字符组,量词,元字符 re模块,也就是我们常说的正则 正则校验网站:http://tool.chinaz.com/regex/ 字符组 在一个字符的位置上能出现的内容 # [1bc] 是一个范围 # [0-9][A-Z][a-z] 匹配三
字符组,量词,元字符
re 模块,也就是我们常说的正则
正则校验网站:http://tool.chinaz.com/regex/
字符组
在一个字符的位置上能出现的内容
# [1bc] 是一个范围# [0-9][A-Z][a-z] 匹配三个字符
# [abc0-9] 匹配一个字符
# [0-9a-zA-Z] 匹配一个字符
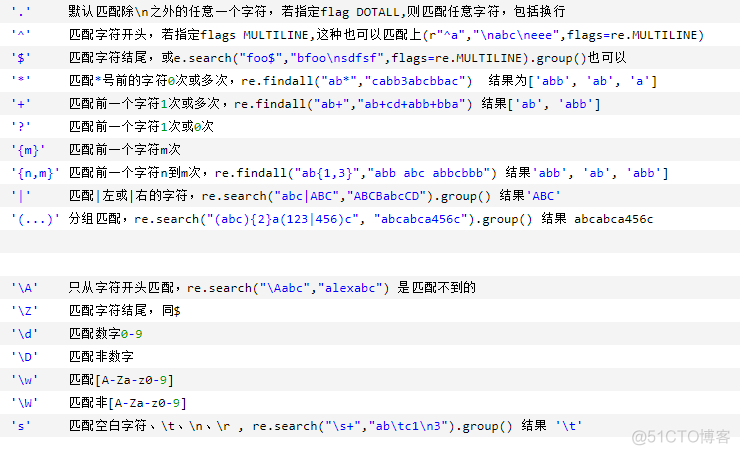
量词
在量词的后面跟了一个 ? 取消贪婪匹配 非贪婪(惰性)模式
# ? 重复零次或一次 0-1# + 重复一次或更多次 1-n
# * 重复零次或更多次 0-n
# {n} 重复n次
# {n,} 重复n次或更多次
# {n,m} 重复n到m次
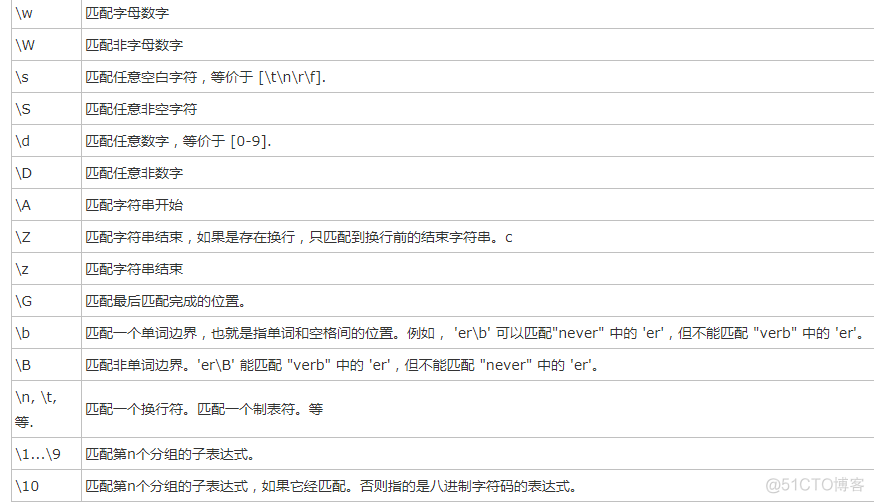
元字符
# \d == [0-9] 也表示匹配一个字符,匹配的是一个数字# \w == [0-9a-zA-Z_] 也表示匹配一个数字字母下划线
# \s == [\n \t] 包括回车 空格 和 制表符tab
# \n 匹配回车
# \t 匹配制表符
# \D 匹配非数字
# \W 匹配非数字字母下滑线
# \S 匹配非空白
# ^ 匹配字符串的开始
# $ 匹配字符串的结尾
# a|b 匹配字符a或字符b
# () 匹配括号内的表达式,也表示一个组
# [^...]匹配除了字符组中字符的所有字符
# . 匹配除换行符以外的任意字符
# [\d\D] [\w\W] [\s\S] 都是匹配所有
特殊用法:在量词的后面跟了一个 ? 取消贪婪匹配 非贪婪(惰性)模式
转义符 \
在正则表达式中,有很多有特殊意义的是元字符,比如\n和\s等,如果要在正则中匹配正常的"\n"而不是"换行符"就需要对"\"进行转义,变成'\\'。
在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。所以如果匹配一次"\n",字符串中要写成'\\n',那么正则里就要写成"\\\\n",这样就太麻烦了。这个时候我们就用到了r'\n'这个概念,此时的正则是r'\\n'就可以了。
# |的用法 [1-9]\d{16}[0-9X]|[1-9]\d{14} 身份证号# ()的用法 [1-9]\d{14}(\d{2}[1-9X])? 身份证号
# 匹配整数或小数:-?\d+(\.\d+)*


re 模块
# re.match 从头开始匹配# re.search 匹配包含
# re.findall 把所有匹配到的字符放到以列表中的元素返回
# re.splitall 以匹配到的字符当做列表分隔符
# re.sub 匹配字符并替换
# re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
# M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
# S(DOTALL): 点任意匹配模式,改变'.'的行为
# findall 会优先显示分组中的内容,要想取消分组优先,(?:正则表达式)
# plit 遇到分组 会保留分组内被切掉的内容
# search 如果search中有分组的话,通过group(n)就能够拿到group中的匹配的内容
# 分组命名:
# (?P<name>正则表达式) 表示给分组起名字
# (?P=name)表示使用这个分组,这里匹配到的内容应该和分组中的内容完全相同
match
import reres = re.match('liu', 'liufujia') # 从头开始匹配
print(res.group())
res = re.match('liu\d+', 'liu352521fujia') # \d表示匹配一个数字,\d+匹配一个或多个数字
print(res.group())
res = re.match('.', 'liufujia') # .匹配任意一个字符
print(res.group())
res = re.match('.+', 'liufujia77') # .匹配任意一个字符,.+匹配所有
print(res.group())
结果:
liuliu352521
l
liufujia77
search
import reres = re.search('f[a-z]+a', 'liu321fuJiafujia123') # . 以f开头,[a-z]小写字母一个,[a-z]+多个小写字母,r[a-z]+a表示以r开头,以a结尾,中间多个任意小写字母
print(res.group())
res = re.search('[a-z]+', 'liuFujia', flags=re.I) # 忽略大小写
print(res.group())
res = re.search('#.+#', '123#hello#j58')
print(res.group())
res = re.search('aal?', 'aaalexaaa') # 匹配?前的l一次或0次
print(res.group())
res = re.search('[0-9]{3}', 'as1def2rt3456gh') # 匹配数字三次
print(res.group())
结果
fujialiuFujia
#hello#
aa
345
案例二
res = re.search('abc|ABC', 'ABCAabcCD') # 先匹配左边的abc,第一个满足大写的就返回大写的
print(res.group())
res = re.search('(abc){2}', 'abcccabcabcjid') # 匹配abc 两次
print(res.group())
res = re.search('\A[0-9]+[a-z]+\Z', '2658afgdfd') # 匹配数字开头,字母结尾
print(res.group())
res = re.search('\A[0-9]+[a-z]\Z', '2658a') # 匹配数字开头,一个字母结尾,字母大于一个会报错
print(res.group())
res = re.search('\d+', 'sd5ere65tere862') # 匹配数字,只匹配一次
print(res.group())
res = re.search('\w+', '$sd5ere65t#ere862') # 匹配非特殊字符一次
print(res.group())
结果
ABCabcabc
2658afgdfd
2658a
5
sd5ere65t
findall
import reres = re.findall('[0-9]{2,3}', 'as1def25rt3456gh') # 匹配前一个字符n到m次
print(res)
res = re.findall('abc|ABC', 'ABCAabcCD') # findall满足的都匹配
print(res)
res = re.findall('\d+', 'sd5ere65tere862')
print(res)
res = re.findall('\D+', '$sd5ere65tere862') # 匹配非数字多次
print(res)
res = re.findall('\w+', '$sd5ere65t#ere862') # 匹配非特殊字符多次
print(res)
结果:
['25', '345']['ABC', 'abc']
['5', '65', '862']
['$sd', 'ere', 'tere']
['sd5ere65t', 'ere862']
split 和 sub
import reres = re.split('[a-z]', '7sdr85fd8gf52')
print(res)
res = re.split('[a-z]+', '7sdr85fd8gf52')
print(res)
res = re.sub('[0-9]+', '|', '2sd36fd5er9') # 替换,匹配所有的数字,替换为|
print(res)
res = re.sub('[0-9]+', '|', '2sd36fd5er9', count=2) # 替换,匹配前两次的数字,替换为|
print(res)
结果:
['7', '', '', '85', '', '8', '', '52']['7', '85', '8', '52']
|sd|fd|er|
|sd|fd5er9
时间效率和空间效率
compile ====》 时间效率
finditer ====》 空间效率
import rere.findall('-0\.\d+|-[1-9]+(\.\d+)?', 'alex83egon20taibai40') # --> python解释器能理解的代码 --> 执行代码
ret = re.compile('-0\.\d+|-[1-9]\d+(\.\d+)?')
res = ret.search('alex83egon-20taibai-40')
print(res.group())
# 节省时间 : 只有在多次使用某一个相同的正则表达式的时候,这个compile才会帮助我们提高程序的效率
结果:
-20import reprint(re.findall('\d', 'sjkhkdy982ufejwsh02yu93jfpwcmc'))
ret = re.finditer('\d', 'sjkhkdy982ufejwsh02yu93jfpwcmc')
for r in ret:
print(r.group())
ret = re.findall('-0\.\d+|-[1-9]\d*(\.\d+)?', '-1asdada-200')
print(ret)
结果
['9', '8', '2', '0', '2', '9', '3']9
8
2
0
2
9
3
['', '']
分组
import reret = re.findall('www.(baidu|csca).com', 'www.csca.com')
print(ret)
结果:
['csca']取消分组优先 ?:
import reret = re.findall('www.(?:baidu|csca).com', 'www.csca.com')
print(ret)
结果:
['www.csca.com']import reret = re.split('\d+', 'abc83egon20bai40')
print(ret)
ret = re.split('(\d+)', 'abc83egon20bai40')
print(ret)
结果:
['abc', 'egon', 'bai', '']['abc', '83', 'egon', '20', 'bai', '40', '']
分组遇见 search
import reret = re.search('\d+(.\d+)(.\d+)(.\d+)?', '1.2.3.4-2*(60+(-40.35/5)-(-4*3))')
print(ret.group())
print(ret.group(1))
print(ret.group(2))
print(ret.group(3))
结果:
1.2.3.4.2
.3
.4