流程就是,Writer 写数据到 ResultSubpartition,再往下传到 Netty,最终通过 Socket 发到其他节点,其他节点通过 Reader 读取数据写入 InputChannel。
Credit 也叫授信机制,每次从写缓冲区往下游节点写数据的时候会通过「backlog」告诉下游的 Reader 自己还积压多少数据未发送。而下游 Reader 接收数据的同时会去检查自己是否还有足够的空间放下未来即将到来的数据,通过「credit」反应出来,如果没有足够的空间且向 LocalBufferPool 申请无果就会返回「credit=0」。
Writer 得到「credit=0」后会阻塞往 Netty 写数据的操作,进而缓解了下游算子的压力(有探活机制,一旦检测到下游可写会恢复写操作的)
TaskManager 内部反压机制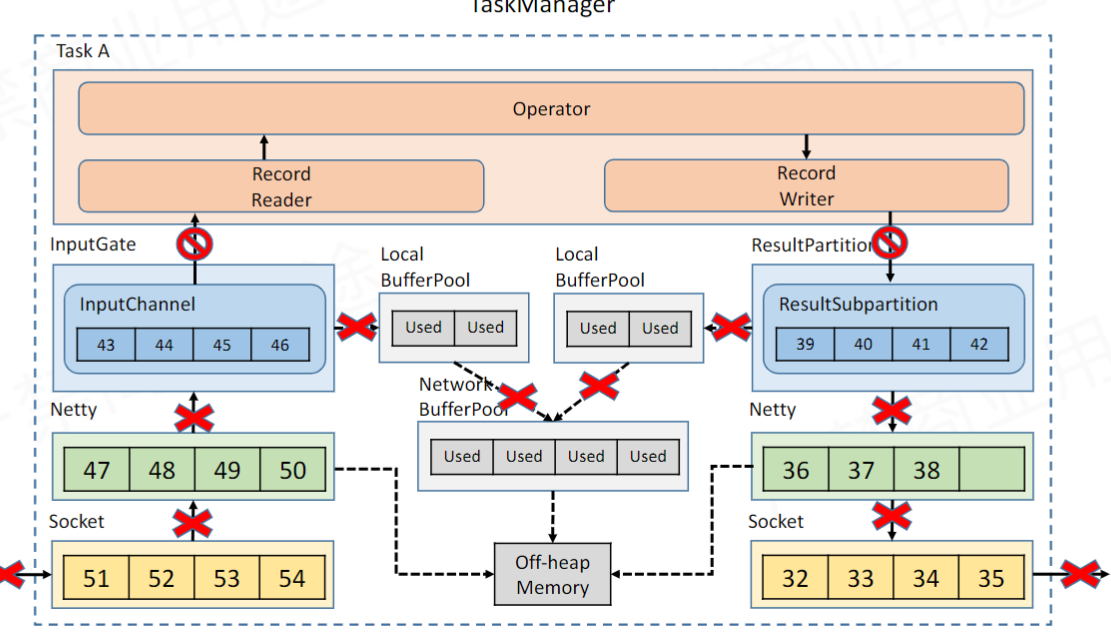
上面谈到下游反馈回来的「credit=0」会阻塞自己对外的输出操作,那么它也应该传播反压到当前节点的读操作。其实 Flink 里面是把 Reader 和 Writer 放在一个线程里的,那么如果写被阻塞了,读就自然被阻塞住。
这样上游算子就会迅速填满 InputChannel,自动触发反压,向上一级级传播,完成整个反压的全局调整。
到这里其实反压就介绍完了,上文说道反压会影响到 Checkpoint,就是说一级级反压的结果就是整个 job 中数据流动缓慢,以至于 Checkpoint barrier 在一定时间内没有完成对齐进而会导致 Checkpoint 超时失败,任务重启,然后由于重启回退又有更严重的数据积压,形成恶性循环。(也就是非对齐 Checkpoint 要解决的问题)
欢迎交流~
