https://blog.csdn.net/weixin_41044151/article/details/114629138
3.GOPROXY配置可以先通过go env查看当前的代理,然后决定是否需要更改
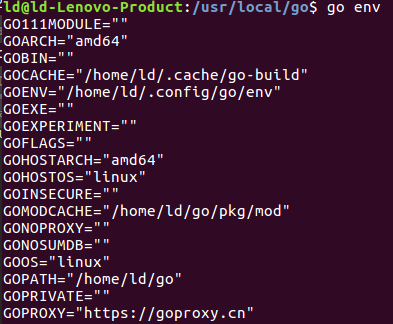
这里已经是国内代理,所以不用修改.否则使用下面命令修改:
go env -w GOPROXY=https://goproxy.cn,direct4.GO module设置
启用了Go Module模式之后,不一定非要将代码写到GOPATH目录下,所以也就不需要我们再自己配置GOPATH了,使用默认的即可,如上图"/home/ld/go".
但是我们需要去开启Go Module模式:https://blog.csdn.net/weixin_48962061/article/details/122568443
Linux中,只要在 /etc/profile 中添加 export GO111MODULE=on
然后执行 source /etc/profile 刷新即可.
然后进入自己的项目中,执行"go mod init 项目名"即可

通过go mod tidy安装执行依赖,最后通过go build进行编译即可

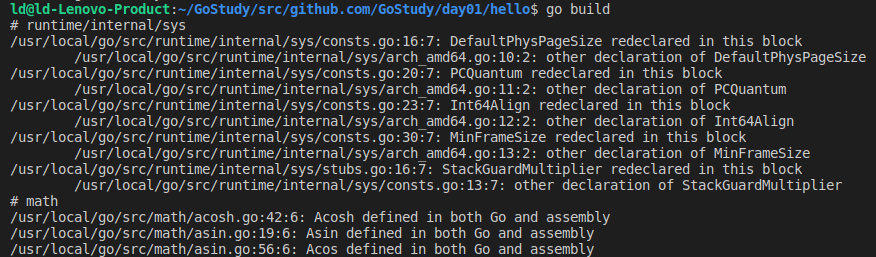
一般是由于忘记之前安装过Go,导致/usr/local/go中存在多份go依赖包所导致,我们直接移除
sudo rm -rf /usr/local/go
然后重新解压缩即可
sudo tar -zxvf go1.18.2.linux-amd64.tar.gz -C /usr/local
(2)如果出现:$GOPATH/go.mod exists but should not
一般是由于我们既设置了GOPATH,又开启了Go module所导致的.
它所说的,在$GOPATH下不允许有go.mod。你的$GOPTH是多少?不要和你运行go mod init的目录一样。让$GOPATH和你的项目目录(有go.mod的目录)不要有父子关系就可以。
最好将GOPATH设置为原来的/home/用户/go即可.开启模块支持后,并不能与$GOPATH共存,所以把项目从$GOPATH中移出.简而言之,go mod init的项目不要在GOPATH下!!!!
6.跨平台以后用到再了解 7.Go module这块后面需要详细学习,看看如何管理项目 8.rune为int32是4字节,而中文utf8占3字节,那么内部存放结构呢?https://www.oo2ee.com/?p=187(utf8,unicode讲的不错)
http://www.codebaoku.com/it-go/it-go-240840.html rune类型只是一种名称叫法,表示用来处理长度大于 1 字节( 8 位)、不超过 4 字节( 32 位)的字符类型
会根据每个字符的码点大小判断是否为 ASCII 字符,如果是,则算做 1 位;如果不是,则查询首字节表,明确字符占用的字节数,验证有效性后再进行计数。如码点值小于 128,则为占 1 字节的 ASCII 字符(或者说英文字符),一般中文就是3字节大小。
Go 语言把字符分byte和rune两种类型处理。byte是类型unit8的别名,用于存放占 1 字节的 ASCII 字符,如英文字符,返回的是字符原始字节。rune是类型int32的别名,用于存放多字节字符,如占 3 字节的中文字符,返回的是字符 Unicode 码点值。
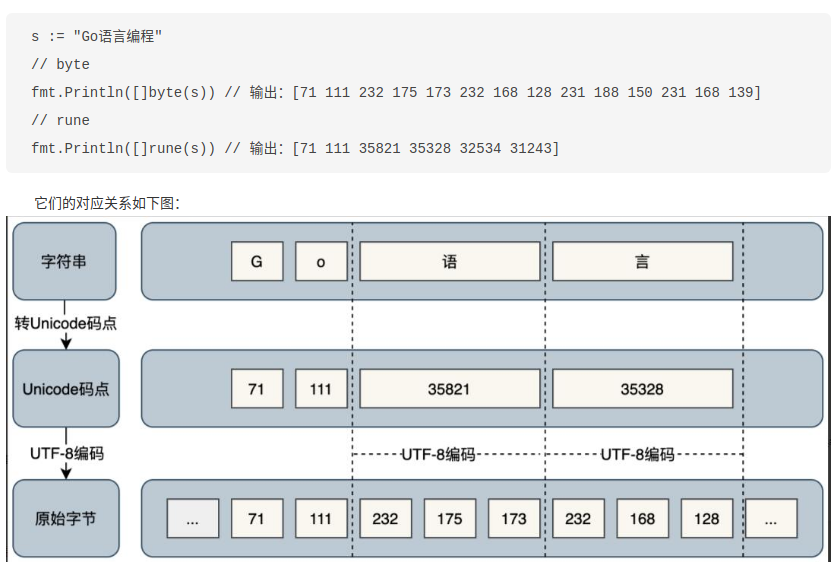
码点这些讲的不错:https://www.sohu.com/a/543058941_121359991
下面我们以一个中文字符的编码转换为例,如汉字 '好':
'好'的Unicode码点:
'好'.codePointAt() \\ 22909
,结果是22909;
22909在UTF-8的3字节数的编码区间 U+0800 (2048) ~ U+FFFF (65535);
22909的二进制值:101100101111101,有15位;
而3字节数的编码需要16位,前面补0,根据表中规则分成3组:0101 100101 111101;
依次填入对应的前缀:11100101 10100101 10111101,得到3个字节;
将得到的三个字节转成十六进制数据:E5 A5 BD,所以汉字 '好' 的UTF-8就是:E5 A5 BD。
S := "Hello,你好世界" // 字符存储 for i := 0; i < len(S); i++ { fmt.Println(S[:i]) } Sconv := []rune(S) for i := 0; i < len(Sconv); i++ { fmt.Println(Sconv[i]) //打印码点值 fmt.Println(string(20320),string(22909)) //输出"你 好",可以知道是按码点值来返回字符的 fmt.Printf("Type is %T, value is %s \n", string(Sconv[i]), string(Sconv[i])) }
可能有点乱,看完上面几篇文章差不多理解了.
个人感觉,rune是一个int32类型的别名,更是一种概念,用于存放各个字符的码点值的结构,为了兼容所有的字符,因此我们需要一个4字节的空间,用于表示足够大的码点值,可以包含所有的字符.通过码点值,我们可以获取对应的字符string(码点值)!!!
用于过渡byte和utf8等类型,感觉有种解耦的概念,但是让人轻易不容易理解原理,目前看来还没有Python好用....。后面了解清楚后,再补充吧
9.Go语言的%d,%p,%v等占位符的使用https://www.jianshu.com/p/66aaf908045e
10.切片cap的实际内存大小func testSlice() { a := [5]int{1,2,3,4,5} s := a[1:5] s2 := a[1:4] s3 := a[2:4] s4 := a[3:4] s5 := s4[1:] //对于切片s4的长度实际为1,我们[1:]后面默认为len(s4),即[1:1],无法取到后面的数据 s6 := s4[1:2] //可以强制去取后面属于cap长度的数据,为后面的数据5 fmt.Printf("s:%v,len(s):%v,cap(s):%v\n",s,len(s),cap(s)) fmt.Printf("s2:%v,len(s2):%v,cap(s2):%v\n",s2,len(s2),cap(s2)) fmt.Printf("s3:%v,len(s3):%v,cap(s3):%v\n",s3,len(s3),cap(s3)) fmt.Printf("s4:%v,len(s4):%v,cap(s4):%v\n",s4,len(s4),cap(s4)) fmt.Printf("s5:%v,len(s5):%v,cap(s5):%v\n",s5,len(s5),cap(s5)) fmt.Printf("s6:%v,len(s6):%v,cap(s6):%v\n",s6,len(s6),cap(s6)) }
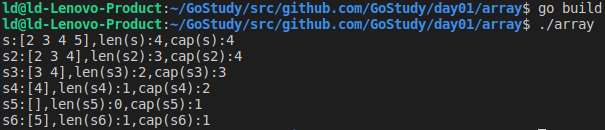
从结果和s6数据可以看出,切片实际的大小是取源数据的(low,end),比如s2看似取得{2,3,4},但是实际会获取索引1后<<索引1,...,索引cap-1>>的所有数据{2,3,4,5},所以cap为4,同样s3的cap为3...
另外在使用一个例子,更加普遍的解释上面的说法:
s7 := a[2:3] s8 := s7[1:3] fmt.Printf("s7:%v,len(s7):%v,cap(s7):%v\n",s7,len(s7),cap(s7)) fmt.Printf("s8:%v,len(s8):%v,cap(s8):%v\n",s8,len(s8),cap(s8))

每个切片会指向一个底层数组,这个数组的容量够用就添加新增元素。
当底层数组不能容纳新增的元素时,切片就会自动按照一定的策略进行“扩容”,此时该切片指向的底层数组就会更换。
“扩容”操作往往发生在append()函数调用时,所以我们通常都需要用原变量接收append函数的返回值。----防止扩容导致的内存地址变化
此外,当空间足够时,会按顺序进行添加元素,不会覆盖后面的原本数据,如下所示:
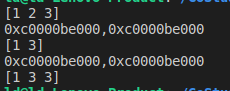
func testMap() { type Map map[string][]int m := make(Map) s := []int{1, 2} s = append(s, 3) fmt.Printf("%+v\n", s) m["q1mi"] = s fmt.Printf("%p,%p\n",s,m["q1mi"]) s = append(s[:1], s[2:]...) //没有进行扩容哦,原本足够容纳数据 fmt.Printf("%+v\n", s) fmt.Printf("%p,%p\n",s,m["q1mi"]) fmt.Printf("%+v\n", m["q1mi"]) }
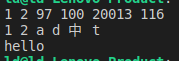
函数的参数中如果相邻变量的类型相同,则可以省略类型
func testParams(a,b int,c,d byte,e,f rune) { fmt.Println(a,b,c,d,e,f) fmt.Println(a,b,string(c),string(d),string(e),string(f)) } func main() { testParams(1,2,'a','d','中','t') fmt.Println("hello") }
func adder() func(int) int { var x int return func(y int) int { x += y return x } } func main() { var f = adder() fmt.Println(f(10)) //10 fmt.Println(f(20)) //30 fmt.Println(f(30)) //60 f1 := adder() fmt.Println(f1(40)) //40 fmt.Println(f1(50)) //90 }
对于我们调用的闭包函数(红色),每次被调用时,其外部(蓝色)函数中的变量声明周期会一直存在,直到我们重新调用外部函数,否则会一直存在.
3.defer执行时机:https://blog.csdn.net/m0_50889849/article/details/124697839一开始错误的认为遇到最后一个defer就开始执行,比如:(错误示例)
func main() { fmt.Println("start") defer fmt.Println(1) defer fmt.Println(2) defer fmt.Println(3) fmt.Println("end") }
以为的错误结果:
start 3 2 1 end
而实际正确的结果是:
start end 3 2 1
在Go语言的函数中return语句在底层并不是原子操作,它分为给返回值赋值和RET指令两步。而defer语句执行的时机就在返回值赋值操作后,RET指令执行前。具体如下图所示:
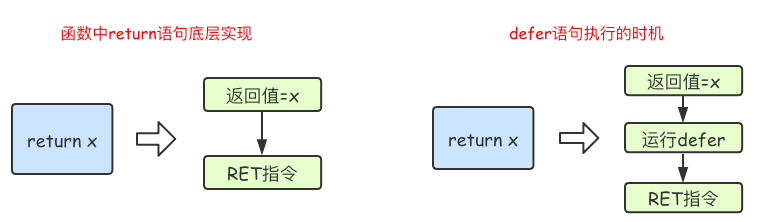
所有的defer语句会在当前函数的return阶段(中间)被调用!!!!,此外需要注意defer执行时是可以改变return中的返回值的 通过下面案例可以知道:
func f1() int { x := 5 defer func() { x++ }() return x } func f2() (x int) { defer func() { x++ }() return 5 } func f3() (y int) { x := 5 defer func() { x++ }() return x } func f4() (x int) { defer func(x int) { x++ }(x) return 5 } func main() { fmt.Println(f1()) fmt.Println(f2()) fmt.Println(f3()) fmt.Println(f4()) }
输出结果:

按照序列进行分析:
(1)fmt.Println(f1())func f1() int { x := 5 defer func() { x++ }() return x }
首先遇到defer语句,跳过,进入return,先将5赋值给返回值,然后执行闭包函数func对x执行++操作,虽然x=6,但是返回值并非为x,所以返回值依旧为5
(2)fmt.Println(f2())func f2() (x int) { defer func() { x++ }() return 5 }
注意返回值为x,在第一行被声明,跳过defer先进行return赋值指令,使得x=5,然后执行x++,x变为6,最后return的ret指令执行,返回x值,为6
(3)fmt.Println(f3())func f3() (y int) { x := 5 defer func() { x++ }() return x }
注意:返回值为y,所以return时,会将x=5赋值给y,之后的defer指令与y无关,所以不会影响返回值
(4)fmt.Println(f4())func f4() (x int) { defer func(x int) { x++ }(x) return 5 }
注意:匿名函数是定义了传参的,所以defer语句中是对局部变量的操作,依旧不会影响返回值
4.defer注册要延迟执行的函数时所应该注意 defer注册要延迟执行的函数时,该函数所有的参数都需要确定其值(就是说,函数参数在函数被写出时就会被确定了,后面在return中间阶段进行延迟执行的时候我们不需要再去关心参数问题了)func calc(index string, a, b int) int { ret := a + b fmt.Println(index, a, b, ret) return ret } func main() { x := 1 y := 2 defer calc("AA", x, calc("A", x, y)) x = 10 defer calc("BB", x, calc("B", x, y)) y = 20 }
因为calc("A", x, y)作为参数传入,所以会按照正常顺序进行操作,先进行执行,以便确定外部calc的参数准确值.
所以执行顺序如下:
calc("A", x, y) --- x=1,y=2
calc("B", x, y) --- x=10,y=2
calc("BB", 10, 12)
calc("AA",1,3)
5.struct内存对齐(其实和C一样)https://segmentfault.com/a/1190000017527311?utm_campaign=studygolang.com&utm_medium=studygolang.com&utm_source=studygolang.com
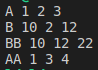
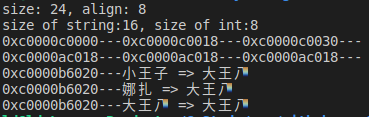
type student struct { name string //占16字节 age int //占8字节 } //注意:最大对齐系数也不会超过 8 func main() { st := student{} fmt.Printf("size: %d, align: %d\n", unsafe.Sizeof(st), unsafe.Alignof(st)) fmt.Printf("size of string:%d, size of int:%d\n",unsafe.Sizeof(string("a")),unsafe.Sizeof(int(1))) m := make(map[string]*student) stus := []student{ {name: "小王子", age: 18}, {name: "娜扎", age: 23}, {name: "大王八", age: 9000}, } for i := 0; i<len(stus);i++ { fmt.Printf("%p---",&stus[i]) } fmt.Println() for _, stu := range stus { m[stu.name] = &stu fmt.Printf("%p---",&stu) } fmt.Println() for k, v := range m { fmt.Printf("%p---",&v) fmt.Println(k, "=>", v.name) } }
之前主要使用C/C++,所以看到下面的部分代码后对Go语言的变量生命周期产生了兴趣(疑惑),与C/C++不同.
我去,Ubuntu下使用VsCode好像有Bug啊(可能版本问题),老是卡死!!!!
package main import ( "fmt" "encoding/json" ) type Student struct { ID int Gender string Name string } type Class struct { Title string Students []*Student } func main() { c := &Class{ Title: "101", Students: make([]*Student,0,100), } for i := 0;i<=10;i++ { stu := &Student{ //疑惑点 Name: fmt.Sprintf("stu%02d",i), Gender: "男", ID: i, } c.Students = append(c.Students,stu) } data, err := json.Marshal(c) if err != nil{ fmt.Println("json marshal failed!") return } fmt.Printf("json:%s\n",data) }
从C/C++角度来看,stu属于for循环内部的局部变量,因此即便我们获取空间地址返回给指针,也是有问题的,可能出现程序崩溃,但是在Go语言中似乎不同,能够正常运行,如下图所示:

在Go语言中,编译器会自动选择在栈上还是在堆上分配局部变量的存储空间,但可能令人惊讶的是,这个选择并不是由用var还是new声明变量的方式决定的。
var global *int func f() { var x int x = 1 global = &x } func g() { y := new(int) *y = 1 }
f函数中的x变量必须在堆上分配,因为它在函数退出后依然可以通过包一级的global变量找到,虽然它是在函数内部定义的。用Go语言的术语说,这个x局部变量从函数f中逃逸了;
相反,当g函数返回时,变量*y将是不可达的,也就是说可以马上被回收的。因此,*y并没有从函数g中逃逸,编译器可以选择在栈上分配*y的存储空间(译注:也可以选择在堆上分配,然后由Go语言的GC回收这个变量的内存空间),虽然这里用的是new方式。
其实在任何时候,你并不需为了编写正确的代码而要考虑变量的逃逸行为,要记住的是,逃逸的变量需要额外分配内存,同时对性能的优化可能会产生细微的影响。
Go语言的自动垃圾收集器对编写正确的代码是一个巨大的帮助,但也并不是说你完全不用考虑内存了。你虽然不需要显式地分配和释放内存,但是要编写高效的程序你依然需要了解变量的生命周期。例如,如果将指向短生命周期对象的指针保存到具有长生命周期的对象中,特别是保存到全局变量时,会阻止对短生命周期对象的垃圾回收(从而可能影响程序的性能)(笔者注:这在Java中是内存泄漏的一个场景)。
所以,我们可以使用指针去使得局部变量逃逸出原本的代码段,延长其生命周期!!!! 三: 1.go module使用之replace如https://www.liwenzhou.com/posts/Go/11-package/#autoid-1-2-1中所说,通过replace可以实现import本地package,但是有一点需要注意:
两个package的名字不能一样,否则会出现下面问题

注意,一个package为main,另外一个为overtime,不要使得两个同名!!
2.接口---值接收者和指针接收者详细看https://www.liwenzhou.com/posts/Go/12-interface/.
作为一个C/C++转Go的学习者,在我看来接口类型的变量本质上就是类似于指针!虽然可以通过修改类(结构体)方法为值传递,使得通过值调用接口:
package main import "fmt" type Sayer interface { Say() } type Cat struct{} func (c Cat) Say() { fmt.Println("喵喵喵~") } type Dog struct{} func (d Dog) Say() { fmt.Println("汪汪汪~") } func main() { var x,y Sayer // 声明一个Sayer类型的变量x a := Cat{} // 声明一个Cat类型变量a b := Dog{} // 声明一个Dog类型变量b x = &a // 可以把Cat类型变量直接赋值给x x.Say() // 喵喵喵 x = &b // 可以把Dog类型变量直接赋值给x x.Say() // 汪汪汪 y = a // 可以把Cat类型变量直接赋值给x y.Say() // 喵喵喵 y = b // 可以把Dog类型变量直接赋值给x y.Say() // 汪汪汪 }可以看到当方法为值传递时,我们使用值接收者和指针接收者都是可以的.但是当方法为指针传递时,只允许使用指针接收者.否则会报错:
cannot use a (variable of type Cat) as type Sayer in assignment:
Cat does not implement Sayer (Say method has pointer receiver)
package main import "fmt" type Sayer interface { Say() } type Cat struct{} func (c *Cat) Say() { fmt.Println("喵喵喵~") } type Dog struct{} func (d *Dog) Say() { fmt.Println("汪汪汪~") } func main() { var x Sayer // 声明一个Sayer类型的变量x a := Cat{} // 声明一个Cat类型变量a b := Dog{} // 声明一个Dog类型变量b x = &a // 可以把Cat类型变量直接赋值给x x.Say() // 喵喵喵 x = &b // 可以把Dog类型变量直接赋值给x x.Say() // 汪汪汪 // y = a // 可以把Cat类型变量直接赋值给x // y.Say() // 喵喵喵 // y = b // 可以把Dog类型变量直接赋值给x // y.Say() // 汪汪汪 }因此,以后还是统一使用指针传递方法,配合指针接受更好!!! 3.反射修改原数据
func reflectModValue(x interface{}) { v := reflect.ValueOf(x) //注意:我们传递进来的是指针,所以通过Elem获取指针中的数据,然后通过Kind获取数据类型进行判断 if v.Elem().Kind() == reflect.Int64 { v.Elem().SetInt(11) } } func main() { var a int64 = 10 fmt.Printf("value is :%d\n",a) reflectModValue(&a) fmt.Printf("value is :%d\n",a) }