在web开发中,经常涉及到对文本、文件等进行base64编码处理,在之前的开发中,使用js-base64来进行处理,但其实浏览器已经原生包含了处理方法。性能更好,兼容性也更高。 btoa() - Bi
在web开发中,经常涉及到对文本、文件等进行base64编码处理,在之前的开发中,使用js-base64来进行处理,但其实浏览器已经原生包含了处理方法。性能更好,兼容性也更高。
btoa() - Binary to ASCIIbtoa()方法可以将一个二进制字符串(例如,将字符串中的每一个字节都视为一个二进制数据字节)编码为 Base64 编码的 ASCII 字符串。
语法:
// 浏览器上下文中
var encodeData = window.btoa(someString)
// js Worker 线程
var encodeData = self.btoa(someString)
示例:
window.btoa('someString')
// 返回 c29tZVN0cmluZw==
atob() 对经过 base-64 编码的字符串进行解码。
语法:
// 浏览器上下文中
var decodeData = window.atob(someString)
// js Worker 线程
var decodeData = self.atob(someString)
示例:
window.atob('c29tZVN0cmluZw==')
// 返回 someString
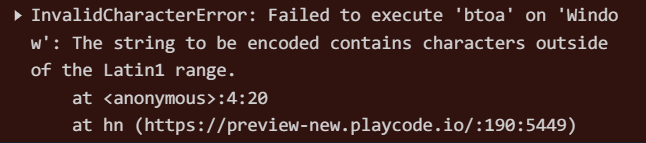
如果直接编码中文,会出现报错
window.btoa('一些字符串')
报错:
因为很明显中文超出了Latin1的语言集范围
Latin1是ISO-8859-1的别名,有些环境下写作Latin-1。ISO-8859-1编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。
btoa(encodeURIComponent('一些字符串'))
// 返回 JUU0JUI4JTgwJUU0JUJBJTlCJUU1JUFEJTk3JUU3JUFDJUE2JUU0JUI4JUIy
decodeURIComponent(atob('JUU0JUI4JTgwJUU0JUJBJTlCJUU1JUFEJTk3JUU3JUFDJUE2JUU0JUI4JUIy'))
// 返回 一些字符串
二次编码的问题是字母全部为大写,且转换后字符串长度比较长,这个问题通过使用escape三次编码可以解决,长度更短更美观
btoa(unescape(encodeURIComponent('一些字符串')))
// 返回 5LiA5Lqb5a2X56ym5Liy
decodeURIComponent(escape(atob('5LiA5Lqb5a2X56ym5Liy')))
// 返回 一些字符串

借助FileReader对象和readAsDataURL方法,我们可以把任意文件转为Base64 Data-URI。假设我们的文件对象是file,则转换的JavaScript代码如下:
var reader = new FileReader();
reader.onload = function(e) {
// e.target.result就是该文件的完整Base64 Data-URI
};
reader.readAsDataURL(file);