Apache Druid是一个实时分析型数据库,旨在对大型数据集进行快速的查询分析("OLAP"查询)。Druid最常被当做数据库来用以支持实时摄取、高性能查询和高稳定运行的应用场景,同时,Dru
Apache Druid是一个实时分析型数据库,旨在对大型数据集进行快速的查询分析("OLAP"查询)。Druid最常被当做数据库来用以支持实时摄取、高性能查询和高稳定运行的应用场景,同时,Druid也通常被用来助力分析型应用的图形化界面,或者当做需要快速聚合的高并发后端API,Druid最适合应用于面向事件类型的数据。
目录
一、主要特征
二、使用场景
三、初始化SpringBoot项目
四、引入依赖文件
五、编写配置文件
六、编写DruidConfig配置类
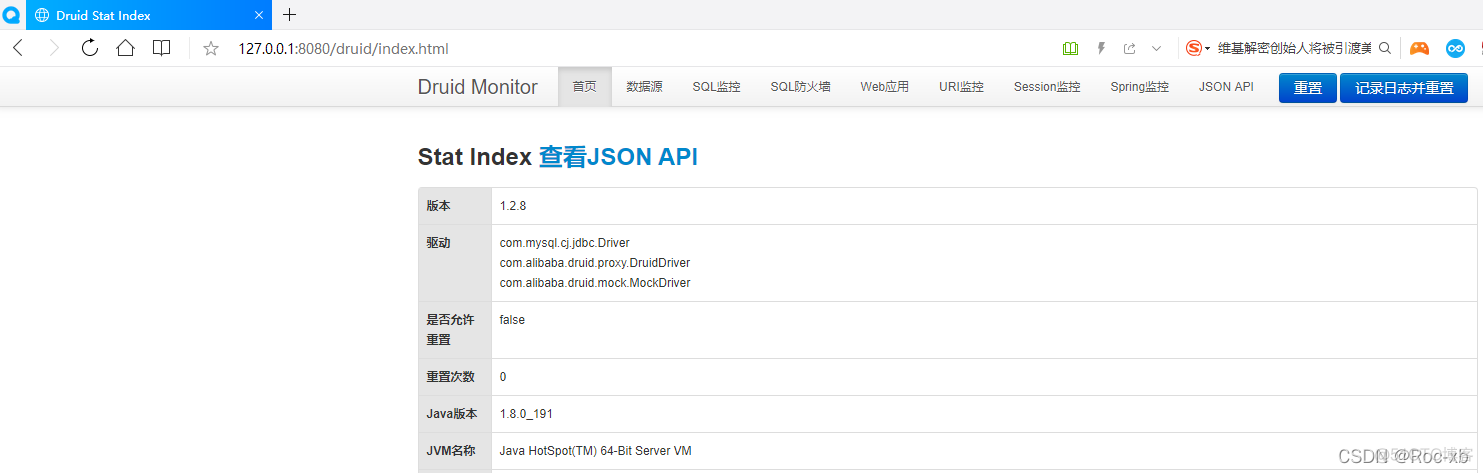
七、查看Druid监控信息
一、主要特征
二、使用场景
如果您的使用场景符合以下的几个特征,那么Druid是一个非常不错的选择。
- 数据插入频率比较高,但较少更新数据
- 大多数查询场景为聚合查询和分组查询(GroupBy),同时还有一定得检索与扫描查询
- 将数据查询延迟目标定位100毫秒到几秒钟之间
- 数据具有时间属性(Druid针对时间做了优化和设计)
- 在多表场景下,每次查询仅命中一个大的分布式表,查询又可能命中多个较小的lookup表
- 场景中包含高基维度数据列(例如URL,用户ID等),并且需要对其进行快速计数和排序
- 需要从Kafka、HDFS、对象存储(如Amazon S3)中加载数据
三、初始化SpringBoot项目
四、引入依赖文件
<dependency><groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- 阿里巴巴druid依赖-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.8</version>
</dependency>
五、编写配置文件
application.yml
spring:# 配置数据源
datasource:
url: jdbc:mysql://127.0.0.1:3306/mysql?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull&useSSL=false # MySQL在高版本需要指明是否进行SSL连接 解决则加上 &useSSL=false
name: demo
username: root
password: 123456
platform: mysql
driver-class-name: com.mysql.jdbc.Driver
# ===================== ↓↓↓↓↓↓ 使用druid数据源 ↓↓↓↓↓↓ =====================
# 连接池类型,druid连接池springboot暂无法默认支持,需要自己配置bean
type: com.alibaba.druid.pool.DruidDataSource
initialSize: 5 # 连接池初始化连接数量
minIdle: 5 # 连接池最小空闲数
maxActive: 20 # 连接池最大活跃连接数
maxWait: 60000 # 配置获取连接等待超时的时间
timeBetweenEvictionRunsMillis: 60000 # 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
minEvictableIdleTimeMillis: 300000 # 配置一个连接在池中最小生存的时间,单位是毫秒
validationQuery: SELECT 1 FROM DUAL # 连接是否有效的查询语句
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
# 打开PSCache,并且指定每个连接上PSCache的大小
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
removeAbandoned: true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,【 'stat':监控统计 'wall':用于防火墙,防御sql注入 'slf4j':日志 】
filters: stat,wall,slf4j
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
#useGlobalDataSourceStat: true # 合并多个DruidDataSource的监控数据
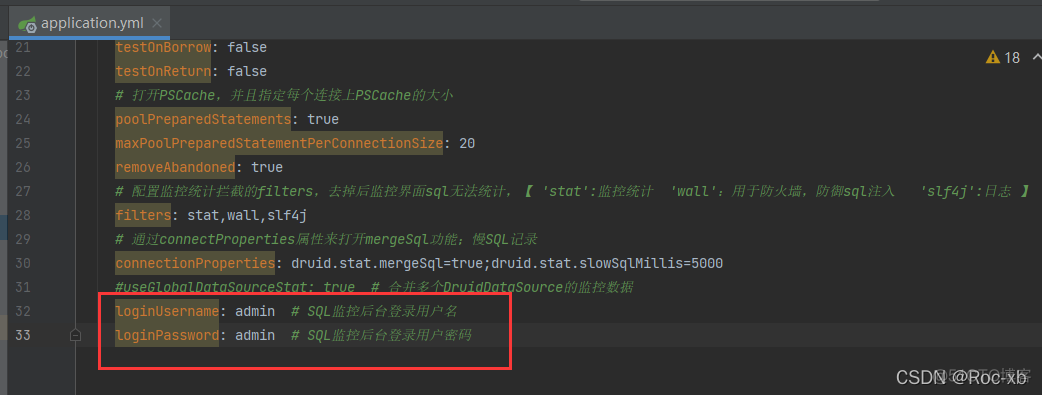
loginUsername: admin # SQL监控后台登录用户名
loginPassword: admin # SQL监控后台登录用户密码
六、编写DruidConfig配置类
package com.csdn.config;import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import com.alibaba.druid.support.spring.stat.DruidStatInterceptor;
import org.springframework.aop.support.DefaultPointcutAdvisor;
import org.springframework.aop.support.JdkRegexpMethodPointcut;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Scope;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
/**
* <p> Druid核心配置类 - 注册bean </p>
*
* @author : Roc-xb
*/
@Configuration
public class DruidConfig {
@Value("${spring.datasource.loginUsername}")
private String loginUsername;
@Value("${spring.datasource.loginPassword}")
private String loginPassword;
/**
* 配置Druid监控
*
* @param :
* @return: org.springframework.boot.web.servlet.ServletRegistrationBean
*/
@Bean
public ServletRegistrationBean druidServlet() {
// 注册服务
ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
// IP白名单(为空表示,所有的都可以访问,多个IP的时候用逗号隔开)
servletRegistrationBean.addInitParameter("allow", "127.0.0.1");
// IP黑名单 (存在共同时,deny优先于allow)
servletRegistrationBean.addInitParameter("deny", "127.0.0.2");
// 设置控制台登录的用户名和密码
servletRegistrationBean.addInitParameter("loginUsername", loginUsername);
servletRegistrationBean.addInitParameter("loginPassword", loginPassword);
// 是否能够重置数据
servletRegistrationBean.addInitParameter("resetEnable", "false");
return servletRegistrationBean;
}
/**
* 配置web监控的filter
*
* @param :
* @return: org.springframework.boot.web.servlet.FilterRegistrationBean
*/
@Bean
public FilterRegistrationBean webStatFilter() {
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(new WebStatFilter());
// 添加过滤规则
Map<String, String> initParams = new HashMap<>(1);
// 设置忽略请求
initParams.put("exclusions", "*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico,/druid/*");
filterRegistrationBean.setInitParameters(initParams);
filterRegistrationBean.addInitParameter("profileEnable", "true");
filterRegistrationBean.addInitParameter("principalCookieName", "USER_COOKIE");
filterRegistrationBean.addInitParameter("principalSessionName", "");
filterRegistrationBean.addInitParameter("aopPatterns", "com.example.demo.service");
// 验证所有请求
filterRegistrationBean.addUrlPatterns("/*");
return filterRegistrationBean;
}
/**
* 配置数据源 【 将所有前缀为spring.datasource下的配置项都加载到DataSource中 】
*
* @param :
* @return: javax.sql.DataSource
*/
@Bean(name = "dataSource")
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource dataSource() {
return new DruidDataSource();
}
/**
* 配置事物管理器
*
* @param :
* @return: org.springframework.jdbc.datasource.DataSourceTransactionManager
*/
@Bean(name = "transactionManager")
public DataSourceTransactionManager transactionManager() {
return new DataSourceTransactionManager(dataSource());
}
/**
* ↓↓↓↓↓↓ 配置spring监控 ↓↓↓↓↓↓
* DruidStatInterceptor: druid提供的拦截器
*
* @param :
* @return: com.alibaba.druid.support.spring.stat.DruidStatInterceptor
*/
@Bean
public DruidStatInterceptor druidStatInterceptor() {
DruidStatInterceptor dsInterceptor = new DruidStatInterceptor();
return dsInterceptor;
}
/**
* 使用正则表达式配置切点
*
* @param :
* @return: org.springframework.aop.support.JdkRegexpMethodPointcut
*/
@Bean
@Scope("prototype")
public JdkRegexpMethodPointcut druidStatPointcut() {
JdkRegexpMethodPointcut pointcut = new JdkRegexpMethodPointcut();
pointcut.setPattern("com.zhengqing.demo.modules.*.api.*");
return pointcut;
}
/**
* DefaultPointcutAdvisor类定义advice及 pointcut 属性。advice指定使用的通知方式,也就是druid提供的DruidStatInterceptor类,pointcut指定切入点
*
* @param druidStatInterceptor
* @param druidStatPointcut:
* @return: org.springframework.aop.support.DefaultPointcutAdvisor
*/
@Bean
public DefaultPointcutAdvisor druidStatAdvisor(DruidStatInterceptor druidStatInterceptor, JdkRegexpMethodPointcut druidStatPointcut) {
DefaultPointcutAdvisor defaultPointAdvisor = new DefaultPointcutAdvisor();
defaultPointAdvisor.setPointcut(druidStatPointcut);
defaultPointAdvisor.setAdvice(druidStatInterceptor);
return defaultPointAdvisor;
}
}
七、查看Druid监控信息
上面的东西配置完成之后,就可以启动项目,然后访问:http://127.0.0.1:8080/druid/login.html
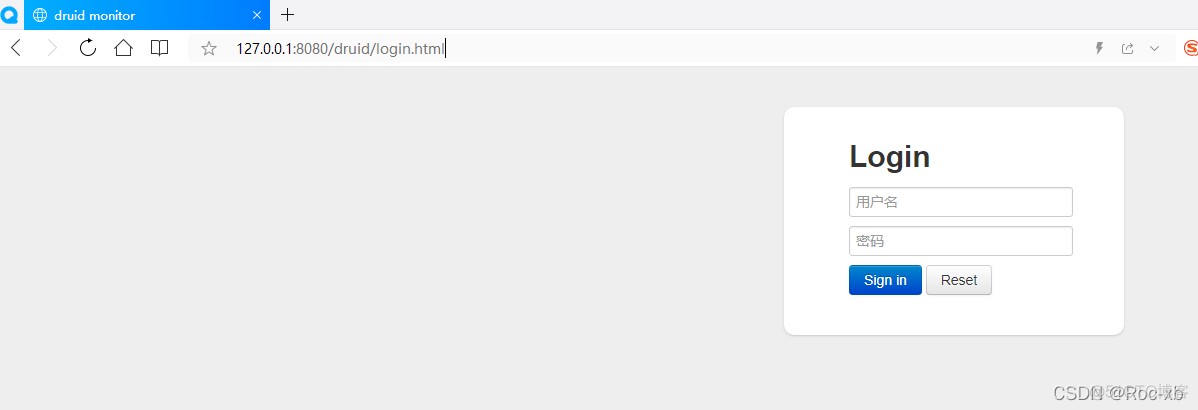
填写登录账号和密码,然后登录即可。
至此,整合过程就完成了,如果本章教程对有你帮助,点个赞支持一下呗~