java的String对象底层是有字符数组存储的,理论上char[] 最大长度是int的最大值,实际
思路:
首先,String字面常量是由String类来维护的,并且在编译时就可以确定(具体请参考String常量池)。因而,如果String字面常量存在一个最大的长度(目前暂且假设),而我们使用的字面常量又超过了这个极限,那么,在编译期间,编译器就能够给出错误信息。因此,我们可以使用IO流生成Java文件,文件的内容就是声明一个String对象,然后使用字面常量赋值,根据动态编译结果,调整字面常量的长度,最后得出字面常量的最大长度值
根据以下代码得出结论(代码来自书《Java深入解析:透析Java本质的36个话题 》):
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.io.OutputStream;
import javax.tools.JavaCompiler;
import javax.tools.ToolProvider;
public class LiteralLength {
public static void main(String[] args) throws Exception {
String fileName = "D:/Literal.java";
StringBuilder prefix = new StringBuilder();
prefix.append("public class Literal{ String s = \"");
int low = 0;
int high = 100_0000;
int mid = (low + high)/2;
StringBuilder literal = new StringBuilder(high);
int result;
String ch = "A";
JavaCompiler compiler = ToolProvider.getSystemJavaCompiler();
//自定义错误输出流 取代System的err
OutputStream err = new OutputStream() {
@Override
public void write(int b) throws IOException {
}
};
int max = 0;
for (int i = 0; i < mid; i++) {
literal.append(ch);
}
while(low <= high){
StringBuilder fileContent
= new StringBuilder(literal.length() + prefix.length() * 2);
fileContent.append(prefix);
fileContent.append(literal);
fileContent.append("\";}");
FileWriter w = new FileWriter(fileName);
BufferedWriter bw = new BufferedWriter(w);
bw.write(fileContent.toString());
bw.close();
w.close();//生成java文件
result = compiler.run(null, null, err, fileName);
//代码点的数量
int codePointCount = literal.codePointCount(0, literal.length());
if(result == 0){//0表示没有编译错误
low = mid + 1;
mid = (low + high)/2;
max = codePointCount;
for (int i = codePointCount; i < mid; i++) {
literal.append(ch);
}
System.out.println("长度" + max
+ "编译成功,增加长度至" + mid);
}else{
//编译错误,说明字面量太长
high = mid - 1;
mid = (low + high)/2;
System.err.println("长度" + codePointCount
+ "编译失败,减少长度至" + mid);
int start = ch.length() == 1? mid : mid *2;
literal.delete(start, literal.length());
}
}
err.close();
System.out.println("最大字面量长度:" + max);
}
}
输出结果:
长度500000编译失败,减少长度至249999
长度249999编译失败,减少长度至124999
长度124999编译失败,减少长度至62499
长度62499编译成功,增加长度至93749
长度93749编译失败,减少长度至78124
长度78124编译失败,减少长度至70311
长度70311编译失败,减少长度至66405
长度66405编译失败,减少长度至64452
长度64452编译成功,增加长度至65428
长度65428编译成功,增加长度至65916
长度65916编译失败,减少长度至65672
长度65672编译失败,减少长度至65550
长度65550编译失败,减少长度至65489
长度65489编译成功,增加长度至65519
长度65519编译成功,增加长度至65534
长度65534编译成功,增加长度至65542
长度65542编译失败,减少长度至65538
长度65538编译失败,减少长度至65536
长度65536编译失败,减少长度至65535
长度65535编译失败,减少长度至65534
最大字面量长度:65534
但是若 修改代码
String ch = "α";
结论 : 最大字面量长度:32767
若 String ch = "字";
最大字面量长度:21845
在class文件中,使用CONSTANT_Utf8_info表来存放各种常量字符串,包括String字面常量,类或接口的全限定名,方法及变量的名称、描述符等。CONSTANT_Utf8_info表的结构如表 所示。

从表3-1可知,CONSTANT_Utf8_info表使用2字节来表示字符串的长度,因此,bytes数组的最大长度为216−1,即65535字节。可是,为什么4个字符(“A”、“á”、“字”与“㊣”)的运行结果各不相同呢?原因在于,在CONSTANT_Utf8_info表中,从“\u0001”~“\u007f”,bytes使用1字节来表示,空字符(null,即“\u0000”)和从“\u0080”~“\u07ff”,使用2字节来表示,从“\u0800”~“\uffff”,使用3字节来表示,而对于增补字符,即代码点范围在“U+10000”~“U+10FFFF”之间的字符,使用6字节来表示。也可以这样认为,增补字符是使用一个代理对来表示的,而代理对的取值范围为“\ud800”~“\udfff”,这些字符都在“\u0800”~“\uffff”之间,每个代理字符使用3字节表示,共6字节。上述的存储是在class文件中的实现,不要与Java程序中的字符相混淆,对于Java程序来说,“A”、“á”、“字”都使用一个char类型变量表示,即2字节,而“[插图]”(增补字符)使用两个char类型变量表示,即4字节。
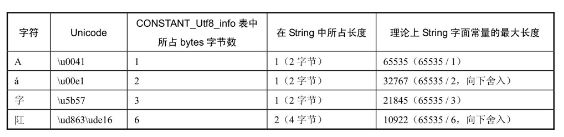
String字面常量的最大长度与String在内存中的最大长度是不一样的,后者的最大长度为int类型的最大值,即2147483647,而前者根据字符(字符Unicode值)的不同,最大长度也不同,最大长度为65534(可手动修改class文件,令输出结果为65535)。
String字面常量的最大长度是由CONSTANT_Utf8_info表来决定的,该长度在编译时确定,如果超过了CONSTANT_Utf8_info表bytes数组所能表示的上限,就会产生编译错误。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持易盾网络。