Python 定时调度–APScheduler
APScheduler提供了基于日期、固定时间间隔以及crontab类型的任务,并且可以持久化任务。
APScheduler提供了多种不同的调度器,方便开发者根据自己的实际需要进行使用;同时也提供了不同的存储机制,可以方便与Redis,数据库等第三方的外部持久化机制进行协同工作,总之功能非常强大和易用。
APScheduler的主要的调度类
在APScheduler中有以下几个非常重要的概念,需要大家理解:
触发器(trigger)
包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行,根据trigger中定义的时间点,频率,时间区间等等参数设置。除了他们自己初始配置以外,触发器完全是无状态的。
作业存储(job store)
存储被调度的作业,默认的作业存储是简单地把作业保存在内存中,其他的作业存储是将作业保存在数据库中。一个作业的数据讲在保存在持久化作业存储时被序列化,并在加载时被反序列化。调度器不能分享同一个作业存储。job store支持主流的存储机制:redis, mongodb, 关系型数据库, 内存等等
执行器(executor)
处理作业的运行,他们通常通过在作业中提交制定的可调用对象到一个线程或者进城池来进行。当作业完成时,执行器将会通知调度器。基于池化的操作,可以针对不同类型的作业任务,更为高效地使用cpu的计算资源。
调度器(scheduler)
通常在应用只有一个调度器,调度器提供了处理这些的合适的接口。配置作业存储和执行器可以在调度器中完成,例如添加、修改和移除作业。
这里简单列一下常用的若干调度器:
- BlockingScheduler:仅可用在当前你的进程之内,与当前的进行共享计算资源
- BackgroundScheduler: 在后台运行调度,不影响当前的系统计算运行
- AsyncIOScheduler: 如果当前系统中使用了async module,则需要使用异步的调度器
- GeventScheduler: 如果使用了gevent,则需要使用该调度
- TornadoScheduler: 如果使用了Tornado, 则使用当前的调度器
- TwistedScheduler:Twister应用的调度器
- QtScheduler: Qt的调度器
BackgroundScheduler: 适合于要求任何在程序后台运行的情况,当希望调度器在应用后台执行时使用。
AsyncIOScheduler:适合于使用asyncio框架的情况
GeventScheduler: 适合于使用gevent框架的情况
TornadoScheduler: 适合于使用Tornado框架的应用
TwistedScheduler: 适合使用Twisted框架的应用
QtScheduler:
add_job() 中 trigger 参数为调用方式,有 interval, day, cron 三种值
date 日期:触发任务运行的具体日期
interval 间隔:触发任务运行的时间间隔
cron 周期:触发任务运行的周期
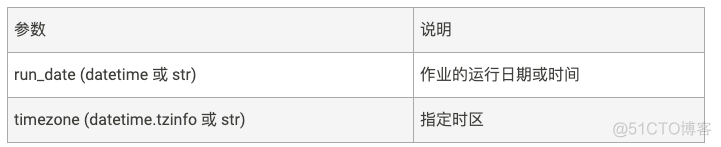
触发器date
特定的时间点触发,只执行一次。参数如下:
定时任务:修改创建文件时间超过100s的文件的文件名
可以使用
import datetime
import os
from dateutil.parser import parser
def TimeStamp2Time(timestamp):
timestruct = time.localtime(timestamp)
return time.strftime('%Y-%m-%d %H:%M:%S',timestruct)
def job(Path,now_time):
files = os.listdir(Path)
for file in files:
if file.endswith('.txt'):
filepath = Path+file
try:
t = os.path.getctime(filepath)
creat_filetime = TimeStamp2Time(t)
a = parser(now_time)
b = parser(creat_filetime)
time_diff = (a-b).total_seconds()
if time_diff/100>1:
try:
new_filename = filepath[:4]+'.json'
os.rename(filepath,new_filename)
except:
print('rename fail')
except:
print(filepath,'is not exist!')
if __name__ == '__main__':
Path = 'D:/data/images/'
while True:
now_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
job(Path,now_time)
time.sleep(10)